DeepSeek R1: Open Source Driving the Future of Enterprise AI
DeepSeek R1 proves open source can rival proprietary AI, aligning with PremAI’s mission to build sovereign, censorship-resistant systems. From model distillation to agentic workflows, PremAI empowers enterprises to own, fine-tune, and scale AI securely while advancing open innovation.

The debate between open-source and closed-source AI has intensified, particularly in the wake of ChatGPT's introduction. In just two short years, we have witnessed a significant shift in priorities, with Open Science becoming a central focus in discussions surrounding the future of AI. For the first time, we observe a landscape where closed-source, proprietary systems no longer dominate the AI race.
DeepSeek R1, a groundbreaking open-source model, has demonstrated performance comparable to the esteemed OpenAI O1 family of models. R1 challenges the notion that proprietary systems are the only path to cutting-edge AI capabilities. This shift towards open source AI is exactly on par with PremAI’s vision to advance sovereign and aware AI systems. We take this commitment seriously so we’ve decided to make the next version of the Prem Platform open source.
In this blog post, we will explore Prem's vision for an open Large Language Model (LLM) ecosystem and how it aligns with key takeaways from DeepSeek's recent paper. We will also introduce methods like model distillation, which have enabled smaller models, such as the Llama and Qwen family of models, to achieve reasoning capabilities similar to those of DeepSeek R1.
However, before diving into the technical aspects, we want to take a moment to emphasize the significance of this milestone for our team and our vision, and why we are excited to share it with the world.
PremAI’s timeless vision for Sovereign AI
The founding purpose of PremAI has been to accelerate the advancement of sovereign and aware AI systems that companies and individuals can fully own.
Why does this matter? AI development and access should be approached more like open science knowledge that is broadly accessible rather than a proprietary, closed-source asset. Throughout history, powerful resources have often been subject to control and censorship. We've seen this pattern with media, book censorship, and, more recently, social media.
However, AI represents a far greater concern. While social media primarily influences what people say to one another, AI has the potential to become deeply integrated into every aspect of our lives. It could serve as a "control layer" for nearly everything, from shaping what our children learn to determining whether you pass a security check at an airport, qualify for a loan, or secure a job application.
This is why accelerating the advent of sovereign and censorship-resistant AI is essential. What do we mean by sovereign AI? It is an alternative vision from the one brought forward by the Open AI of the world. Instead of a one-size-fits-all problem model or system, an alternative system consisting of millions and eventually billions of smaller, more significant, open, and proprietary AI models and agents seamlessly coordinate, interact, and exchange value and information.
We believe this approach is the right path to building advanced AI systems that can genuinely benefit humanity. This philosophy is the foundation of PremAI. The name "Prem" holds dual significance: it represents "On-Premise," symbolizing ownership, and it is also a Sanskrit term for the highest form of intelligence, the ultimate intelligence behind all creation.
Early on in our journey, as referenced in the leaked internal document by a Google engineer, we realized that closed-source systems, although benefiting from OS models, ultimately had no moat. It has been apparent to us that the entire LLM space was eventually getting commoditized by the advancement of more evolved OS models.
Today, a week following the release of Deep Seek R1, that day has come.
We have been anticipating this day over the last two years and have been heads down, working on building the world's most effective and cutting-edge platform so that every company in the world could leverage this shared intelligence (R1) and build their own proprietary AI models.
We see a future where open-source research transforms the industry by breaking down barriers to collaboration, advancing innovation, and making cutting-edge reasoning models accessible to all. As we prepare to release the latest version of our platform, we have also decided to open-source our technology later next month.
Open source empowers the Prem AI team to collaborate with researchers and developers worldwide, enabling us to collectively build upon shared innovations, accelerate technological advancement, and create diverse applications. To realize our open-source vision, we've developed a platform that leverages the full potential of industry leaders like DeepSeek. Here's how R1's capabilities integrate seamlessly with our platform offerings:
- Integrated memory capabilitiesAgents built using Prem can seamlessly reference historical context for long-term scenarios while staying agile in real-time interactions.
