Fine-Tuning Phi-3 & Gemma 2: The Budget Path to GPT-4 Performance at a Fraction of the Cost
Fine-tuned Phi-3 hit 96% accuracy vs GPT-4o’s 80% on financial tasks. Learn to fine-tune Phi-3 and Gemma 2 with QLoRA for under $100. Benchmarks, code, and deployment guide.

This is a complete guide to Phi-3 fine-tuning and Gemma 2 fine-tuning for enterprises seeking budget AI model training without sacrificing quality.
A 3.8 billion parameter model outscoring GPT-4o on financial classification. 96% accuracy versus 80%.
This isn’t a hypothetical. A multi-institutional study ran over 200 training experiments and found that Microsoft’s Phi-3-mini beat GPT-4o on 6 of 7 financial NLP benchmarks.
The inference cost difference: $0.13 per million tokens versus ~$3.75 (GPT-4o blended average). That’s roughly 29x cheaper.
Google’s Gemma 2 tells a similar story. The 9B model approaches early GPT-4 performance on human preference evaluations with an Elo rating of 1187. It runs on a single RTX 4090.
Two tech giants built models specifically designed for fine-tuning on constrained budgets. Microsoft optimized Phi-3 for reasoning on minimal parameters. Google distilled Gemma 2 from Gemini for practical deployment.
This guide shows you how to fine-tune both for under $100 in compute costs. You’ll get the benchmarks, the code, and the production deployment path.
No theoretical frameworks. Just the process that works.
Why Phi-3 and Gemma 2? The Budget Power Duo
Most enterprise teams default to GPT-4 or Claude. The logic seems sound: pay for the best, get the best results.
The math doesn’t support this for high-volume, specific tasks.
Consider a customer service operation handling 100,000 queries per day. At 500 tokens per query, that’s 50 million tokens daily. GPT-4o costs roughly $187/day in API fees (at ~$3.75/M tokens blended). A fine-tuned Phi-3 self-hosted costs under $10/day.
Annual difference: approximately $65,000.
But cost savings mean nothing if accuracy drops. Here’s why these two models specifically deliver both.
Microsoft’s Phi-3 approach: Quality over quantity. The training data went through aggressive filtering. Microsoft calls it “textbook-quality data.” The result: a 3.8B model that hits 69% on MMLU (per the technical report), matching GPT-3.5 despite being 50x smaller.
Google’s Gemma 2 approach: Knowledge distillation from Gemini. The 9B model inherits capabilities from Google’s flagship without the compute requirements. The Chatbot Arena Elo rating of 1187 puts it in competitive range with early GPT-4 variants.
Both are permissively licensed. Both run on consumer hardware. Both are designed for fine-tuning, not just inference.
The selection heuristic is straightforward. Phi-3 excels at math, code, and structured outputs. Gemma 2 excels at multi-turn conversation and general knowledge tasks.
Pick Phi-3 for analytical workloads. Pick Gemma 2 for dialogue-heavy applications. Either will outperform GPT-4 on your specific task after fine-tuning.
This is the core principle behind domain-specific language models: specialized training beats general-purpose scale.
Note on newer models: Microsoft has since released Phi-3.5 and Phi-4, while Google released Gemma 3 (March 2025) with 128K context. The fine-tuning principles in this guide apply to all versions, though newer models may offer improved base performance.

The Benchmark Reality Check
Fine-tuning claims are easy to make. Let’s look at verified numbers.
Table 1: Cost and performance comparison of Phi-3-mini, Gemma 2 9B, GPT-4o, and GPT-4o-mini across key benchmarks
| Metric | Phi-3-mini (3.8B) | Gemma 2 9B | GPT-4o | GPT-4o-mini |
|---|---|---|---|---|
| MMLU (General Knowledge) | 69% | 71.3% | ~86% | ~82% |
| Financial NLP (fine-tuned) | 96% | N/A | 80% | N/A |
| MT-Bench / Chat Quality | 8.38 | Elo 1187 | 9.0+ | 8.6 |
| HumanEval (Code) | 58.5% | 40.2% | 90.2% | ~87% |
| Inference Input (per 1M tokens) | $0.13 | $0.65 | $2.50 | $0.15 |
| Inference Output (per 1M tokens) | $0.52 | $0.65 | $10.00 | $0.60 |
| Fine-tuning Cost (compute only) | $8-50 | $15-50 | $25/M tokens | $3/M tokens |
Sources: Microsoft Phi-3 Technical Report, Google Gemma 2 Report, arXiv:2410.01109, OpenAI Pricing. Pricing as of February 2025.
