Enterprise AI Evaluation for Production-Ready Performance
A deep dive into PremAI’s enterprise evaluation framework, covering rubric-based scoring, BYOE integration, and the processes that ensure reliable, production-ready AI model performance at scale.

Evaluation represents the critical final validation step before deploying AI models to production environments. PremAI's evaluation framework delivers quantifiable insights into model performance, enabling technical leaders to make data-driven deployment decisions.
Our previous articles covered the strategic importance of enterprise dataset automation and production-scale fine-tuning. While building and training models addresses immediate business requirements, confirming their real-world performance before production deployment remains essential.
This third installment in our Prem Studio series examines evaluation methodology. The evaluation phase validates that models deliver consistent results in production environments, not merely in controlled test scenarios. Prem's evaluation framework combines customizable rubric-based metrics with seamless system integration, providing complete visibility into model performance and behavior.
Why Evaluation Requires Executive Attention
Evaluation forms an integral component of every model development lifecycle. Large language models (LLMs) and small language models (SLMs) present unique evaluation challenges. Traditional mathematical metrics such as ROUGE scores and BLEU offer limited insight into LLM performance. Additionally, LLM-as-judge evaluation approaches introduce inherent biases, making score attribution difficult to interpret.
The challenge intensifies when reference outputs are unavailable, creating interpretability gaps in the evaluation process. Prem Platform addresses these complexities through a streamlined yet comprehensive evaluation pipeline built on two core offerings:
Agentic Evaluation: For organizations without existing evaluation infrastructure seeking to leverage Prem's evaluation capabilities:
The process involves two steps:
- Metric Creation: Organizations define their evaluation criteria in natural language, specifying what the metric should quantify and assess. Prem's intelligence model generates a comprehensive set of rules (collectively termed Rubrics) to evaluate model outputs.
- Rubric-Based Assessment: A specialized LLM-as-judge pipeline applies user-defined metrics, delivering scores and detailed reasoning based exclusively on the specified criteria.
BYOE (Bring Your Own Evaluation): For enterprises with established evaluation infrastructure that prefer to maintain evaluation results within the Prem ecosystem.
These two approaches provide comprehensive coverage of the evaluation lifecycle across different models and use cases. The following sections detail each methodology and explain how evaluation integrates with data augmentation and fine-tuning capabilities.
Prem's Agentic Evaluation Framework
Prem's evaluation process consists of two phases: metric creation and judge-based evaluation using those metrics. To illustrate the concept of metrics, consider this dataset example:
System Prompt:
You are a helpful recipe assistant.
You are to extract the generic ingredients from each of the recipes provided.
User:
Title: Quick Coffee Cake(6 Servings)
Ingredients: "3 Tbsp. softened butter or margarine", "1/2 c.
granulated sugar", "1 egg", "1 c. flour", "1 1/4 tsp. baking powder",
"1/4 tsp. salt", "1/3 c. milk", "1/4 tsp. vanilla", "1/3 c. brown sugar,
packed", "1/2 tsp. cinnamon", "2 Tbsp. butter or margarine"
Generic ingredients:
A:
["butter", "sugar", "egg", "flour", "baking powder", "salt", "milk", "vanilla", "brown sugar", "cinnamon", "butter"]
In a scenario where a small language model is trained for this specific task, the evaluation criteria would include:
- Verification that the correct ingredient set appears in model output
- Confirmation that output follows proper list formatting conventions
- Validation that ingredients are not duplicated and no extraneous ingredients are added
Traditional metrics cannot adequately evaluate these scenarios. A standard LLM-as-judge would provide a score without transparent scoring criteria. This gap highlights the necessity for well-defined metrics.
Understanding Prem Metrics
Metrics comprise a set of rules (positive and negative criteria), collectively called rubrics. For the ingredient extraction example, an Ingredient-check metric might include these rubrics:
Positive Criteria (Requirements for acceptable output):
- Outputs a valid Python list
- Avoids duplicate ingredients
- Contains the complete set of generic ingredients
Negative Criteria (Disqualifying output characteristics):
- Includes text outside a Python list
- Contains duplicate ingredients within the list
- Omits ingredients present in the reference output
Prem Metrics accommodates up to five positive and five negative rules per metric. Manual rule creation can be time-intensive, so Prem Intelligence automates this process. Organizations describe their evaluation requirements in plain language, and the system generates appropriate rules.
