Chunking Strategies in Retrieval-Augmented Generation (RAG) Systems
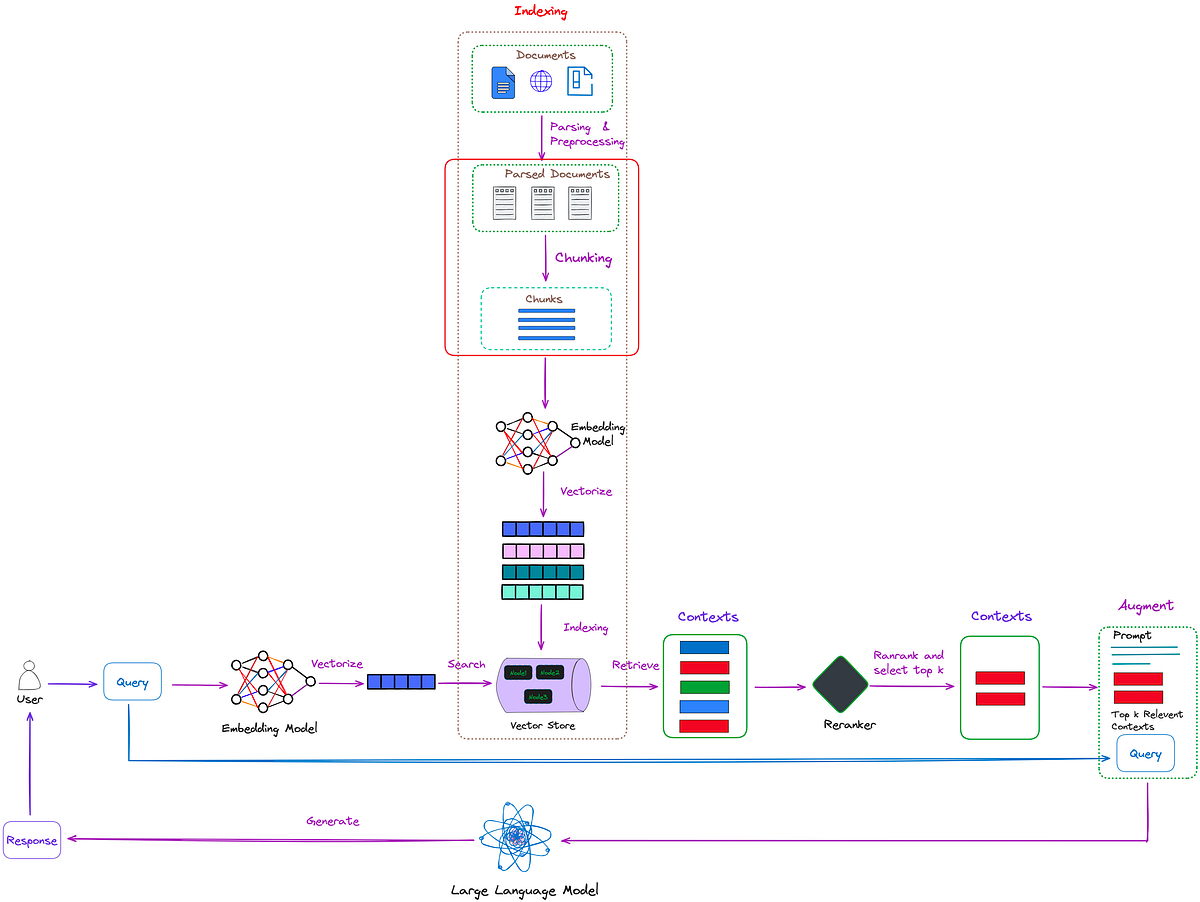
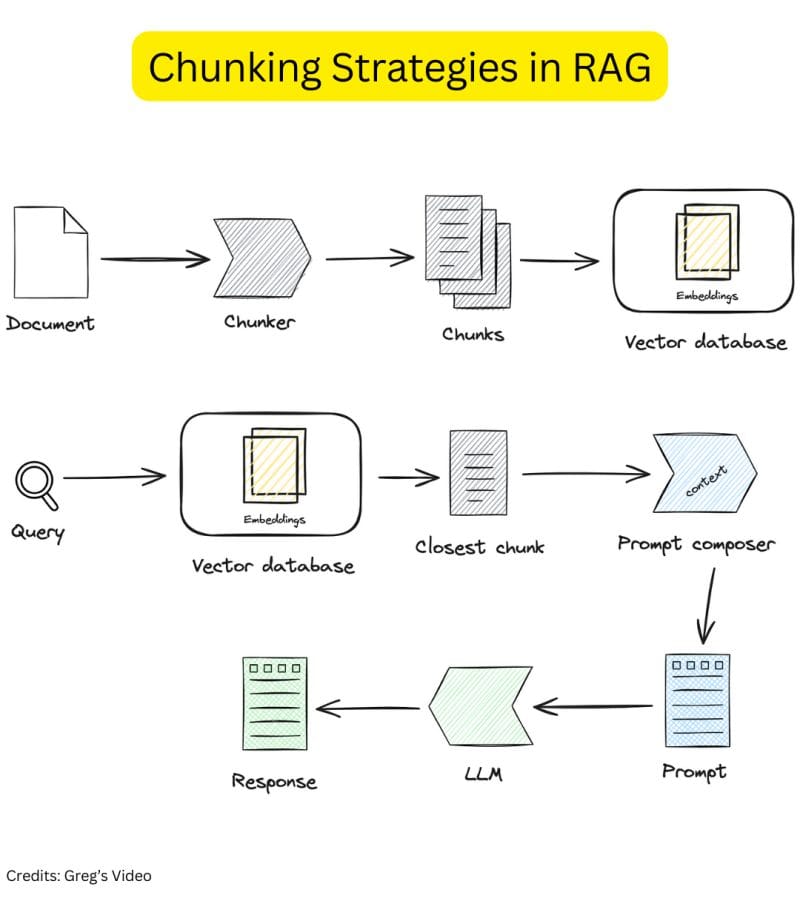
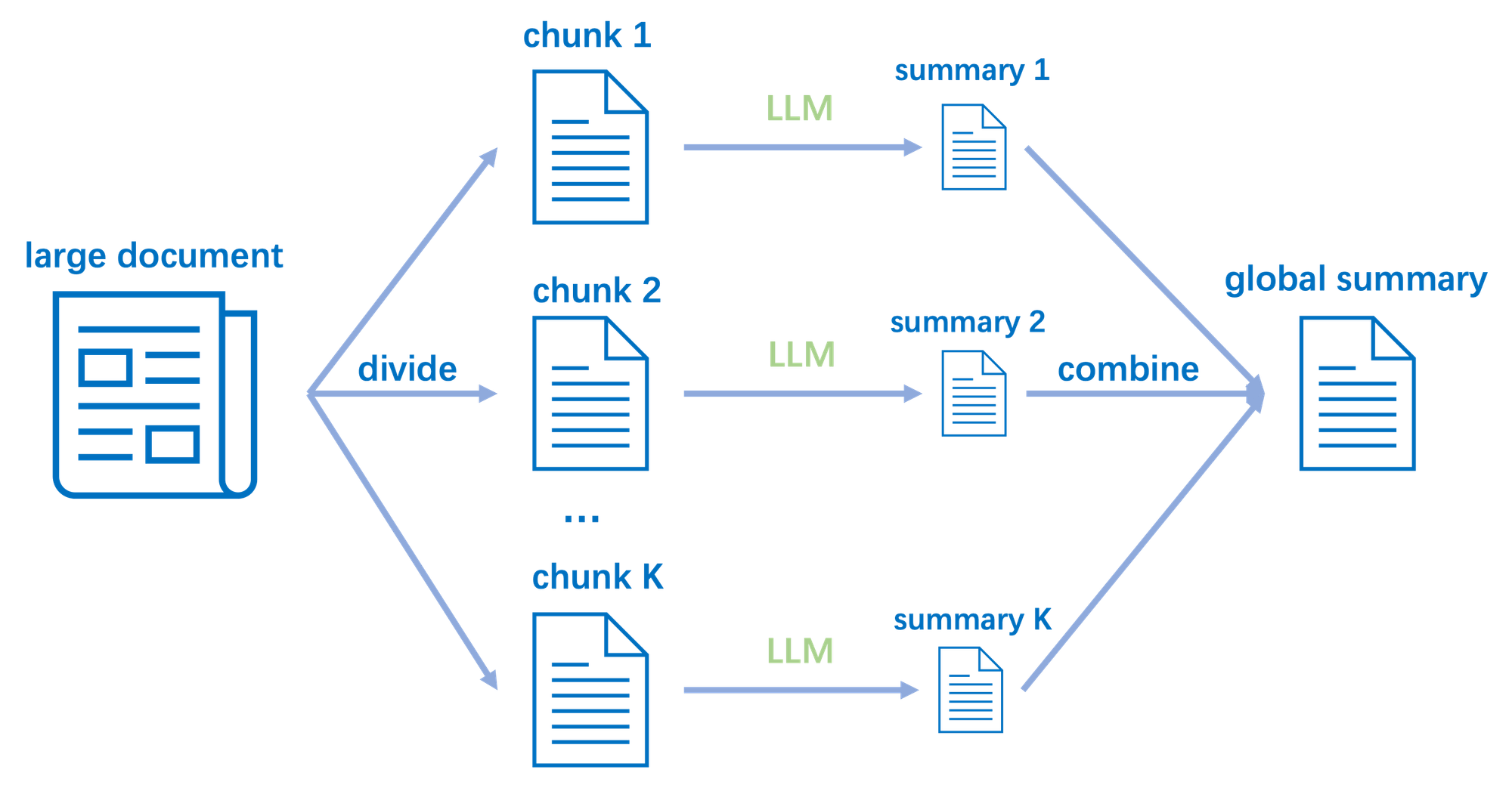
Chunking enhances Retrieval-Augmented Generation (RAG) by splitting large texts into manageable parts for efficient processing in language models. This technique supports accurate responses, maintains context, and enables fast, parallel processing.


Chunking plays a crucial role in Retrieval-Augmented Generation (RAG) systems, where it helps optimize the process of extracting relevant information from vast datasets. When working with large language models (LLMs), chunking is essential for dividing massive bodies of text into smaller, manageable segments that can be processed efficiently without losing the context.
In RAG systems, the aim is not only to retrieve information but also to generate coherent, contextually accurate responses. However, large documents can pose challenges for language models due to token limitations and context windows. By dividing