The financial NLP result deserves explanation.
Researchers at multiple institutions fine-tuned Phi-3-mini on six related financial tasks: headline classification, sentiment analysis (FPB and Twitter), named entity recognition (NER), and question answering (ConvFinQA and FinQA). They called the phenomenon the “cocktail effect.” Training on multiple related tasks creates compounding improvements.
The results on headline classification:
- Fine-tuned Phi-3-mini: 96%
- GPT-4o zero-shot: 80%
- Fine-tuned Phi-3-mini on Twitter sentiment: 91% vs GPT-4o’s 75%
A model 50x smaller beat the flagship by 16 percentage points.
This pattern repeats across domains. The LoRA Land study fine-tuned 310 models across 31 tasks. Finding: fine-tuned small models outperform GPT-4 on roughly 80% of tested tasks (25 of 31). Average improvement over GPT-4: 10 points.
Average compute cost per fine-tuned model: $8.
Can Phi-3 beat GPT-4?
Yes, on domain-specific tasks. Published research showed fine-tuned Phi-3-mini achieving 96% accuracy versus GPT-4o’s 80% on financial headline classification. The key is multi-task fine-tuning on related domain data, not just single-task optimization.
Where GPT-4 Still Wins
Honesty matters here. GPT-4 maintains significant advantages in three areas.
Complex code generation. HumanEval scores tell the story: GPT-4o hits 90.2%, Phi-3-mini manages 58.5%. For greenfield code generation, larger models still lead.
Novel reasoning. Tasks outside your training distribution will fail. Apple’s “GSM-Symbolic” research demonstrated that all language models experience significant accuracy degradation on novel problem variations. Smaller models are more sensitive to this effect.
Zero-shot breadth. If you can’t predict what users will ask, general-purpose models have structural advantages.
For the full decision framework on when small models work and when they don’t, see our SLM vs LLM enterprise comparison.
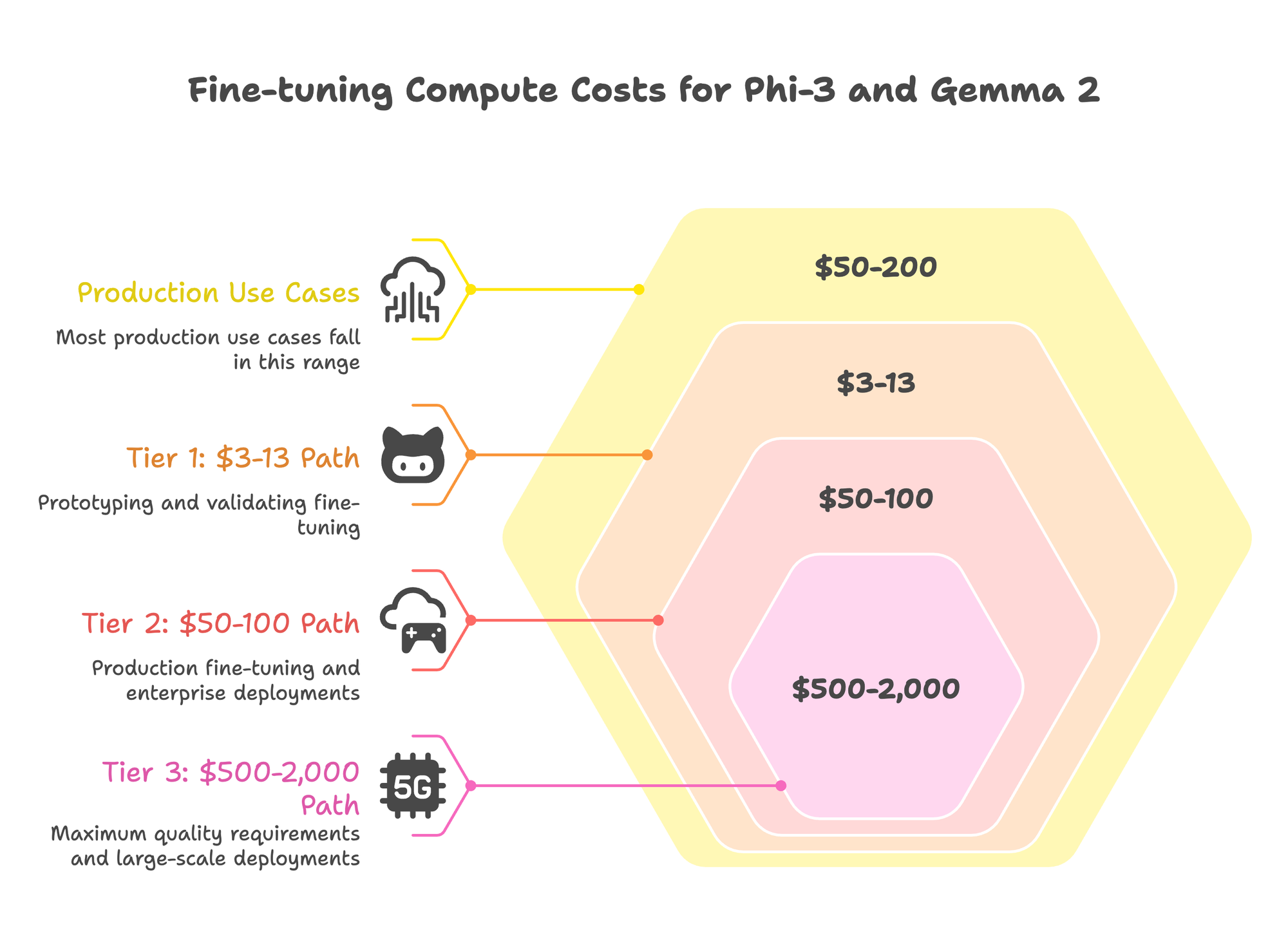
Hardware and Cost Planning
The budget spectrum for fine-tuning runs from $3 to $50,000 in compute costs. Most production use cases fall in the $50-200 range.
