Edge Deployment of Language Models: Are They Ready?
Edge deployment of LLMs promises low latency, privacy, and real-time insights. This article explores the challenges, cutting-edge solutions, and future opportunities to make edge-based AI a reality across industries like healthcare, robotics, and IoT

Transforming AI: The Push for Edge-Based Language Models
Large Language Models (LLMs) have revolutionized AI with applications in healthcare, robotics, and IoT. However, the limitations of cloud-based deployments, such as high latency, bandwidth costs, and privacy risks, call for a shift to edge computing. By processing data closer to the source, edge deployments reduce delays, enhance privacy, and improve efficiency for real-time and context-aware applications. This article explores the challenges, advancements, and future directions for deploying LLMs at the edge.
Why Edge Deployment is the Future of Language Models
As the demand for intelligent applications grows, the limitations of cloud-based deployments for Large Language Models (LLMs) become more evident. Edge deployment offers a transformative alternative, enabling real-time processing, localized data handling, and enhanced efficiency for applications spanning various industries. This section explores the motivations behind edge deployment for LLMs and highlights its advantages through practical use cases.
Driving Factors for Edge Deployment
- Latency Reduction for Real-Time Applications
Many critical applications, such as autonomous vehicles and robotics, require near-instantaneous decision-making. Cloud-based LLMs suffer from communication delays due to the need to transmit data to distant servers. Deploying LLMs at the edge minimizes these delays, allowing for faster responses essential for real-time scenarios. - Enhanced Privacy and Security
Centralized data processing in the cloud poses significant privacy risks, especially in sensitive domains like healthcare. Edge deployment ensures that data remains close to its source, reducing exposure to potential breaches and aligning with data protection regulations such as GDPR. - Bandwidth Optimization
With the rise of multimodal applications (text, audio, video), transmitting large volumes of data to the cloud becomes both costly and inefficient. Edge computing processes data locally, conserving bandwidth and lowering operational costs. - Personalization and Context Awareness
Edge-deployed LLMs can leverage localized data to provide more personalized and context-aware responses. For instance, virtual assistants can tailor recommendations based on user-specific preferences and local environmental data.
Use Cases Highlighting the Need for Edge LLMs
- Healthcare
Advanced medical LLMs like Google’s Med-PaLM are being fine-tuned for real-time diagnostic assistance. Edge deployment in hospitals enables instant analysis of patient data, ensuring timely interventions without risking data privacy. - Robotics
Robotics systems powered by LLMs benefit significantly from edge computing. Tasks such as navigation, object manipulation, and interaction with humans require low-latency decision-making that cloud solutions cannot reliably provide. - Internet of Things (IoT)
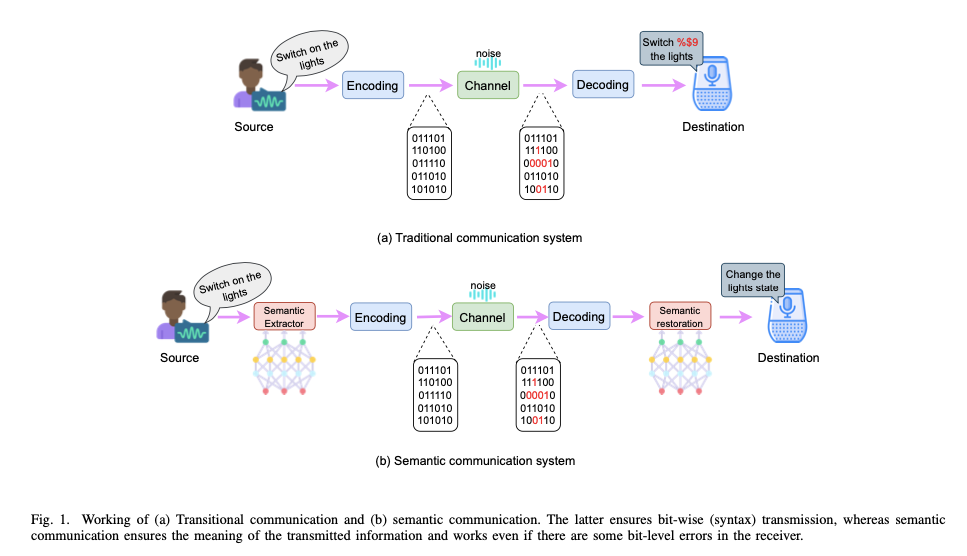
In IoT networks, edge-based LLMs enable semantic communication, interpreting and acting on user commands locally. This setup reduces the need for extensive data transmission, improving system efficiency while preserving device autonomy. - Autonomous Driving
Autonomous vehicles equipped with edge-deployed LLMs process sensor data locally to make split-second decisions, enhancing safety and reducing reliance on external networks.