documents into chunks, we ensure that the system maintains coherence and relevance across the segments, allowing for more accurate and contextually rich outputs.

Understanding How Transformers Process Tokens in RAG
Large Language Models (LLMs), such as GPT-4, GPT-3.5, and Llama, are designed to process input sequences token by token. However, one of the core limitations of these models is handling long context lengths. A typical context length range in which LLMs perform well in terms of accuracy and speed is between 2048 to 4096 tokens. Beyond this limit, it becomes challenging for LLMs to maintain similar performance levels.
These models have strict token limitations, with smaller models typically handling up to 4096 tokens, while more advanced models are capable of processing up to 32,000 tokens. Without proper chunking, LLMs might discard important parts of a document, leading to a reduction in the quality of generated responses. For example, legal or financial documents are often far longer than these token limits, making chunking essential for accurate information retrieval.
Chunking also plays a significant role in reducing latency by enabling parallel processing of smaller segments. This speeds up retrieval in real-time applications, such as customer support chatbots and automated assistants, where fast response times are critical. When done correctly, chunking can also improve the memory footprint, making RAG systems more scalable for production-grade use.
Mastering Core Chunking Strategies for RAG Systems
In Retrieval-Augmented Generation (RAG) systems, chunking strategies can make or break the efficiency of your model's retrieval and generation processes. Let's dive into the most common chunking methods that developers can leverage for RAG applications:
Fixed Size Chunking
One of the simplest chunking methods. In this approach, the text is divided into fixed-size chunks based on character count, without considering sentence boundaries or semantic meaning. It’s ideal for uniformly structured content but risks breaking up the context in the middle of sentences or paragraphs.