Important caveat: These figures cover compute costs only. Engineering time for data preparation, training iteration, and evaluation typically adds 40-80 hours for a first deployment. Factor this into your total cost of ownership.
For teams without dedicated ML engineers, Prem Studio compresses this timeline significantly. The platform handles hyperparameter selection, training orchestration, and evaluation automatically. You upload data and select a base model; the system handles the iteration loop that typically consumes engineering weeks.
Tier 1: The $3-13 Path
Google Colab’s free T4 GPU handles Phi-3-mini with QLoRA. Training a 3.8B model on 5,000 examples takes 2-3 hours.
For Gemma 2 9B, you’ll need Colab Pro ($10/month) for A100 access. The 9B model requires 16-24GB VRAM with 4-bit quantization.
Unsloth cuts training time in half and reduces memory by 63%. This moves Gemma 2 9B into RTX 4090 territory.
Realistic for: Prototyping, validating whether fine-tuning works for your task, datasets under 5,000 examples.
Tier 2: The $50-100 Path
Cloud GPU providers like RunPod and Vast.ai rent RTX 4090s at $0.40/hour. A production fine-tuning run takes 2-4 hours.
The math:
GPU: RTX 4090 @ $0.40/hour
Training: 3 hours (10K examples)
Dataset prep: $15 (GPT-3.5 for synthetic generation)
Total compute: $16.20
Add buffer for experimentation and iteration: $50-100 total compute.
Realistic for: Production fine-tuning, 10K-50K training examples, most enterprise deployments.
Tier 3: The $500-2,000 Path
A100 40GB instances run $1.10-1.50/hour. Full precision LoRA (not quantized) trains faster and sometimes yields marginally better results.
For Gemma 2 27B, you need A100 80GB ($2.00-3.00/hour) or H100. The 27B model competes with Llama 3 70B on benchmarks while fitting on a single high-end GPU.
Realistic for: Maximum quality requirements, regulated industries needing audit trails, large-scale deployments.
GPU Requirements by Model
Phi-3-mini (3.8B): 8GB VRAM minimum with QLoRA. RTX 3060 works.
Phi-3-medium (14B): 16GB VRAM with QLoRA. RTX 4090 recommended.
