
Balancing LLM Costs and Performance: A Guide to Smart Deployment
Balancing LLM costs and performance requires strategies like dynamic model routing, hybrid deployment, and fine-tuning smaller models for specific tasks. Techniques such as token optimisation, caching, and leveraging open-source models help reduce expenses while maintaining efficiency.


Large Language Models (LLMs) have rapidly transitioned from experimental tools to essential components of enterprise operations. They power diverse applications—from customer service automation to content generation—driven by advances in model design and scalable cloud solutions.
The market now offers a wide range of LLMs with varying performance and costs. Popular models like OpenAI's GPT-3.5/4, Meta’s LLaMA, and other open-source alternatives each serve distinct use cases. This diversity gives companies flexibility but also complicates model selection.
High-performance models come with substantial costs. For example, GPT-4 provides superior capabilities but at significantly higher token processing fees compared to models like GPT-3.5. Businesses must carefully weigh these expenses against expected gains.
The rising operational costs of LLMs are pushing enterprises to seek smarter deployment strategies. Solutions like OptLLM enable dynamic model selection, ensuring that only tasks requiring high precision are routed to premium models.
Understanding the Costs of LLM Deployment
Deploying Large Language Models (LLMs) involves a range of costs beyond subscription fees. These include direct operational expenses and indirect costs related to customization, integration, and ongoing maintenance. Understanding these cost drivers is essential for making informed deployment decisions.
Direct Costs: Pay-Per-Token and Infrastructure
LLM providers charge based on token usage, making inference costs a significant factor. For example, OpenAI’s GPT-4 charges $0.03 per 1,000 input tokens and $0.06 per 1,000 output tokens, which is substantially higher than GPT-3.5.
Deployment Models:
- API Access: Provides ease of use and scalability but incurs variable, usage-based costs.
- In-House Deployment: Requires upfront investments in GPUs, cloud compute resources, and infrastructure but offers predictable operational costs over time.
Choosing between these models depends on workload predictability and scale.
Indirect Costs: Fine-Tuning and Integration
Customizing models to specific use cases introduces additional costs:
- Fine-Tuning: Requires substantial compute resources, high-quality datasets, and engineering time.
- Integration: Involves backend development, API integration, and security compliance efforts to align the model with existing systems.
These costs scale with the complexity of the deployment and the frequency of updates.
Operational Costs: Inference, Latency, and Scalability
Inference costs can escalate as user demand grows. Larger models consume more compute power, increasing latency and cloud costs.
- Real-Time Constraints: Applications like chatbots require low-latency responses, pushing up compute demands.
- Auto-Scaling: Handling peak loads requires dynamic scaling and load balancing, adding infrastructure complexity.
Balancing model performance with computational efficiency is crucial to controlling these costs.
Hidden Costs: Maintenance, Compliance, and Security
Hidden costs can significantly impact long-term expenses:
- Model Drift: Regular fine-tuning is necessary to maintain model relevance as data evolves.
- Regulatory Compliance: Adhering to data privacy laws (e.g., GDPR, CCPA) increases legal and operational costs.
- Security Risks: Models must be protected against adversarial attacks, misuse, and data leaks, requiring ongoing security audits.
These factors contribute to the total cost of ownership and must be planned for in any LLM deployment.
Quality vs. Cost: Is Higher Spend Justified?
Balancing the cost of deploying Large Language Models (LLMs) with the quality of their outputs is one of the most critical challenges businesses face. While premium models offer superior performance, they often come with exponentially higher costs. Understanding when these costs are justified is key to maximizing value.
Evaluating ROI in LLM Adoption
The return on investment (ROI) from LLMs depends on how effectively model performance translates into business value. High-performance models like GPT-4 may improve accuracy and user experience but come with significantly higher operational costs.
The Decision-Theoretic Model provides a framework for assessing ROI by weighing model costs against task success rates and the financial impact of outputs. This analysis helps determine if premium models are worth the investment or if more cost-effective alternatives suffice.
Diminishing Returns on Model Performance
Higher costs do not always guarantee proportionally better results. For example, GPT-4 may outperform GPT-3.5 in complex reasoning but may offer only marginal gains for simpler tasks like text classification.
Upgrading to more powerful models must be justified by measurable improvements in performance that impact key business metrics.