Edge deployment represents a paradigm shift in how LLMs are implemented across industries. By addressing the challenges of latency, privacy, and bandwidth, it opens doors to new possibilities in real-time, context-aware applications.
Challenges Hindering Edge Deployment of Language Models
While edge deployment of Large Language Models (LLMs) promises significant advantages, it also comes with its own set of challenges. These issues stem from the inherent limitations of edge devices and the resource-intensive nature of LLMs. This section delves into the major technical hurdles that developers and engineers face when attempting to deploy LLMs at the edge.
3.1 Computational Demands
LLMs, with their billions of parameters, require immense computational power for both training and inference. For example, GPT-3, with 175 billion parameters, needs advanced GPUs to process data efficiently. Edge devices, which are inherently resource-constrained, often lack the necessary hardware to support such operations. This mismatch leads to high latency and limited performance in edge environments unless optimized techniques, such as split learning or parameter-efficient fine-tuning, are applied.
3.2 Memory and Storage Constraints
The memory and storage requirements of LLMs are a significant bottleneck for edge deployment:
- Model Size: LLMs such as GPT-3 occupy hundreds of gigabytes. Storing and running multiple versions of these models on edge devices with limited memory capacity is a formidable challenge.
- Caching and Updates: Frequent model updates, especially for fine-tuning, demand efficient caching and storage mechanisms. Parameter-sharing techniques like LoRA address some of these issues but still require careful resource allocation.
3.3 Communication Overhead
Transmitting large models or intermediate outputs between edge devices and servers consumes significant bandwidth:
- Latency in Model Delivery: For example, transferring GPT-2 XL (5.8 GB) over a typical 100 Mbps connection takes approximately 470 seconds, a delay unsuitable for real-time applications.
- Bandwidth Strain: Applications involving multimodal data (e.g., text, video, and audio) exacerbate bandwidth limitations, further complicating deployments in edge settings.
3.4 Privacy and Security
LLMs deployed at the edge often handle sensitive user data, such as medical records or personal interactions. Ensuring privacy and compliance with regulations like GDPR is a critical concern:
- Data Protection: Local processing minimizes exposure but also requires robust security measures to prevent breaches.
- Model Integrity: Securing models from malicious attacks, such as adversarial inputs or data poisoning, remains an ongoing challenge.
3.5 Energy Efficiency
The energy consumption of LLMs on resource-limited devices can quickly deplete available power:
- High Energy Costs: On-device inference of large models can consume tens of joules per token, making them impractical for continuous operation on battery-powered devices.
- Optimization Needs: Techniques such as quantization and pruning are vital for reducing energy demands while maintaining acceptable performance levels.
Edge deployment of LLMs requires overcoming these multifaceted challenges. Developers must employ advanced optimization techniques and leverage distributed computing paradigms to make these deployments viable and efficient.
Advancing Edge Deployments: Solutions for Optimizing Language Models
To address the challenges associated with deploying Large Language Models (LLMs) at the edge, researchers and developers have devised various innovative techniques. This section explores cutting-edge solutions that enhance the efficiency and feasibility of edge-based LLM deployments.