Gemma 2 9B: 16-24GB VRAM with QLoRA. RTX 4090 or A100 40GB.
Gemma 2 27B: 24-48GB VRAM with QLoRA. A100 80GB recommended.
How much does Phi-3 fine-tuning cost?
Compute costs only: QLoRA on cloud GPUs runs $8-50 total. Full LoRA on A100s costs $200-500. Full fine-tuning (all parameters) runs $2,000-5,000. The sweet spot for most enterprises is QLoRA at $50-100, which achieves 95-98% of full fine-tuning performance. Add 40-80 engineering hours for a first deployment.
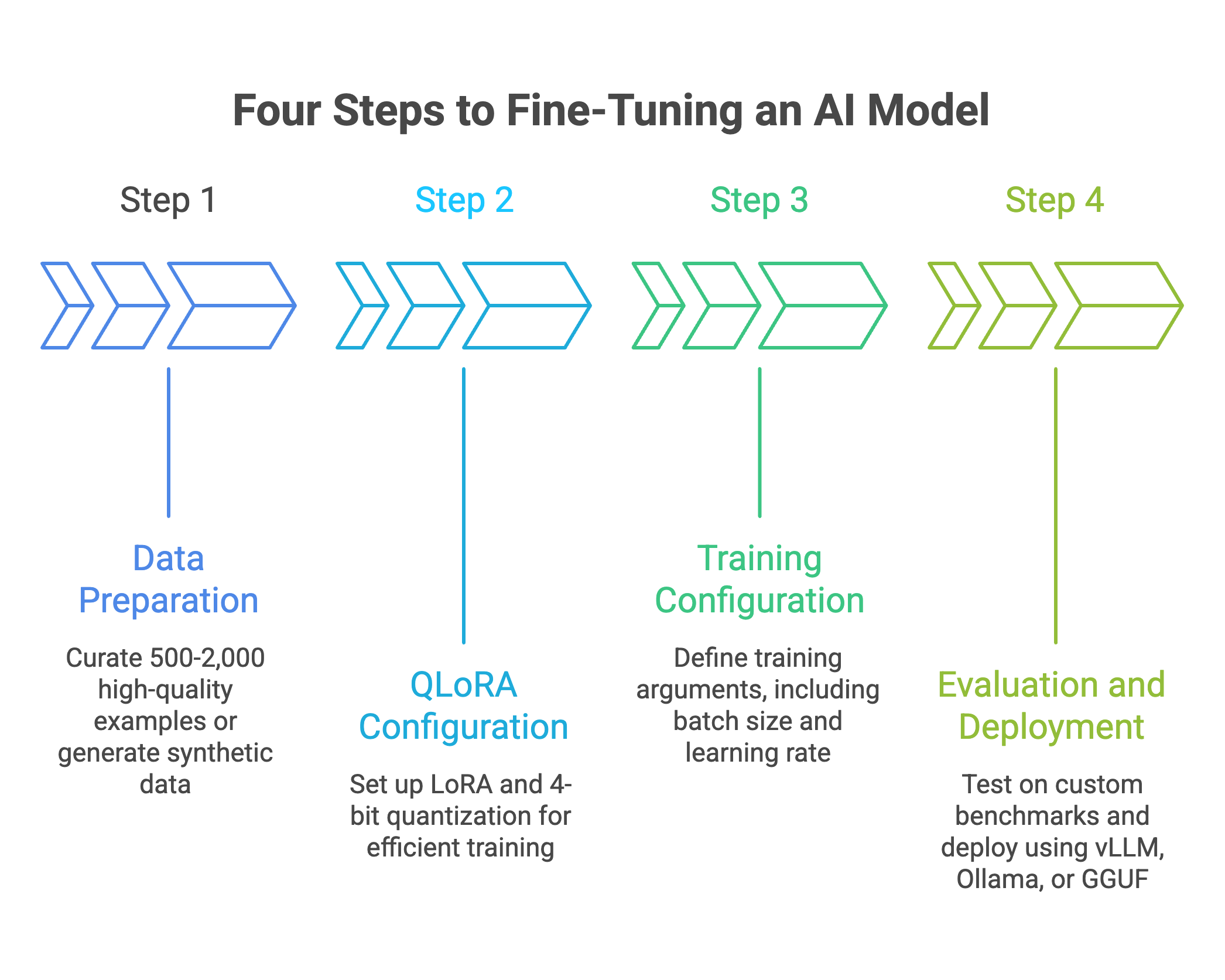
The Fine-Tuning Process
Four steps from raw data to production model.
