Generative AI Integration for Web Developers
Generative AI offers new opportunities in content creation, but challenges like model selection and data complexity hinder developers. This article explores these issues and introduces Prem AI, a platform designed to simplify AI integration.


Generative AI has revolutionised the landscape of content creation, data analysis, and user interaction, offering developers new opportunities to enhance user experiences. From generating realistic text to producing high-quality images and videos, Generative AI is leading innovation across industries. However, for web developers looking to integrate these AI models into production-grade applications, the journey is not without its challenges. Selecting the right model, ensuring optimal deployment, and managing model performance at scale are just a few of the hurdles developers face, especially when they lack specialized knowledge in AI or machine learning.
This article explores the core challenges developers encounter when integrating Generative AI. We’ll examine how AI integration can sometimes feel “broken” due to these difficulties and introduce Prem AI as a solution designed to streamline the process and help developers overcome these obstacles effectively.
Model Selection and Complexity
When building production-ready Generative AI applications, one of the most pressing challenges is selecting the right AI model. Today’s developers are faced with a wide array of models, from simple language models to more sophisticated architectures like transformers and autoregressive models. This abundance creates a new problem: with so many choices, how can developers make the right decision, especially if they aren’t AI experts?
Why Model Selection is a Problem
With the proliferation of AI models such as GPT-4, LLaMA, Mistral, and Claude, developers often find themselves overwhelmed. Each model offers distinct capabilities—ranging from language fluency to specific task optimizations—making it difficult to match the right model to a given use case.
Several factors contribute to this complexity:
- API Limitations: Each model has its own API constraints regarding input size, output formats, and rate limits. Developers must understand these limitations and determine how they impact their application.
- Pricing Models: Models like OpenAI’s GPT-4 may charge per token, while others may charge per inference call, complicating cost estimates for developers trying to scale AI-driven applications.
- Optimization Challenges: Some models require fine-tuning or other configurations to perform optimally. Misconfiguration can lead to suboptimal performance, increased latency, or excessive costs during production.
This complexity is further exacerbated by the need to choose between pre-trained models, which are generalized, and fine-tuned models that cater to specific tasks. Understanding when and how to fine-tune a model adds another layer of decision-making.
Why It's Broken
Many large models, including GPT-4 and LLaMA, are powerful but come with inherent limitations. One key issue is the lack of differentiation among models, as many are trained on similar datasets. This leads to outputs that are often generic or undifferentiated. In the case of AI-generated content, this results in a flood of mediocrity—content that lacks the originality expected from cutting-edge AI systems.
Developers also struggle to fully understand the trade-offs between different models. For instance, some models excel at summarization but falter when tasked with generating creative writing. This variability makes it difficult to optimize a model for diverse business use cases, and without a clear “killer app” for generative AI, developers may find themselves using more powerful, and expensive, models than necessary, leading to inefficiencies.
Data Availability and Quality
The effectiveness of AI models is highly dependent on the quality of data they are trained on. However, ensuring access to high-quality, diverse, and relevant data has become increasingly difficult for developers, especially as data sources become more restricted.
The diagram below illustrates how data from structured databases can be processed with Text-to-SQL before being passed into a model API for generation, showcasing how external data is essential for accurate responses:
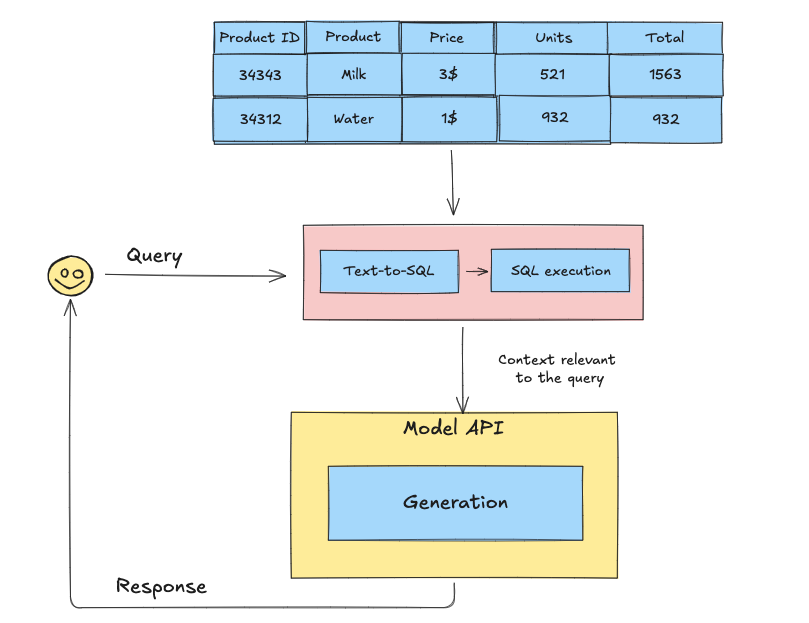
The Data Crisis
Generative AI is facing a looming data crisis. Vast quantities of training data, once readily available, are now becoming harder to access as online platforms place data behind paywalls or limit access due to privacy concerns. This scarcity poses a significant challenge for developers attempting to train or fine-tune models on up-to-date, relevant datasets.