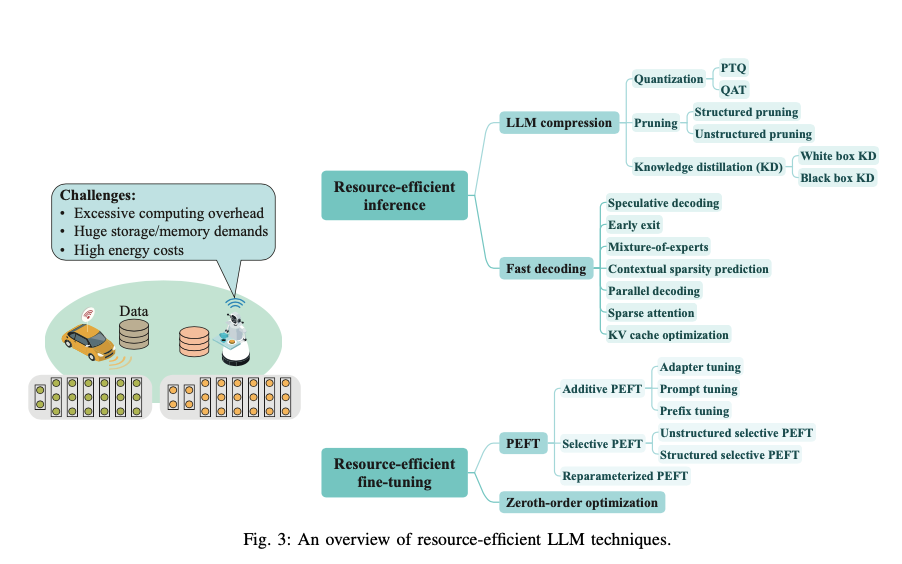
Model Quantization and Compression
Model compression techniques aim to reduce the size and computational demands of LLMs, making them more suitable for edge devices:
- Post-Training Quantization (PTQ): Converts model parameters to lower precision (e.g., INT4), significantly reducing memory and computational requirements without retraining. PTQ is ideal for resource-limited edge devices.
- Quantization-Aware Training (QAT): Simulates quantization during training to improve the performance of low-precision models. While more resource-intensive, QAT yields better accuracy than PTQ.
- Pruning: Eliminates redundant parameters, streamlining the model while maintaining performance. Structured pruning is particularly effective for hardware optimization on edge devices.
Parameter-Efficient Fine-Tuning
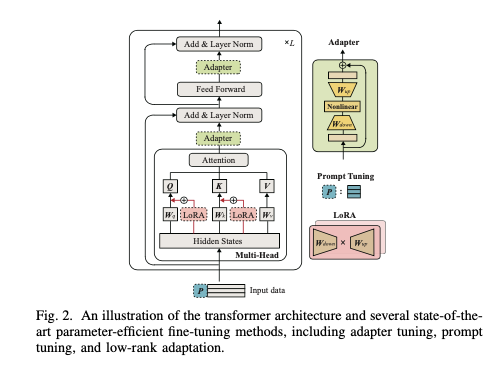
Rather than updating all parameters, parameter-efficient fine-tuning (PEFT) focuses on optimizing a subset of the model:
- LoRA (Low-Rank Adaptation): Introduces low-rank matrices to the pre-trained model, allowing efficient fine-tuning with minimal computational overhead.
- Adapter Tuning: Inserts additional layers into the model for task-specific updates, while keeping the original parameters frozen.
- Prompt Tuning: Adds trainable tokens to the input sequence for fine-tuning, requiring minimal changes to the model architecture.
Split Learning and Inference
Split learning and inference divide the computational workload between edge devices and servers:
- Split Learning: Partitions the model into sub-models, enabling collaborative training between devices and servers while preserving data privacy. Techniques like Split Federated Learning (SFL) parallelize the training process for faster results.
- Split Inference: Separates inference tasks into device-side and server-side components, optimizing resource utilization and reducing latency.
Collaborative and Distributed Computing
Edge-based deployments benefit from distributed computing paradigms:
- Collaborative Inference: Edge devices and servers share the inference workload, leveraging proximity to reduce latency and improve performance.
