Data Distillation: 10x Smaller Models, 10x Faster Inference

Data distillation lets you take knowledge from massive models like GPT-5 or Llama-3.3-70B and transfer it to smaller models that actually run in production.
GPT-5 needs expensive GPUs and takes seconds to respond when using reasoning. But a 3B parameter model distilled from GPT-5? Runs on standard hardware with millisecond response times while keeping most of the performance.
What Is Data Distillation?
Data distillation is a technique where a large, complex model (the "teacher") transfers its knowledge to a smaller model (the "student") by creating or curating a dataset that captures the teacher's learned patterns.
A professor doesn't transfer their entire brain to students. They create lecture notes, examples, and exercises that encode their understanding. The students learn from these distilled materials.
In AI terms:
- Teacher model: A large model (GPT-5, Llama-3.3-70B, etc.)
- Distillation process: Extracting knowledge into a compact dataset
- Student model: A smaller model that learns from this distilled data
- Result: A lightweight model that retains most of the teacher's capabilities
You're not compressing data randomly. You're capturing what the large model learned from potentially terabytes of training data and encoding it into a smaller, focused dataset
Why This Matters Now
Large language models keep getting bigger. GPT-5 has over a trillion parameters. Claude and Gemini are similarly massive.
GPT-5 models are reasoning models by default, they generate step-by-step thinking processes before answering. This makes them more accurate but slower. A reasoning model might take 10-30 seconds to answer complex questions because it's thinking through the problem. For production applications that need sub-second responses, this is a dealbreaker.
Data distillation solves this. You use GPT-5's reasoning capabilities to generate high-quality training data, complete with its reasoning chains. Then train a smaller, non-reasoning model on these outputs. The result: you get the accuracy benefits of reasoning models but with the speed of standard models
These models are incredible, but they have a problem:
They don't fit in production environments.
Your application needs:
- Fast response times (under 100ms)
- Ability to run on standard hardware
- Predictable costs
- Local deployment options
A trillion-parameter model needs specialised hardware and significant resources. But a 7-billion parameter model? That runs on a single GPU. A 2-billion parameter model? That fits on edge devices.
Data distillation bridges this gap.
Understanding the Two Approaches
Data distillation and knowledge distillation (logit distillation) are different approaches:
Data Distillation
You create a curated dataset from the teacher's outputs, then use it to train student models independently. The teacher generates responses, predictions, or representations that become your training data.
Example workflow:
- Feed diverse prompts to your teacher model
- Collect its outputs
- Create a distilled dataset from these outputs
- Train any number of student models on this dataset
