
MoEs comeback in GenAI with Mixtral
This article takes a deep dive into Mixture of Experts models, spotlighting Mistral's latest release. Learn how this architecture enhances AI scalability, efficiency, and performance, paving the way for next-gen AI systems that balance resource optimization with powerful capabilities.

Just yesterday, Mistral AI announced their new model Mixtral 8x7B. It is a high-quality Sparse Mixture of Expert models (SMoEs). Its weights are open-source and licensed under Apache 2.0
magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%https://t.co/uV4WVdtpwZ%3A6969%2Fannounce&tr=http%3A%2F%https://t.co/g0m9cEUz0T%3A80%2Fannounce
— Mistral AI (@MistralAI) December 8, 2023
RELEASE a6bbd9affe0c2725c1b7410d66833e24
The OG release tweet of the Mixtral model by Mistral AI
This blog post explores the intricacies of MoE, its historical roots, potential connections with GPT-4, and the unique aspects of the Mistral model. It's a journey into understanding how MoE models, by allowing for specialized task handling, could revolutionize AI's approach to complex problems. Here's a quick TLDR about Mixtral 8x7B:
- Mixtral outperforms Llama 2 70B on most benchmarks.
- It has a 6x faster inference compared to Llama 2 70B.
- One of the most powerful open-weight models with a permissive license that matches or outperforms GPT-3.5 on most standard benchmarks.
- Handles a context length of whooping 32K tokens, and supports English, French, Italian, German, and Spanish.
- Gracefully handles code generation tasks well.
- The model can be instruction-tuned and achieves a score of 8.3 on the MT bench.
📒 Understanding Mixture of Experts
Mixture of Experts (MoEs) is not a new concept. Very similar to traditional ensemble methods, the idea was originally introduced in the year of 1991 by the paper Adaptive Mixture of Local Experts. The idea of MoE by definition is quite simple. In standard networks, input data is processed linearly, passing through successive layers. MoE models disrupt this linearity by introducing several "expert" networks, each tailored to handle specific tasks or data types. Where each "expert" is nothing but generally a Feed Forward Neural Network (FFN).
Along with the experts, we have a gating mechanism, that plays a crucial role in this setup, directing the input to the most appropriate expert based on its characteristics. This division of labor allows MoE models to specialize, leading to potentially more accurate and efficient outcomes in complex and diverse data distribution, compared to a one-size-fits-all approach (or dense networks). Figure 1 below gives a high-level overview of MoE architecture.
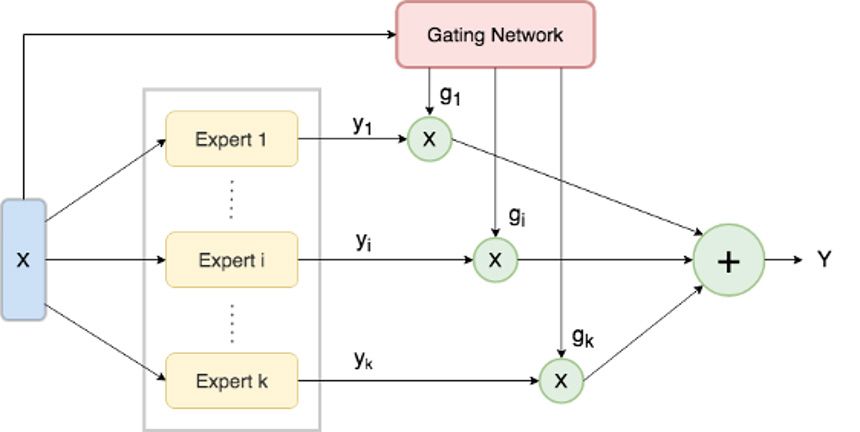
Since, the release of this concept, a lot of work has been done on the architecture in this field. Keeping our interest aligned with Mixtral, we will focus more on the Transformer's aspect of MoEs.
Sparsity in MoEs
The Mixtral model uses Sparse MoEs (or SMoEs). So let's understand what sparse means here. We already know that a dense neural network model is a sequential model, where all the parameters are used. A sparse MoE model does not use all the parameters during prediction computation. The computation is conditioned by putting the input to the best expert out of all of them. This conditioning is learned by a gating network (G) that decides which Expert (E) to choose when certain input is been passed. A typical gating network can simply be a network with a softmax function. There are more complex gating networks like Nosisy top-K gating, however, that is out of the scope of this post.