- Access to external tools and data sourcesPrem connects agents to APIs, domain-specific knowledge bases, and hardware-accelerated pipelines, empowering them to reason and act effectively in dynamic environments.
- Automated fine-tuning and distillationOur platform includes built-in fine-tuning and distillation workflows to optimize large and small language models (LLMs/SLMs) for specific domains and hardware, ensuring cost-efficiency, peak performance, and operation without human intervention.
- Real-time feedback loopsPrem enables models to self-improve autonomously by leveraging user feedback, ensuring they stay relevant and continuously evolve over time, again with no human intervention.
- Objective performance metricsPrem provides real-time performance insights with clear metrics like accuracy, latency, and other critical KPIs, ensuring confidence in AI-driven decision-making.
Autonomous Fine-tuning Agent
Fine-tuning as a service is becoming increasingly ubiquitous, but it often performs better with larger base models. However, challenges like the scarcity of high-quality data make fine-tuning less accessible. At PremAI, we tackle this with our Autonomous Fine-Tuning Agent, which automates building Small Language Models (SLMs) for specific domains. From generating synthetic data to managing parallel fine-tuning jobs and evaluating models, our agent streamlines the process end-to-end.
Our emphasis on SLMs stems from their unique advantages. They are ideal for edge deployment, enabling secure local inference without relying on external cloud providers, thus ensuring data sovereignty. Additionally, SLMs are far more cost-effective, requiring less computational power for training and inference. This makes them a practical, privacy-focused, and autonomous solution for businesses seeking efficient and controlled AI capabilities.
Sovereignty drives PremAI's development of an autonomous fine-tuning agent (available on the platform), which aims to accelerate the democratization of AI ownership. We are committed to empowering individuals and organizations to fine-tune and adapt AI models to their specific needs, emphasizing the importance of accessibility and collaboration in the field.
Go ahead and build your first AI agent with DeepSeek on app.premai.io
Now, let's break down some of DeepSeek’s groundbreaking advancements.
DeepSeek’s Versatility
DeepSeek R1 is a reasoning model built on top of DeepSeek-v3, a 671B foundation model leveraging a Mixture of Experts (MoE) architecture, with 37B active parameters. This model outperforms Anthropic AI’s Sonnet 3.5 and OpenAI’s GPT-4. The release of DeepSeek-v3 and R1 is considered a groundbreaking achievement in the AI space for the following key reasons:
Hyper-Efficiency
The complete model required approximately 2.78 million H800 GPU hours for training, estimated at $5.57 million. In contrast, models like Llama 3.1 (405B) were trained on 30.84 million H100 GPU hours at an estimated cost of $123 million. This stark difference highlights the remarkable efficiency of DeepSeek’s training pipeline, which not only reduced costs but also delivered outstanding results.
Architectural innovations such as Multi-Token Prediction (MTP) and Multi-Head Latent Attention (MLA), coupled with extensive low-level hardware optimizations, contributed to this unprecedented efficiency. Let’s explore the architecture of DeepSeek in detail.
Multi-Token Prediction
The Multi-Token Prediction (MTP) mechanism of DeepSeek represents an approach to improving efficiency and performance during training and inference. Unlike traditional next-token prediction models that only predict the immediate next token in the sequence, MTP simultaneously extends its predictive capacity to multiple future tokens. This densifies the training signal, ensuring the model learns faster and generating richer representations for downstream tasks.
