Breaking the Pareto Frontier with Prem AI MiniGuard-v0.1
MiniGuard-v0.1 compresses 8B-model safety performance into 0.6B parameters, delivering 99.5% accuracy with 2.5× faster speed and 67% lower cost. Learn how PremAI advances efficient, production-ready AI safety.

Today, we're releasing MiniGuard-v0.1, a 0.6B parameter safety classifier that matches NVIDIA's Nemotron-Guard-8B at 99.5% benchmark accuracy.
13x smaller. 2.5x faster. 67% cheaper to serve.
Model: huggingface.co/prem-research/MiniGuard-v0.1
The Problem With Large Guard Models
The current generation of safety classifiers (Llama Guard, Aegis Guard, Nemotron Guard) are good at their job. Nemotron-8B achieves strong accuracy across diverse safety categories, from harmful instructions to sexual content to discrimination. However, the “8B” in its name reflects substantial underlying complexity. At 8B parameters, you're adding real infrastructure cost and latency to every request.
For applications where safety classification sits in the critical path (chatbots, content generation, agentic workflows) this creates a tax. Not on correctness, but on experience. Users wait longer. Costs go up. And teams start making compromises they'd rather not make.
What If the Problem Is Just Data?
The conventional wisdom is that safety classification is hard because it requires understanding context, intent, and nuance. A message containing "kill" could be a threat, a video game discussion, or cooking instructions. Distinguishing between them seems like it should require a large model with broad world knowledge.
But when we looked at where vast models actually outperformed small ones, we found something interesting. It wasn't general reasoning. It was specific patterns. Trigger words that look dangerous out of context. Edge cases where phrasing matters. Categories where the training data was sparse.
This suggested a different approach. What if we could teach a small model exactly what a large model knows about these specific hard cases, without trying to transfer general language understanding?
Building MiniGuard
MiniGuard-v0.1 is trained using four techniques, each targeting a specific gap between small and large model performance.
Targeted synthetic data. We identified trigger words that cause false positives. Terms like "kill," "shoot," "hot," "destroy" that appear in both harmful and benign contexts. Then we generated training examples specifically around these patterns. The goal wasn't more data, but the right data. Examples that teach the model when "shoot the photo" is different from "shoot the target."
Step-by-step distillation. Rather than just training on Nemotron's final classifications, we trained on its reasoning process. When the teacher model works through why a message is or isn't harmful, that reasoning becomes supervision for the student. This transfers the decision-making logic, not just the outputs.
Model soup. We trained MiniGuard and averaged the weights of the top 3 checkpoints from the same training run. This reduces variance and produces a more robust final model than any single checkpoint.
FP8 quantization. The final model runs in 8-bit precision with minimal accuracy loss. This cuts memory footprint and inference cost further.
The Results
On the Nemotron-Safety-Guard benchmark (nvidia/Nemotron-Safety-Guard-Dataset-v3, English test split), MiniGuard achieves 0.893 Macro F1. Nemotron-Guard-8B achieves 0.897 Macro F1.
99.5% of the accuracy at 1/13th the size.
| Model | Macro F1 | Parameters |
|---|---|---|
| Nemotron-Guard-8B-v3 | 0.897 | 8B |
| MiniGuard-v0.1 | 0.893 | 0.6B |
| LLaMA-3.1-8B | 0.837 | 8B |
| LLaMA-3.2-3B | 0.813 | 3B |
At typical production concurrency (1-8 requests), MiniGuard is 2-2.5x faster than Nemotron. P95 latency at c=1: 67ms vs 165ms.
On older, cheaper hardware like L40S, MiniGuard is 4-5x faster while maintaining low latency.
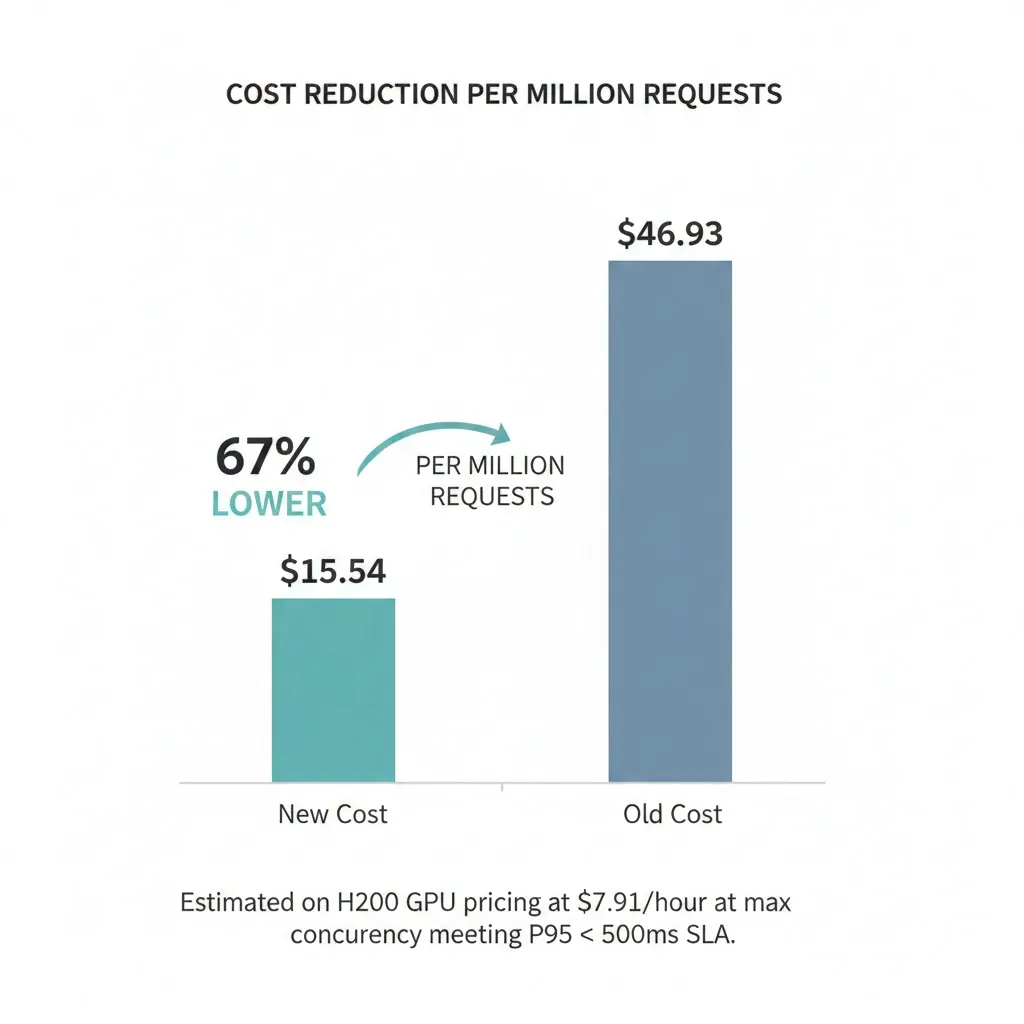
Production Data
We also tested MiniGuard on out-of-distribution production data with edge cases not seen during training.
