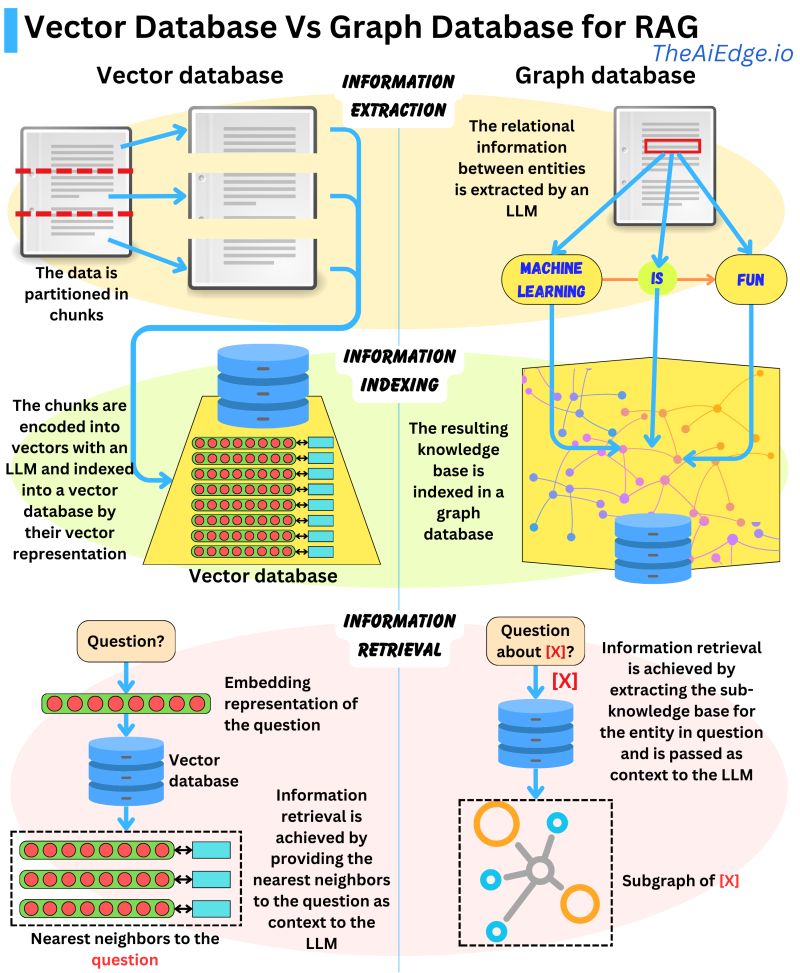
Advanced RAG Methods: Simple, Hybrid, Agentic, Graph Explained
Discover Retrieval-Augmented Generation (RAG) methods: Simple RAG for basic tasks, Hybrid RAG combining retrieval techniques, AgenticRAG with modular multi-agent systems, and GraphRAG leveraging graph data. Each method offers unique strengths, tailored for tasks.

Overview of the Methods Compared
In this section, we introduce and outline the key Retrieval-Augmented Generation (RAG) methods we will explore in detail. These methods represent diverse approaches to integrating retrieval mechanisms into generative frameworks, each tailored to specific needs and use cases.
The four RAG methods covered in this comparison are Simple RAG, Hybrid RAG, AgenticRAG, and GraphRAG. Each of these methods has unique strengths, limitations, and ideal scenarios for application. Below, we provide an overview of each method, striking a balance between narrative explanation and concise bullet-point details.
Simple RAG
Simple RAG is the foundational approach to retrieval-augmented generation. It combines a single retrieval module with a generative model to provide responses grounded in external knowledge. The retrieval module selects relevant documents or passages, which are then processed by the language model to generate coherent text.