Example:
from langchain.text_splitter import CharacterTextSplitter
def fixed_size_chunking(text: str, chunk_size: int = 450, chunk_overlap: int = 50):
"""
Splits text into fixed-size chunks based on character count.
Args:
text (str): The text to be chunked.
chunk_size (int): The size of each chunk in characters.
chunk_overlap (int): The number of overlapping characters between chunks.
Returns:
list: A list of text chunks.
"""
text_splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = text_splitter.split_text(text)
return chunks
def main():
markdown_text = "This is a longer document to chunk. " * 20 # Example repeated text to simulate a long document
chunks = fixed_size_chunking(markdown_text)
for idx, chunk in enumerate(chunks, start=1):
print(f"--- Chunk {idx} ---")
print(chunk)
print()
if __name__ == "__main__":
main()
Reference: "Simple Chunking Strategies for RAG Applications"
This method works well in cases where the chunk size is more important than the context, such as in large data analysis of genetic sequences or standardized datasets like surveys. However, it may not be suitable for tasks that require preserving the flow of meaning, such as legal analysis or customer support.
Pros:
- Simple Implementation: Easy to implement without the need for advanced processing.
- Versatile: Handles various types of data with minimal computational requirements.
- No Dependencies: Does not require any ML model or specific language considerations.
Cons:
- Context Loss: May break up sentences or paragraphs, leading to a loss of semantic context.
- Lack of Flexibility: Ineffective when dealing with varied text structures, leading to inaccurate results for complex documents.
- Redundancy: Fixed chunks may end up containing redundant information, especially with overlapping segments.
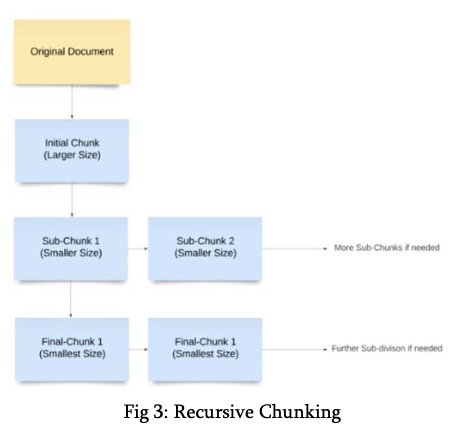
Recursive Chunking
Recursive Chunking provides a more adaptive solution than fixed-size chunking. It operates by splitting text using multiple separators (e.g., paragraph breaks, sentences) in a hierarchical manner until an optimal chunk size is reached. Recursive chunking ensures that even when the text is fragmented, the semantic relationships between chunks remain intact.
```python
from langchain.text_splitter import CharacterTextSplitter
def fixed_size_chunking(text: str, chunk_size: int = 450, chunk_overlap: int = 50):
"""
Splits text into fixed-size chunks based on character count.
Args:
text (str): The text to be chunked.
chunk_size (int): The size of each chunk in characters.
chunk_overlap (int): The number of overlapping characters between chunks.
Returns:
list: A list of text chunks.
"""
text_splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = text_splitter.split_text(text)
return chunks
def main():
markdown_text = "This is a longer document to chunk. " * 20 # Example repeated text
chunks = fixed_size_chunking(markdown_text)
for idx, chunk in enumerate(chunks, start=1):
print(f"--- Chunk {idx} ---")
print(chunk)
print()
if __name__ == "__main__":
main()
```
- Pros:
- Versatile: Handles various separators like paragraphs or sentences.
- Flexible for Different Data Types: Works well for both text and code by adapting to different content structures.
- Maintains Context: Maintains a balance between chunk size and context preservation, reducing fragmentation.
- Cons:
- Increased Complexity: Recursive nature can add computational overhead, especially when dealing with large documents.
- Parameter Tuning: Requires parameter tuning to decide on separator hierarchies for optimal chunking.