| Model | Parameters | Rel. Macro F1 | Cost per 1M requests | Cost Savings |
|---|---|---|---|---|
| MiniGuard-v0.1 | 0.6B | 91.1% | $15.54 | 67% |
| Nemotron-Guard-8B-v3 | 8B | 100% | $46.93 | baseline |
MiniGuard retains 91.1% of Nemotron's performance on production traffic while costing 67% less to serve.
Ablation Studies
We progressively applied each technique to Qwen3-0.6B and measured impact:
| Training Configuration | Macro F1 | Δ Macro F1 |
|---|---|---|
| Qwen3-0.6B (base) | 52.5 | baseline |
| + Vanilla SFT | 85.0 | +32.5 |
| + Think SFT (distillation) | 88.6 | +3.6 |
| + Targeted synthetic data | 89.3 | +0.7 |
| + Top-3 Model Soup | 89.2 | -0.1 |
| + FP8 Quantization | 89.3 | +0.1 |
On production data, the story changes. Targeted synthetic data and model soup combine for +5.5 points in relative Macro F1. That's the gap between a model that works in the lab and one that works in production.
What It Means
MiniGuard was evaluated on English data for chat safety classification.
On benchmarks, it matches Nemotron almost exactly (99.5% of its accuracy) despite being 13x smaller. On real production traffic, it held up well: 91.1% relative Macro F1 compared to Nemotron's baseline. It also costs 67% less to serve and runs 2.5x faster at typical loads.
The techniques we used (targeted synthetic data, distillation from reasoning traces, model soup, FP8 quantization) aren't safety-specific. We used them to compress what an 8B model knows into 0.6B parameters. If you have a large model doing a narrow task well, the same approach should work.
Conclusion
MiniGuard-v0.1 demonstrates that safety classification doesn’t require massive models to be effective. By applying targeted synthetic data, reasoning-based distillation, model soup, and FP8 quantization, PremAI compressed an 8B-parameter safety model into just 0.6B parameters, while retaining 99.5% of its accuracy. The result is a safety classifier that is dramatically faster, more affordable, and production-ready without sacrificing reliability.
For teams building chatbots, agents, or any system where safety checks sit in the critical path, MiniGuard removes the latency and cost barriers of large guard models. It delivers enterprise-grade performance at a fraction of the infrastructure footprint.
MiniGuard-v0.1 is open-source and ready to use. If you're scaling LLM workloads and want safer, faster, and more economical infrastructure, PremAI is here to help accelerate your path to production.
FAQs
1. What is MiniGuard-v0.1?
MiniGuard-v0.1 is a 0.6B-parameter safety classifier from PremAI that matches Nemotron-Guard-8B accuracy while being faster, lighter, and cheaper to run.
2. How accurate is MiniGuard compared to Nemotron-Guard-8B?
MiniGuard achieves 99.5% of Nemotron’s benchmark accuracy, delivering 0.893 Macro F1 versus Nemotron’s 0.897.
3. Why is MiniGuard cheaper to serve?
Its smaller size allows FP8 quantization, lower GPU memory usage, and higher throughput—resulting in 67% lower serving costs per million requests.
4. What makes MiniGuard fast in production?
MiniGuard is 2–2.5× faster at typical concurrency and up to 5× faster on older GPUs, thanks to model compression and optimized training techniques.
5. How was MiniGuard trained?
PremAI used targeted synthetic data, reasoning-based distillation, model soup, and FP8 quantization to close the gap between 8B and 0.6B models.
6. Can MiniGuard replace Nemotron Guard?
Yes, MiniGuard is a drop-in replacement with the same prompt template and output format, but dramatically lower latency and cost.
7. Does MiniGuard work on real production traffic?
Yes. MiniGuard retained 91.1% of Nemotron’s performance on OOD production data while being significantly cheaper and faster.
Try It
MiniGuard-v0.1 is available now under MIT license. It's a drop-in replacement for Nemotron Guard. Same prompt template, same output format.
vllm serve prem-research/MiniGuard-v0.1 --async-scheduling -q=fp8
The model card and weights are on Hugging Face. The full technical report has the ablation studies and benchmark details.
MiniGuard is built by the research team at Prem. We're working on making AI infrastructure safer, secure and more accessible. If you're building with LLMs and running into cost or latency walls, we'd love to talk.