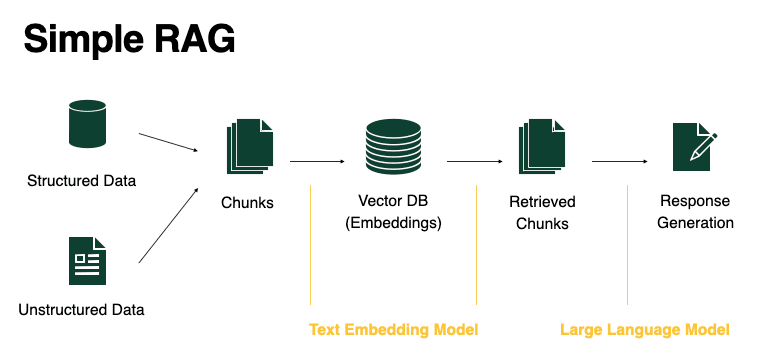
- Key Characteristics: The architecture of Simple RAG is straightforward, making it easy to implement and understand. It is suitable for tasks like basic question-answering or text summarization, where the complexity of the queries is relatively low.
- Advantages: Simple RAG's simplicity is its main strength, allowing it to be used without extensive computational resources or complex configurations. This makes it ideal for applications that prioritize ease of deployment.
- Limitations: However, Simple RAG struggles with more sophisticated information needs, particularly when dealing with ambiguous or multi-faceted queries. Its reliance on a single retrieval strategy often limits its ability to handle nuanced contexts effectively.
- Typical Applications: Use cases include FAQs and straightforward knowledge retrieval, where the need for advanced context handling is minimal.
Consider adding an image or diagram that illustrates the flow of Simple RAG, showing how the retrieval and generation components interact. The following image is recommended:
Hybrid RAG
Hybrid RAG enhances the retrieval process by combining multiple retrieval techniques, such as sparse (e.g., BM25) and dense (e.g., DPR) retrieval. This hybrid approach provides better accuracy and robustness compared to the more basic Simple RAG.
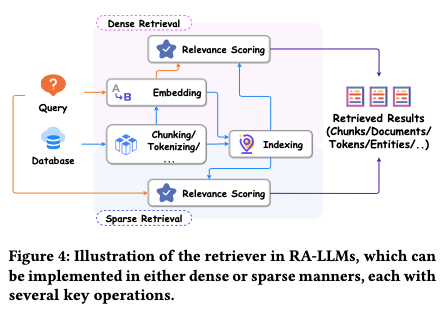
Hybrid RAG employs both keyword-based and semantic retrieval to ensure a broader and more precise search capability. By combining these approaches, it can effectively handle queries that are not well-defined or require understanding both explicit and implicit meanings.
- Key Characteristics: The hybrid nature of this method ensures a more comprehensive retrieval process, making it useful for tasks where precise and varied information retrieval is essential.
- Advantages: This method significantly improves retrieval precision, making it robust for heterogeneous data environments. Hybrid RAG is well-suited for applications involving multi-domain queries, where diverse retrieval capabilities are needed.
- Limitations: The main downside is the increased computational cost due to the combination of different retrieval strategies. Configuring and maintaining such a hybrid system also requires more resources and expertise.
- Use Cases: Hybrid RAG is ideal for complex retrieval scenarios involving documents with diverse formats and sources.
| Retrieval Method | Sparse (e.g., BM25) | Dense (e.g., DPR) |
|---|---|---|
| Technique | Keyword-based retrieval | Semantic vector-based retrieval |
| Strengths | Simple, efficient, good for well-defined keywords | Effective at capturing semantic meaning, handles complex queries well |
| Weaknesses | Struggles with semantic understanding | Requires more computational power, complex training |
| Best Use Cases | Simple, keyword-focused queries | Complex, open-ended queries requiring deeper context |
To understand more about different RAG strategies, visit here: RAG Strategies.