- Multi-Hop Model Splitting: Distributes large models across multiple edge servers, balancing computational demands and optimizing resource usage.
Caching and Parameter Sharing
Efficient model caching and parameter sharing strategies enhance storage and bandwidth utilization:
- Parameter Sharing: Identifies and caches shared parameters across models, significantly reducing storage requirements on edge servers.
- Model Caching Strategies: Tailors caching methods based on model popularity and task-specific requirements, improving service quality for end users.
Optimization for Energy Efficiency
Given the limited power resources of edge devices, energy-efficient methods are critical:
- Contextual Sparsity Prediction: Activates only the most relevant parameters during inference, reducing energy consumption without compromising performance.
- Speculative Decoding: Accelerates inference by predicting and verifying tokens in parallel, cutting energy costs by up to 50%.
The combination of these techniques paves the way for practical and scalable edge deployments of LLMs. By leveraging these advancements, developers can overcome the resource constraints and operational challenges of deploying LLMs at the edge.
Architectural Innovations for Deploying Language Models at the Edge
The successful deployment of Large Language Models (LLMs) at the edge requires reimagining existing architectures. This section explores how modern frameworks, driven by innovations in 6G-enabled mobile edge computing (MEC), support efficient edge-based LLM deployments.
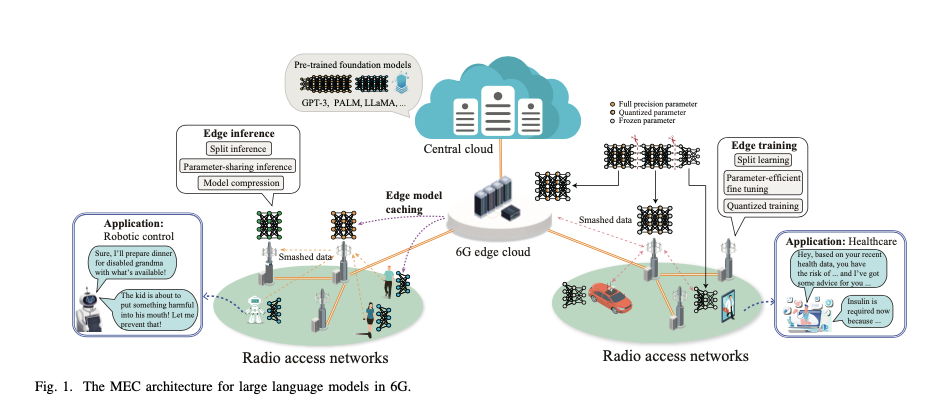
AI-Native Edge Architecture
Modern edge architectures integrate AI functionalities at every layer to optimize LLM deployment:
- Task-Oriented Design: Unlike traditional throughput-focused designs, task-oriented architectures aim to minimize latency and maximize LLM performance by optimizing distributed computing and resource allocation.
- Network Virtualization: Implements centralized controllers to manage distributed resources, enabling efficient coordination of data, model training, and inference processes.
- Neural Edge Paradigm: Mimics the structure of neural networks, distributing LLM layers across edge nodes to facilitate collaborative computing and reduce latency.
Edge Model Caching and Delivery
Caching and delivering LLMs at the edge require innovative approaches to handle the large size of these models:
- Parameter-Sharing Caching: Recognizes shared components across models and caches them only once, reducing storage requirements. For instance, LoRA fine-tuned models can share up to 99% of their parameters, minimizing redundancy.
- Model Compression for Delivery: Compression techniques, such as quantization, reduce model size for faster delivery while preserving accuracy.
- Dynamic Model Placement: Places frequently accessed models closer to users, dynamically relocating resources based on usage patterns to reduce service latency.
Distributed Training and Fine-Tuning
Edge environments excel in adapting pre-trained models to local contexts through distributed training mechanisms:
- Federated Learning: Combines updates from multiple devices to enhance a central model while preserving data privacy.