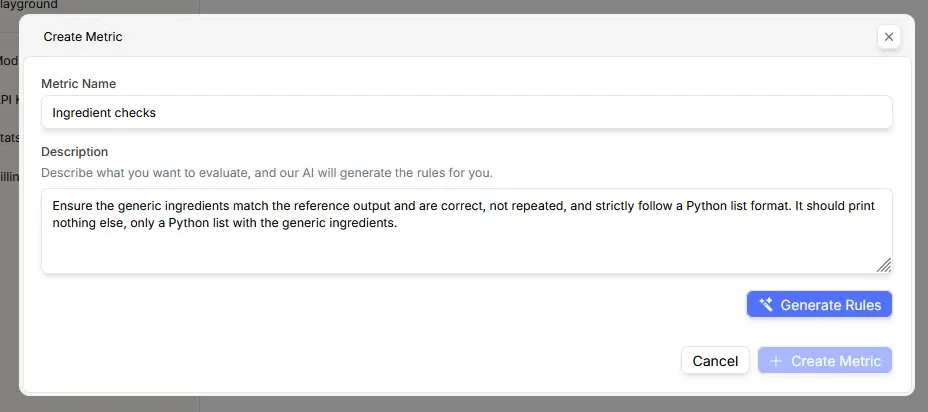
After articulating evaluation requirements, the system generates these rules:
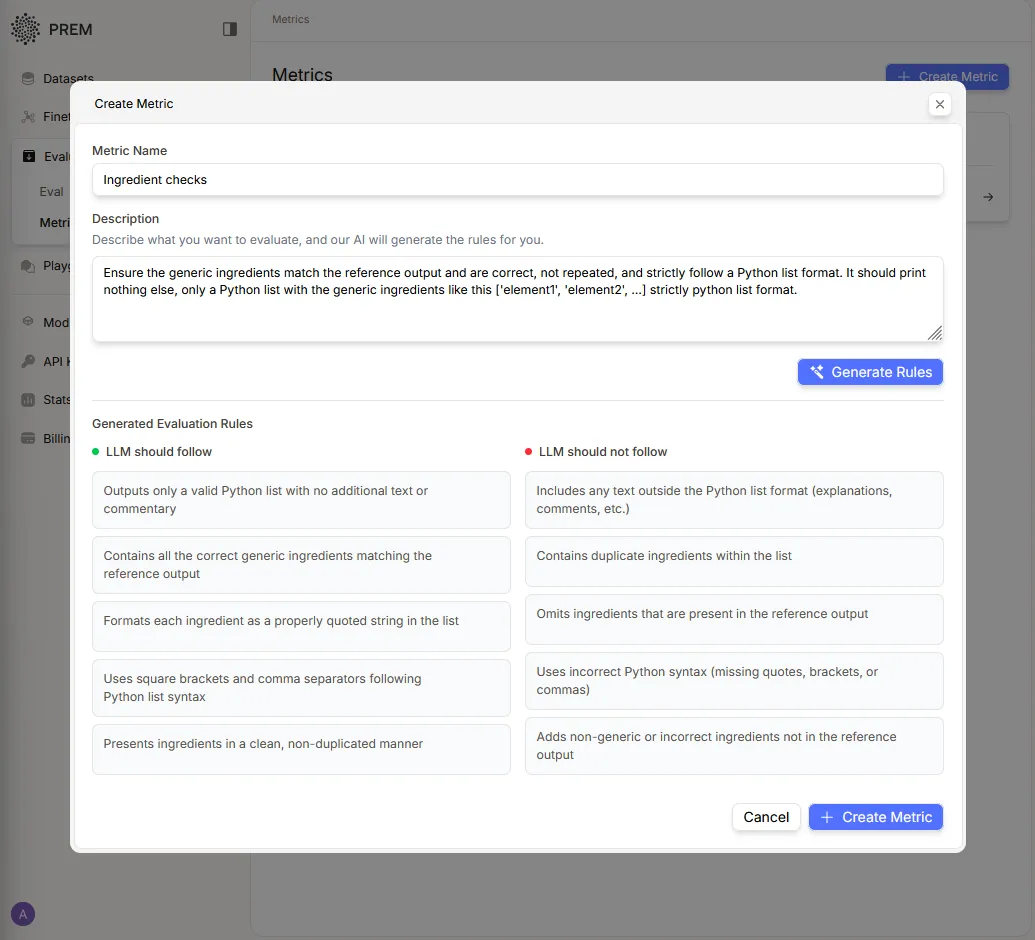
Rules can be modified to incorporate specific organizational requirements. Multiple metrics can be created using this approach. All metrics are stored in the metrics section for future editing or deletion as needed.
Executing Evaluation with Prem Metrics
Evaluation with Prem Metrics follows a straightforward process. Navigate to the evaluation section, select the dataset snapshot for evaluation, choose the models to evaluate, and specify the required metrics. Once initiated, the evaluator engine begins streaming results automatically.
Evaluation Methodology
Before examining results, understanding the evaluation process is essential. When an evaluation job is launched with selected metrics, Prem employs the defined rubrics with a specialized Judge model to provide qualitative evaluation based on those rubrics, instructing the LLM to provide reasoning for each rubric.
