AI Data Residency Requirements by Region: The Complete Enterprise Compliance Guide
73% of enterprises cite data privacy as their top AI concern. This guide maps where AI data flows, regional requirements (EU, US, China, India), and how to maintain compliance.

€1.2 billion.
That's what Meta paid for transferring EU user data to the United States. TikTok followed with €530 million for sending data to China. Uber paid €290 million for moving driver records across borders.
The era of "move fast and figure out compliance later" is over for AI.
According to Deloitte's State of AI in the Enterprise report (August–September 2025), 73% of enterprises now cite data privacy and security as their top AI risk concern. 77% factor a vendor's country of origin into AI purchasing decisions.
The regulatory pressure is intensifying. EU AI Act penalties reach 7% of global turnover, higher than GDPR. China enforces mandatory AI registration with localization requirements. India's financial regulators mandate in-country data storage.
This guide maps where AI data actually flows, what each major region requires, and how to architect compliant infrastructure.
What Is AI Data Residency?
Three related concepts get conflated. They’re not the same.
Data residency refers to where data is physically stored, the geographic location of servers.
Data sovereignty refers to whose laws govern that data, the legal jurisdiction that applies.
Data localization refers to legal mandates requiring data to stay within specific borders.
Traditional data residency focused on storage. AI introduces complexity that storage-focused thinking misses.
Training data residency: Where was the data that trained your model stored and processed? If you’re using GPT-4, the training happened on US infrastructure using data scraped globally.
Inference residency: Where does computation happen when you query the model? A prompt sent to OpenAI’s API may process in Virginia or Amsterdam depending on your endpoint.
Fine-tuning data residency: Where is your custom training data processed? When you fine-tune on Azure, Microsoft’s documentation specifies the geography but processing may span regions.
Output data residency: Where are generated responses stored and logged? Most providers retain prompts and completions for 7-30 days across their infrastructure.
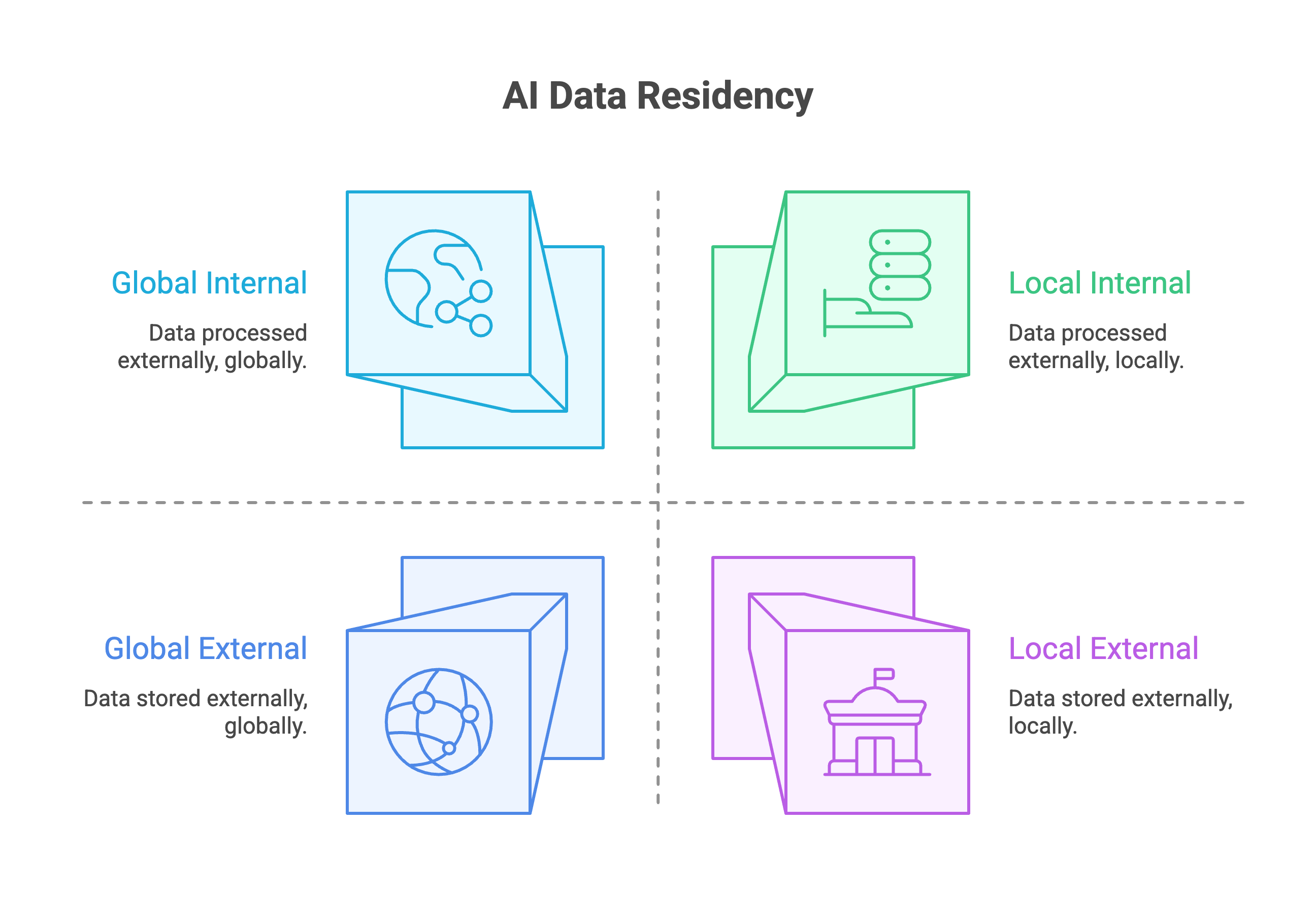
What is AI data residency?