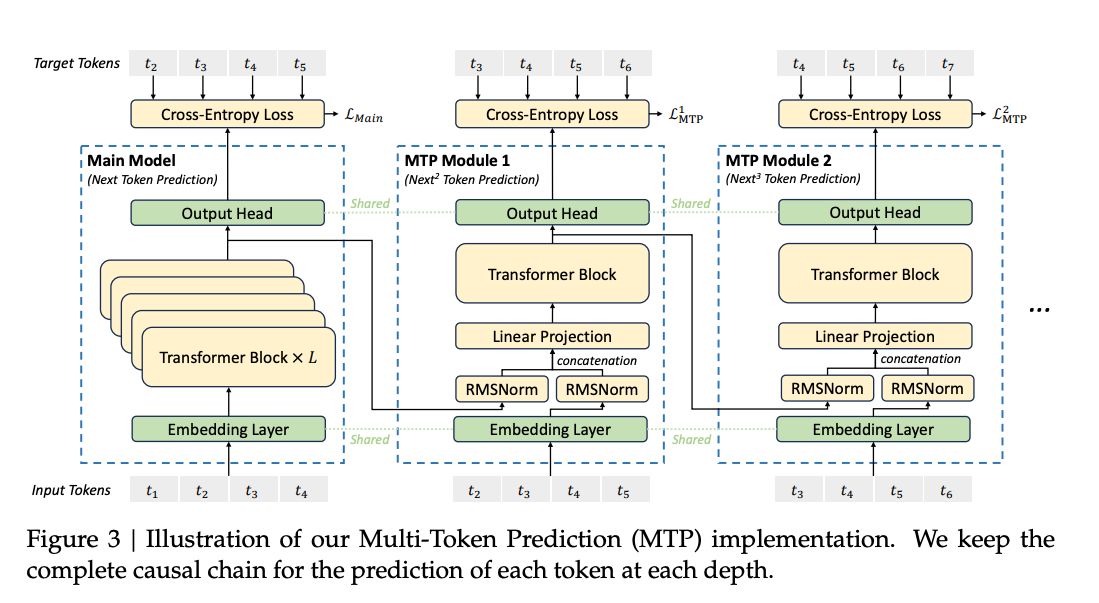
MTP integrates multiple prediction layers sequentially within its architecture, retaining the causal structure essential for high-quality generative tasks. These layers share embeddings and output heads with the main model, ensuring memory efficiency without sacrificing performance. By predicting tokens at increasing depths within a sequence, MTP creates a forward-looking model capable of anticipating broader contexts, a vital capability for complex reasoning and generative challenges.
Multi-Head Latent Attention (MLA) & DeepSeek MoE
At the heart of DeepSeek’s architecture lies the Multi-Head Latent Attention (MLA) mechanism. MLA redefines traditional attention by introducing low-rank compression for keys and values, dramatically reducing memory consumption during inference. This compression mechanism ensures that only essential information is cached while retaining the model's ability to generate high-fidelity outputs.
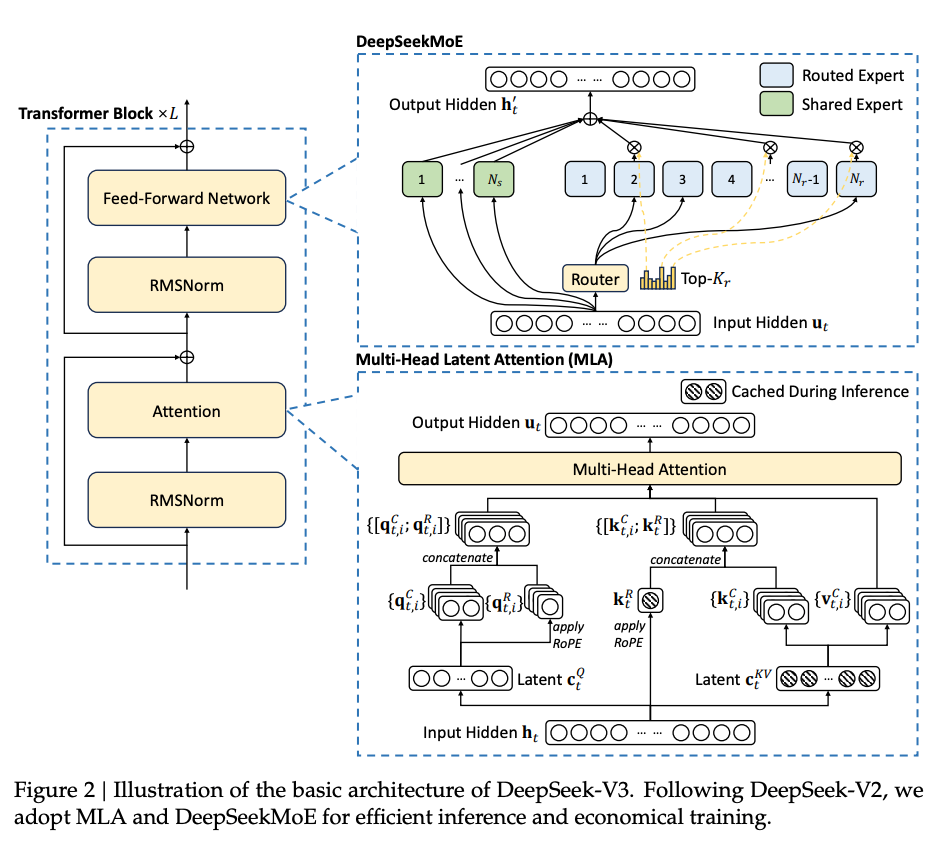
MLA also improves computational efficiency with its novel handling of queries, keys, and values, employing rotary positional embeddings (RoPE) to ensure that the model effectively captures positional dependencies over extended contexts. The balance between memory efficiency and performance precision makes MLA particularly suited for large-scale tasks with significant computational constraints, reinforcing DeepSeek’s reputation for optimization and scalability.