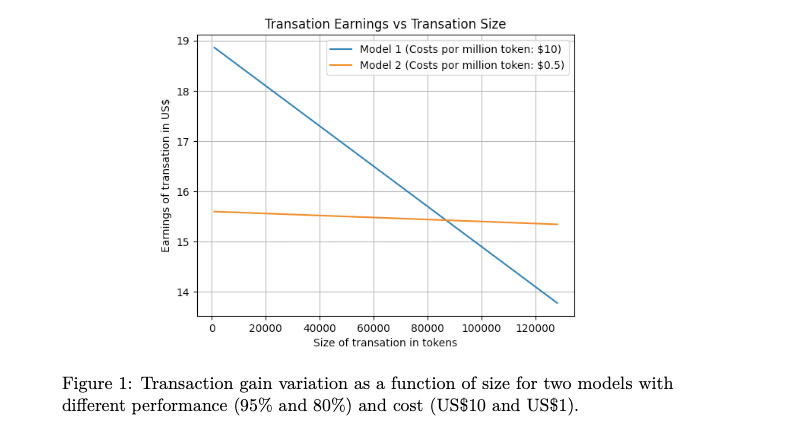
Measuring Cost-Effectiveness: The ENCS Framework
The Expected Net Cost Savings (ENCS) framework offers a way to quantify the trade-off between model cost and performance. ENCS evaluates how often a model’s output is directly useful and how much time or cost it saves.
For example, in a customer service setting, a fine-tuned GPT-2 model achieved significant cost savings despite being less advanced than GPT-3 because its responses were frequently usable with minimal editing.
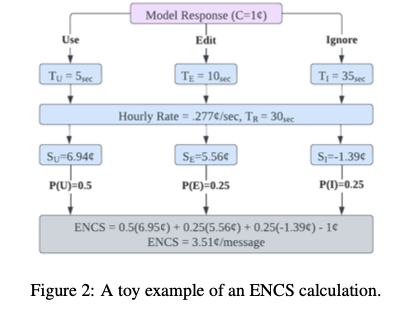
When Premium Models Are Worth It
Premium models are justified in specific scenarios where accuracy and nuance are critical, such as:
- Healthcare and Legal Analysis: Where errors can have serious consequences.
- Complex, Open-Ended Tasks: Creative content generation or complex problem-solving
- Brand Differentiation: Delivering superior customer experiences in competitive markets
For routine tasks, smaller or fine-tuned models can deliver sufficient quality at lower costs.
Balancing Cost and Quality
Companies can optimize LLM usage by:
- Dynamic Model Routing: Assigning simple tasks to lightweight models and complex tasks to advanced models.
- Hybrid Architectures: Combining models with retrieval-augmented generation (RAG) systems to reduce reliance on large models.
- Fine-Tuning Smaller Models: Customizing smaller models for specific tasks to improve efficiency.
These strategies ensure that model selection aligns with both performance needs and budget constraints.
Optimization Strategies for Cost-Efficient LLM Usage
Optimizing Large Language Model (LLM) deployment requires strategies that balance performance and cost. By implementing smarter deployment techniques, businesses can maximize ROI without sacrificing model quality.
Dynamic Model Routing
Not all tasks require premium models. Dynamic model routing assigns tasks based on complexity, sending simple queries to lightweight models and complex tasks to more powerful models.
- Simple Tasks: Handled by cost-efficient models like GPT-3.5.
- Complex Tasks: Routed to advanced models like GPT-4 when higher accuracy is critical.
Frameworks like OptLLM automate this process, reducing costs by up to 49% while maintaining performance.
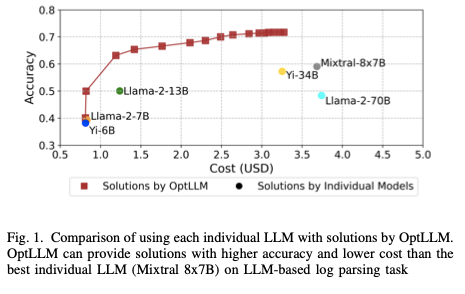
Hybrid Deployment: API Access and In-House Models
A hybrid deployment model combines cloud APIs with in-house models to optimize performance and cost.
- APIs: Flexible for handling complex, unpredictable workloads.
- In-House Models: Cost-effective for predictable, high-volume tasks.
This hybrid approach balances scalability with cost savings.