- Sentence Interruption: May still cut sentences or paragraphs if not tuned properly, causing semantic loss.
Document-Based Chunking
Document-Based Chunking leverages the inherent structure of documents. Instead of splitting based purely on size, this method takes into account logical divisions like headings, lists, or sections. It ensures that chunks retain coherence, especially in documents with complex formatting (e.g., markdown, tables, or code).
Example (MarkdownTextSplitter using Langchain):
from langchain.text_splitter import MarkdownTextSplitter
from langchain.docstore.document import Document
def document_based_chunking(markdown_text: str, chunk_size: int = 400, chunk_overlap: int = 50) -> list[Document]:
"""
Splits markdown text into chunks based on document structure.
Args:
markdown_text (str): The markdown content to split.
chunk_size (int): The maximum size of each chunk.
chunk_overlap (int): The number of overlapping characters between chunks.
Returns:
list[Document]: A list of Document objects representing the chunks.
"""
splitter = MarkdownTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = splitter.create_documents([markdown_text])
return chunks
def display_chunks(chunks: list[Document]):
"""
Displays the content of each chunk.
Args:
chunks (list): A list of Document objects.
"""
for idx, chunk in enumerate(chunks, start=1):
print(f"--- Chunk {idx} ---")
print(chunk.page_content)
print()
def main():
markdown_text = """
# Introduction
This is the introduction section of the document. It provides an overview of the main topics discussed.
## Background
The background section delves into the history and foundational concepts relevant to the subject matter.
### Detailed Analysis
Here, we perform a detailed analysis of the key components, breaking down complex ideas into understandable parts.
## Conclusion
The conclusion summarizes the findings and provides final thoughts on the discussed topics.
"""
chunks = document_based_chunking(markdown_text)
display_chunks(chunks)
if __name__ == "__main__":
main()
This method is particularly useful when working with highly structured content, such as technical manuals or research papers.
Pros:
- Preserves Structure: Takes advantage of document structure (e.g., headings, sections) to create coherent chunks.
- Retains Logical Flow: Keeps logical groupings, making it ideal for structured documents such as research papers and technical manuals.
- Customizable: Allows parameter customization (e.g., chunk size and overlap) for different document types.
Cons:
- Limited to Structured Documents: Not effective for unstructured text without a clear document hierarchy.
- Potential Redundancy: May create chunks with overlapping information, leading to inefficiency.
- Requires Preprocessing: For documents without an inherent structure, preprocessing may be required to determine chunking boundaries.
Semantic Chunking
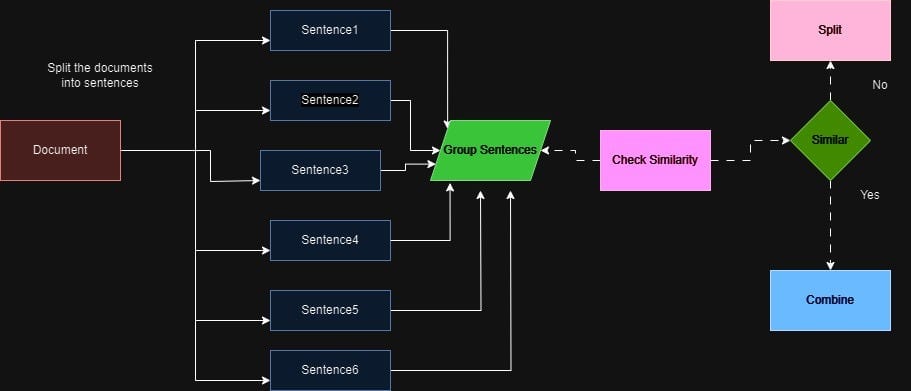
Semantic Chunking uses embeddings to group text based on semantic similarity. This method ensures that chunks maintain context and meaning, making it ideal for tasks where preserving content relationships is crucial.
Example (using Langchain):
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings # Replace with your embedding model
from langchain.docstore.document import Document
def semantic_chunking(text: str, embed_model, chunk_size: int = 500, chunk_overlap: int = 100):
"""
Splits text into semantically meaningful chunks using embeddings.