The idea of sparsity in Networks (a.k.a Sparse MoEs) helps to significantly increase the model size without increasing the computation. However, this comes with a bunch of challenges, as follows:
- Passing inputs into batches is considered to be efficient for dense networks. But for MoEs, it introduces un-even data inflow, where certain experts end up getting more consumed compared to others or get underutilized and hence makes training inefficient.
- The sparse MoE setup is very much prone to overfitting and hence is very hard to train and generalize.
🤖 Incoming of Switch Transformers
Switch Transformers are very important architectures when studying applications of MoEs in Transformers. In the above section, we learned about the cons of using Sparse MoEs. Switch transformers try to mitigate that by proposing a switch transformer layer. See Figure 2, below.
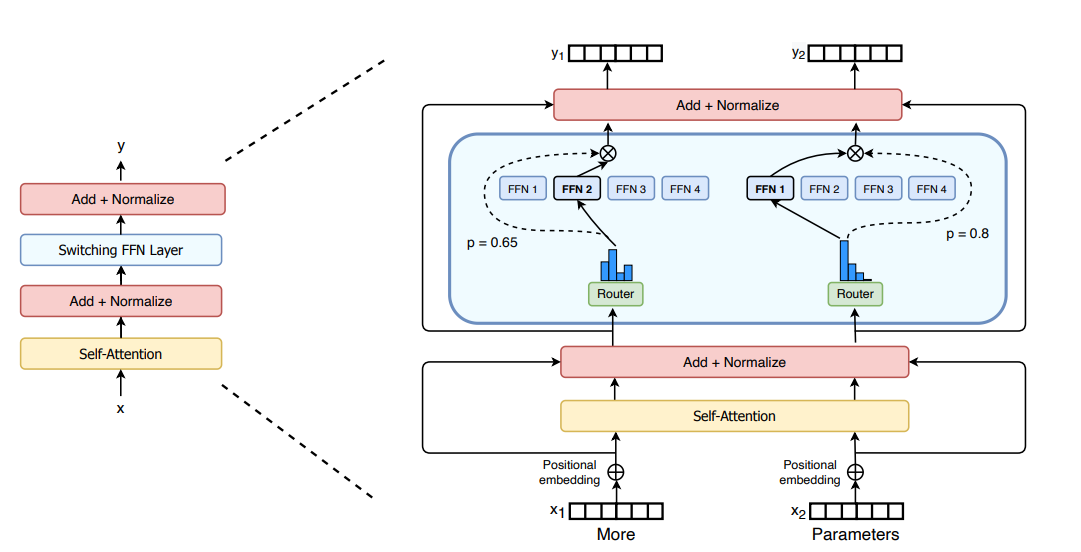
The Switch Transformer paper uses Switch Feed Forward Neural Networks (FFNs). This replaces the traditional point-wise FFN with multiple FFNs, known as Experts. Hence the idea derives from the same old MoE concepts. Once tokens are passed into the self-attention and layer normalization layer, each token is then passed through the Switch Transformer layer. Inside that layer, it passes through the router function (switch) that routes each token to the specific FFN expert.
As each token only passes through one expert FFN, the number of floating-point operations (FLOPS) stays equal, whilst the number of parameters increases with the number of experts.
