Continual Learning: How AI Models Stay Smarter Over Time
Continual learning keeps AI models adaptive and up to date. It reduces model drift, preserves accuracy, and ensures continuous improvement through data-driven retraining and evaluation cycles.

Machine learning models age, not in years, but in data drift.
As new data, trends, and user behaviors emerge, yesterday’s model slowly starts to lose its edge.
This is where Continual Learning comes in, a modern ML practice that ensures your model keeps learning, improving, and adapting long after its first training run.
What is Continual Learning?
Continual Learning is the process of regularly updating a trained model with new or refined data so that it stays accurate, relevant, and aligned with the latest information, without starting from scratch each time.
In other words, it’s the operational heartbeat of production AI systems, allowing models to evolve alongside changing inputs, domains, and tasks.
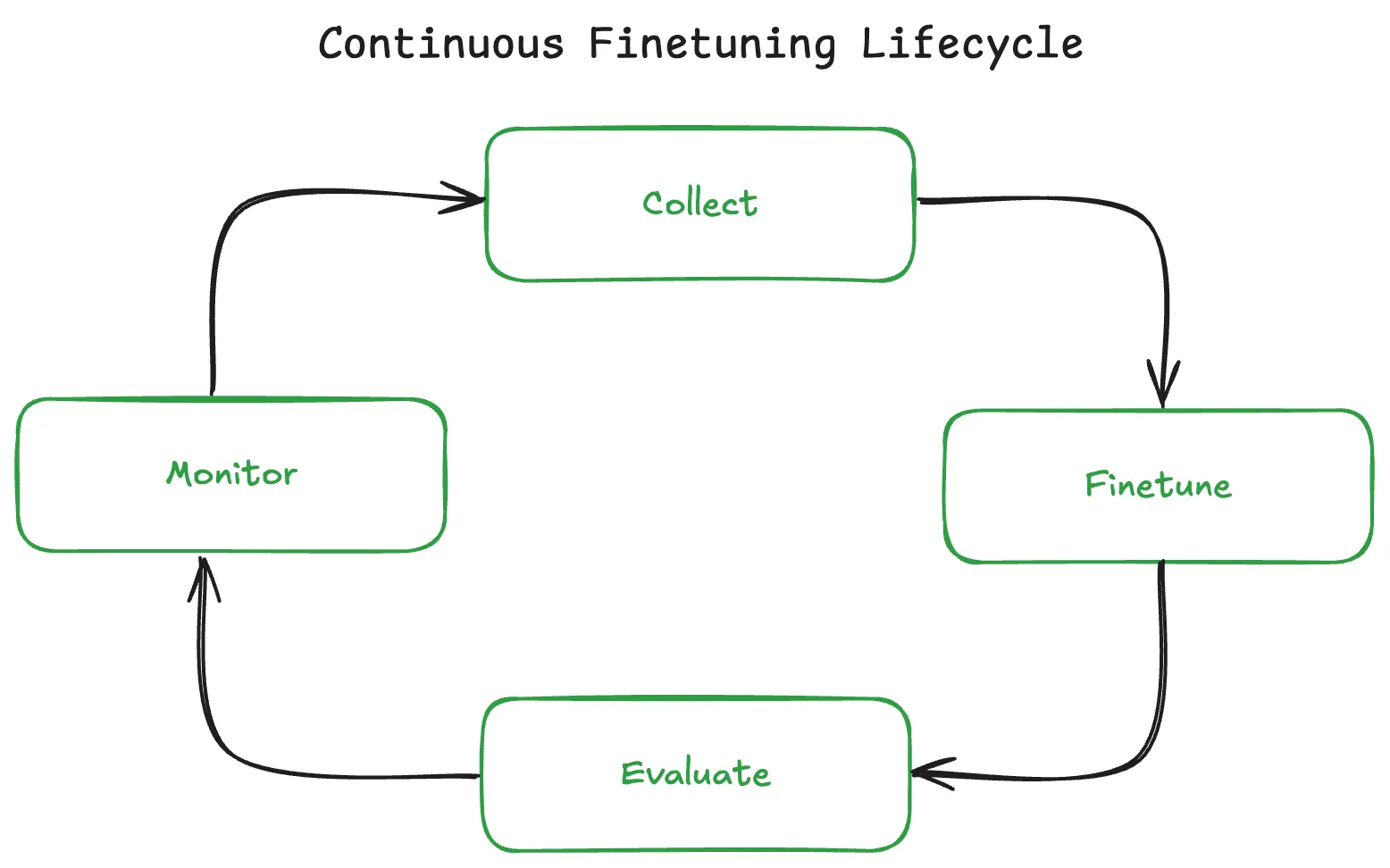
Instead of training once and deploying forever, continual learning turns model improvement into a recurring cycle:
Collect → Fine-tune → Evaluate → Deploy → Monitor → Repeat
This approach is especially critical for:
- Dynamic data environments (social media, search, conversational AI).