The LLM determines whether the evaluated answer adheres to each specific rubric, providing a binary response with supporting reasoning.
An aggregation step follows, consolidating all rubric results and scores to produce a final score and verdict. The verdict functions as an evaluation report, identifying precisely where the model succeeded and where it fell short.
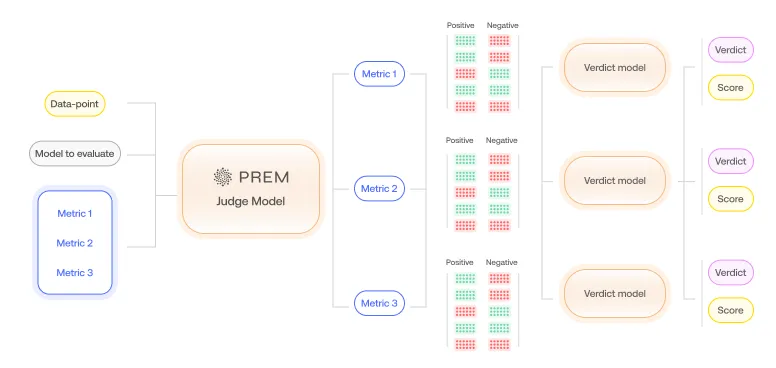
Analysis of results from Prem Agentic evaluation on the above dataset reveals the following. Upon evaluation completion, the dashboard displays:
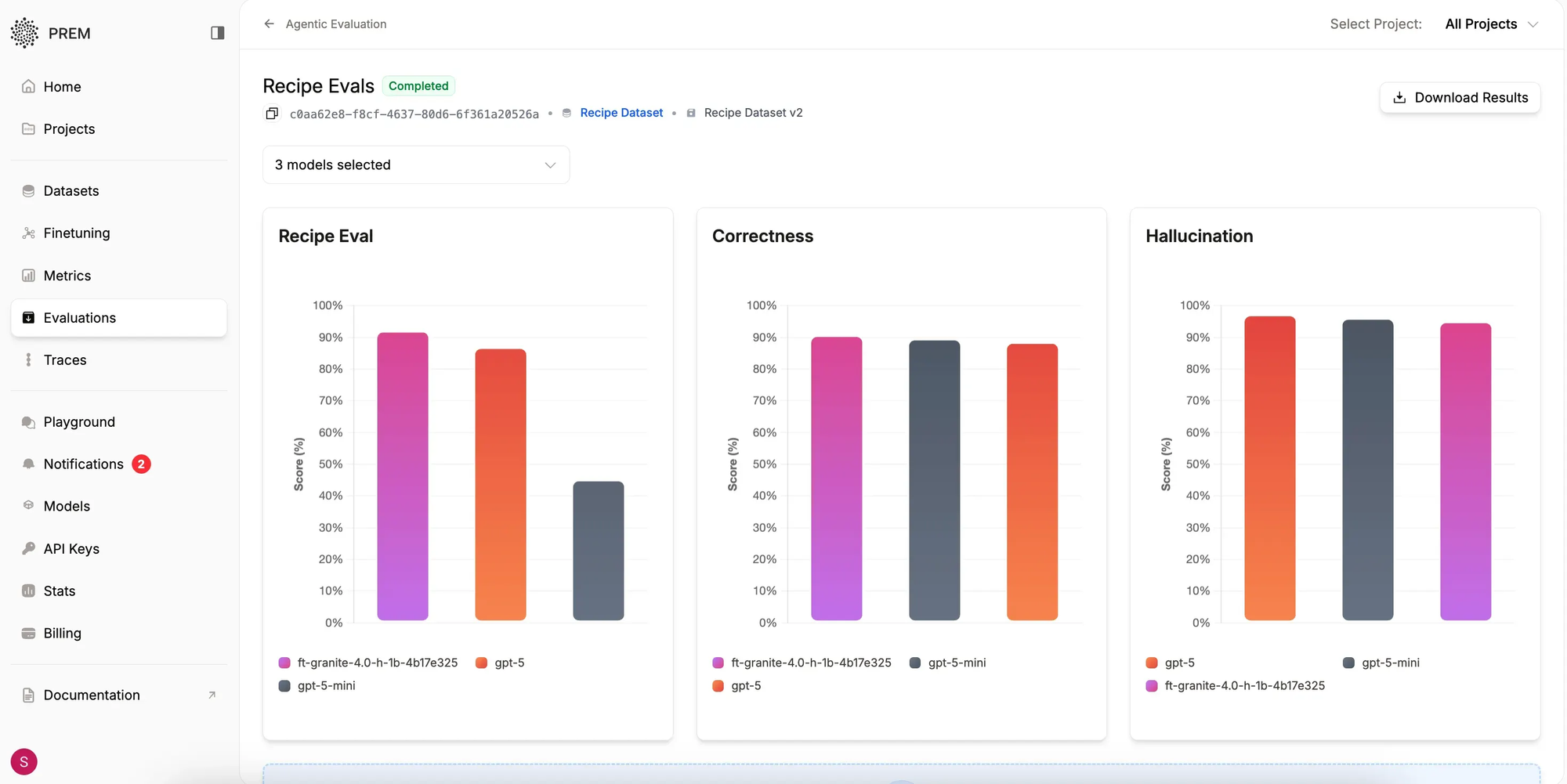
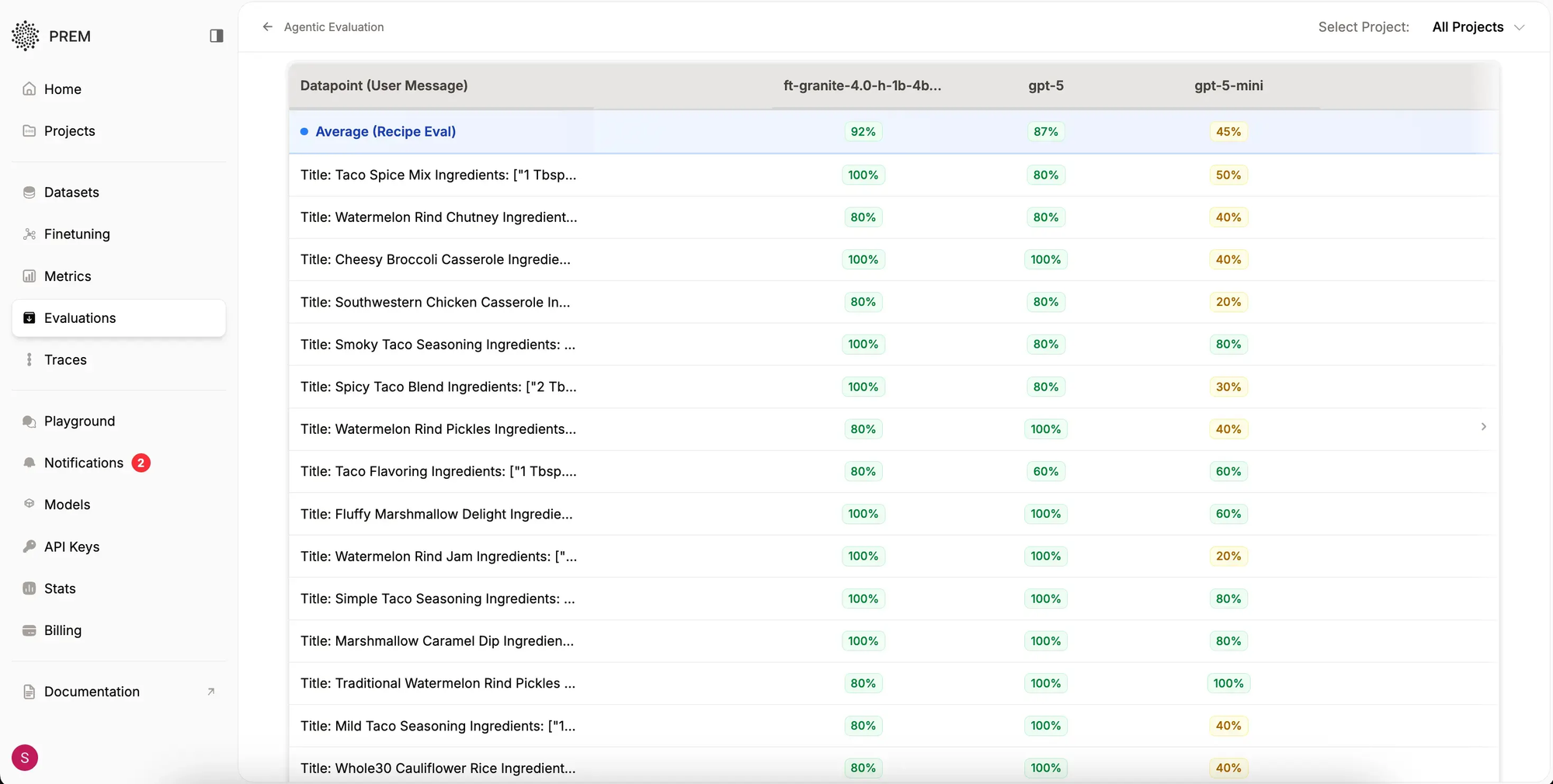
The summary shows overall model performance for each metric. For this experiment IBM’s granite-4-h-1b model is finetuned. This models were evaluated using the defined metric above, along with Prem's default Correctness metric.