Capacity Factor
In the previous sections of the blog, we discussed that one key challenge in Sparse MoEs is that, some experts are overutilized compared to others. Switch Transformers tries to mitigate that challenge by introducing a concept called Capacity Factor. The goal here is to route an equal number of tokens to each expert overall so that the computation stays stable. To do this, we define a term called expert capacity (a.k.a batch size of each expert), which is defined as:
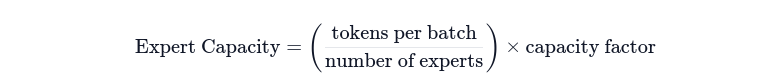
Simply, if the capacity factor is 1, then we can say that at a given batch all the experts are divided equally in terms of compute labor. In that way, no expert is wasted or underutilized in a given step. However, doing this assumes that all the tokens are being equally allocated across the experts. However, in practice it has been seen that certain experts will overflow, resulting in certain tokens not being processed by the other experts,
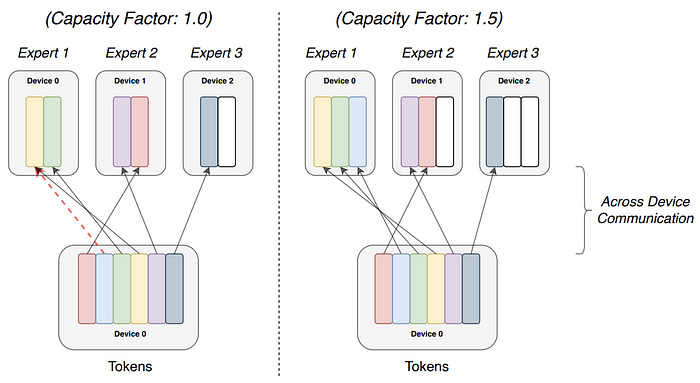
So, to address this, it contradicts itself, by introducing in-balanced routing of tokens by increasing the capacity factor. This although mitigates the overflow problem but has a tradeoff with more computation and inter-device communication during training. The authors also introduced an auxiliary loss that penalizes the unbalanced routing of tokens by the router functions. The Authors found empirically that 1.25 as the capacity factor gives the best performance.
🤔 What do these experts learn?
The figure below is a table from ST-MoE, where the observed the experts in encoder part of (Encoder-Decoder models) exhibit shallow concepts. Examples include, "expert" for punctuation, conjunctions and articles, verbs, etc.
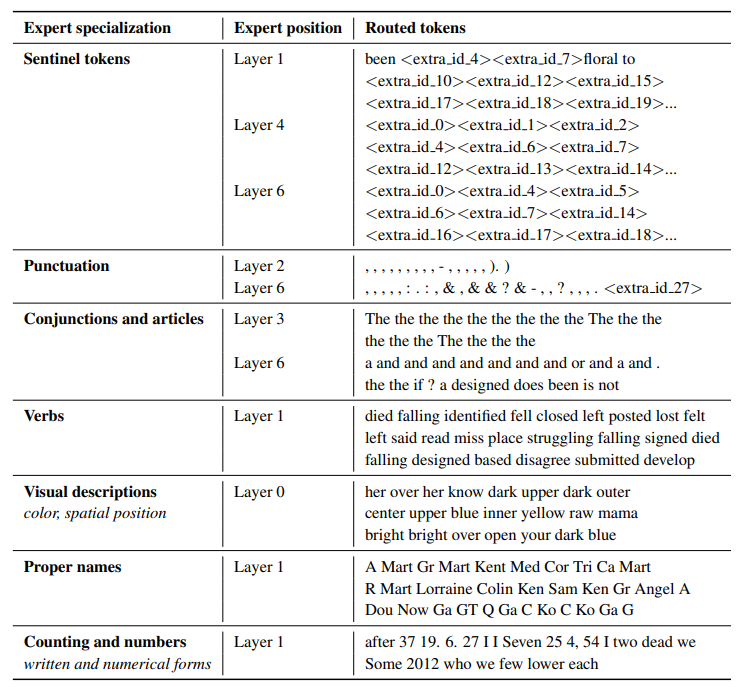
The authors from the same papers also observed that the decoder part of the experts exhibits fewer specializations.
🔬 Back to the current affairs
Phew, so that ends our primer in Mixture of Experts and its current relations and application with Transformers. Our resources section contains some valuable articles and papers which you can check out if you are more interested in taking a deeper dive. Now let's jump into the current news about Mistral AI and speculations of Open AI using MoEs.
MoEs and their relation with GPT-4
i might have heard the same 😃 -- I guess info like this is passed around but no one wants to say it out loud.
— Soumith Chintala (@soumithchintala) June 20, 2023
GPT-4: 8 x 220B experts trained with different data/task distributions and 16-iter inference.
Glad that Geohot said it out loud.