- Domain-evolving models (finance, healthcare, e-commerce).
- User-personalized systems (recommendation engines, assistants, chatbots).
What CFT Can Include?
CFT encompasses a range of sub-techniques:
- Instruction tuning: refining how the model interprets and executes instructions.
- Task-specific fine-tuning: optimizing for defined use cases like summarization or classification.
- Model editing and refinement: fixing factual inaccuracies or adding newly discovered information.
- Preference alignment: improving model behavior based on human or AI feedback (e.g., through Direct Preference Optimization or DPO).
- Multilingual adaptation: extending the model to new languages while retaining its performance in existing ones.
Continual Learning vs RAG: When to Use Each
Aspect | Continual Learning | RAG (Retrieval-Augmented Generation) |
|---|---|---|
Best for | Teaching the model how to respond (style, format, behavior) | Providing the model what to know (facts, data, documents) |
Frequency of updates | Static or rarely changing information | Frequently updated information (daily, weekly, monthly) |
Cost | High upfront cost, then cheaper per query | Lower upfront, small ongoing cost per query |
Speed | Fast responses (no retrieval overhead) | Slightly slower (needs to fetch documents first) |
Your shop policy example | ❌ Bad choice - You'd need to retrain monthly, costing time and money | ✅ Perfect choice - Just update your policy docs, chatbot auto-fetches latest version |
✅ Use Continual Learning When:
Example 1: Customer service tone
- Your brand has a specific friendly, casual voice
- You want responses like "Hey there! 😊" instead of "Hello, how may I assist you?"
- Why continual learning: This is about teaching style, not facts
Example 2: Structured output format
- Your system needs responses in specific JSON format
- Medical reports that must follow exact templates
- Why continual learning: The model learns the pattern, no document lookup needed
Example 3: Domain-specific tasks
- Legal document analysis with specific clause identification
- Code generation in your company's unique framework
- Why continual learning: Complex reasoning patterns that benefit from being "baked in"
✅ Use RAG When:
Example 1: Your monthly shop policies (your exact case!)
- Return policy changes from 30 days to 45 days
- New holiday hours announced
- Why RAG: Update the document once, chatbot instantly knows. No retraining!
Example 2: Product catalog
- Daily inventory changes
- New products added weekly
- Price updates
- Why RAG: Retraining for every product change would be insane
Example 3: Company knowledge base
- Employee handbook updates
- Internal wikis and documentation
- Support ticket history
- Why RAG: Information changes constantly, fetch on-demand
Is your information changing monthly or more often?
├─ YES → Use RAG ✅
└─ NO → Continue...
│
Is this about teaching the model HOW to behave/format responses?
├─ YES → Use continual learning ✅
└─ NO → Continue...
│
Do you have a massive, stable knowledge base you query constantly?
├─ YES → Consider continual learning (performance optimization)
└─ NO → Use RAG (more flexible) ✅Can You Use Both?