AI data residency refers to the physical location where AI-related data, including training data, prompts, model weights, and generated outputs, is stored and processed. Unlike traditional data storage, AI creates multiple residency touchpoints: where the model was trained, where inference runs, where fine-tuning occurs, and where outputs are logged.
The US CLOUD Act Problem
Here’s the gap most compliance guides miss.
The US CLOUD Act allows US law enforcement to compel American companies to provide access to data stored abroad, even if servers are physically located in the EU.
Selecting “EU region” in AWS, Azure, or Google Cloud does NOT guarantee sovereignty if the provider is US-headquartered. The legal jurisdiction follows the company, not the data center.
This distinction matters. True data sovereignty requires either:
- Non-US-headquartered providers
- Self-hosted infrastructure
- Legal structures that prevent extraterritorial access
For technical implementation of GDPR-compliant systems, see our GDPR-compliant AI architecture guide.
Where Does AI Data Actually Flow?
Most enterprise compliance teams understand that API calls send data to external servers. Few understand the full picture of where AI data travels.
Table 1: Data flow points in enterprise AI systems and their compliance implications
| AI Operation | Data Created | Where It Typically Goes | Default Retention |
|---|---|---|---|
| API Inference | Prompts, completions, tokens, metadata | Provider’s regional servers | 0-30 days |
| Fine-Tuning | Training examples, model weights, checkpoints | Provider cloud storage | Until deletion |
| RAG/Embeddings | Document chunks, vectors, retrieval logs | Vector database (cloud or self-hosted) | Persistent |
| Caching | Prompt-response pairs, KV cache | GPU memory → SSD → cloud storage | Session-based |
| Observability | Full payloads, latency, errors | Monitoring platform | 30-365 days |
Major AI Provider Data Handling
The policies differ significantly across providers.
OpenAI API: Retains data for 30 days for abuse monitoring. API and business data not used for training by default. Zero Data Retention available for qualifying organizations. Human reviewers may access data unless ZDR is enabled.
Anthropic (Claude): Retains API data for 7 days (reduced from 30 as of September 2025). API data never used for model training. ZDR addendum available for maximum isolation.