- Split Learning (SL): Divides model training between devices and servers, ensuring computational efficiency and privacy. Variants like Split Federated Learning (SFL) enable simultaneous training by multiple clients for faster results.
- Multi-Hop Training: Extends split learning by involving multiple edge servers to balance workload and optimize resource use.
Efficient Edge Inference
Inference at the edge benefits from optimized frameworks that reduce latency and computational demands:
- Collaborative Inference: Distributes inference workloads across devices and servers, allowing edge nodes to process initial layers and offload complex computations to more powerful servers.
- Split Inference: Separates inference tasks into device-side and server-side components, minimizing communication overhead and latency.
Integrated Communication and Computing
Seamless communication between edge nodes is critical for handling the computational demands of LLMs:
- Task-Oriented Communication Protocols: Focuses on transmitting only essential features or intermediate data, reducing bandwidth usage.
- Dynamic Resource Allocation: Allocates network and computational resources based on real-time demand, ensuring optimal performance for edge-deployed LLM.
By leveraging these architectural innovations, edge systems can unlock the full potential of LLMs. These frameworks not only optimize resource use but also ensure scalability, privacy, and efficiency for edge-based applications.
Current Landscape and Industry Applications of Edge-Based Language Models
The deployment of Large Language Models (LLMs) at the edge is reshaping industries by enabling real-time, localized, and efficient AI applications. This section examines the current landscape, focusing on how organizations are leveraging edge-based LLMs and the strategies driving their adoption.
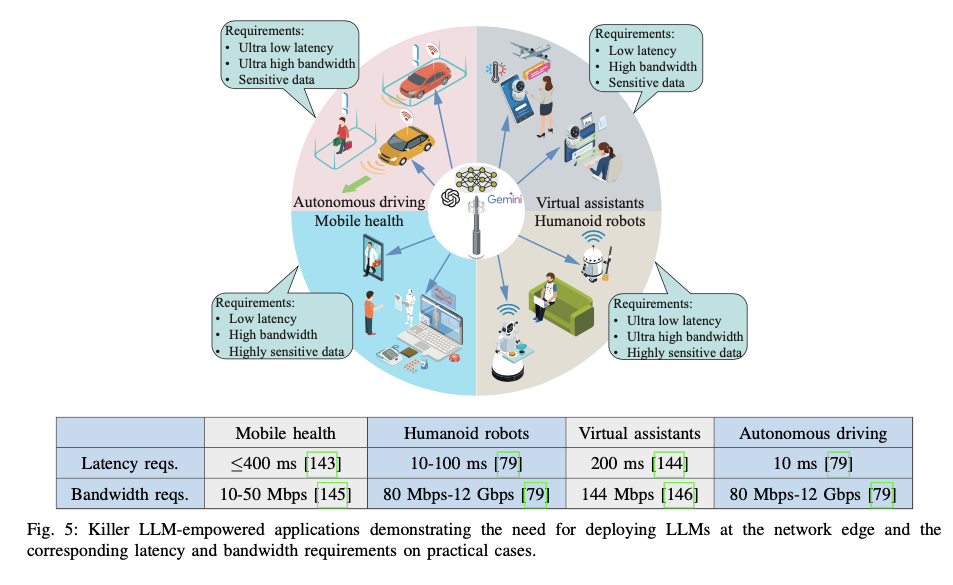
Pioneering Use Cases
- Healthcare
- Applications: Edge-deployed LLMs like Google’s Med-PaLM are revolutionizing patient care by providing real-time diagnostic insights while preserving data privacy. By processing data locally, these models enable hospitals to make critical decisions faster and comply with privacy regulations.
- Outcomes: Enhanced patient outcomes through rapid analysis and reduced dependency on cloud infrastructure.
- Robotics
- Applications: Robotics systems, such as Google’s PALM-E, integrate LLMs for autonomous task execution and environmental understanding. Edge deployment reduces latency, enabling robots to interact more efficiently in dynamic environments.
- Outcomes: Improved decision-making and responsiveness in robotics for applications like industrial automation and home assistance.