Yes! The best systems often combine them:
- Update your model for your brand voice and response style
- RAG for fetching up-to-date policies, products, and data
Why It Matters: The Cost of Static Models
Even the most advanced model begins to decay the moment it's deployed. Shifts in data, new patterns, evolving contexts, and user feedback all create what's known as model drift. Without regular updates, this leads to:
- Declining accuracy
- Increased bias or outdated predictions
- Reduced user trust
Continual learning counters drift by making adaptation part of the process, ensuring your model learns continuously, just like your users do. Real-world examples include:
- Recommendation models at Netflix and Spotify constantly re-tuned with new interaction data
- Financial models retrained daily to adapt to market behavior
This becomes especially critical when considering temporal dynamics. Language and behavior patterns aren't static, they shift with cultural moments, seasons, and evolving norms:
- Language evolution: Slang, terminology, and communication styles change over time. A model trained on 2020 data may miss new phrases, memes, or professional jargon that emerged in 2023–2024.
- Seasonal patterns: E-commerce models face different user behaviors during holiday seasons versus off-peak months. Search queries, purchasing intent, and product preferences shift predictably throughout the year.
- Policy and regulatory changes: Companies update their policies, governments change regulations, and industry standards evolve. A chatbot trained on last year's return policy will provide outdated guidance without continual learning.
- Cultural and social shifts: Public sentiment, current events, and societal values influence how users interact with AI systems. Models need to adapt to remain relevant and appropriate.
Without accounting for these temporal dynamics, even a well-trained model becomes a time capsule-accurate for its training period, but increasingly disconnected from present reality.
Two Ways to Do Continual Learning
1️⃣ Retraining an Existing Model on New Data
This is the most practical and widely adopted method. Here, the model doesn’t start over, instead, you pick up from the latest checkpoint and teach it using new or updated data.
Workflow Example:
- Collect new user or domain-specific data.
- Clean and validate remove duplicates, ensure schema consistency, fix noisy labels.
- Integrate synthetic or feedback-based samples (like self-instruct or reinforcement learning updates).
- Fine-tune using parameter-efficient methods (LoRA, adapters, PEFT).
- Evaluate for regressions across legacy and new benchmarks.