For example: if you ask GPT-5 'What's 47 × 83?', it reasons through the calculation step by step. When you distill, you capture both its reasoning process and the final answer (3,901). Your smaller model learns from this complete thought process, not just the final number.
Knowledge Distillation (Logit Distillation)
The student learns directly from the teacher's probability distributions during training. Instead of learning just "the answer is Paris," the student learns the teacher's confidence distribution across all possible answers.
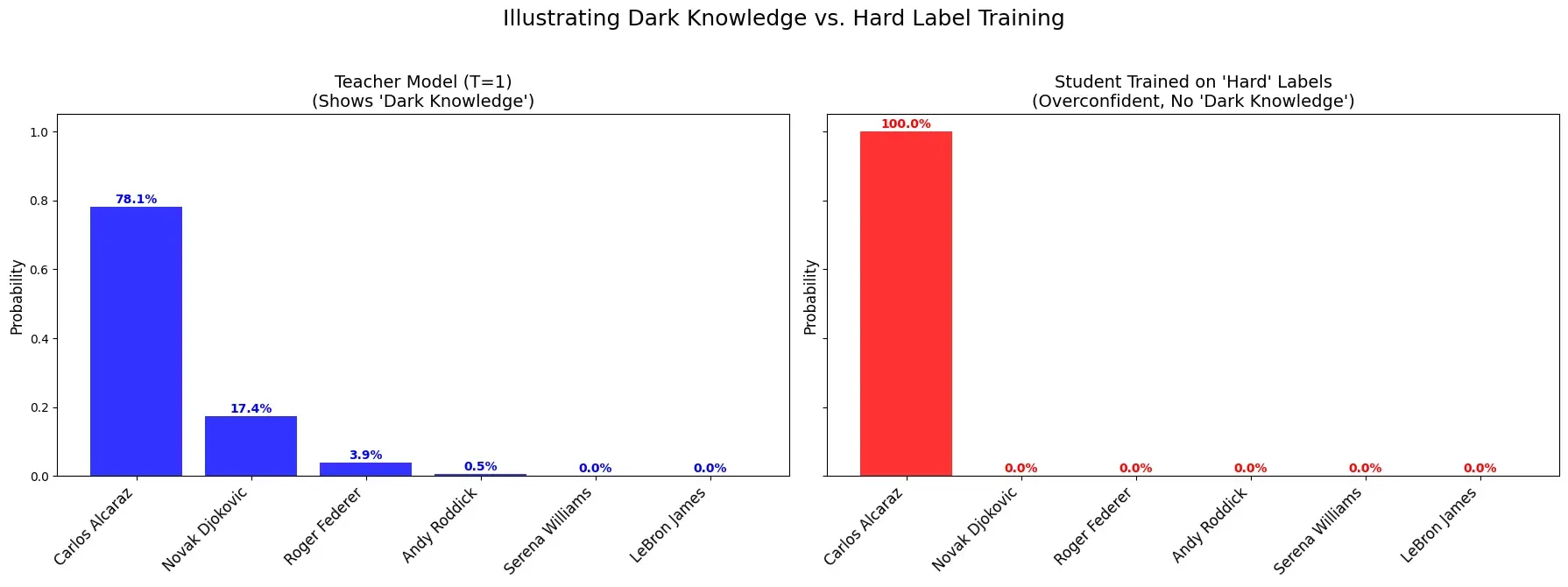
When asked "Who won Wimbledon 2023?", a strong LLM assigns probabilities to all plausible answers:
Teacher Model (T=1): Carlos Alcaraz (78.1%), Novak Djokovic (17.4%), Roger Federer (3.9%), Andy Roddick (0.5%)
This rich distribution shows the model knows Djokovic is more likely than Federer to win Wimbledon - that's the 'dark knowledge'.
In logit distillation, the student learns all these probabilities in a single training step. It understands why Djokovic was plausible (recent champion) and Federer less so (retired).
In data distillation, the teacher outputs only "Carlos Alcaraz" and the student learns just that fact - missing all the context about relationships between players.
Student trained on hard labels: Learns "Alcaraz = 100%" and assigns zero probability to everything else. It learned the fact but not the context.
KD vs Data Distillation:
| Method | Supervision | Cost | Performance Gain | Example Use Cases |
|---|---|---|---|---|
| Knowledge Distillation (KD) | Online teacher logits (teacher + student run together) | High | Higher | Creative tasks, reasoning-heavy tasks, safety/alignment-heavy behaviour, complex decision boundaries |
| Data Distillation | Offline teacher decoded outputs (teacher runs once → generates synthetic dataset) | Low | Lower | Knowledge-intensive tasks, recall-focused tasks, cheap fine-tuning, multi-student training, privacy-sensitive setups |
How LLM Distillation Is Different
LLM distillation works differently from image classifiers. Language models generate text sequentially - each word depends on previous words. When GPT-5 uses reasoning, it generates complete thought processes. You distill both the answers and the reasoning steps. A teacher handling 100K tokens can teach a student that handles 4K tokens to use context efficiently.
def distill_llm_response(teacher_model, student_model, prompt, temperature=3.0):
"""
Computes the distillation loss between a teacher and student model.
"""
# Teacher forward pass — get full logits (includes reasoning signals)
teacher_logits = teacher_model(prompt, return_logits=True)
# Temperature scaling softens the distribution
soft_targets = F.softmax(teacher_logits / temperature, dim=-1)
# Student forward pass
student_logits = student_model(prompt)
student_log_probs = F.log_softmax(student_logits / temperature, dim=-1)
# KL divergence: core KD loss
loss = F.kl_div(student_log_probs, soft_targets, reduction='batchmean')
# Standard KD temperature correction
return loss * (temperature ** 2)
The temperature parameter is crucial. At T=1, you barely smooth the distribution. At T=10, everything becomes equally likely. For LLMs, T=3-7 usually works best.