Token Optimization and Prompt Engineering
Since LLMs are billed per token, reducing token usage directly lowers costs.
- Prompt Engineering: Crafting concise, efficient prompts to minimize token count.
- Token Compression: Using preprocessing techniques to reduce input size without losing context.
Frameworks like QC-Opt apply these techniques to cut costs by up to 90% without sacrificing output quality.
Fine-Tuning Smaller Models
Fine-tuning smaller models on domain-specific data can provide high performance at lower costs.
- Task-Specific Training: Fine-tuned models outperform general-purpose models in specialized tasks.
- Knowledge Distillation: Compressing larger models into smaller, more efficient versions without significant performance loss.
This strategy reduces computational demands while maintaining accuracy.
Caching and Response Reuse
For repetitive queries, caching frequently used responses minimizes redundant computations.
- Static Caching: Stores common responses for instant retrieval.
- Partial Caching: Reuses parts of responses for similar queries.
This approach is especially effective in customer service and FAQ systems.
Leveraging Open-Source Models
Open-source models like LLaMA and Mistral provide cost-effective alternatives to proprietary solutions.
- Cost Savings: No per-token fees and full control over customization.
- Flexibility: Models can be fine-tuned and deployed in-house to match business needs.
This reduces reliance on expensive API-based models.
Hidden Costs in LLM Deployments
Beyond direct expenses like model licensing and infrastructure, deploying Large Language Models (LLMs) comes with hidden costs that can significantly impact total spending. Understanding these factors is critical for effective cost management.
Maintenance and Model Degradation
LLMs require ongoing maintenance to remain effective. Without regular updates, models suffer from model drift, where their outputs become less accurate as data and user behavior change.
- Frequent Updates: Regular fine-tuning and retraining are necessary to maintain relevance.
- Technical Debt: Poor maintenance leads to degraded performance and higher operational costs.
Neglecting maintenance can erode model performance, increasing the need for costly interventions.
Compliance and Data Privacy
Compliance with data regulations (e.g., GDPR, CCPA) introduces additional legal and operational costs. Companies must invest in secure data handling, encryption, and auditing.
- Data Sovereignty: Managing global data residency laws adds complexity.
- Security Audits: Ongoing security checks are required to prevent data breaches.
Non-compliance risks legal penalties and reputational damage.
Latency and Performance Penalties
High model latency can degrade user experience and increase costs.
- Infrastructure Overprovisioning: To reduce latency, companies often overinvest in compute resources.
- User Churn: Slow responses in real-time applications can lead to lost customers and revenue.
Balancing performance with infrastructure costs is critical for high-traffic applications.
Vendor Lock-In and Switching Costs
Relying on proprietary APIs can create vendor lock-in, limiting flexibility and driving up costs.
- Pricing Risks: Vendors can change pricing models or service terms unexpectedly.
- Migration Costs: Switching providers requires costly re-engineering and retraining of models.
Diversifying model providers mitigates these risks.
Integration and Customization Overheads
Integrating LLMs into existing systems can be resource-intensive. Fine-tuning, API integration, and adapting workflows to support LLM outputs require significant engineering effort.
- Integration Costs: Backend development and security updates add to deployment expenses.
- Continuous Adaptation: Regular model updates demand ongoing adjustments.
These efforts can delay deployment and inflate total costs.
Monitoring and Incident Response
Production-grade LLMs need constant monitoring to detect performance issues, security threats, and system failures.
- Monitoring Tools: Investing in tools for real-time monitoring and anomaly detection.
- Incident Response: Addressing outages or failures leads to downtime and lost revenue.
Without proactive monitoring, small issues can escalate into costly disruptions.
Strategies to Maximize ROI in LLM Implementations
Maximizing the return on investment (ROI) from Large Language Models (LLMs) requires more than choosing the most powerful model. It demands strategic deployment, cost optimization, and continuous performance evaluation to ensure models deliver value efficiently.
Dynamic Model Routing
Dynamic model routing optimizes costs by assigning tasks to models based on complexity. Lightweight models handle simple queries, while high-performance models are reserved for complex tasks.
- Routine Tasks → Smaller, cheaper models (e.g., GPT-3.5).
- Complex Tasks → Advanced models (e.g., GPT-4) for high-stakes outputs.
Tools like OptLLM automate this process, balancing performance and cost.