Moreover, poor-quality data can lead to biased or inaccurate outputs, undermining the performance of even the most advanced models. This is particularly true in industries that require AI to generate content or perform tasks with high levels of accuracy, such as legal, medical, or financial sectors.
Data Preprocessing Challenges
Acquiring relevant data is only half the battle; preprocessing that data is equally important and labor-intensive. Generative models require clean, well-structured datasets to perform effectively. Developers often face several challenges during this stage:
- Data Cleaning: Removing duplicates, inconsistencies, and noise from datasets.
- Normalization: Ensuring data from various sources is formatted consistently.
- Data Augmentation: Enhancing datasets through augmentation techniques to ensure they are comprehensive enough to train AI models effectively.
These tasks require significant technical expertise, and developers without strong data science skills may struggle to manage them efficiently.
The Role of Synthetic Data
Synthetic data is emerging as a potential solution to the data scarcity problem. Generated algorithmically, synthetic data mimics the properties of real-world data, allowing developers to train models without the associated privacy or availability concerns. While promising, synthetic data comes with its own challenges, particularly in ensuring that it accurately reflects the variability of real-world data without introducing biases.
Fine-Tuning Complexity
Fine-tuning AI models is a critical step in customizing them for specific tasks. Pre-trained models provide a solid foundation, but they often need to be refined to meet the demands of specific industries or use cases, such as generating industry-specific reports or handling highly specialized customer queries.
The Resource Intensity of Fine-Tuning
Fine-tuning models like GPT-4 or Claude requires not only access to domain-specific datasets but also significant computational resources. The process can take days or even weeks, depending on the size of the model and the dataset, and requires substantial GPU and memory capacities. For smaller teams or organizations with limited resources, this can be a major barrier.
- Hyperparameter Tuning: the process of adjusting model parameters such as learning rates and batch sizes, is critical to the success of fine-tuning. However, finding the right balance is a meticulous and time-consuming process, often requiring multiple iterations and deep machine learning expertise. For many developers, navigating these intricacies can be overwhelming.
Fine-tuning also isn’t a one-time task. As business needs evolve or new data becomes available, models must be continuously fine-tuned to prevent “model drift,” where the model’s accuracy or relevance degrades over time.
- Ethical Considerations: there are also ethical concerns surrounding fine-tuning. Biased or incomplete datasets can lead to models that reinforce harmful stereotypes or generate exclusionary outputs. Developers must be vigilant in ensuring that their fine-tuning processes are fair, transparent, and ethical.
Retrieval-Augmented Generation (RAG) Complexity
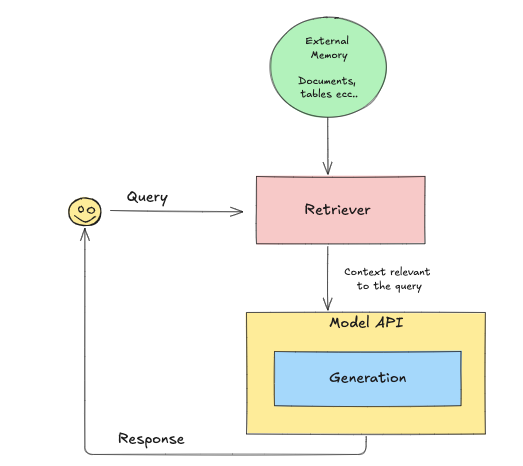
Retrieval-Augmented Generation (RAG) is a technique that enhances AI model outputs by incorporating external data. While RAG has the potential to significantly improve the accuracy and relevance of model responses, implementing RAG in production is highly complex.
