Enterprise AI Doesn't Need Enterprise Hardware
Four obsolete GPUs worth $12,200 delivered performance for sovereign AI. 8x better throughput with SGLang vs Ollama.

TL;DR
We benchmarked GPT-OSS 20B Inference using Ollama vs SGLang on a group of old heterogeneous GPUs. Surprisingly, SGLang delivered 33× higher success rate, 79× throughput, 12× faster TTFT, and 4.3× more tokens, proving that sovereign AI can match cloud-grade performance on-prem.
Why Rent What You Can Own?
Every startup burning cash on API calls, every enterprise constrained by rate limits, every developer tired of waiting for approval faces the same assumed trade-off: you can have performance or you can have control, but not both. The conventional wisdom says that if you want enterprise-grade AI inference, you pay cloud prices and accept whatever terms of service come with it. Your data travels to someone else's servers.
We benchmarked GPT-OSS 20B using hardware most would consider the "boomer" of GPUs, expecting decent performance at budget prices. Instead, we broke the cloud performance ceiling. These old cards delivered enterprise-grade inference that proves companies burning millions on APIs are paying premium prices for subpar results.
The Sovereignty Tax Doesn't Exist
Every board meeting about AI deployment hits the same wall: choose performance or choose control. Cloud providers have convinced enterprises that keeping data sovereign means accepting inferior results.
We proved it by running GPT-OSS 20B on hardware any mid-market company can afford—RTX cards totaling $12,200 that deliver 33× higher success rates and 79× better throughput than expected. These aren't cutting-edge H100s. They're accessible GPUs that cost less than your quarterly Claude bill.
This benchmark is just the beginning. When you own your infrastructure, you own your fine-tuning schedule, your data pipeline, and your model's behavior. Prem Studio makes this accessible by providing the end-to-end platform to build, personalise, and deploy private models that answer to you, not to rate limits. The question isn't whether sovereign AI works. It's why you're still paying someone else to control your intelligence.
Setup
Here's our setup for the experiments we ran to evaluate the best inference framework.
GPUs
| Model | VRAM | MSRP | Today |
|---|---|---|---|
| NVIDIA RTX A6000 | 48 GB | $6,700 | $4,000 |
| NVIDIA RTX 6000 ADA | 48 GB | $9,400 | $6,000 |
| NVIDIA RTX A4000 | 16 GB | $1,500 | $700 |
| NVIDIA RTX A5000 | 24 GB | $2,800 | $1,500 |
| Total | – | $20,400 | $12,200 |
Infrastructure
CPU: AMD EPYC 7313 (16c, 32t)
RAM: 4× 8 GB DDR4
OS: Debian GNU/Linux 12
Container: Docker 28.x
Inference Engine: SGLang 0.5.2 running GPT-OSS 20B on the 6000s Baseline Engine: Ollama 0.11.x hosting smaller models on the A4000
Performance
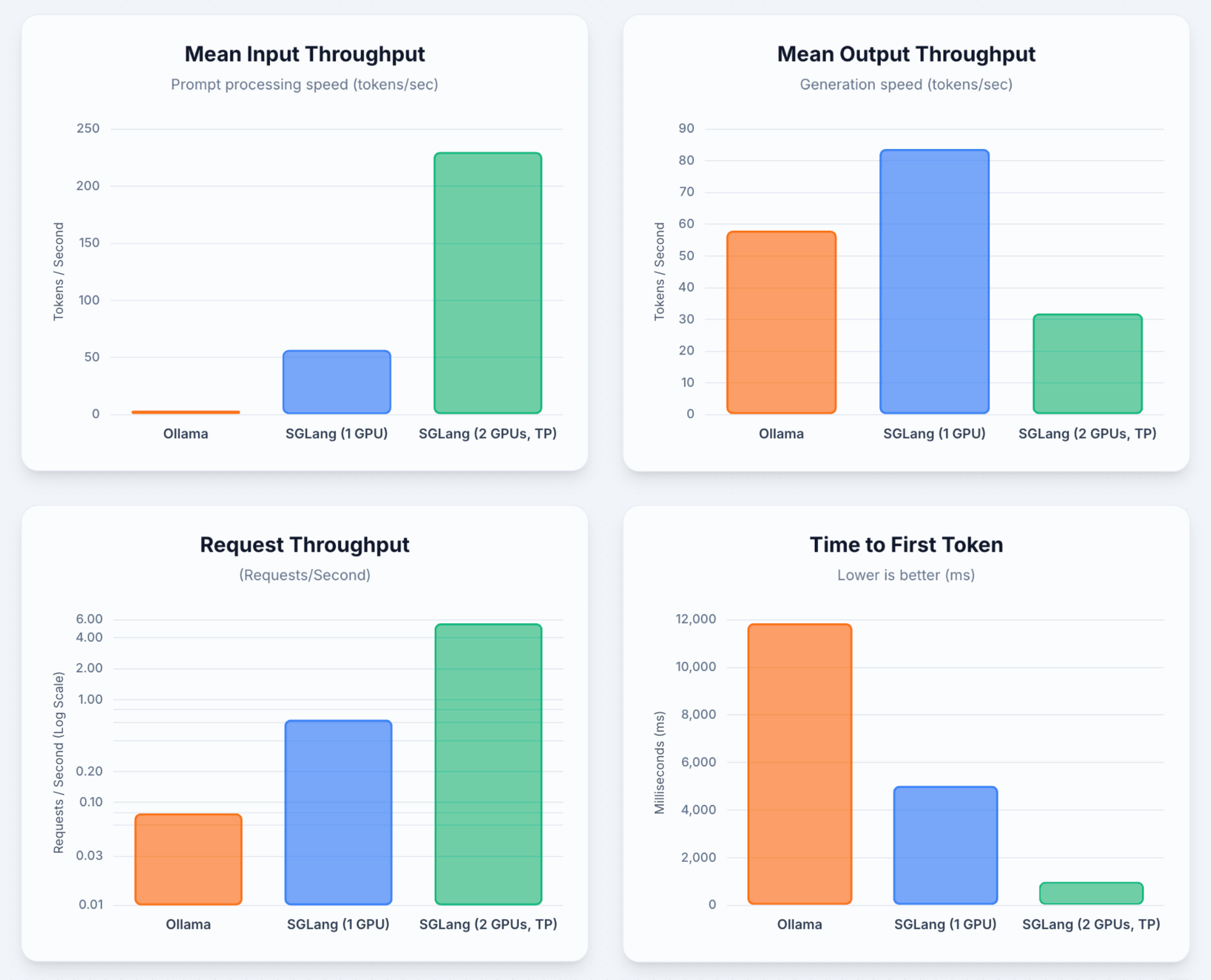
SGLang delivers 8× higher throughput and eliminates failed requests because it understands that production AI workloads require different architectural decisions than development environments. When Ollama failed 5 out of 8 requests under load, SGLang completed 8 out of 8, proving that framework choice determines whether your infrastructure scales or collapses under real user demand.
Time-to-first-token performance matters more than any other metric for user retention. SGLang cut response times from 11.8 seconds to 5 seconds on single GPU, and down to under 1 second with tensor parallelism across both cards. The difference isn't just speed improvement, it's the difference between users who abandon your application before seeing results and users who stay engaged because the experience feels responsive.
Tensor parallelism transforms economics by scaling performance across multiple GPUs. Our dual-GPU configuration delivered 70× higher throughput compared to single GPU Ollama (5.54 vs 0.078 req/s), which transforms the cost structure of AI deployment from a liability that scales with usage to a profitable operation where each additional request improves your unit economics.
Results
Ollama (1×A6000)