AWS Bedrock: Does not store or log prompts and completions. Data never used to train AWS models. Remains in customer-selected region.
Azure OpenAI: Data stored in resource’s Azure geography. Not used for training without consent. EU Data Boundary ensures processing stays in EU for EU customers.
Google Vertex AI: 30-55 day retention for abuse monitoring. Paid users excluded from training. Regional deployments supported with documentation.
The Hidden Data Flows
Most enterprises miss these secondary data paths:
Embedding APIs: When you call OpenAI’s text-embedding-ada-002 or similar, your documents leave your infrastructure to be vectorized externally.
Vector database cloud services: Pinecone, Weaviate Cloud, and similar managed services store your chunked documents on their infrastructure.
Observability platforms: LangSmith, Langfuse, and similar tools may log full prompts and completions to their servers for debugging and monitoring.
Model registries: Downloads from Hugging Face and model hubs may log metadata about your access patterns.
For keeping AI data entirely internal, see our guide on private LLM deployment.
Regional Requirements Map
The regulatory landscape varies dramatically by jurisdiction. Some mandate localization. Others focus on governance. Most are tightening requirements through 2026.
AI data residency requirements by major region (2026)
| Region | Data Localization Required? | Key AI-Specific Requirements | Maximum Penalties | Key Deadline |
|---|---|---|---|---|
| EU | No (but sovereignty concerns apply) | EU AI Act Art. 10 data governance, bias detection, representative datasets | 7% global turnover or €35M | Aug 2026 |
| USA | No federal requirement | State ADM disclosure (CA, CO, VA), HIPAA for healthcare, FedRAMP for gov | Varies by state/sector | Ongoing |
| China | Yes (for CIIOs and important data) | GenAI registration, content labeling, security assessment for transfers | RMB 10M + criminal | Now |
| India | Sector-specific (finance, insurance) | RBI payment data localization, SEBI governance data requirements | TBD under DPDP Rules | 2025-26 |
| UK | No | “Not materially lower” protection standard for transfers | £17.5M or 4% turnover | Now |