- IoT Networks
- Applications: LLMs embedded at the edge in IoT ecosystems support semantic communication, enabling devices to interpret and act on high-level user commands. For example, a smart home assistant can manage multiple tasks with a single instruction, such as setting up a “movie night” by dimming lights and adjusting room temperature.
- Outcomes: Increased efficiency, user satisfaction, and resource optimization in IoT applications.
- Autonomous Driving
- Applications: Edge-based LLMs process sensor data in real-time to assist with navigation and decision-making. For example, LLMs can understand complex scenarios, such as recognizing construction zones, and suggest alternative routes.
- Outcomes: Safer, more reliable autonomous vehicles with reduced reliance on external networks.
Industry Strategies for Edge Deployment
- Model Optimization
Companies focus on model compression and parameter-efficient fine-tuning to make LLMs feasible for edge environments. Techniques like LoRA and QLoRA allow the deployment of compact yet powerful models. - Collaborative Edge Frameworks
Collaborative inference and distributed training strategies ensure efficient resource utilization. By splitting workloads across devices and edge servers, organizations achieve better performance and reduced latency. - Privacy-First Design
Industries prioritize data protection by leveraging edge computing’s ability to process information locally. This approach is particularly valuable in healthcare and financial applications, where data sensitivity is paramount.
Comparative Analysis of Edge Deployment Approaches
| Industry | Edge Deployment Strategy | Key Benefits | Challenges |
|---|---|---|---|
| Healthcare | Federated learning for personalized care | Privacy compliance, faster diagnosis | Data heterogeneity across devices |
| Robotics | Split inference for real-time interaction | Reduced latency, improved adaptability | High computational demands |
| IoT | Semantic communication for task automation | Streamlined interactions, lower bandwidth usage | Limited processing power of devices |
| Autonomous Driving | On-device processing for safety-critical tasks | Low-latency decisions, enhanced reliability | Bandwidth-intensive sensor data |
The Path Forward
As edge deployment gains traction, industries must continue refining their strategies:
- Interoperability: Ensuring that models can work seamlessly across diverse edge devices and ecosystems.
- Scalability: Developing frameworks to handle growing volumes of data and user interactions without compromising performance.
- Sustainability: Investing in energy-efficient techniques to minimize the environmental impact of edge-based LLMs.
By embracing edge deployment, industries are unlocking new capabilities and transforming how AI interacts with the physical world. These advancements highlight the potential of LLMs to drive innovation across domains while addressing latency, privacy, and efficiency challenges.
Overcoming Challenges and Shaping the Future of Edge-Based Language Models
Deploying Large Language Models (LLMs) at the edge is a promising solution to address latency, privacy, and bandwidth challenges. However, significant hurdles remain, including resource constraints, data heterogeneity, and energy inefficiency. This section highlights the path forward for edge-based LLMs.
Key Challenges
- Resource Limitations: Insufficient computational power, memory, and storage in edge devices constrain LLM deployment.
- Data Heterogeneity: Diverse and unstructured data from IoT and real-time applications require robust processing mechanisms.
- Privacy and Security: Distributed edge nodes must safeguard sensitive data and prevent cyber threats.
- Energy Efficiency: High energy consumption limits scalability on edge devices.
Future Directions
- Model Optimization
Techniques like parameter-efficient fine-tuning (e.g., LoRA) and quantized training reduce resource demands while maintaining performance. - Distributed Collaboration
Frameworks like split and federated learning optimize resources and enhance scalability while preserving data privacy. - Sustainable Architectures
Energy-saving methods, such as sparsity prediction and speculative decoding, combined with low-power hardware, will improve efficiency. - Privacy-Centric Solutions
Advanced encryption and secure federated models ensure data protection without compromising performance.
The Road Ahead
Edge-based LLMs represent the future of AI deployment, enabling smarter, localized, and more responsive systems. By addressing challenges and leveraging emerging innovations, industries can unlock their transformative potential in domains such as healthcare, IoT, and autonomous driving.