Though, at this point, GPT-4 is… https://t.co/mfsK7a6Bh7
MoEs and their relation with GPT-4
Not only this tweet, but we also got to see a huge number of tweets from some top AI researchers speculating about GPT4 using Mixture of Experts. So, all of these gave us a lot of hints that just increasing the model size might not be the only solution. To prove that hypothesis, Mistral AI finally launched 🎉 Mixtral 8x7B the first Mixture of Experts LLM.
🎸 The Mixtral 8x7B Model
Now if you guessed that the total number of parameters of these models is 56B, then you are not there yet. The model is a 47B parameter model. This is because only the FFN layers are treated as individual experts and the rest of the model parameters (like the attention) are shared. So the memory requirement to fit Mixtral would be the same amount of memory required to fit a 47B parameter model, however the compute (FLOPs) would be significantly lower compared to the same 47B parameter model.
For example, suppose if we only use 2 experts for each token then the inference speed would be like using a 12B model (not 2x7B i.e. 14B, since only FFNs are here experts and others are shared). Similarly, if we consider only one expert is used per token, then the compute would be like using a ~ 6B parameter model. Currently, we do not have much information about the data, or much along the sides of training procedures.
Instruct Models
Mistral 8x7B comes along with instruct models. The instruct model is optimized using Supervised Fine-tuning and Direct Preference Optimisation (DPO). One of the problems with Large Language Models is reliability. Mixtral instruct models claim to ban outputs from applications that require a strong/moderate level of moderation. An example is shown here.
Performance benchmarks
Mixtral brings a significant performance boost both in terms of inference costs and qualitative performance when compared with closed-source models like Open AI gpt-3.5 and Bigger Open-Source Models like Llama 2 70B—more on the figure below.
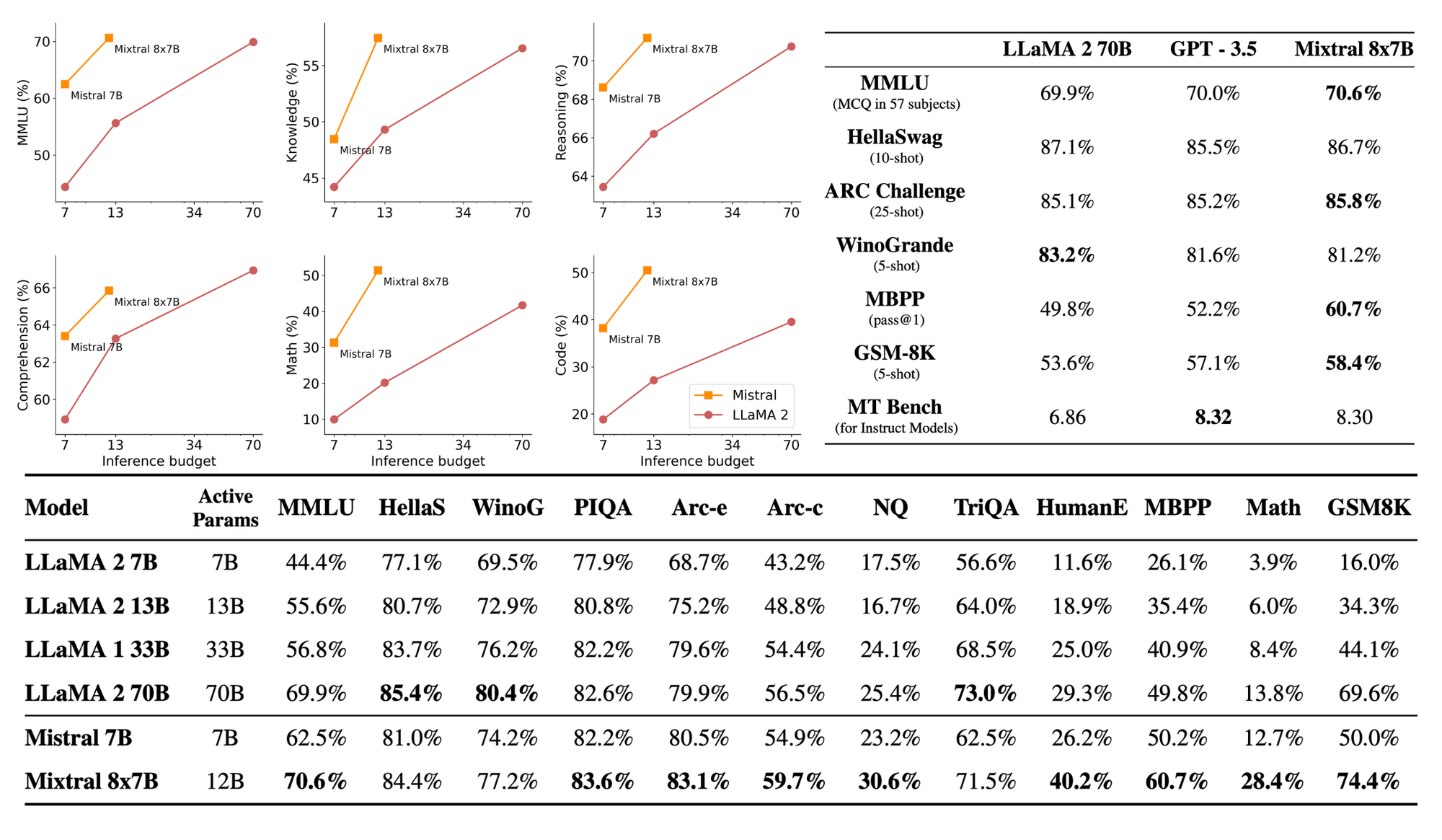
Not only that Mixtral also passes reliability benchmark scores like truthfulness and bias.
"Compared to Llama 2, Mixtral is more truthful (73.9% vs 50.2% on the TruthfulQA benchmark) and presents less bias on the BBQ benchmark. Overall, Mixtral displays more positive sentiments than Llama 2 on BOLD, with similar variances within each dimension."
Last but not least, it also provides a significant improvement in multilingual aspects supporting languages like French, German, Italian, and English.