Building Your Distillation Dataset
The quality of your distilled dataset determines everything. Here's the systematic approach:
Step 1: Coverage Over Volume
You need diverse examples that span your model's capabilities:
- Creative tasks (writing, storytelling)
- Analytical tasks (reasoning, comparison)
- Factual responses
- Code generation
- Conversation handling
- Edge cases
Don't just dump random prompts. 50K carefully selected examples outperform 10M random ones.
Step 2: Mine the Learning Boundaries
The most valuable examples sit where the teacher shows medium confidence (60-85%). These boundary cases encode the most information about decision-making.
*# Find high-value training examples*
teacher_probs = teacher_model.predict(prompts)
confidence = torch.max(teacher_probs, dim=-1).values
valuable_indices = torch.where((confidence > 0.6) & (confidence < 0.85))
distillation_data = prompts[valuable_indices]
Step 3: Synthetic Augmentation
Use the teacher to generate variations that teach different aspects:
base = "Explain quantum computing"
variations = [
f"{base} to a beginner",
f"{base} using analogies",
f"{base} in 3 sentences",
f"{base} focusing on applications"
]
*# Each variation teaches different abstraction levels*
Real Implementation: Llama-3.3-70B to 7B
Let me share an actual distillation project:
Starting point: Llama-3.3-70B fine-tuned on domain-specific tasks Target: Deploy on edge devices with <4GB memory Process:
- Data curation:
- Extracted 100K prompts from production usage
- Filtered for diversity using embedding clustering
- Added 20K synthetic examples for weak areas
- Teacher inference:
- Generated responses with full logit distributions
- Captured intermediate layer representations
- Temperature = 5 for optimal knowledge transfer
- Student training:
loss = 0.7 * distillation_loss + 0.3 * hard_label_loss
*# Balance learning from teacher with staying grounded*
- Results:
- 10x size reduction (70B → 7B)
- 89% performance retention on benchmarks
- 15x faster inference
- Better consistency on narrow tasks
The surprising part? The student was more reliable for specific use cases. Smaller models have fewer failure modes.
Common Pitfalls and Solutions
Problem: Student outputs nonsense Solution: Increase temperature to 5+. Start with soft targets, gradually introduce hard labels.
Problem: Massive performance drop Solution: Your compression ratio is too aggressive. Try intermediate sizes (70B → 13B → 7B).
Problem: Good benchmarks, poor production performance Solution: Your distillation data doesn't match real usage. Use actual production prompts.
Problem: Training instability Solution: Use layer-wise learning rates. Early layers (general features) need lower LR than task-specific layers.
Making Distillation Practical
Managing distillation pipelines involves juggling large models, tracking experiments, and handling massive datasets. This is where infrastructure becomes critical.
Prem Studio streamlines this workflow. Generate synthetic training data, version control your distilled datasets, compare teacher-student performance metrics - all integrated into your ML pipeline. The platform handles the complexity while you focus on model optimisation.
Check our documentation for implementation templates and best practices.
The Path Forward
We believe the future isn't infinitely larger models. It's specialised, efficient models that excel at specific tasks.
Why? Because a focused 7B model that perfectly handles your use case beats a general 70B model that does everything adequately. Especially when it runs locally, responds instantly, and scales economically.
Data distillation is how we get there. Teaching giants to create focused, capable apprentices.
Try it yourself. Take your largest model, distill its knowledge, and see how much intelligence you can pack into a smaller package.
FAQs
Q: How much performance loss should I expect from distillation? A: Typically 2-10% accuracy drop for 10-100x compression. Depends heavily on task complexity and how well you design the distillation process.
Q: Can I distill a model without access to its training data? A: Yes. You can use unlabelled data or even generate synthetic data. The teacher model's outputs become your labels.
Q: What's the minimum dataset size for effective distillation? A: Varies by task, but generally 10-100K examples work well. Quality matters more than quantity. better to have 10K diverse examples than 100K similar ones.
Q: Should I distill from one large teacher or ensemble multiple teachers? A: Ensembles often work better but cost more computationally. Try single teacher first, then experiment with ensembles if you need that extra performance.
Q: Can distillation actually improve performance over the teacher? A: Surprisingly, yes. Sometimes the regularisation effect of distillation helps the student generalise better on specific tasks, especially with noisy data.
Q: How do I handle distillation for multi-modal models? A: Treat each modality separately during feature matching, but maintain joint training on the final representations. Balance the losses carefully, one modality might dominate otherwise.