- Deploy gradually, monitor KPIs, and repeat.
✅ Pros:
- Faster and significantly more cost-efficient.
- Preserves previously learned knowledge.
- Fits naturally into MLOps pipelines (continuous integration for models).
⚠️ Risks:
- Catastrophic forgetting: the model may forget old knowledge.
- Bias amplification if new data is unbalanced.
- Requires continuous monitoring to prevent regressions.
🧠 Mitigation Techniques:
- Replay old data alongside new.
- Apply regularization (EWC, L2) to retain important weights.
- Freeze earlier layers, fine-tune higher layers.
- Maintain a validation set that represents both past and present data.

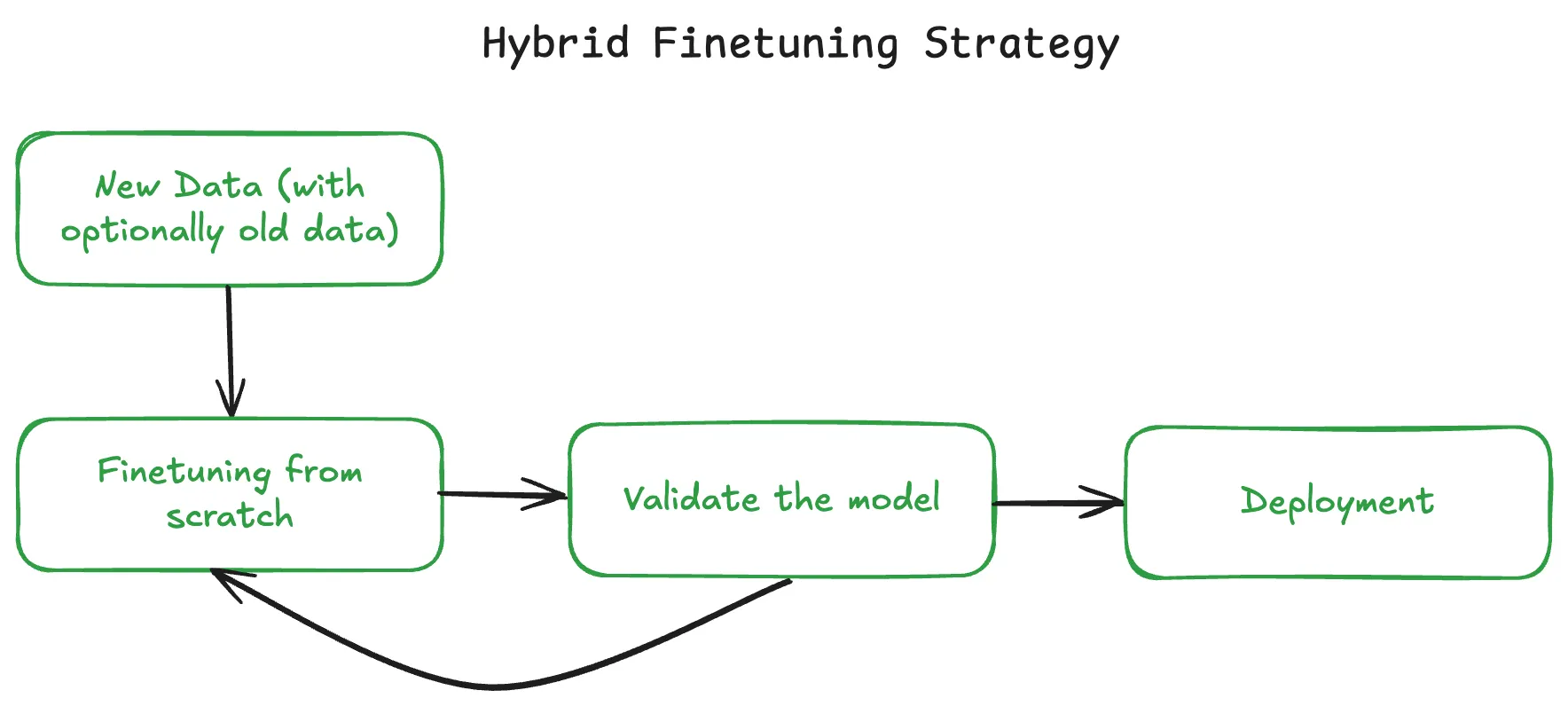
2️⃣ Training a New Model from Scratch on New Data
In some cases, it’s better to start fresh. This approach discards the old weights and rebuilds a model entirely from scratch using new (and optionally old) datasets.
This is common when:
- The domain or task has changed significantly (e.g., text → multimodal).
- Architecture changes are needed (e.g., LLaMA → Mistral-like models).
- Previous training data is outdated or flawed.
- You have a large, diverse new dataset that justifies re-training.
✅ Pros:
- Removes legacy biases and performance bottlenecks.
- Allows architectural improvements or tokenization changes.
- Ideal for large-scale, foundational upgrades.
⚠️ Cons:
- Computationally expensive and time-consuming.
- Can overfit if the new dataset is narrow.
- Discards useful prior knowledge unless mixed with older data.
In practice:
Most production AI teams use a hybrid model continual learning for rapid updates and periodic full retraining (quarterly or yearly) for architectural and foundational refreshes.
How to Decide Between the Two
Scenario | Fine-tune Existing Model | Train From Scratch |
|---|---|---|
Frequent small updates | ✅ Yes | ❌ No |
Major domain or data shift | ⚠️ Maybe | ✅ Yes |
Compute budget | 💸 Low | 💸💸 High |
Need to preserve old skills | ✅ Yes | ❌ No |
Architecture redesign | ❌ No | ✅ Yes |
Deployment timeline | Fast | Slow |
In most real-world pipelines, continual learning wins for practicality and cost-efficiency, while full retraining is reserved for transformative updates.
Best Practices for Effective CFT
Before implementing CFT, keep these factors in mind:
- Dataset SimilarityThe closer your new dataset is to previous fine-tuning data (in format or intent), the better your model’s retention.
- Balanced Learning Rate & DurationUse smaller learning rates and shorter training cycles to prevent “overwriting” older weights.
- Comprehensive EvaluationDon’t just measure performance on new data, benchmark the model on older tasks as well.