| Brazil | No | New SCCs effective August 2025, 48-hour breach notification | 2% revenue or R$50M | Aug 2025 |
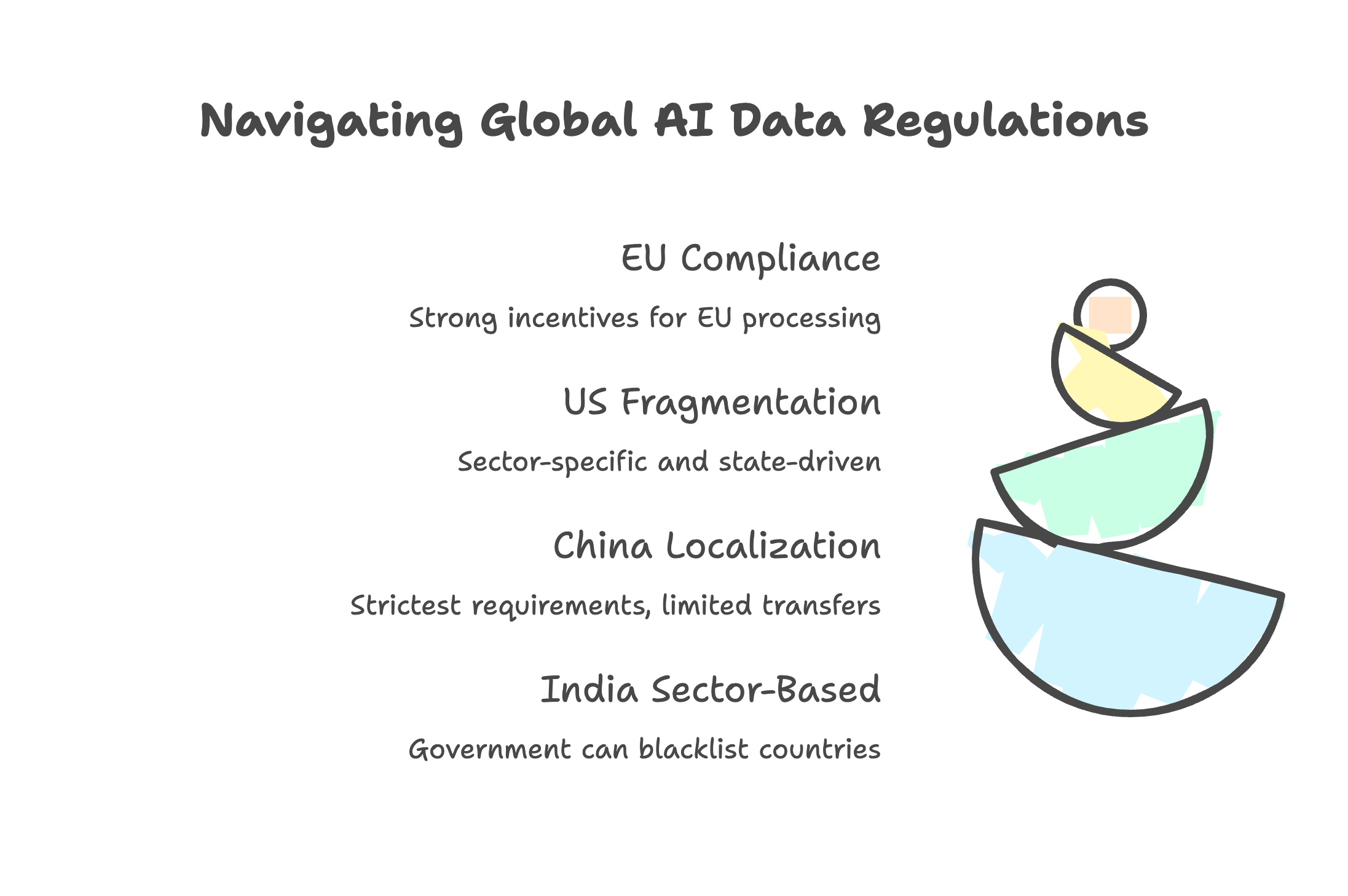
European Union: Most Complex Regulatory Stack
The EU doesn’t mandate physical data localization. But the compliance requirements create strong incentives for EU-based processing.
EU AI Act (fully applicable August 2026): High-risk AI systems require documented data governance, bias detection and correction, and datasets that reflect the specific characteristics of the deployment environment. Penalties reach 7% of global annual turnover, exceeding GDPR.
GDPR: Cross-border transfers require Standard Contractual Clauses, Binding Corporate Rules, or adequacy decisions. The EU-US Data Privacy Framework allows transfers to certified US companies, but legal challenges are expected (“Schrems III”).
Technical sovereignty: The emerging concern isn’t just where data sits but who controls the infrastructure. US CLOUD Act access to EU data stored by US companies remains legally unresolved.
United States: Fragmented State-by-State
No federal AI law exists. The landscape is sector-specific and state-driven.
Twenty states have enacted comprehensive privacy laws as of 2025: California, Virginia, Colorado, Connecticut, Texas, and fifteen others. Most focus on consumer rights and transparency rather than localization.
California CPRA: Requires disclosure of automated decision-making practices and opt-out mechanisms.
Sector-specific: HIPAA governs healthcare data. GLBA covers financial information. FedRAMP applies to government AI systems.
China: Strictest Localization Requirements
China operates a tripartite data protection regime: Cybersecurity Law, Data Security Law, and Personal Information Protection Law.
Cross-border transfer pathways (Article 38 PIPL): Organizations must choose security assessment, personal information protection certification, or standard contract with the Cyberspace Administration of China.
Critical Information Infrastructure Operators: Must localize data within China. No transfer pathway available for sensitive systems.
GenAI registration: 302 services registered as of December 2024. Mandatory content labeling and algorithmic registration required.