The DeepSeekMoE architecture embodies a sophisticated implementation of the Mixture-of-Experts (MoE) paradigm, aiming to balance computational efficiency and performance. With its auxiliary-loss-free load-balancing strategy, DeepSeekMoE sidesteps the traditional performance trade-offs that often accompany load balancing. Instead, it introduces a dynamic bias adjustment mechanism that monitors and optimizes expert usage in real time, ensuring a balanced load across training and inference scenarios.
This architecture incorporates both shared and routed experts, along with an innovative token-to-expert affinity scoring system to determine expert allocation dynamically. The balance between generalization and specialization, coupled with precise gating mechanisms, enables DeepSeekMoE to handle diverse and complex tasks effectively, ranging from language understanding to domain-specific reasoning.
GRPO: The secret sauce behind R1
DeepSeek-V3 serves as the foundational model, but the exceptional capabilities of DeepSeek-R1 stem from its innovative training strategy. Traditionally, the standard approach to training cutting-edge models involves three steps: first, pre-training a base model; next, performing instruction tuning using Supervised Fine-Tuning (SFT) to align the model with human-like responses; and finally, refining it further with Reinforcement Learning from Human Feedback (RLHF) techniques such as Proximal Policy Optimization (PPO) or Direct Preference Optimization (DPO). These steps are designed to improve the model’s alignment and reliability.
However, DeepSeek deviated from this conventional pipeline. Instead of relying on an intermediate SFT phase, DeepSeek-R1 transitioned directly from the foundational DeepSeek-V3 model to fine-tuning with a reinforcement learning (RL) framework. They used a method called Grouped Relative Policy Optimization (GRPO), leveraging Chain-of-Thought (CoT) techniques to fine-tune the model. Lets understand both in details.
The Power of Chain-of-Thought Reasoning
At the heart of DeepSeek-R1's exceptional reasoning ability is its focus on Chain-of-Thought (CoT) reasoning, a method that guides the model to deconstruct complex problems into manageable, sequential steps. Unlike traditional approaches where models directly output answers, CoT encourages a logical progression, breaking tasks into smaller, explainable actions. This approach is particularly transformative for reasoning-intensive domains like mathematics, coding, and logical problem-solving.

DeepSeek-R1’s CoT implementation isn’t merely a superficial addition. The model learns to “think aloud,” creating intermediate steps that reveal how it arrives at conclusions. This behavior not only boosts interpretability but also leads to better outcomes on intricate benchmarks.
A fascinating aspect of this progression is that CoT isn’t strictly enforced through rigid supervised examples. Instead, DeepSeek-R1 organically develops these reasoning pathways during its training, evolving more sophisticated CoT strategies over time. This approach results in outputs that are not only accurate but also transparent, allowing users to trace the reasoning proces
GRPO: The Reinforcement Engine Behind R1
DeepSeek-R1’s reasoning prowess owes much to its innovative use of Group Relative Policy Optimization (GRPO), a reinforcement learning (RL) framework fine-tuned to amplify reasoning capabilities. Traditional RL methods rely heavily on a critic model to evaluate actions, but GRPO takes a more efficient path. Instead of using a separate critic, it compares model outputs against one another within a sampled group, ranking and prioritizing responses that perform relatively better.