Args:
text (str): The text to be chunked.
embed_model: The embedding model to use for semantic similarity.
chunk_size (int): The maximum size of each chunk.
chunk_overlap (int): The number of overlapping characters between chunks.
Returns:
list[Document]: A list of Document objects representing the semantic chunks.
"""
splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = splitter.create_documents([text])
# Placeholder for additional semantic clustering logic
embeddings = embed_model.embed_documents([chunk.page_content for chunk in chunks])
# Add semantic clustering using embeddings if necessary
return chunks
def main():
markdown_text = """
# Overview
Semantic chunking leverages embeddings to ensure that each chunk maintains contextual and semantic integrity. This approach is particularly useful for applications requiring high relevance and coherence in information retrieval.
## Applications
- **Customer Service:** Enhances chatbot responses by maintaining context across interactions.
- **Academic Research:** Assists in organizing and retrieving research papers based on thematic similarity.
- **Content Management:** Facilitates efficient content tagging and categorization for large datasets.
"""
# Initialize your embedding model (replace with actual model initialization)
embed_model = OpenAIEmbeddings(api_key="your-openai-api-key")
semantic_chunks = semantic_chunking(markdown_text, embed_model)
for idx, chunk in enumerate(semantic_chunks, start=1):
print(f"--- Semantic Chunk {idx} ---")
print(chunk.page_content)
print()
if __name__ == "__main__":
main()
"Simple Chunking Strategies for RAG Applications"
Semantic chunking is ideal for complex systems, such as customer service chatbots or academic research tools, where maintaining the meaning across chunks is more important than preserving the document's original structure.
- Pros:
- Contextual Grouping: Organizes text based on semantic similarity, ensuring meaningful and contextually relevant chunks.
- Handles Overlap: Effective in managing chunk size and overlap without compromising on content quality.
- Application Versatility: Particularly useful for chat-based applications, customer support systems, and content recommendation.
- Cons:
- Complexity: Requires embedding models for clustering and semantic understanding.
- Model Dependency: Relies on pre-trained embedding models for meaningful chunk generation.
- Computational Resources: Demands more computational power due to the embedding and similarity evaluation process.
How to Select the Optimal Chunking Strategy for RAG Applications
When building or optimizing Retrieval-Augmented Generation (RAG) systems, selecting the right chunking strategy is crucial to balancing performance, accuracy, and efficiency. In this section, we will examine how developers can choose the most suitable chunking strategy by considering three main factors: model compatibility, task specificity, and system constraints.
Model Compatibility
The chunking strategy must align with the token limitations and processing capabilities of the model you are using. For example, large language models (LLMs) like GPT-4 can handle up to 32,000 tokens, allowing them to process larger chunks of text without losing context. Conversely, smaller models like BERT are optimized for shorter chunks, typically under 512 tokens. Understanding these limitations is essential because exceeding token limits leads to truncation, which can degrade the quality of both retrieval and generation.
- Recommendation: For large models such as GPT-4, it is often advisable to use larger chunks (1,500 to 2,500 tokens) to minimize the number of retrieval calls and reduce processing time. However, these larger chunks must still preserve the semantic integrity of the text to avoid generating irrelevant outputs.
Task Specificity
The nature of the task directly influences the chunking strategy. Tasks that involve precise information retrieval, such as legal document analysis or fact-checking, require smaller chunks to improve granularity and retrieval accuracy. In contrast, tasks that need broader context, such as summarization or content generation, perform better with larger chunks that retain more information from the source material.
For instance, chunking based on sentence boundaries is particularly effective when processing highly structured text, as it ensures that each chunk remains semantically meaningful. This method avoids breaking up sentences, which could lead to fragmented and less coherent outputs.
- Recommendation: For information retrieval tasks, smaller chunks (250-512 tokens) should be employed to enhance search precision. For summarization or content generation tasks, larger chunks of 1,000-2,000 tokens can preserve broader context.