- Training FrequencyRegular updates are good, but too frequent fine-tunes may introduce noise or instability.Define clear triggers (e.g., data drift thresholds).
- Quality Over QuantityCurated, high-quality data often drives better outcomes than large but noisy datasets.
The Core Challenge: Catastrophic Forgetting
The biggest hurdle in continual learning is catastrophic forgetting, where a model’s performance on previous tasks drops after it’s fine-tuned on new ones. This happens because new data updates the model’s internal weights, sometimes at the expense of older knowledge. However, research has shown that this can be managed effectively with the right strategy.
Key Insight:
When successive fine-tuning datasets are similar in structure or objective, the model tends to retain or even improve its previous capabilities. When datasets differ significantly (e.g., shifting from Q&A to summarization), performance on earlier tasks can deteriorate sharply.
Design takeaway:
Plan continual learning phases carefully, maintain dataset similarity or use regularization, replay, or adapter techniques to retain old knowledge.
When to Use Continual Learning
Continual Learning isn’t just a research concept, it’s a production-grade strategy used by top AI teams.
Here’s when it becomes especially valuable:
1. Incremental Model Improvement
When a model is already fine-tuned and you want to enhance it further using newer, better, or domain-specific data, without restarting from scratch.
This is common in production models that evolve weekly or monthly.
2. Multilingual Adaptation
When extending an English-proficient model to handle new languages, CFT allows incremental multilingual learning without degrading performance in English.
For instance, a two-phase fine-tune, English → multilingual, often preserves core capabilities while expanding new ones.
3. Handling Data Drift
For live systems (chatbots, search, or financial models), user behavior and data change constantly.
CFT helps the model adapt naturally to these shifts, keeping it aligned with real-world trends.
4. Incremental Knowledge Integration
When new knowledge becomes available, like updated legal rules or product catalogs, continual learning integrates it efficiently without rebuilding the entire model.
5. Preference Alignment and Human Feedback
After collecting feedback, stack Supervised Fine-tuning (SFT) with Direct Preference Optimization (DPO) to better align the model’s tone, reasoning, and helpfulness to human expectations.
This method is widely adopted in RLHF-style pipelines.
Continual learning isn’t just a technical upgrade, it’s a strategic capability. It turns AI from a static artifact into a living system that learns continuously from its environment.
Wrapping Up
Continual learning bridges the gap between static model performance and real-world evolution.
It keeps your AI system relevant, data-aligned, and performance-stable in the face of constant change.
It’s faster, cheaper, and smarter than rebuilding from scratch and when done right, it creates a self-improving AI lifecycle.
⚙️ Do It Seamlessly with Prem Studio
Prem Studio lets you build, monitor, and manage continual learning workflows without the operational overhead.
From dataset versioning, parameter-efficient retraining, to automated deployment, Prem Studio provides an end-to-end pipeline for teams building continuously improving models.
👉 Learn how to set up continual learning pipelines using Prem Studio in our documentation: docs.premai.io
💡 FAQs on Continual Learning
1. Does continual learning make models biased over time?
It can, if new data isn’t balanced or diverse. Always curate and validate every fine-tuning batch.
2. How do I know when my model actually needs fine-tuning again?
Monitor drift metrics or a steady drop in accuracy. When performance dips, it’s time to update.
3. Can a model become worse after multiple fine-tunes?
Yes, over-tuning can degrade generalization. Use validation sets from both old and new data.
4. Is it safe to fine-tune on user-generated data?
Only if data is cleaned and anonymized. Raw user data often carries noise and bias.
5. Can fine-tuning replace pre-training?
No. Fine-tuning adapts, it doesn’t build foundational understanding like pre-training does.
6. How small can a fine-tuning dataset be?
Surprisingly small, if it’s high-quality and well-aligned with the model’s prior training.
7. Does continual learning affect inference speed?
Not directly, but adding adapters or larger checkpoints can slightly impact latency.
8. How do I keep track of all fine-tuning versions?
Use dataset and model versioning tools, Prem Studio automates this seamlessly.