- Building an Efficient Retrieval System: Designing and managing a retrieval system that can pull relevant information from external sources in real time is technically demanding. Developers need to build efficient indexing systems and ensure that the retrieved data is contextually appropriate for the AI model’s output.
- Managing Context and Relevance: even with a strong retrieval system in place, ensuring that the data retrieved is relevant to the task at hand is another challenge. Developers must effectively filter out irrelevant information to maintain high-quality model outputs.
- Deployment and Scalability: Deploying AI models in production introduces its own set of challenges, particularly when scaling the application to meet real-world demands. Developers must manage infrastructure, optimize performance, and control costs to ensure their AI systems function effectively in production environments.
The diagram below illustrates the full orchestration process, showing how queries are handled, routed through various stages like caching, guardrails, and model gateways, before generating a response. This process ensures that models perform optimally while maintaining security and scalability:
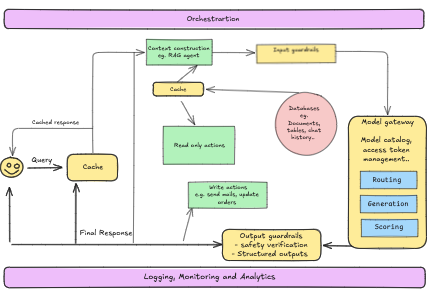
Infrastructure and Compute Resources
Generative AI models, particularly large ones, require significant computational power. Scaling these models to serve large user bases while maintaining performance can strain infrastructure, often necessitating cloud-based solutions with scalable GPU instances.
- Cost and Latency Management: managing costs while ensuring low-latency responses is a common challenge during AI deployment. Developers need to optimize their systems to balance performance and cost, especially when handling high traffic.
- Security and Ethical Considerations: as AI becomes more integrated into production environments, security and ethical considerations must be at the forefront of development. AI systems are vulnerable to adversarial attacks, and without proper safeguards, they can produce biased or harmful outputs.
- Security Risks: generative AI systems are vulnerable to several security threats, including adversarial attacks and prompt injections. Developers must implement input validation, output filtering, and continuous monitoring to ensure system security.
- Ethical Challenges: AI models trained on biased or unregulated data can perpetuate harmful stereotypes. Developers must prioritize fairness and transparency in AI development by using bias detection tools and conducting thorough ethical reviews.
How Prem AI Empowers Web Developers
Prem AI stands as a comprehensive solution for developers aiming to overcome the typical challenges associated with integrating Generative AI into their applications. The platform offers a suite of tools designed to simplify and accelerate every stage of the AI lifecycle, from model selection and fine-tuning to deployment and performance monitoring.
Removing the Complexity of Model Selection with Prem Lab
One of the key challenges developers face is choosing the right AI model for their specific application. Prem AI addresses this problem with Prem Lab, a testing environment where users can experiment with multiple large language models (LLMs) simultaneously. Developers can compare performance metrics, such as response times and accuracy, across different models like GPT-4, Claude, LLaMA, and others. Prem Lab provides real-time insights, allowing developers to quickly assess which model best fits their needs without requiring deep expertise in machine learning.