AgenticRAG
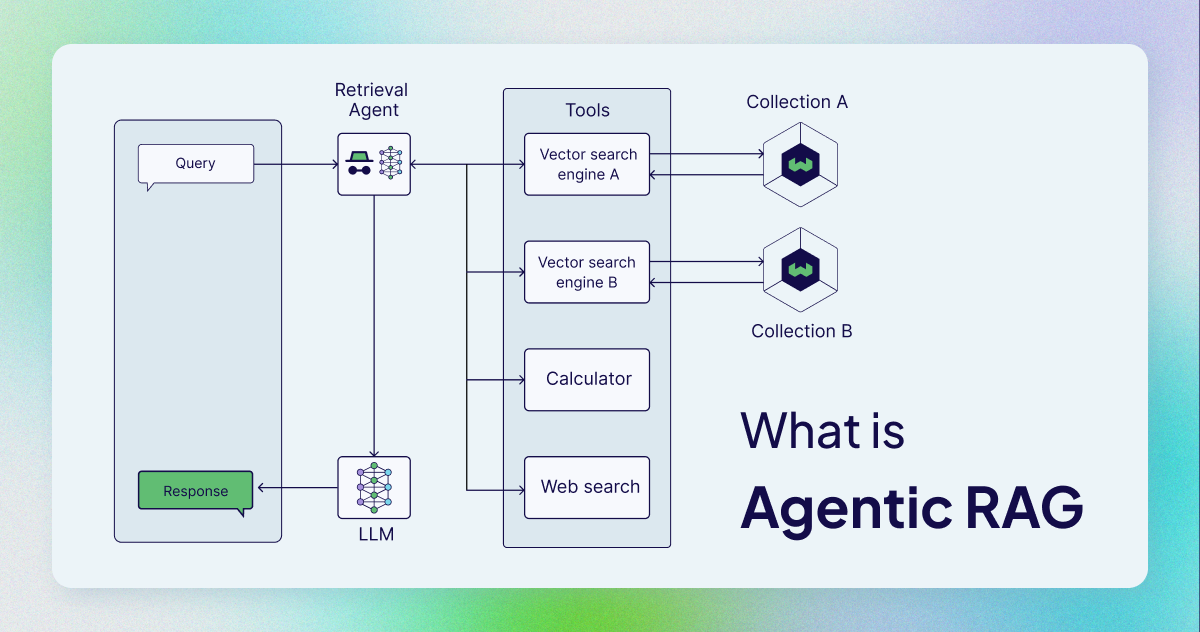
AgenticRAG introduces a multi-agent architecture where different agents specialize in distinct tasks related to retrieval or generation. The retrieval process not includes usage of different vector DBs along with set of tools which are given by the user for the agents to use for better retrieval. This modularity allows AgenticRAG to adapt dynamically to complex information requests.
The system relies on specialized sub-agents that coordinate to provide the final response. Each agent has a distinct role, such as handling specific types of queries or optimizing certain aspects of retrieval. The master agent oversees the process and combines the agents' outputs into a coherent answer.
- Key Characteristics: This method's multi-agent system enhances adaptability and flexibility, making it suitable for dynamic environments.
- Advantages: AgenticRAG excels in situations requiring high adaptability, as the modular setup allows for specialization. It is particularly effective in scenarios where different types of data need to be handled concurrently.
- Limitations: The increased complexity is a significant drawback. Implementing and coordinating multiple agents require more computational resources and careful architectural design, leading to challenges in scalability.
- Applications: Typical use cases include time-series analysis and other complex, multi-step reasoning tasks where diverse types of data need to be processed effectively.
For more, go here: RAG Strategies.