The results reveal that while closed-source models perform well on correctness measures, they underperform on custom-defined metrics. Detailed results are available by tapping each row of the evaluation leaderboard, which displays a dialog such as:
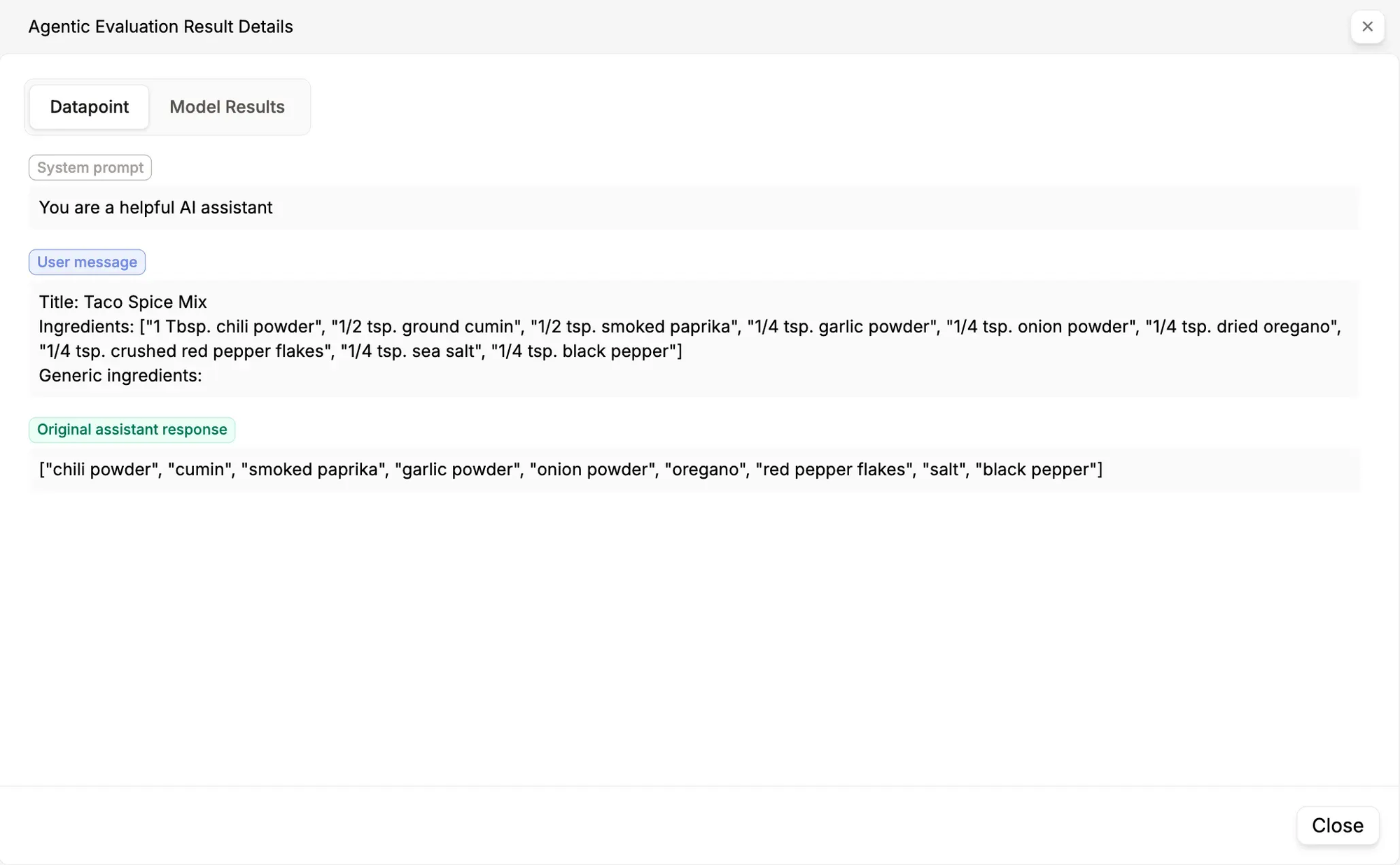
The datapoint, user input, and ground truth response are visible here. The Model Results section displays:
The initial output is a verdict, a concise summary highlighting strengths and weaknesses of the model's response.
A detailed view follows, showing performance against provided rubrics, clarifying which rules the model followed and which it violated.
Scoring calculation is transparent: the number of satisfied positive rules divided by total rules, multiplied by 100. This transparency eliminates uncertainty about score derivation. If the scoring approach is unsatisfactory, rule sets can be edited or new metrics created.