System Constraints
The computational limitations of the system where your RAG model is deployed also impact the chunking strategy. Systems with limited memory or processing power benefit from smaller chunks, which reduce the load on both the retriever and the language model. However, smaller chunks may increase the number of API calls, raising costs and introducing latency.
Conversely, systems with more robust resources can afford to process larger chunks, reducing the number of retrieval operations. However, larger chunks can introduce noise, especially when irrelevant sections of a document are included in the retrieval process.
- Recommendation: Balance chunk size based on system capacity. On constrained systems, smaller chunks (250-500 tokens) reduce the memory footprint but may increase retrieval costs. On high-performance systems, larger chunks (1,500-2,000 tokens) improve efficiency while maintaining contextual relevance.
Advanced Techniques for Chunking Optimisation
There are advanced methods to fine-tune the chunking process for RAG systems, including metadata attachment and adaptive chunking.
- Metadata Attachment: Adding metadata like document titles, timestamps, or author information to each chunk helps optimize retrieval. This metadata can serve as additional filters during retrieval, improving the relevancy of the retrieved information.
- Adaptive Chunking: In dynamic environments, adaptive chunking strategies can be implemented to adjust chunk sizes based on the model’s response during generation. For example, self-reflection mechanisms, like those used in Self-RAG, allow the model to adjust its chunking strategy on the fly, improving performance in complex or ambiguous tasks.
By understanding these factors and applying advanced chunking techniques, developers can significantly enhance the performance of RAG systems across a variety of tasks.
Best Practices for Implementing Chunking Strategies in RAG Systems
When implementing chunking strategies for Retrieval-Augmented Generation (RAG) systems, it's essential to follow best practices to ensure both efficiency and accuracy. The right chunking strategy enhances retrieval performance, preserves context, and avoids common pitfalls like over-chunking or under-chunking. Below are best practices that developers can use when working with chunking strategies in production-grade systems.
Optimizing Chunk Size and Overlap
Chunk Size: Choosing the right chunk size is crucial for maintaining the context within each chunk while also staying within the model's token limitations. Smaller chunks can be processed faster and reduce the risk of memory overload, but they may lose important context. Larger chunks retain more context but may introduce irrelevant information or exceed the model’s token limit, reducing performance.
- Best Practice: For most RAG systems, a chunk size between 256-512 tokens is optimal for tasks involving precise information retrieval, while 1,000-2,000 tokens might be better for broader context tasks like summarization.
Overlap: Introducing overlap between chunks ensures that the transition between chunks is smooth and that no critical information is lost. Typically, an overlap of 100-200 tokens is recommended, depending on the task and the length of the chunk.
- Best Practice: Use overlap strategically to maintain continuity between chunks. A 10-20% overlap can help retain context across segments while minimizing redundancy.
Handling Different Data Types
RAG systems often need to handle a variety of data types, including text, code, and structured documents like tables. Each data type requires a tailored approach to chunking.
- Text Documents: For plain text, recursive chunking methods such as Recursive Character Text Splitting work well by splitting text based on characters or sentences, ensuring context is preserved across chunks.
- Structured Data: For documents with inherent structure (e.g., markdown or JSON), document-specific chunking methods should be used. This allows the system to maintain logical sections, ensuring that context is retained in structured documents like reports or manuals.
- Code: Code requires more careful chunking due to its structure. Syntax-aware chunking should be applied, where code is split based on function definitions, blocks, or other syntax-related delimiters.
Avoiding Over-Chunking
One common pitfall in chunking strategies is over-chunking, where the text is divided into too many small segments. This can result in excessive API calls and higher latency, ultimately reducing the system's performance. On the other hand, under-chunking can lead to chunks that are too large and difficult for the model to process efficiently.
- Best Practice: Aim for a balance between maintaining context and optimizing for performance. Use chunk sizes that are large enough to capture meaningful content but not so large that they overwhelm the model.
Post-Retrieval Optimization
After retrieving the chunks, it’s important to optimize the retrieved content before it is passed to the language model. Post-retrieval techniques such as context compression and re-ranking help focus the model on the most relevant chunks, improving the overall performance of the RAG system.