Hybrid Deployment Models
Combining API access and in-house deployment creates a scalable, cost-effective solution.
- Cloud APIs: Used for unpredictable, high-complexity workloads.
- In-House Models: Deployed for routine, high-volume tasks to lower recurring costs.
This hybrid strategy provides both flexibility and cost stability.
Fine-Tuning Smaller Models
Fine-tuning smaller, open-source models on domain-specific datasets can reduce reliance on larger, costlier models.
- Task-Specific Models: Smaller models trained for specific use cases can match or outperform larger models in niche applications.
- Knowledge Distillation: Compresses larger models into smaller, more efficient versions without sacrificing performance.
This approach improves performance while cutting operational costs.
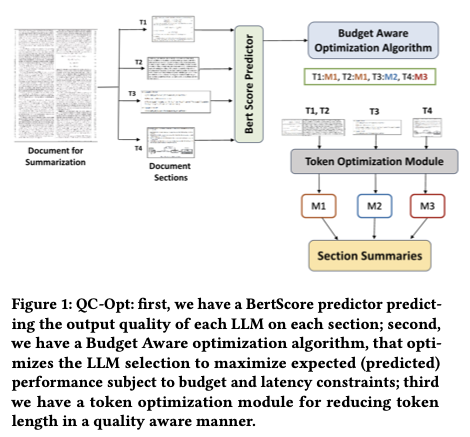
Token and Prompt Optimization
Optimizing input prompts reduces token usage, directly lowering costs.
- Concise Prompts: Reduces token count without sacrificing context.
- Retrieval-Augmented Generation (RAG): Supplies models with external data to minimize prompt length.
Frameworks like QC-Opt implement token optimization to cut costs by up to 90%.
Caching and Response Reuse
Implementing caching for frequently asked questions or repetitive queries reduces redundant processing.
- Static Caching: Stores common responses for instant retrieval.
- Partial Caching: Reuses segments of responses across similar queries.
This strategy reduces inference costs, especially in customer support applications.
Multi-Model and Multi-Provider Strategies
Diversifying across multiple models and providers prevents vendor lock-in and improves cost efficiency.
- Model Diversity: Using different models for different tasks optimizes performance and cost.
- Provider Flexibility: Prevents over-reliance on a single vendor and mitigates pricing risks.
This approach ensures adaptability in a changing market.
Incremental Deployment and Scaling
Phased deployment allows businesses to scale LLM use gradually and validate ROI before full-scale rollout.
- Pilot Programs: Test models in non-critical workflows.
- Gradual Scaling: Expand to core operations after validating performance.
- Full Integration: Scale models organization-wide for long-term growth.
This reduces risk and prevents overspending on unproven solutions.
Key Trends Shaping the Future of LLM Economics
The future of Large Language Models (LLMs) will be shaped by innovations aimed at improving cost-efficiency and performance. Understanding these trends is crucial for businesses to stay competitive and maximize the value of their AI investments.
Shift Toward Smaller, Specialized Models
Smaller, fine-tuned models are emerging as cost-effective alternatives to massive general-purpose LLMs. These models deliver high performance on specific tasks while requiring fewer resources.
- Domain-Specific Models: Tailored for industry-specific tasks.
- Lower Inference Costs: Reduced compute requirements improve scalability.
Growth of Open-Source LLMs
Open-source models like LLaMA and Mistral offer flexibility and significant cost savings over proprietary models.
- Customization: Full control over model training and deployment.
- Cost Savings: No per-token fees and vendor independence.
Advancements in Optimization Techniques
Emerging optimization methods are making LLMs more efficient:
- Model Pruning and Quantization: Reducing model size without losing accuracy.
- Knowledge Distillation: Compressing large models into smaller, faster ones.
These techniques lower infrastructure costs and speed up inference.
Sustainability and Energy Efficiency
Environmental concerns are driving the development of energy-efficient models. Reducing the carbon footprint of AI operations is becoming both a regulatory and business priority.
- Energy-Efficient Architectures: Less power-hungry models.
- Green Data Centers: Providers shifting to renewable energy sources.
Monetization of Custom AI Models
Companies are turning proprietary models into revenue streams through licensing and AI-as-a-service models.
- Model Licensing: Offering fine-tuned models to other organizations.
- Data Monetization: Leveraging proprietary data for commercial AI products