Step 1: Data Preparation
The quality-over-quantity rule applies universally. Research shows that 50,000 curated examples outperform 10 million noisy ones.
Start with 500-2,000 high-quality examples. You can always add more after evaluating where the model fails.
Data format (ChatML, works for both models):
{
"messages": [
{"role": "system", "content": "You are a financial analyst specializing in earnings reports."},
{"role": "user", "content": "Classify this headline: 'Apple reports record Q4 revenue of $94.8B'"},
{"role": "assistant", "content": "Category: Earnings Report\nSentiment: Positive\nEntities: Apple (Company), Q4 (Period), $94.8B (Revenue)"}
]
}
Synthetic data generation:
If you lack training examples, generate them. Use GPT-4 to create input-output pairs based on your specifications. Cost: $0.01-0.05 per example.
The process:
- Write 20-50 seed examples manually (gold standard quality)
- Prompt GPT-4 to generate variations
- Have domain experts validate a sample
- Filter for quality
This manual approach works but scales poorly. Prem Studio automates data expansion using multi-agent augmentation: a topic analysis agent identifies patterns in your seed examples, a paraphrasing agent generates controlled variations, a scenario agent creates edge cases, and a validation agent filters for semantic coherence.
Fifty seed examples become thousands without manual labeling. The Prem-1B-SQL model used this approach, starting with existing datasets plus ~50K synthetically generated samples to achieve 51.54% on BirdBench.
For manual data preparation strategies, see our complete fine-tuning guide.
Step 2: QLoRA Configuration
This configuration works for both Phi-3 and Gemma 2. For faster training, consider using Unsloth which provides optimized implementations.
from peft import LoraConfig
from transformers import BitsAndBytesConfig
# LoRA configuration
lora_config = LoraConfig(
r=16, # Rank: 8-64, 16 is the sweet spot
lora_alpha=32, # Scaling: typically 2x rank
lora_dropout=0.05, # Light regularization
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"], # Include MLP layers
bias="none",
task_type="CAUSAL_LM"
)
# 4-bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # Normalized float 4-bit
bnb_4bit_compute_dtype="bfloat16"
)
Why these settings:
- r=16 captures enough task-specific adaptation without overfitting. Higher ranks (32, 64) rarely improve results and increase memory.
- lora_alpha=32 (2x rank) provides stable training gradients.
- Target attention and MLP projections for best results. The MLP layers (gate_proj, up_proj, down_proj) are increasingly standard practice for Gemma 2.
Step 3: Training Configuration
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./phi3-finetuned",
learning_rate=2e-4, # QLoRA paper recommendation
num_train_epochs=3, # More epochs rarely help
per_device_train_batch_size=4,
gradient_accumulation_steps=4, # Effective batch size: 16
warmup_ratio=0.03,
lr_scheduler_type="cosine",
fp16=False,
bf16=True, # Critical for Gemma 2
logging_steps=10,
save_strategy="epoch"
)
Critical: Gemma 2 specifics
Two undocumented requirements that will waste hours if you miss them:
- Use bfloat16, not float16. The instruction-tuned Gemma 2 models produce erratic outputs with float16. This isn’t in most tutorials.
- Set
attn_implementation="eager"when loading the model. Gemma 2 uses soft-capping in attention, which is incompatible with Flash Attention. If you see NaN losses, this is why.
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-9b-it",
quantization_config=bnb_config,
attn_implementation="eager", # Required for Gemma 2
device_map="auto"
)
Step 4: Evaluation and Deployment
Don’t skip evaluation. Generic benchmarks like MMLU won’t predict performance on your specific task.
Build custom benchmarks:
- Hold out 10-20% of your data
- Test on real edge cases from production
- Measure what matters to your business (accuracy, latency, format compliance)
Deployment options:
- vLLM for production APIs. Continuous batching provides 2-3x throughput versus vanilla inference.
- Ollama for local deployment and testing.
- GGUF export for edge devices and mobile.