- Re-ranking: This technique reorders the retrieved chunks based on their relevance to the user query. For instance, placing the most relevant chunks at the top of the list ensures that the model focuses on the most important content.
- Context Compression: This reduces the amount of irrelevant content by focusing only on key information within the chunks, thus avoiding noise and improving the accuracy of the model’s responses.
Advanced Techniques: Recursive and Adaptive Retrieval
In more complex systems, recursive and adaptive retrieval techniques can be employed to enhance the chunking process. Recursive retrieval involves continuously refining the retrieval process based on feedback, while adaptive retrieval enables the system to decide when and how to retrieve information based on confidence scores from the model.
- Best Practice: Use recursive retrieval when dealing with large, unstructured datasets to improve relevance over multiple iterations. Adaptive retrieval can be used to optimize performance by dynamically adjusting the retrieval strategy based on the system's needs.
Key Takeaways from Chunking Strategies in RAG Systems
In this blog, we explored the importance of selecting the right chunking strategy for optimizing Retrieval-Augmented Generation (RAG) systems. The choice of chunking method—whether fixed-size, recursive, document-based, or semantic—depends largely on the nature of your data and the specific needs of your application.
Here are the main takeaways:
- Understanding Chunking's Role: Chunking is essential for overcoming token limitations and ensuring that large documents can be processed efficiently by Large Language Models (LLMs). Whether you're working with text, code, or multimedia, applying the right chunking method enhances both retrieval and generation quality.
- Start with Simplicity: For developers new to chunking, starting with simple techniques like fixed-size or recursive chunking is a practical approach. These methods offer ease of implementation and effective results for straightforward data structures.
- Scale Up as Complexity Grows: As your data and system requirements grow more complex, advanced methods like document-based or semantic chunking provide a more refined approach. These techniques help maintain contextual accuracy and relevance, especially in large-scale or unstructured datasets.
- Balance Performance and Context: Striking the right balance between chunk size, overlap, and data structure is critical. Over-chunking can increase computational costs and reduce system efficiency, while under-chunking risks losing important context. Tailoring your chunking strategy to the specific demands of your application ensures optimal performance.
In conclusion, the right chunking strategy can significantly enhance the performance and scalability of your RAG system, helping you deliver more accurate and contextually relevant results while maintaining efficiency. By understanding your data, experimenting with different methods, and scaling intelligently, you can ensure your system is equipped to handle even the most complex retrieval tasks.
References:
 Sayantan Das
Sayantan Das
 FullStackRetrieval-com
FullStackRetrieval-com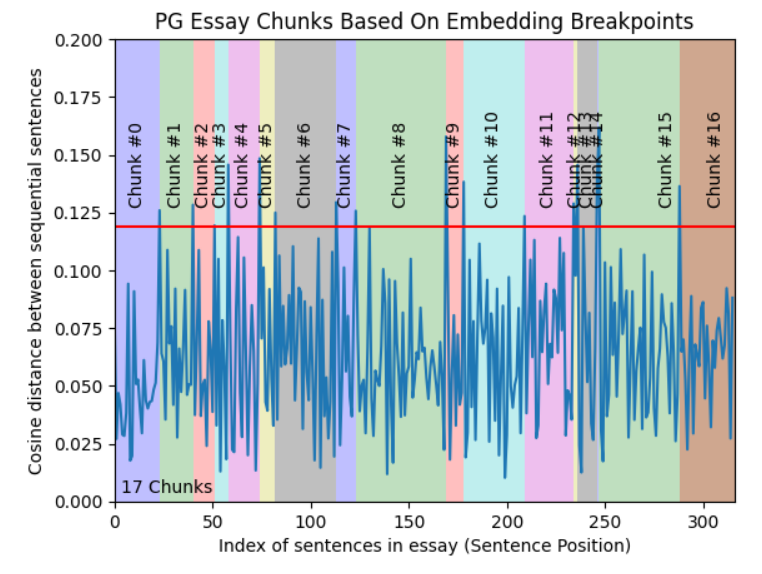
 David Richards
David Richards