The evaluation analysis for the closed-source model shows:
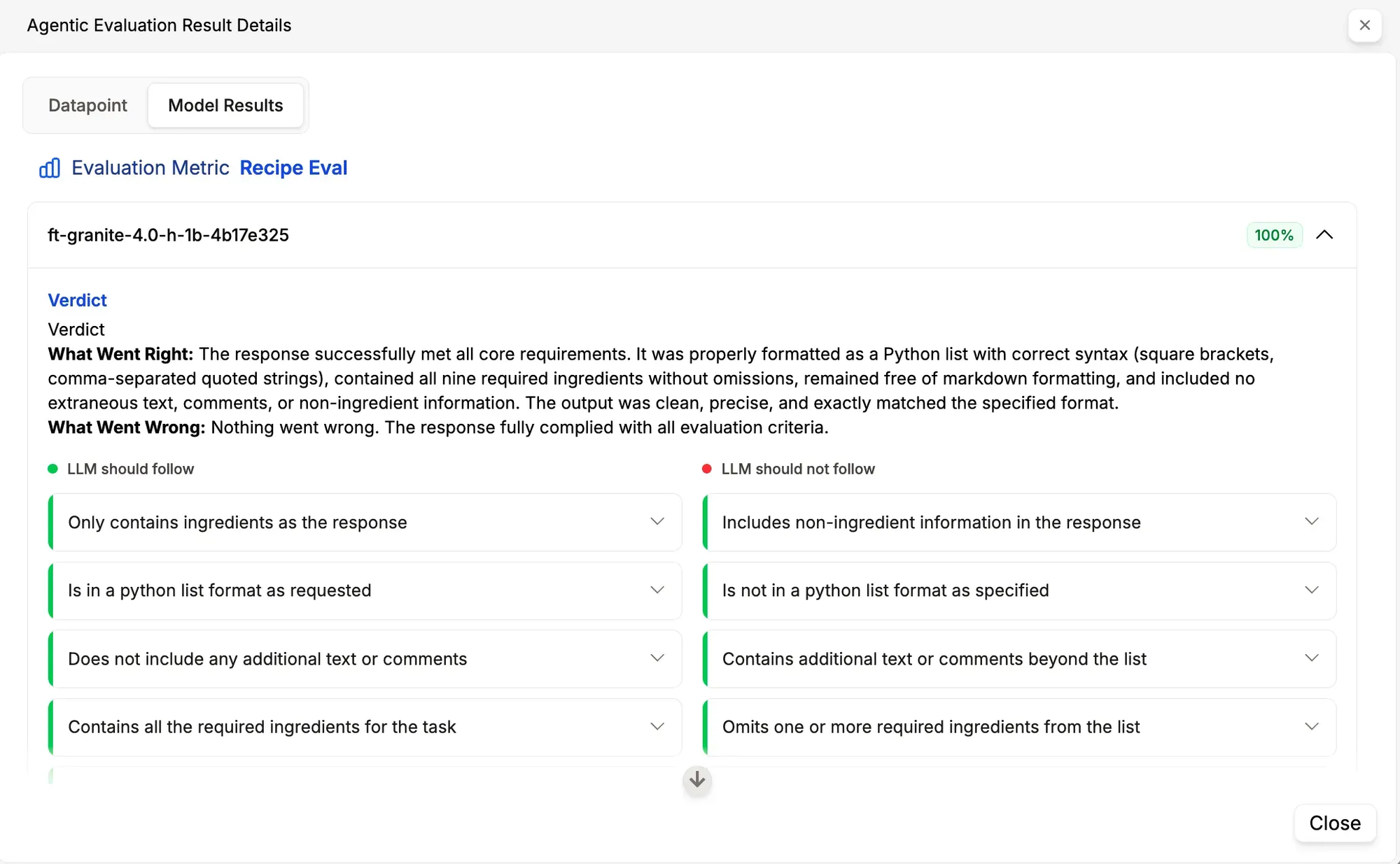
Similarly, it highlights violated rules in red and adjusts scores accordingly.
Strategic Value of Prem Agentic Evaluation in Model Lifecycle Management
The previous section demonstrates the reliability of Prem Agentic evaluation. Through user-defined custom metrics, organizations can pinpoint exactly where models underperform and where they excel.
This intelligence enables creation of improved synthetic datasets that address identified weaknesses by generating training data that teaches models how to improve on deficient areas. Once enhanced synthetic datasets are generated, iterative improvement of existing fine-tuned models proceeds through Prem continuous fine-tuning.
Bring Your Own Evaluation
Bring Your Own Eval serves organizations that have established proprietary evaluation methods and wish to evaluate Prem's fine-tuned models on their own infrastructure while logging results on Prem's evaluation dashboards.