Important: If using QLoRA/LoRA adapters with vLLM, you must either merge the adapters into the base model first, or use vLLM’s --enable-lora flag. The basic deployment command won’t work with unmerged adapters.
# Merge adapters before deployment
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("microsoft/phi-3-mini-4k-instruct")
model = PeftModel.from_pretrained(base_model, "./phi3-lora-adapter")
merged_model = model.merge_and_unload()
merged_model.save_pretrained("./phi3-merged")
For detailed deployment architecture, see our self-hosted LLM guide.
Real-World Results
Theory matters less than production outcomes. Here’s what the research shows.
Financial Services: The Benchmark Case
The arXiv study trained Phi-3-mini on six interconnected financial tasks. The multi-task approach created synergies that single-task fine-tuning misses.
Results:
- Headline classification: 96% (vs GPT-4o’s 80%)
- Twitter sentiment: 91% (vs 75%)
- Financial phrase bank: 89% (vs 80%)
- Named entity recognition: 98% (vs 66%)
Cost comparison at 50M tokens/day (assuming 50/50 input/output split):
- GPT-4o API: ~$312/day (~$114,000/year)
- Fine-tuned Phi-3 self-hosted: $10/day ($3,650/year)
Annual savings: approximately $110,000 in compute costs.
Healthcare: Compliance-Driven Deployment
Healthcare deployments often prioritize data residency over cost. A common pattern: deploying Gemma 2 9B on edge servers to keep protected health information local.
On-premise deployment means no data leaves the network. Fine-tuning on domain-specific transcripts typically improves task accuracy by 20-40% compared to zero-shot performance.
For healthcare and other regulated industries, see our guides on GDPR-compliant AI and private LLM deployment.
The Hybrid Pattern
Most production systems don’t choose between SLMs and LLMs. They use both.
Consider a hypothetical e-commerce platform handling 200,000 monthly conversations with a hybrid setup:
- Fine-tuned 7B model: handles 90% of queries (routine questions, order status, returns)
- GPT-4: handles the remaining 10% (complex, novel requests)
- Confidence-based router: directs traffic automatically
Expected result: 80-90% cost reduction with maintained quality scores.
The routing logic is simple: if the SLM’s confidence score falls below threshold, escalate to GPT-4. Most queries never need the expensive model.
When NOT to Fine-Tune
Fine-tuning isn’t always the answer. Recognizing when to skip it saves time and money.
Skip Fine-Tuning When
You have fewer than 200 quality examples. Fine-tuning needs data. Below 200 examples, you’re likely overfitting to noise rather than learning patterns. Use prompt engineering or RAG instead.
The task requires broad general knowledge. A model fine-tuned on legal contracts won’t know about current events. If queries span unpredictable domains, general-purpose LLMs have structural advantages.
Queries are highly unpredictable. SLMs trained on customer service conversations fail when users ask unexpected questions. If you can’t characterize your query distribution, don’t fine-tune.
You need results in under a week. Fine-tuning well takes iteration. Data prep, training, evaluation, debugging. If you’re on a tight deadline, start with prompt engineering and fine-tune later.
| Approach | Best For | Time to Deploy | Compute Cost |
|---|---|---|---|
| Prompt Engineering | Prototyping, low volume, unpredictable queries | Hours | $0 upfront |
| RAG | Knowledge-heavy tasks, frequently updated info | Days | $100-500 |
| Fine-Tuning | High-volume, specific, repetitive tasks | 1-2 weeks | $50-2,000 |
When Phi-3/Gemma 2 Won’t Work
Complex multi-step reasoning. All language models degrade at high complexity. Smaller models hit that ceiling sooner. If your task requires synthesizing information across multiple reasoning steps, larger models have more headroom.
Long documents exceeding context limits. Gemma 2 caps at 8K tokens (Gemma 3 supports 128K). Phi-3.5 handles 128K, but attention quality degrades over long contexts. If your documents routinely exceed 32K tokens, consider RAG or document chunking strategies.
Zero-shot on novel domains. Fine-tuned models are specialists. Outside their training distribution, they underperform general-purpose LLMs badly. Plan for fallback routing.