🚀 Start using Mixtral
You can start getting hands-on with Mixtral either through their premier way, i.e. using the Mistral Platform, or through HuggingFace Transformers.
Mistral AI Platform
Here is the sample code on how to use the Mixtral model using their platform. More on this here.
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
api_key = os.environ["MISTRAL_API_KEY"]
model = "mistral-tiny"
client = MistralClient(api_key=api_key)
messages = [
ChatMessage(role="user", content="What is the best French cheese?")
]
# No streaming
chat_response = client.chat(
model=model,
messages=messages,
)
# With streaming
for chunk in client.chat_stream(model=model, messages=messages):
print(chunk)HuggingFace Transformers
You can also download the model weights and use them with HuggingFace Transformers. Here is the model card to know more details.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))🚴 Open Source and Research
Mixtral opens a whole new avenue for Large Language Models research. Some of the very significant areas of research are as follows:
- Fine-tuning / Instruction tuning Mixtral or LLMs with MoEs. This paper, MoEs Meets Instruction Tuning (July 23), introduces us to performing Single / Multi-task instruction tuning using MoEs.
- Efficient Training and Inference of MoEs. Lots of awesome Open Source Projects like MegaBlocks, FairSeq, OpenMoE are helping us to get started with that.
- Distilling a Large Sparse MoE back to a smaller dense model. For example, distilling Mixtral 8x7B to Mistral 7B would be a great thing to study.
- Another awesome area of open research is quantizing MoE LLMs, like QMoE.
Conclusion
The advent of Mistral's MoE model marks an exciting time in AI, showcasing the potential of specialized, highly efficient neural networks. While current limitations in terms of computational demands pose challenges, the model opens up new avenues for exploration and development. As we continue to refine and adapt these models, we edge closer to more targeted and effective AI applications, promising a future where AI can address an even broader range of complex tasks with precision and efficiency.
Sources and References
- Mixtral-8x7B-v0.1, Mixtral-8x7B-Instruct-v0.1.
- Mixture of Expert Explained by HuggingFace
- Adaptive Mixture of Local Experts (1991)
- ST-MoE: Designing Stable and Transferable Sparse Expert Models (Feb 2022)
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Jan 2022)