Setup Configuration
To begin evaluation by bringing your own evaluator to Prem, create an evaluation endpoint that Prem Studio will ping with the selected dataset for evaluation. Detailed instructions are available here:
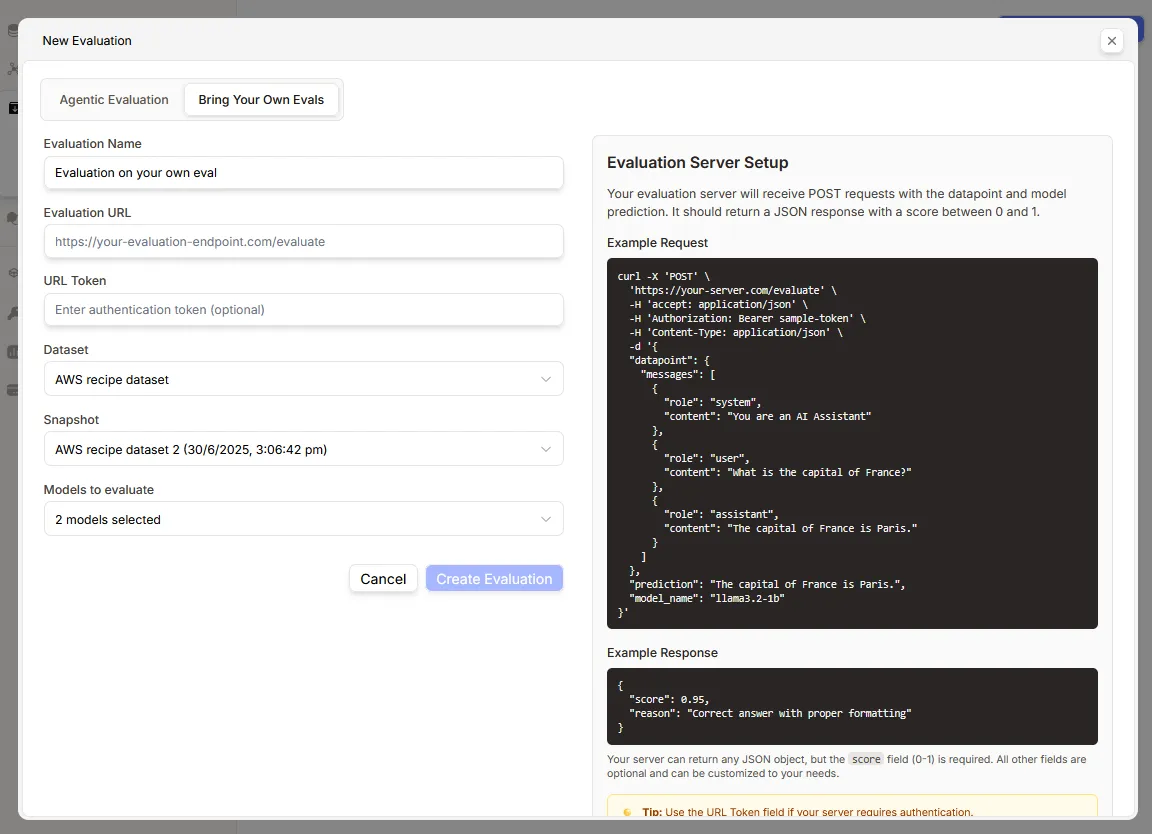
The Prem Studio server transmits each datapoint in the selected snapshot, model names, and their responses, expecting a score and evaluation reasoning in return. The evaluation endpoint returns a score and optionally other evaluation-related information for display in the final result.
This approach enables in-house evaluation using Prem infrastructure and models without exposing evaluation intellectual property.