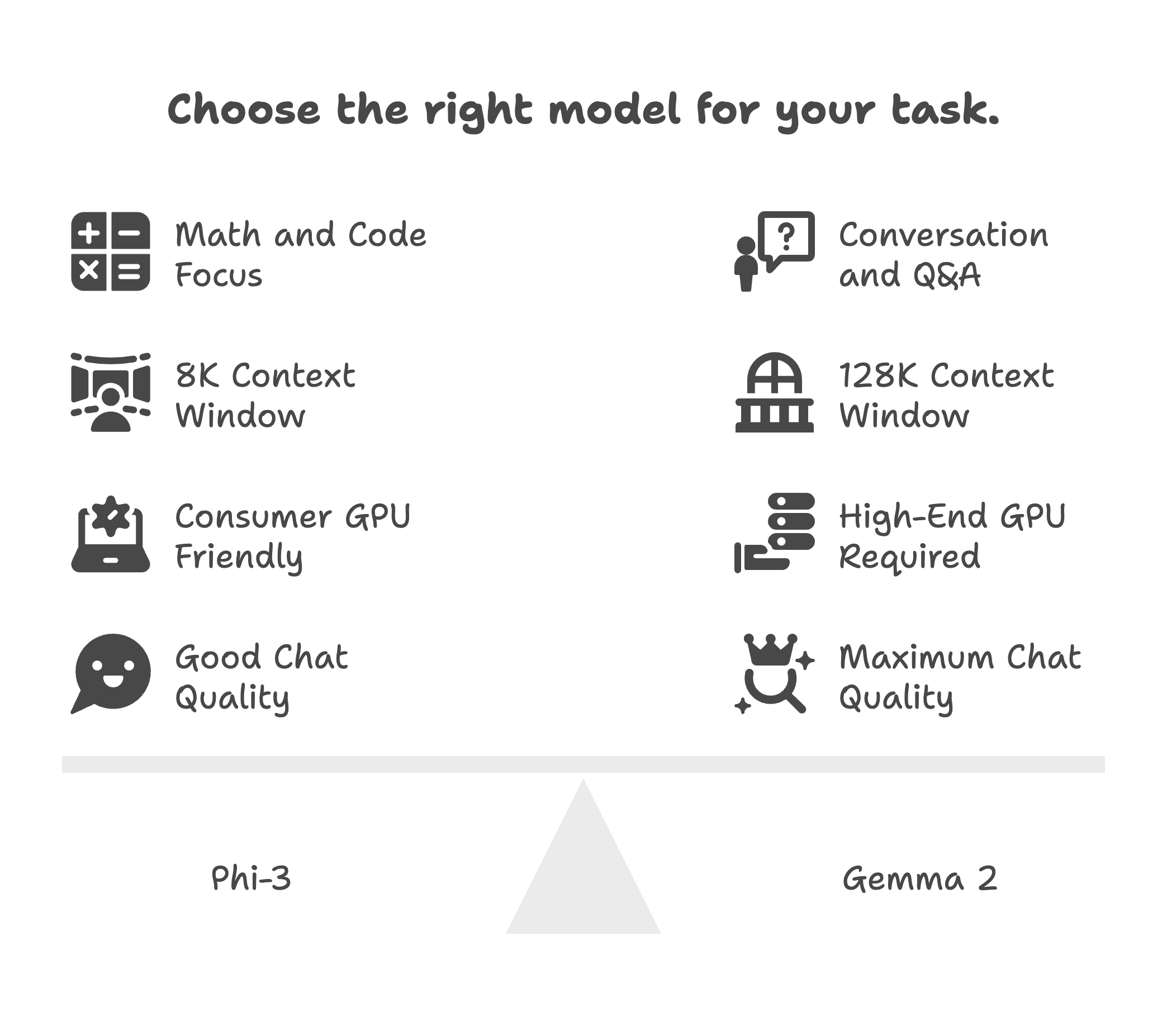
Decision Framework: Phi-3 vs Gemma 2
Both models work. Here’s how to choose.
Table 3: Selection criteria for choosing between Phi-3 and Gemma 2 based on task requirements
| Factor | Choose Phi-3 | Choose Gemma 2 |
|---|---|---|
| Primary Task | Math, code, structured output, JSON | Conversation, Q&A, chat, dialogue |
| Context Length Needed | >8K tokens (Phi-3.5 supports 128K) | 8K tokens sufficient |
| Hardware Available | Limited GPU (3.8B fits on 8GB) | RTX 4090+ (9B needs 16-24GB) |
| Ecosystem | Azure, Microsoft stack | Google Cloud, Vertex AI |
| Chat Quality Priority | Acceptable (MT-Bench 8.38) | Critical (Elo 1187) |
The Decision Tree
- Is your task math, code, or structured extraction? Phi-3. Its training data emphasizes reasoning and format compliance.