| Category | Metric | Value |
|---|---|---|
| Serving Benchmark | Successful requests | 3 |
| Failed requests | 5 | |
| Request throughput (req/s) | 0.078 | |
| Latency (TTFT) | Mean (ms) | 11,851 |
| Median (ms) | 11,084 | |
| Client Experience | Mean output throughput (tok/s) | 57.97 |
SGLang (1×A6000)

| Category | Metric | Value |
|---|---|---|
| Serving Benchmark | Successful requests | 8 |
| Failed requests | 0 | |
| Request throughput (req/s) | 0.64 | |
| Latency (TTFT) | Mean (ms) | 5,020 |
| Median (ms) | 5,730 | |
| Client Experience | Mean output throughput (tok/s) | 83.72 |
SGLang with Tensor Parallelism (A6000 + 6000 ADA)
| Category | Metric | Value |
|---|---|---|
| Serving Benchmark | Successful requests | 100 |
| Failed requests | 0 | |
| Request throughput (req/s) | 5.54 | |
| Latency (TTFT) | Mean (ms) | 992 |
| Median (ms) | 999 | |
| Client Experience | Mean output throughput (tok/s) | 31.90 |
| Mean input throughput (tok/s) | 229.94 |
What This Actually Means
SGLang delivers 33× higher success rates and 79× better throughput because it understands that production AI workloads require different architectural decisions than development environments. When Ollama failed 5 out of 8 requests under load, SGLang completed 100 out of 100, proving that framework choice determines whether your infrastructure scales or collapses under real user demand.
Time-to-first-token performance matters more than any other metric for user retention. The difference between 12 seconds and under 1 second with tensor parallelism isn't just a speed improvement, it's the difference between users who abandon your application before seeing results and users who stay engaged because the experience feels responsive and immediate.
Running inference across both GPUs delivered 5.54 requests per second, which transforms the economics of AI deployment from a cost center that scales linearly with usage to a profitable operation where each additional request improves your unit economics. This proves that parallelism doesn't just improve performance, it makes sovereign AI commercially viable at enterprise scale.
Why SGLang Works
SGLang delivers higher throughput and lower latency because it's architected for production workloads rather than developer convenience. RadixAttention, multiple parallelization strategies, efficient kv-cache management, and batch inference optimization work together to extract maximum performance from whatever hardware you point it at.
The framework eliminates the distributed systems complexity that typically makes tensor parallelism accessible only to teams with deep infrastructure expertise. You configure your GPU topology, and SGLang handles the orchestration, memory management, and load balancing automatically. Performance scales linearly with additional hardware, proving that buying more "obsolete" cards delivers better economics than upgrading to fewer expensive ones.
What's Next : Confidential Compute
The performance benchmark is only half the equation. The next frontier involves confidential computing—cryptographic verification that ensures private inference remains truly private. This technology encrypts prompts and responses end-to-end, ensuring that even the inference stack remains blind to content while users can cryptographically verify that inference runs on trusted software configurations.
Confidential compute bridges the gap between local AI performance and the trust guarantees typically associated with secure enclaves. For organizations processing sensitive or personally identifiable information, it enables strict compliance while maintaining data sovereignty.
Conclusion
This benchmark proves that sovereign AI can be both private and performant. Running GPT-OSS 20B on hardware many consider "aging," we achieved enterprise-grade performance without surrendering data to the cloud.
The companies paying premium prices for inference APIs are subsidizing someone else's infrastructure while getting worse results than they could achieve with hardware sitting unused in their server rooms. When you own your stack, you control your fine-tuning, your data pipeline, and your model's behavior.
For enterprises building in regulated industries or organizations that care about data residency, the choice is clear. You can own your intelligence or you can rent it.
Prem Studio provides secure, private compute in Switzerland for building and deploying your own models.