First enforcement action (May 2025): Shanghai authorities imposed the first administrative penalty specifically targeting unlawful cross-border transfers, establishing precedent for aggressive enforcement.
India: Sector-Based Approach
India’s DPDP Act (2023) doesn’t mandate blanket localization but allows the government to blacklist countries for data transfers.
RBI mandate: Payment system data must be stored exclusively in India. Foreign processing permitted only under strict conditions.
SEBI: Critical governance, risk, and compliance data must remain in India.
Insurance (IRDAI): Policy and claims data must be stored locally.
Real Enforcement Cases
Abstract compliance requirements become concrete when regulators issue fines. Recent enforcement shows AI-specific actions increasing.
Major GDPR and AI-Related Fines (2023-2025)
| Company | Fine | Violation |
|---|---|---|
| Meta | €1.2 billion (2023) | Transferring EU Facebook user data to US |
| TikTok | €530 million (2025) | Transferring EU citizen PII to servers in China |
| Uber | €290 million (2024) | Transferring driver data (including criminal records) to US |
| Clearview AI | €30.5 million (2024) | Multiple GDPR violations in facial recognition |
| OpenAI | €15 million (2024) | No legal basis for ChatGPT training + breach notification failure |
| €310 million (2024) | Behavioral analysis and targeted advertising violations |
Cumulative GDPR enforcement: €5.88 billion in fines since 2018. €1.2 billion in 2024 alone. 443 breach notifications per day in 2025, a 22% increase year-over-year.
Source: DLA Piper GDPR Fines Survey
The Samsung ChatGPT Incident
In May 2023, Samsung banned ChatGPT internally after employees leaked sensitive data through the tool.
Three separate incidents occurred within 20 days:
- Sensitive semiconductor source code
- Internal meeting transcripts
- Chip testing sequences
Samsung’s internal survey found 65% of employees believed generative AI tools carry security risk. The company restricted use on both company-owned and personal devices connected to internal networks.
Italy’s ChatGPT Ban
Italy became the first country to temporarily ban ChatGPT (March-April 2023) over GDPR concerns.