- Is it conversation, Q&A, or customer-facing chat? Gemma 2. The distillation from Gemini optimized for dialogue quality.
- Do you need context windows >8K tokens? Phi-3.5 or Gemma 3. Both support 128K context.
- Limited to consumer GPU (8-16GB)? Phi-3-mini at 3.8B. It fits anywhere.
- Maximum chat quality is non-negotiable? Gemma 2 27B. It matches larger models on human preference evaluations.
Both Work Well For
- Text classification
- Named entity extraction
- Sentiment analysis
- Content generation with guardrails
- Summarization
- Translation (with appropriate fine-tuning data)
Production Deployment
A fine-tuned model sitting on Hugging Face isn’t production-ready. Here’s the deployment path.
Optimization Checklist
1. Quantize after training.
Fine-tune in bfloat16, then quantize for inference. GGUF format works for edge deployment. AWQ or GPTQ work for server inference.
4-bit quantization reduces model size by 75% with minimal accuracy loss (typically <1%).
2. Merge adapters and deploy with vLLM or TensorRT-LLM.
Continuous batching increases throughput 2-3x versus naive inference. For production APIs handling concurrent requests, this is mandatory.
# After merging LoRA adapters into base model
python -m vllm.entrypoints.openai.api_server \
--model ./phi3-merged \
--quantization awq
3. Implement monitoring.
Track latency, accuracy drift, and token usage. Models degrade over time as user query distributions shift. Set up alerts for accuracy drops.
4. Build fallback routing.
Low-confidence predictions should escalate to a larger model or human review. A simple threshold (e.g., escalate if model confidence <0.7) catches most failure cases.
Cost at Scale
| Daily Volume | GPT-4o API (blended) | Self-Hosted Phi-3 | Annual Savings |
|---|---|---|---|
| 1M tokens | ~$6.25 | <$1 | ~$1,900 |
| 10M tokens | ~$62.50 | $3-5 | ~$21,000 |
| 50M tokens | ~$312.50 | $10 | ~$110,000 |
GPT-4o blended rate assumes 50/50 input/output at $2.50/$10.00 per 1M tokens.
The break-even point for self-hosting falls around 2-3 million tokens per day. Below that, API convenience wins. Above it, infrastructure investment pays off within months.
For teams wanting production deployment without infrastructure management, Prem Studio handles fine-tuning and deployment with SOC 2 and GDPR compliance built-in.
The Action Plan
Week 1: Analysis
Audit your current LLM usage. Categorize queries by type, volume, and accuracy requirements. Identify candidates for fine-tuning: high-volume, well-defined, repetitive tasks.
Calculate current costs and potential savings.
Week 2: Data Preparation
Collect 500-1,000 training examples from production logs. Format as ChatML conversations. Have domain experts validate quality.
If you lack examples, generate synthetic data using GPT-4.
Week 3: Fine-Tuning
Fine-tune Phi-3 or Gemma 2 using QLoRA. Budget: $50-100 on cloud GPUs. Train 2-3 candidate configurations. Evaluate on held-out data.
Week 4: Validation
A/B test against your current LLM in shadow mode. Compare accuracy, latency, and cost. Document edge cases where the fine-tuned model fails.
If results meet requirements, deploy to production with fallback routing.
The Bottom Line
Fine-tuned Phi-3 beat GPT-4o on financial tasks. 96% versus 80%. The research is published and reproducible.
Total fine-tuning compute cost: $8-50 with QLoRA.
Inference cost: roughly 29x cheaper than GPT-4o.
First-year ROI for high-volume deployments: 300-400%.
Microsoft and Google built these models specifically for enterprise fine-tuning. The architectures, licensing, and ecosystems support production deployment. The benchmarks prove the performance.
The question isn’t whether fine-tuned SLMs can match LLMs on specific tasks. The research settled that. The question is whether you’re capturing the cost savings.
Book a technical call to discuss your specific use case.