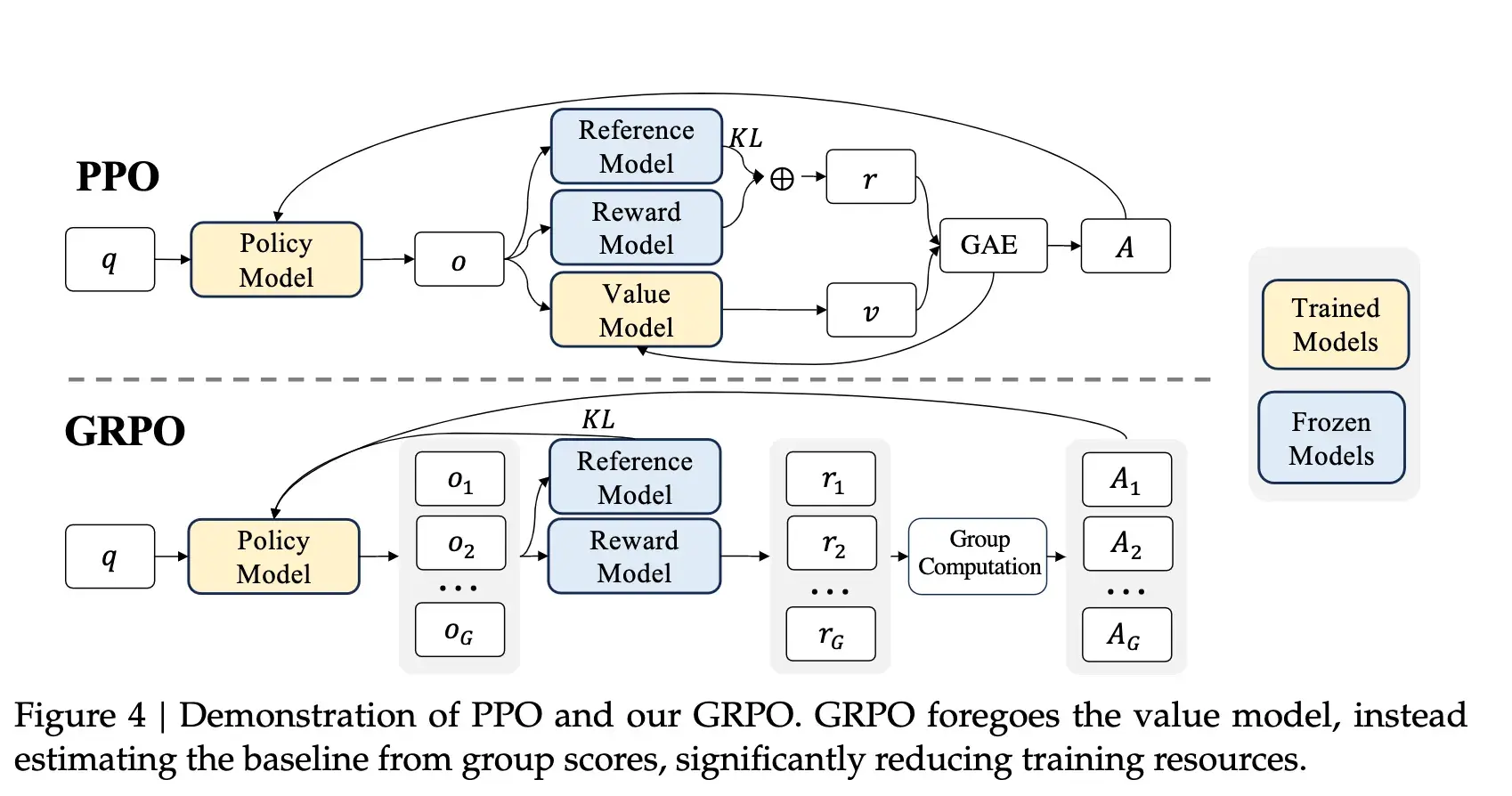
This structure is particularly well-suited for tasks requiring CoT reasoning. As the model generates outputs for each problem, GRPO dynamically rewards solutions that follow coherent, logical pathways while penalizing erratic or unclear reasoning. This relative scoring mechanism simplifies the RL pipeline, eliminating the computational overhead of a critic model without compromising performance.