GraphRAG
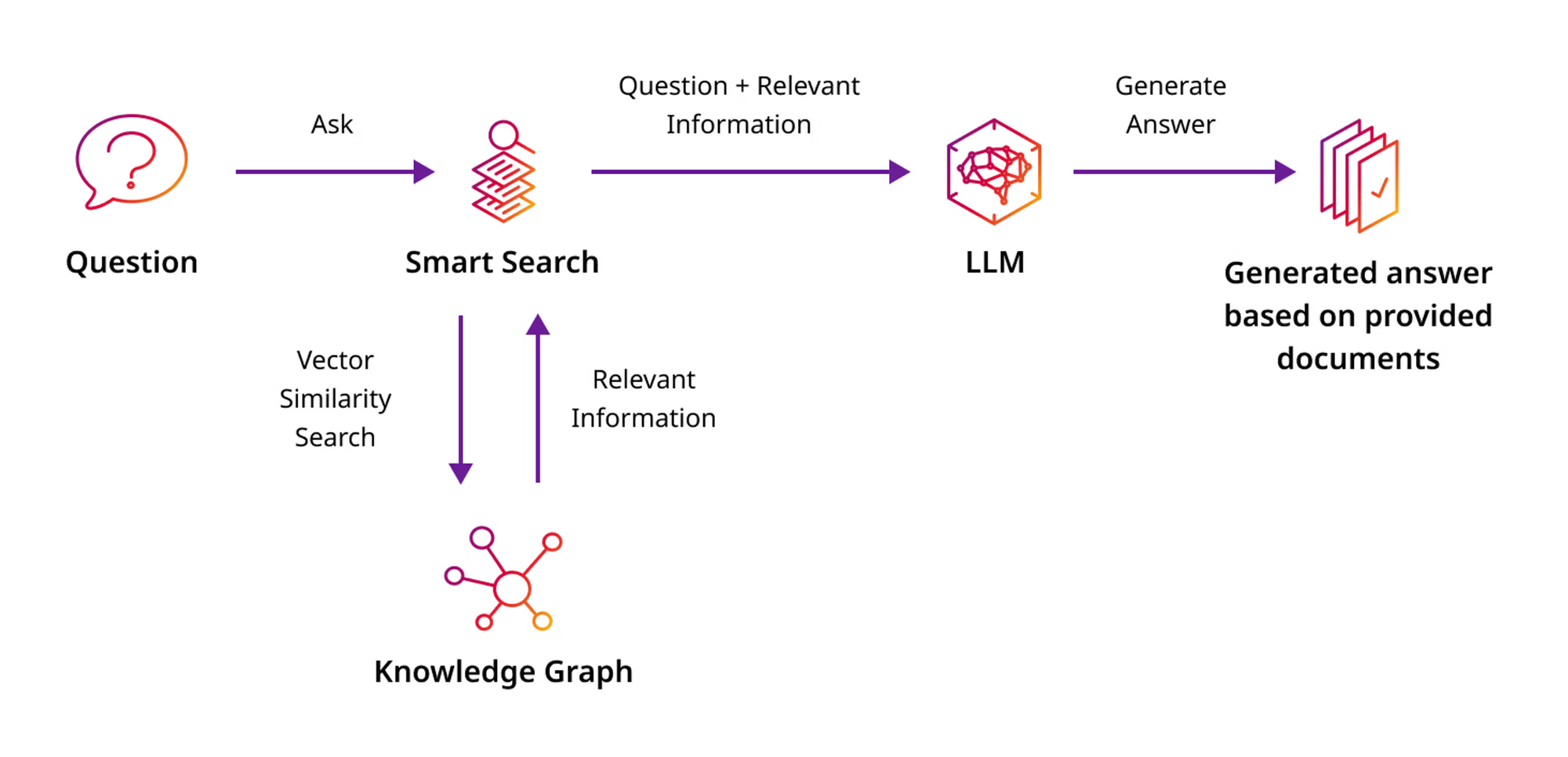
GraphRAG leverages graph-based data structures to enhance retrieval, making it particularly powerful for scenarios involving structured queries or where relationships between entities are crucial. During the indexing stage of documents, we use LLMs to convert document chunks to knowledge graphs.
During the time of retrieval, we use different search methods on the nodes and edges of the graph (like node embedding search, bm25, BFS search), that gives high degree of precision, especially when the queries are related to entities and their relationships.
- Key Characteristics: GraphRAG stands out due to its use of graph databases, which enables it to maintain and exploit relationships between entities, resulting in highly precise retrieval for certain types of questions.
- Advantages: It is especially useful for tasks requiring structured information, such as those involving knowledge graphs or semantic networks.
- Limitations: The reliance on graph structures can limit scalability, particularly when dealing with large or unstructured datasets. Managing and maintaining graph databases can also be computationally expensive.
- Applications: GraphRAG is well-suited for knowledge graph queries and domain-specific retrieval tasks where understanding the relationships between entities is crucial.
Comparative Analysis of RAG Methods
In this section, we compare the four RAG methods—Simple RAG, Hybrid RAG, AgenticRAG, and GraphRAG—by highlighting their strengths, weaknesses, and suitability for different applications. The comparative analysis provides insights into the factors that influence the effectiveness of each method, allowing readers to understand which method is best suited for specific use cases. `In this section, we will explore the strengths and weaknesses of each RAG method, highlighting what makes them suitable for different scenarios.