OpenAI had to implement:
- Explicit privacy disclosures
- Age verification mechanisms
- Data processing controls
Service was restored after approximately one month of compliance modifications. The incident established that EU regulators will take action against AI providers specifically.
For understanding what certifications actually protect, see our SOC 2 compliance analysis.
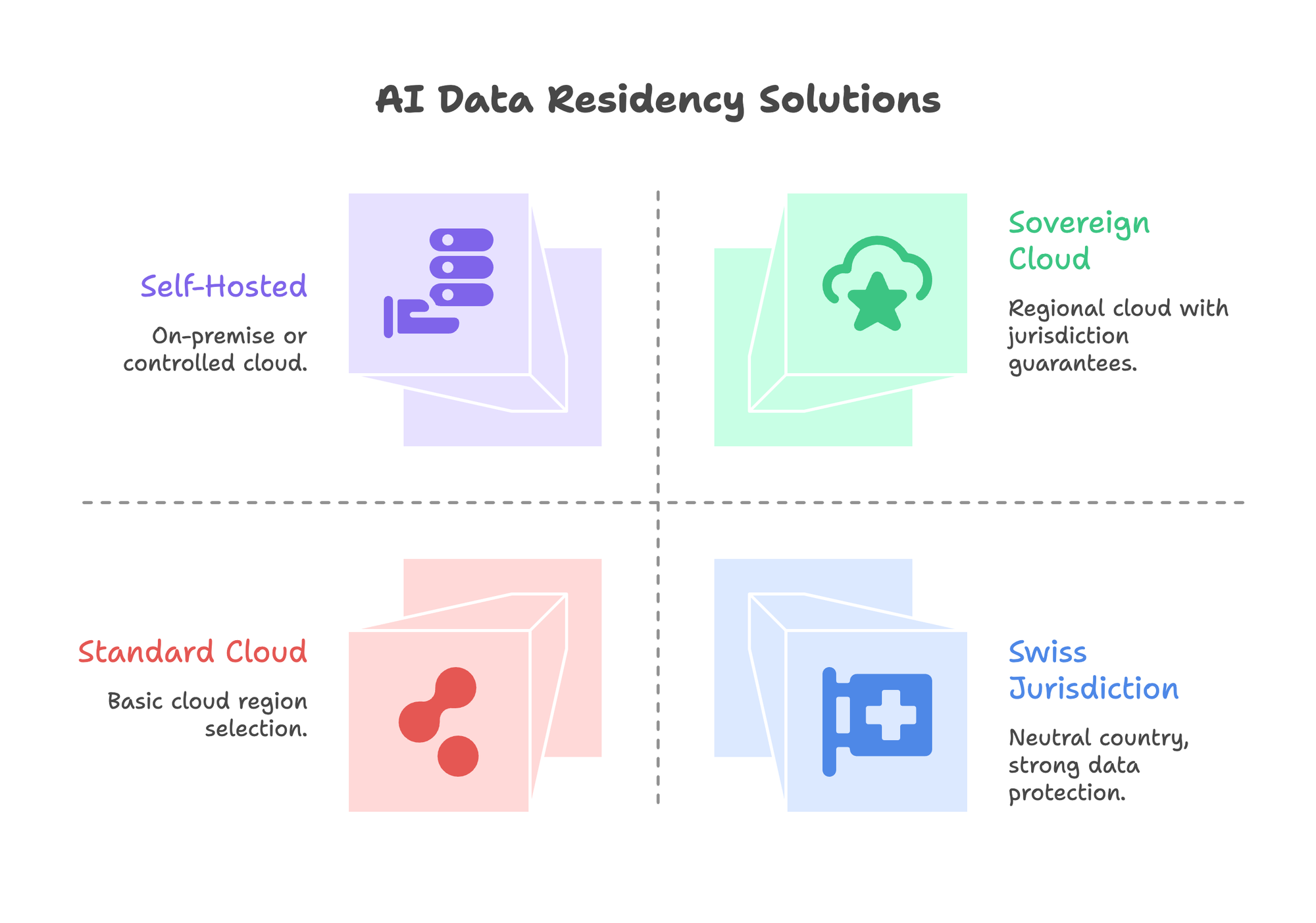
Technical Solutions for AI Data Residency
Compliance is architectural. Here are the technical approaches enterprises implement.
Solution 1: Self-Hosted LLMs
Keep everything on-premise or in controlled cloud infrastructure.
Inference engines:
- vLLM: Production workloads with strict latency SLAs (793 tokens/second, 35x throughput vs llama.cpp)
- Ollama: Prototyping and development (easy setup, good for testing)
- TensorRT-LLM: NVIDIA-optimized for maximum performance
Open-source models: Llama 3, Mistral, Qwen, Phi-3/4, Gemma 2
Economics: Break-even point around 2M tokens/day or 8,000+ conversations. Payback period typically 6-12 months. H100 spot instances run approximately $10k/year for a 7B model at 70% utilization.
For detailed setup guidance, see our self-hosted LLM guide.
Solution 2: Sovereign Cloud
Use regional cloud deployments with jurisdiction guarantees that go beyond simple region selection.
AWS European Sovereign Cloud (January 2026): German-incorporated entity (AWS European Sovereign Cloud GmbH), physically and logically separate from other AWS regions, EU-resident leadership, 90 initial services.
Microsoft Azure Sovereign: Multi-layered approach including public cloud controls, private deployments, and partner clouds (Bleu in France, Delos Cloud in Germany). EU Data Boundary ensures customer data stays in EU.
Google Distributed Cloud: Enables running Google services on customer premises or edge locations.
Critical distinction: Regional deployment from a US provider ≠ sovereignty. The US CLOUD Act still applies to US-headquartered companies regardless of data center location.
Solution 3: Confidential Computing
Process sensitive data in hardware-protected enclaves where it remains encrypted even during computation.