During training, DeepSeek-R1's GRPO-driven optimization synergizes with its CoT capabilities. For example, it learns to allocate more “thinking time” to challenging problems, exploring deeper reasoning steps when simpler solutions fail. Over thousands of training iterations, this combination results in a model that doesn’t just answer questions, it explains them in a way that aligns with human preferences. By balancing technical accuracy with user-friendly outputs, GRPO becomes the secret ingredient that transforms DeepSeek-R1 into a leader in reasoning.
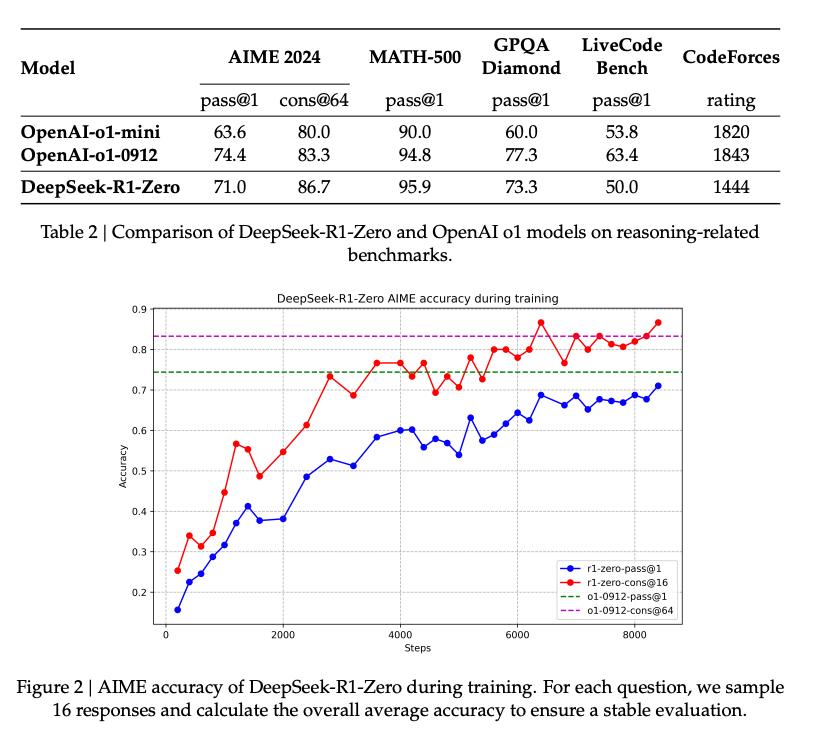
As shown in the figure above, DeepSeek-R1's performance not only catches up with but eventually surpasses OpenAI's O1 models, highlighting the effectiveness of its innovative training approach and the impact of reinforcement learning on enhancing reasoning capabilities.
Making It Accessible to the Community Through Distillation
Distillation is a process used to transfer the knowledge of a larger, more powerful model into a smaller, lightweight model, allowing the latter to replicate much of the original model's performance while being more efficient. In the context of Large Language Models (LLMs), distillation involves training a smaller model to mimic the outputs of a larger model by using the larger model's predictions as "soft labels." This approach reduces computational overhead while retaining core capabilities, making advanced AI more accessible.
In the DeepSeek-R1 paper, distillation played a pivotal role in democratizing its reasoning capabilities. By leveraging the outputs of DeepSeek-R1, smaller models such as Qwen and Llama variants were fine-tuned on curated datasets, resulting in highly efficient yet capable models. These distilled versions achieved impressive results on benchmarks, often outperforming larger open-source models. This effort ensures that the breakthroughs in reasoning pioneered by DeepSeek-R1 can be utilized even in resource-constrained environments, broadening their impact across the community.