- Simple RAG
- Simple RAG is the most straightforward approach to retrieval-augmented generation, making it easy to implement and requiring minimal computational resources. This simplicity makes it ideal for low-complexity use cases, such as answering frequently asked questions or generating simple summaries. However, due to its reliance on a single retrieval strategy, Simple RAG struggles with more sophisticated information needs, particularly when queries are complex or ambiguous. This makes it less suitable for multi-faceted or evolving datasets.
- Hybrid RAG
- Hybrid RAG combines both sparse and dense retrieval techniques to provide a broader and more adaptable retrieval capability. By leveraging both keyword-based and semantic retrieval, Hybrid RAG achieves a higher level of precision and versatility, making it well-suited for environments that require understanding both explicit terms and nuanced meanings. However, this combination comes at the cost of increased computational requirements and a more complex setup, which can be challenging to manage, especially in heterogeneous data environments.
- AgenticRAG
- AgenticRAG uses a multi-agent system where each agent specializes in different tasks, allowing for dynamic adaptability and targeted retrieval. This modular approach is particularly effective for scenarios that involve multiple steps or require handling different types of data concurrently. However, the complexity of coordinating multiple agents increases the computational load, making it challenging to scale, particularly in resource-constrained environments. The intricate design and implementation process also add to the overall complexity of using AgenticRAG.
- GraphRAG
- GraphRAG leverages graph-based data structures to enhance retrieval, making it highly effective for structured queries and scenarios where understanding relationships between entities is crucial. This graph-based retrieval allows for highly precise information extraction, particularly in knowledge graph queries and domain-specific retrieval tasks. However, GraphRAG's reliance on graph structures can limit its scalability, as managing large or unstructured datasets can be computationally expensive. The computational overhead involved in maintaining graph databases further contributes to its limitations.
Comparative Summary Table
| Method | Strengths | Weaknesses | Best Use Cases |
| Simple RAG | Straightforward, low resource usage | Limited in handling complex queries | FAQs, simple summarization |
| Hybrid RAG | Combines multiple retrieval methods | High computational cost, complex setup | Multi-domain queries, diverse data environments |
| AgenticRAG | Multi-agent adaptability for complex tasks | High complexity, coordination challenges | Time-series analysis, multi-step reasoning |
| GraphRAG | Graph-based precision for structured data | Scalability issues, computational overhead | Knowledge graph queries, entity relationships |
In-Depth Exploration of RAG Techniques
In this section, we delve into the advanced topics related to Retrieval-Augmented Generation (RAG), focusing on the latest innovations, the challenges faced by current systems, and the potential future directions. The key focus areas include improving the efficiency of RAG systems, enhancing reasoning capabilities, and addressing scalability issues.
Future Directions
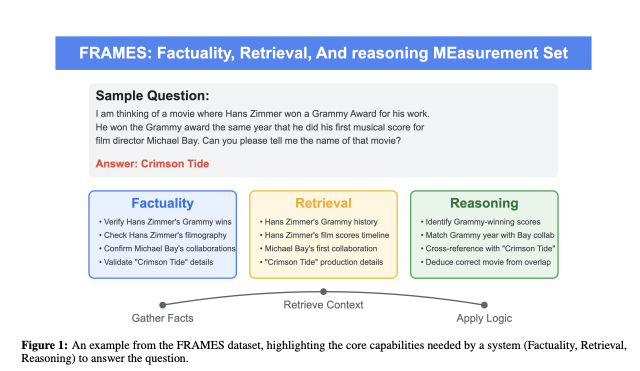
Recent advancements in Large Language Models (LLMs) have opened up opportunities for more sophisticated retrieval and reasoning techniques in RAG systems. One major area of future work is the development of more advanced hybrid retrieval strategies. These strategies may incorporate multiple dense retrievers, each trained on different types of data, to improve performance in diverse and complex queries. The document "Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation" introduces FRAMES, a dataset that emphasizes multi-hop retrieval, highlighting the need for sophisticated retrieval approaches to handle real-world scenarios that require information integration across multiple sources.