Technologies:
- NVIDIA H100 Confidential Computing: GPU-level secure enclaves for AI workloads
- Intel TDX: Trusted Domain Extensions for CPU-based isolation
- AMD SEV-SNP: Secure Encrypted Virtualization with strong attestation
Use cases: Multi-party AI without data sharing, protecting model weights from extraction, processing regulated data in shared infrastructure.
Market adoption: 70% of enterprise AI workloads will involve sensitive data by 2026, driving confidential computing adoption.
Solution 4: Swiss Jurisdiction
Switzerland offers structural advantages for data sovereignty.
EU adequacy status: Data flows freely between EU and Switzerland without additional safeguards.
No US intelligence-sharing agreements: Not bound to Five Eyes or similar data-sharing pacts.
Technology-neutral FADP: Switzerland’s Federal Act on Data Protection applies directly to AI without specialized legislation, providing regulatory clarity.
Political neutrality: Centuries of neutrality create stability for long-term data governance planning.
PremAI operates under Swiss FADP jurisdiction. For teams requiring guaranteed data residency without infrastructure complexity, Prem Studio provides:
- Cryptographic verification per interaction
- Data processing stays in specified regions
- Fine-tuning runs on your infrastructure, training data never transits external servers
- SOC 2, GDPR, and HIPAA compliance documentation
Grand/Advisense, serving approximately 700 European financial institutions, achieved 100% data residency compliance using this approach for automated compliance review.
Decision Framework
Match your requirements to the appropriate technical approach.
The Decision Tree
1. Is your data subject to localization mandates?
- China CIIO, India RBI, Russia personal data → Self-hosted or in-country cloud only
- No mandates → Continue to next question
2. Does US CLOUD Act access concern you?
- Yes → Non-US provider, Swiss jurisdiction, or self-hosted
- No → Regional deployment from any provider may suffice
3. Do you process more than 2M tokens per day?
- Yes → Self-hosting becomes cost-effective
- No → Managed services likely more efficient
4. Do you need verifiable audit trails for every interaction?
- Yes → Confidential computing or on-premise with logging
- No → Provider certifications may be sufficient
5. Are you in a regulated industry?
- Healthcare → HIPAA Business Associate Agreement required
- Financial services → Check DORA, PCI-DSS, SOX requirements
- Government → FedRAMP or equivalent certification
Vendor Evaluation Questions
When evaluating AI providers, ask specifically:
- Where is inference physically processed? Can I select specific regions?
- What data retention applies to prompts and completions?
- Is my data used for model training? Can I get a contractual opt-out?
- What happens to fine-tuning data after the job completes?
- Can I get zero data retention in writing with SLA backing?
- What certifications cover AI-specific processing (not just storage)?
The Action Plan
Immediate Steps
1. Audit current AI data flows. Map every touchpoint: inference APIs, embedding services, vector databases, observability platforms, fine-tuning jobs. Most organizations discover data paths they weren’t aware of.
2. Identify jurisdiction requirements. Match your data subjects to regional laws. EU residents trigger GDPR. Chinese residents trigger PIPL. Sector-specific rules (HIPAA, RBI) may impose stricter requirements.
3. Evaluate vendor contracts. Check Data Processing Agreements for AI-specific clauses. Many DPAs were written before generative AI and don’t address training data or inference residency.
4. Document data governance. EU AI Act requires documented data governance practices by August 2026. Start building this documentation now.
The Bottom Line
Data residency for AI isn’t about checking a compliance box. It’s about understanding that every API call, every fine-tuning job, and every RAG query creates data flows with regulatory implications.
The €1.2 billion fine to Meta wasn’t for a breach. It was for standard data transfers that regulators deemed non-compliant.
The enterprises handling this well aren’t choosing between capability and compliance. They’re architecting systems where data stays where it should, whether on-premise, in sovereign cloud, or with providers who guarantee residency in writing.
With EU AI Act penalties reaching 7% of global turnover and enforcement actions accelerating, the cost of getting this wrong exceeds the cost of getting it right.
Book a technical call to discuss your data residency requirements.