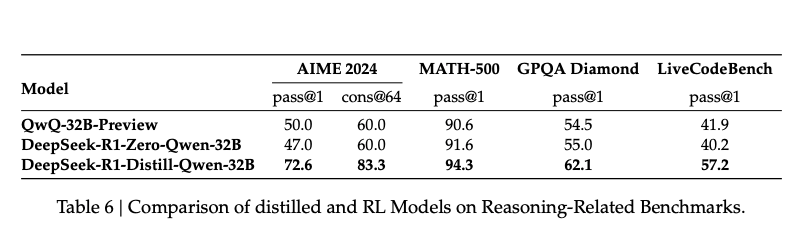
This approach not only extends the reach of DeepSeek-R1's reasoning breakthroughs but also sets a new standard for scalability and accessibility within the AI community, enabling high performance with lower computational demands. Additionally, DeepSeek-R1 is distributed under the permissive MIT license, granting researchers and developers the freedom to inspect and modify the code, use the model for commercial purposes, and integrate it into proprietary systems.
Open Source and Accessibility
DeepSeek-R1 is distributed under the permissive MIT license, granting researchers and developers the freedom to inspect and modify the code, use the model for commercial purposes, and integrate it into proprietary systems.
One of the most striking benefits is its affordability. Operational expenses are estimated at only around 15%-50% based on the input/output token size (likely closer to 15% since output token counts could dominate for reasoning models) of what users typically spend on OpenAI’s GPT-3 model**.**
The cost of running DeepSeek-R1 on Fireworks AI is $8 per 1 million tokens (both input & output), whereas running the OpenAI GPT-3 model costs $15 per 1 million input tokens and $60 per 1 million output tokens. This cost efficiency democratizes access to high-level AI capabilities, making it feasible for startups and academic labs with limited funding to leverage advanced reasoning.
Because it is fully open-source, the broader AI community can examine how the RL-based approach is implemented, contribute enhancements or specialized modules, and extend it to unique use cases with fewer licensing concerns.
Global Sentiment
The release of DeepSeek's R1 model shook the global market, with tech stocks falling. Nvidia, a prominent player in the AI hardware industry, saw its stock plummet by more than 17% as investors grappled with concerns over R1's ability to deliver competitive results using less advanced and more affordable hardware. This development underscores the potential for disruptive innovation in the AI sector, challenging established players and their reliance on high-end, expensive hardware solutions. Developers are already taking advantage.

In contrast, Apple's stock emerged as a bright spot, surging by approximately 3.3%3. This positive market reaction can be attributed to the potential for smaller, more efficient AI models to enhance the capabilities of Apple's iPhone lineup and the company's prudent approach to AI spending. Meanwhile, Meta's stock rose by nearly 2% on the back of the company's bold promises to introduce a new "leading state of the art" AI model and ramp up its investment in the field.
Meta has already been at the forefront of open-source AI with their Llama model family. However we haven’t publicly seen results that are on par with DeepSeek R1.
As the market sways, developers will continue to take full advantage of having the tools they need to build AI solutions at a fraction of the cost. As investors reassess the valuations of established players in light of emerging, cost-effective competitors like DeepSeek, the stage is set for a period of intense competition and innovation. The ability to deliver cutting-edge AI capabilities while optimizing hardware requirements and costs is likely to emerge as a key differentiator in this new era.
Why Prem AI
Prem AI is building the future of enterprise-scale AI. The Prem platform eliminates the complexity of fragmented AI systems required to build agentic workflows, enabling enterprises and teams to build and scale powerful AI agents effortlessly. Our team is hyper-focused on bringing the latest Open Source innovation in agentic workflows to enterprises.
Ranging from memory utilities (graph, vector, RDBMs), giving agents access to custom tools (including proprietary tools), a native feedback system to improve the agent performance over time, a monitoring system so teams can monitor and track model performance, and an autonomous fine-tuning agent focused on model distillation to enable edge inference.