Another important direction is enhancing real-time retrieval and reasoning capabilities. The FRAMES dataset shows that models significantly improve their performance when they are forced to retrieve and reason in multiple steps rather than relying on a single inference. Future RAG systems could incorporate iterative retrieval processes, where models plan their search more effectively over multiple steps, enhancing their ability to deal with complex, multi-hop queries.
Challenges
Scalability remains a major challenge for RAG systems. As highlighted in the FRAMES dataset, the complexity of managing and processing multiple retrieved documents, particularly in scenarios involving multi-hop reasoning, requires substantial computational resources. This poses scalability challenges, especially in real-world applications where systems need to handle large volumes of information across diverse domains. Ensuring that RAG systems can scale efficiently while maintaining accuracy is a key area for future research.
Another challenge is related to the reasoning capabilities of current LLMs. According to the FRAMES dataset, many models still struggle with complex types of reasoning, such as temporal reasoning, numerical reasoning, and combining information from multiple documents to derive conclusions. Even with advanced retrieval mechanisms, existing models often fall short in synthesizing retrieved information into coherent and accurate responses. Addressing these reasoning gaps is crucial to developing more robust RAG systems.
Additionally, the FRAMES dataset highlights the issue of ensuring factual accuracy and avoiding hallucinations, especially in multi-hop scenarios. The evaluation reveals that even state-of-the-art models tend to hallucinate or provide incorrect information when the retrieved data is insufficiently processed or when the reasoning chains are complex. Effective training techniques, such as using curated multi-hop datasets and employing human feedback, could help address these limitations.
Recent Innovations
Recent innovations in RAG systems have focused on improving retrieval accuracy and enhancing the reasoning process. For example, the introduction of multi-step retrieval mechanisms, as detailed in the FRAMES dataset, compels models to iteratively retrieve and reason, significantly improving their performance on complex queries. This multi-step approach not only boosts retrieval accuracy but also enhances the overall reasoning capabilities of RAG systems.
Another notable innovation is the development of advanced evaluation frameworks, such as FRAMES, which provide a more comprehensive assessment of RAG systems by evaluating factuality, retrieval accuracy, and reasoning in an integrated manner. Unlike previous benchmarks that assessed these capabilities in isolation, FRAMES offers a holistic approach that better reflects real-world performance, especially for complex, multi-document retrieval tasks.
Innovative retrieval techniques, such as training dense retrievers specifically for multi-hop queries, have also emerged as promising solutions. These techniques help models adapt to iterative contexts, improving their ability to retrieve relevant documents for each reasoning step. Additionally, the integration of advanced optimization techniques, such as those used in PRM-800K and DSPy, is being explored to enhance numerical, temporal, and post-processing reasoning, further pushing the boundaries of what RAG systems can achieve.
Summary and Conclusion
In conclusion, Retrieval-Augmented Generation (RAG) represents a powerful approach to integrating retrieval mechanisms with generative language models, allowing systems to ground their responses in external data. Throughout this article, we have explored the different types of RAG methods—Simple RAG, Hybrid RAG, AgenticRAG, and GraphRAG—each offering unique strengths and facing particular challenges.
Simple RAG is ideal for straightforward use cases due to its ease of implementation but struggles with more complex information needs. Hybrid RAG combines multiple retrieval methods to provide a versatile solution but requires significant computational power. AgenticRAG excels in adaptability and dynamic environments, though its complexity makes scalability a challenge. Finally, GraphRAG is highly effective for structured information retrieval but faces limitations in scalability due to its reliance on graph-based databases.
Advanced topics in RAG systems include future directions such as iterative retrieval strategies and real-time enhancements, addressing ongoing challenges in scalability, reasoning complexity, and maintaining factual accuracy. Recent innovations have further improved retrieval accuracy and evaluation methods, pushing the capabilities of RAG systems forward.
The development of more sophisticated hybrid retrieval techniques, iterative retrieval, and advanced evaluation frameworks like FRAMES will be crucial in addressing the limitations of current systems. As RAG continues to evolve, it holds the potential to significantly improve how language models interact with information, providing more reliable, relevant, and contextually accurate responses.
References: