Prem Cortex: Human-Like Memory for Smarter Agents
Cortex is PremAI’s cognitive memory layer for AI agents. Unlike vector DBs, it provides human-like memory with short and long-term storage, smart collections, temporal intelligence, and evolving knowledge graphs, making agents context-aware and production ready.

Building AI agents without proper memory is like having a brilliant colleague with severe amnesia. They might give you great answers, but ask them about yesterday's conversation, and there is no remembrance.
Most vector databases treat memories like documents in a filing cabinet. No understanding of relationships or maintain awareness of chronological context. No intelligence about what belongs together. When applied at scale, your search for "security best practices" returns home security cameras mixed with OAuth2 implementations.
What is Cortex?
Cortex is a memory layer for agentic systems that mimics human cognition. Instead of being another vector database wrapper, it's a configurable tool that agents can tune for intelligent memory storage and retrieval.
Think of it as giving your agent a human-like memory with adjustable knobs:
Dual-tier Architecture
- STM (Short-Term Memory): Fast, recent context with configurable capacity
- LTM (Long-Term Memory): Persistent storage with relationship graphs
- Background evolution that discovers connections automatically
Smart Collections
- Auto-organizes memories by domain (work.programming vs personal.cooking)
- Prevents the "everything is relevant" problem at scale
- Context-aware query transformation per collection
Temporal Intelligence
- Natural language date ranges ("last week", "yesterday")
- Adjustable temporal_weight (0.0 = pure semantic, 1.0 = pure recency)
- Auto-detects time-sensitive queries
Agent-Friendly API
- Single interface with tunable parameters
- Multi-user/session isolation built-in
- Optional background processing for non-blocking responses
Quick Spin-Up (Agent Memory Tool)
import os
from dotenv import load_dotenv
from cortex.memory_system import AgenticMemorySystem
from datetime import datetime, timedelta
load_dotenv('.env')
# Initialize as a tool for your agent
memory_tool = AgenticMemorySystem(
api_key=os.getenv("OPENAI_API_KEY"),
enable_smart_collections=True, # Knob 1: Domain organization
enable_background_processing=True, # Knob 2: Async vs sync
stm_capacity=10 # Knob 3: Recent Short term memory context size
)
# Agent stores memories with timestamps
# Recent memory (1 hour ago)
memory_tool.add_note(
"User prefers TypeScript over JavaScript for new projects",
user_id="user_123",
time=(datetime.now() - timedelta(hours=1)).astimezone().isoformat()
)
# Yesterday's memory
memory_tool.add_note(
"Discussed API rate limiting strategies using Redis",
user_id="user_123",
time=(datetime.now() - timedelta(days=1)).astimezone().isoformat()
)
# Last week's memory
memory_tool.add_note(
"Team decided to migrate from REST to GraphQL",
user_id="user_123",
time=(datetime.now() - timedelta(days=7)).astimezone().isoformat()
)
# Specific date memory (January 2024)
memory_tool.add_note(
"Q1 planning: Focus on performance optimization",
user_id="user_123",
time="2024-01-15T10:00:00+00:00"
)
# Agent retrieves with different strategies
# Strategy 1: Pure semantic search
results = memory_tool.search("programming preferences", user_id="user_123", memory_source="ltm")
# Returns: TypeScript preference (most semantically relevant)
# Strategy 2: Temporal-aware search
results = memory_tool.search(
"what did we discuss yesterday?",
user_id="user_123",
memory_source="ltm",
temporal_weight=0.7, # 70% recency, 30% semantic
)
# Returns: Redis rate limiting (from yesterday)
# Strategy 3: Date-filtered search
results = memory_tool.search(
"team decisions",
user_id="user_123",
memory_source="ltm",
date_range="last week"
)
# Returns: GraphQL migration (within date range)
# Strategy 4: Specific month search
results = memory_tool.search(
"planning",
user_id="user_123",
memory_source="ltm",
date_range="2024-01"
)
# Returns: Q1 performance optimization (January only)
How Cortex Works as an Agent Tool
Cortex provides agents with configurable memory operations through a simple API:
# Storage knobs agents can tune
memory_tool.add_note(
content="...", # What to remember
user_id="...", # User isolation
session_id="...", # Session tracking
time="...", # RFC3339 timestamp
**metadata # Custom metadata
)
# Retrieval knobs agents can tune
results = memory_tool.search(
query="...", # What to find
context="...", # Context for query (if any)
limit=10, # How many results
memory_source="all", # "stm" | "ltm" | "all"
temporal_weight=0.0, # 0.0 to 1.0 recency blend
date_range="last week", # Natural language or RFC3339
where_filter={...}, # Metadata filters
user_id="...", # User context
session_id="..." # Session context
)
Behind the scenes, Cortex handles:
- Parallel processing through STM (fast) and LTM (deep) paths
- Smart categorization to prevent domain confusion
- Automatic evolution to build relationship networks
- Hybrid retrieval combining global and collection-aware search
Under the hood: Automatic evolution
When a new memory is added:
- Candidate selection: Cortex pulls likely neighbors from LTM using semantic similarity, shared tags, and collection context
- LLM decisioning: An LLM inspects the new memory + candidates and proposes actions with confidence scores
- Strengthen or create links (typed: similar/supports/contradicts)
- Update tags/metadata for neighbors
- Merge if the new memory duplicates an existing one
- Safety & thresholds: Actions apply only if confidence ≥ threshold; never references non‑existent IDs; runs in background if configured
- Persistence: Relationship updates are stored alongside metadata and timestamps (RFC3339)
Example decision:
{
"should_evolve": true,
"actions": ["strengthen", "update_neighbor"],
"suggested_connections": [
{"id": "prev_debug_note", "type": "similar", "strength": 0.86,
"reason": "Both describe React re-render loops"}
],
"tags_to_update": ["debugging", "react", "performance"]
}
Smart Collections: Domain-Aware Intelligence
The killer feature that prevents the "everything matches" problem:
# Without Smart Collections
query = "authentication issues"
# Returns: home security auth, API auth, login problems, 2FA setup...
# With Smart Collections
query = "authentication issues"
# Cortex discovers: work.backend.auth collection (85% relevant)
# Transforms query: "OAuth2 JWT authentication debugging issues"
# Returns: Only backend auth memories, ranked by relevance
Collections form automatically when 10+ (configurable) memories share a pattern. Each collection develops its own query enhancement logic, making domain-specific searches incredibly precise.
Strengths: Built for Agentic Control
Parallel Search Optimization Agents can spawn multiple Cortex instances with different configurations to maximize search coverage:
# Agent creates specialized searchers
recent_searcher = AgenticMemorySystem(
enable_smart_collections=False, # Skip for speed
stm_capacity=200 # Larger recent window
)
deep_searcher = AgenticMemorySystem(
enable_smart_collections=True, # Full intelligence
enable_background_processing=True
)
# Agent runs parallel searches with different strategies
results = await asyncio.gather(
recent_searcher.search(query, temporal_weight=0.9), # Recent-focused
deep_searcher.search(query, memory_source="ltm"), # Deep historical
deep_searcher.search(query, date_range="2024-01") # Time-boxed
)
Configurable Trade-offs Every knob is designed for agents to tune based on context:
- Need speed? Disable smart collections, use STM only
- Do you require deeper insights: Enable background processing, search LTM
- Require greater accuracy: Enable collections, use domain-specific search
Multi-User Context Switching Built-in user/session isolation means agents can manage multiple conversations without cross-contamination.
Ecosystem Integration
- LLMs: OpenAI and Ollama (OpenAI‑compatible). Use your own client key and endpoint.
- Embeddings: OpenAI (
text-embedding-3-*,ada-002) or local SentenceTransformers (all-MiniLM-L6-v2,all-mpnet-base-v2) - Vector DB: ChromaDB over HTTP for persistent LTM
- Agents/Orchestration: Use directly from Python or wrap as tools in LangChain/your framework
- Minimal LangChain Tool wiring:
import os
from typing import Optional, List, Dict, Any
from datetime import datetime, timedelta
from pydantic import BaseModel, Field
from langchain.tools import StructuredTool
from cortex.memory_system import AgenticMemorySystem
# Initialize Cortex (enables smart collections if OPENAI_API_KEY is set)
api_key = os.getenv("OPENAI_API_KEY")
memory = AgenticMemorySystem(
api_key=api_key,
enable_smart_collections=bool(api_key),
model_name="all-MiniLM-L6-v2", # local/fast embeddings
)
# Tool input schemas
class CortexAddNoteInput(BaseModel):
content: str
user_id: Optional[str] = None
session_id: Optional[str] = None
time: Optional[str] = Field(
default=None, description="RFC3339 timestamp (e.g., 2025-08-07T10:00:00+00:00)"
)
context: Optional[str] = None
tags: Optional[List[str]] = None
metadata: Optional[Dict[str, Any]] = None
class CortexSearchInput(BaseModel):
query: str
limit: int = Field(default=10, ge=1, le=50)
memory_source: str = Field(
default="all", description='"stm" | "ltm" | "all"'
)
temporal_weight: float = Field(
default=0.0, ge=0.0, le=1.0, description="0.0 = pure semantic, 1.0 = pure recency"
)
date_range: Optional[str] = Field(
default=None, description='e.g. "last week", "2024-01", RFC3339 range'
)
where_filter: Optional[Dict[str, Any]] = None
user_id: Optional[str] = None
session_id: Optional[str] = None
# Tool functions
def cortex_add_note_fn(
content: str,
user_id: Optional[str] = None,
session_id: Optional[str] = None,
time: Optional[str] = None,
context: Optional[str] = None,
tags: Optional[List[str]] = None,
metadata: Optional[Dict[str, Any]] = None,
):
return memory.add_note(
content=content,
user_id=user_id,
session_id=session_id,
time=time,
context=context,
tags=tags,
**(metadata or {}),
)
def cortex_search_fn(
query: str,
limit: int = 10,
memory_source: str = "all",
temporal_weight: float = 0.0,
date_range: Optional[str] = None,
where_filter: Optional[Dict[str, Any]] = None,
user_id: Optional[str] = None,
session_id: Optional[str] = None,
):
return memory.search(
query=query,
limit=limit,
memory_source=memory_source,
temporal_weight=temporal_weight,
date_range=date_range,
where_filter=where_filter,
user_id=user_id,
session_id=session_id,
)
# Structured tools with schemas
cortex_add_note = StructuredTool.from_function(
name="cortex_add_note",
description="Store a memory note (supports time/user/session/context/tags/metadata)",
func=cortex_add_note_fn,
args_schema=CortexAddNoteInput,
)
cortex_search = StructuredTool.from_function(
name="cortex_search",
description="Search memories with optional temporal/date filtering and metadata filters",
func=cortex_search_fn,
args_schema=CortexSearchInput,
)
# Example usage (agents will call .invoke under the hood)
_ = cortex_add_note.invoke(
{
"content": "User prefers TypeScript over JavaScript",
"user_id": "user_123", # optional
"session_id": "onboarding", # optional
"time": datetime.now().astimezone().isoformat(), # optional
"context": "preferences.programming", # optional
"tags": ["typescript", "language"], # optional
"metadata": {"source": "chat"}, # optional
}
)
results = cortex_search.invoke(
{
"query": "programming preferences",
"limit": 5,
"memory_source": "all",
"temporal_weight": 0.2, # optional
"date_range": "last week", # optional
"where_filter": {"context": {"$eq": "preferences.programming"}}, # optional
"user_id": "user_123", # optional
"session_id": "onboarding", # include if you added with a session
}
)
print(f"Top result: {results[0]['content'][:60]}..." if results else "No results")
Add these tools to your agent as usual
📉 Current Limitations
Latency Challenges Cortex prioritizes intelligence over speed. Compared to pure vector databases:
- Smart collection discovery adds 2-8s overhead
- LLM-powered categorization adds ~500ms per memory
- Evolution processing can take 1-2s in synchronous mode
If you need <200ms retrieval consistently, Cortex might be too heavy. Consider disabling smart collections or using STM-only mode for latency-critical paths.
No Multimodal Support (Yet) Currently text-only. Image, audio, and video memory support is in active development and coming soon. For now, you'll need to store multimodal content references as text descriptions.
📊 Performance: Real Numbers
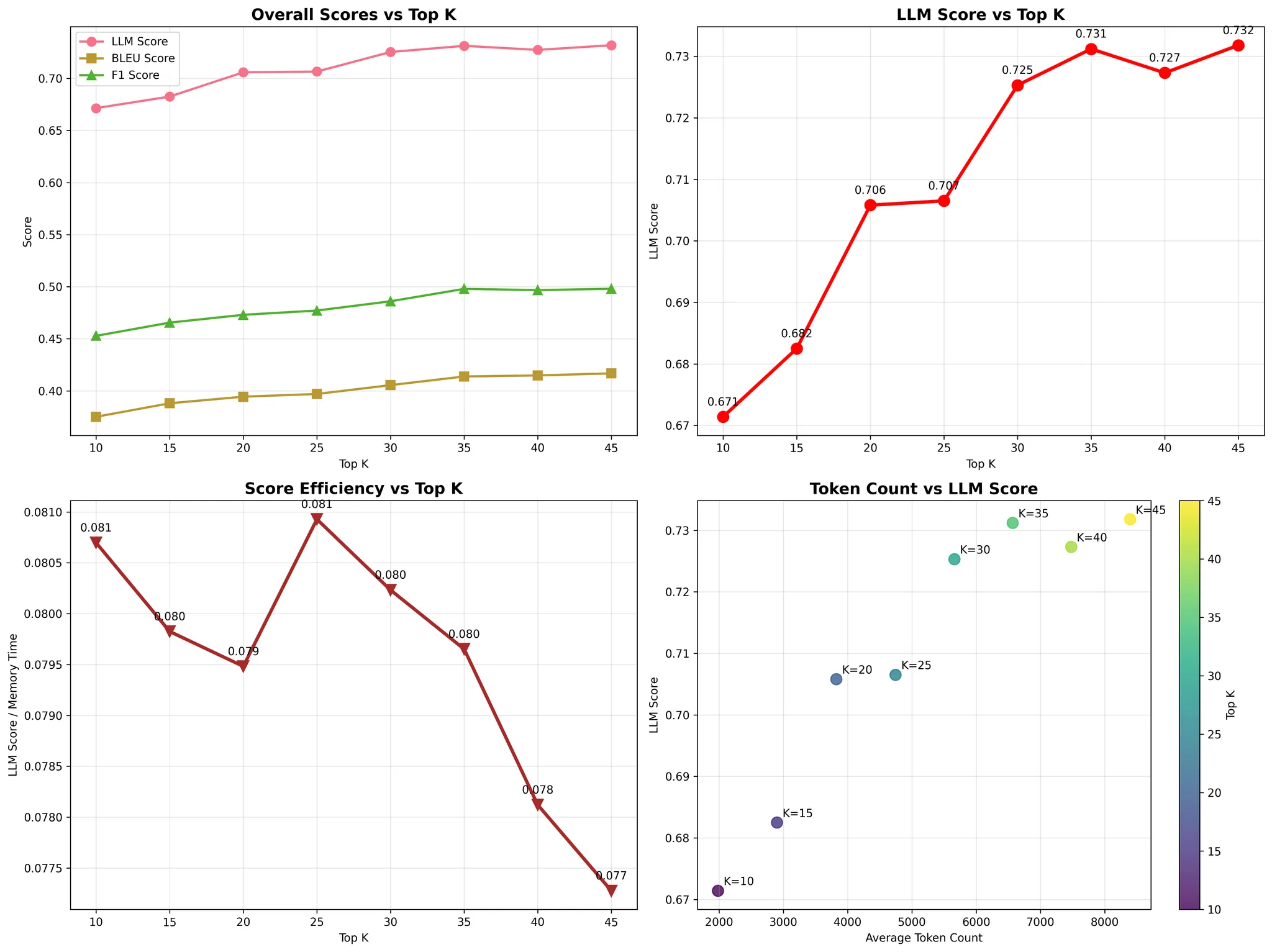
On the LoCoMo10 benchmark (1,540 questions):
- At ~3k tokens (Top‑K 15): 0.682 — near Mem0 (0.684) with fewer tokens
- At ~4k tokens (Top‑K 20): 0.706 — higher than Mem0 (0.684) at similar budget
- At ~4.5k tokens (Top‑K 25): 0.707 — maintains lead
- Approaches full‑context: 0.731 at ~7k tokens (Top‑K 35); full‑context baseline (all turns) is 0.8266 at ~26k tokens
- Latency: ~2–8s with Smart Collections; ~1.5–2s without
🔥 Why Build Agents with Cortex?
No More Memory Soup At scale, traditional vector search returns everything vaguely related. Cortex's collections ensure your agent's search for "deployment" finds DevOps memories, not "deployed to production" cooking recipes.
Temporal Awareness Built-In Agents can naturally handle "What did we discuss last Tuesday?" without complex date parsing. Cortex supports control over temporal intent and adjusting temporal weighting for retrieval scoring.
Evolving Knowledge Graphs Unlike static stores, memories form relationships. Your agent learns that "Sarah's debugging session" connects to "React performance issues" and "team architecture decisions."
Production-Ready Knobs
enable_background_processing: Choose between fast responses or complete evolutionstm_capacity: Tune conversation context window (10-200 memories)temporal_weight: Blend semantic and recency (0.0 to 1.0)enable_smart_collections: Toggle domain organization
Real-World Use Case: Engineering Team Assistant
# Initialize with smart collections for multi-domain content
team_memory = AgenticMemorySystem(
enable_smart_collections=True,
stm_capacity=100 # Keep last 100 interactions fast
)
# Throughout the day, memories build relationships
team_memory.add_note(
"Sprint planning: Authentication service needs OAuth2 upgrade",
time=datetime.now().astimezone().isoformat()
)
team_memory.add_note(
"Security review flagged our OAuth implementation as outdated",
time=(datetime.now() - timedelta(hours=2)).astimezone().isoformat()
)
team_memory.add_note(
"John volunteered to lead the OAuth2 migration",
time=(datetime.now() - timedelta(days=1)).astimezone().isoformat()
)
# Smart Collections organize automatically:
# → work.security.oauth (OAuth-related memories)
# → work.planning.sprint (Sprint planning memories)
# → work.team.assignments (Who's doing what)
# Later, the PM asks...
results = team_memory.search("What are the security priorities?")
# Returns: OAuth2 upgrade (linked to John, timeline, and sprint planning)
# New developer joins and asks...
results = team_memory.search("Who should I talk to about authentication?")
# Returns: John + OAuth2 context + security review notes
# Weekly standup automation
weekly = team_memory.search(
"What did we plan this week?",
date_range="last week" # Database-level filtering
)
After a month: 2,000+ memories organized into ~15 domain collections. Queries that would return 50+ results in flat search return 5-8 highly relevant ones.
Gotchas & Limitations
LLM Processing Overhead: Smart categorization needs ~500ms LLM calls. Disable when operating at high throughput.
Collection Threshold: Needs 10+ (configurable) similar memories before creating collections. Early queries are less precise.
Not a Database: Unsuitable for structured data, logs, or metrics. A database should be used for that purpose.
VectorDB Required: Needs external vector database server. Adds operational complexity.
Evolution Lag: Background processing means relationships appear eventually, not instantly.
Final Verdict: Memory That Actually Learns
Cortex isn't just another vector database wrapper - it's a cognitive memory layer that agents can tune for their specific needs. The combination of smart collections, temporal awareness, and automatic evolution solves real problems that flat storage can't touch.
✅ Ship it if:
- Building agents that need to remember conversations over time
- Dealing with 500+ memories across multiple domains
- Need temporal queries as first-class citizens
- Want memories that evolve and connect automatically
- Can tolerate 2-10s latency for intelligent results
- Require multi-user isolation
❌ Refrain from proceeding if:
- Need consistent <200ms retrieval latency
- Working with multimodal content (images/video)
- Simple key-value storage is enough
- Working with <100 memories
- Can't have a vector DB
- Storing structured/tabular data
The question isn't whether your agents need better memory - it's whether they need it yet.
🛠 Get Started:
GitHub: Prem Cortex on GitHub.
Built by: Prem