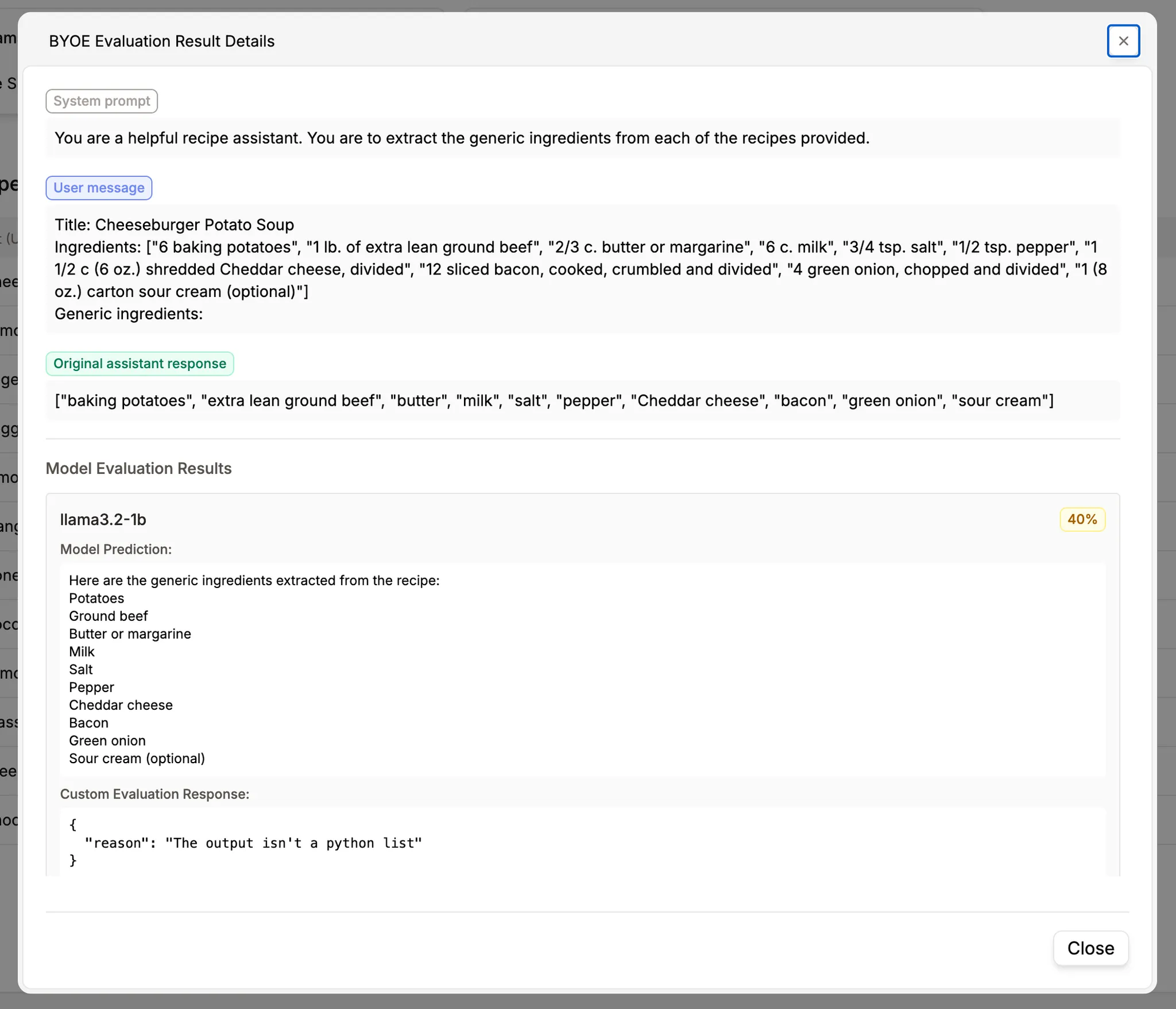
Sample evaluation endpoint result:
Strategic Implementation Considerations
A robust dataset and precisely fine-tuned model form the foundation of successful AI systems, but their value depends entirely on the ability to measure real-world performance accurately. Prem Studio's flexible, transparent evaluation tools eliminate guesswork and deliver actionable insights into actual model performance. Whether leveraging Prem's agentic evaluation or implementing your own approach, complete control and confidence are maintained throughout the process.
The next article examines the final component: deploying models into production and delivering fast, reliable inference at scale. The transition from development to real-world impact will be addressed comprehensively.
Start evaluating your models today with Prem Studio.
Learn more about Prem Evaluations.
Frequently Asked Questions
- Why does evaluation matter for enterprise AI initiatives?
Evaluation confirms that models perform reliably in production scenarios, not solely in controlled testing environments. - How does PremAI enhance evaluation processes?
PremAI provides custom, rubric-based evaluation with seamless integration for transparent, actionable results. - What post-evaluation capabilities does PremAI offer?
The platform uses evaluation insights to improve datasets and fine-tuning processes, enabling continuous model enhancement. - What are Prem Metrics and how do they function?
Prem Metrics are custom evaluation tools built on rubrics, which are sets of positive and negative rules defining acceptable and unacceptable model output characteristics. They provide transparent, rule-based scoring for AI models. - Can evaluation metrics be modified after creation?
Yes, metrics can be edited or deleted at any time. If scoring results are unsatisfactory, rule sets can be modified or entirely new metrics created to better align with organizational requirements. - How many rules can be included in a single metric?
Prem Metrics supports up to five positive rules and five negative rules per metric, providing granular control over evaluation criteria. - How does Bring Your Own Eval (BYOE) function?
BYOE enables organizations to use proprietary evaluation methods on their own infrastructure while logging results in Prem's dashboards. Your evaluation endpoint receives datapoints and model responses, then returns scores and reasoning without exposing intellectual property.
Early Access
Early access to Prem Studio is now available. Teams developing reliable, production-grade AI systems can apply for access and begin development immediately.
Sign up and claim $5 in credits: https://studio.premai.io/