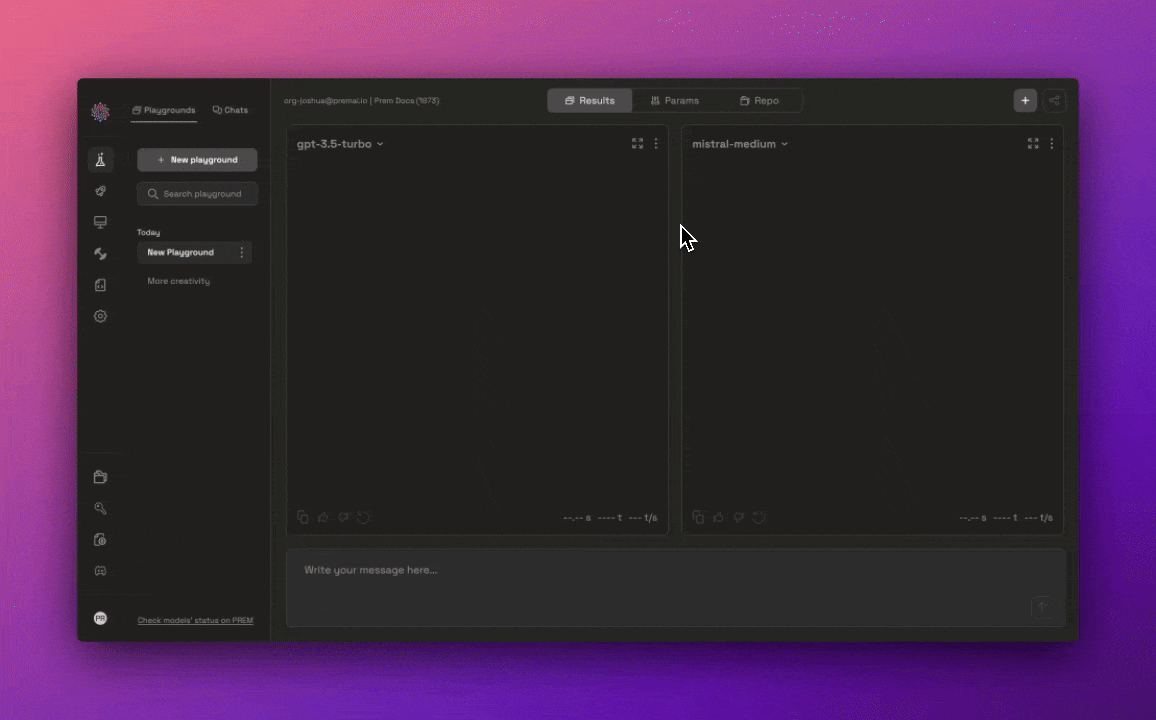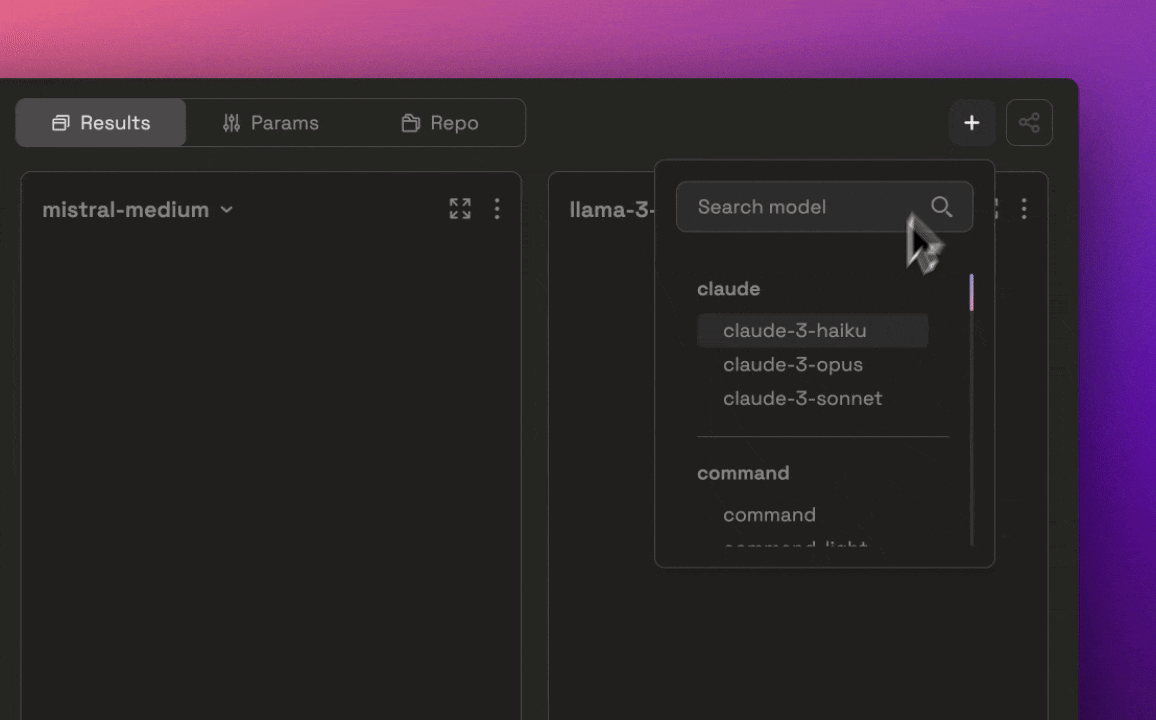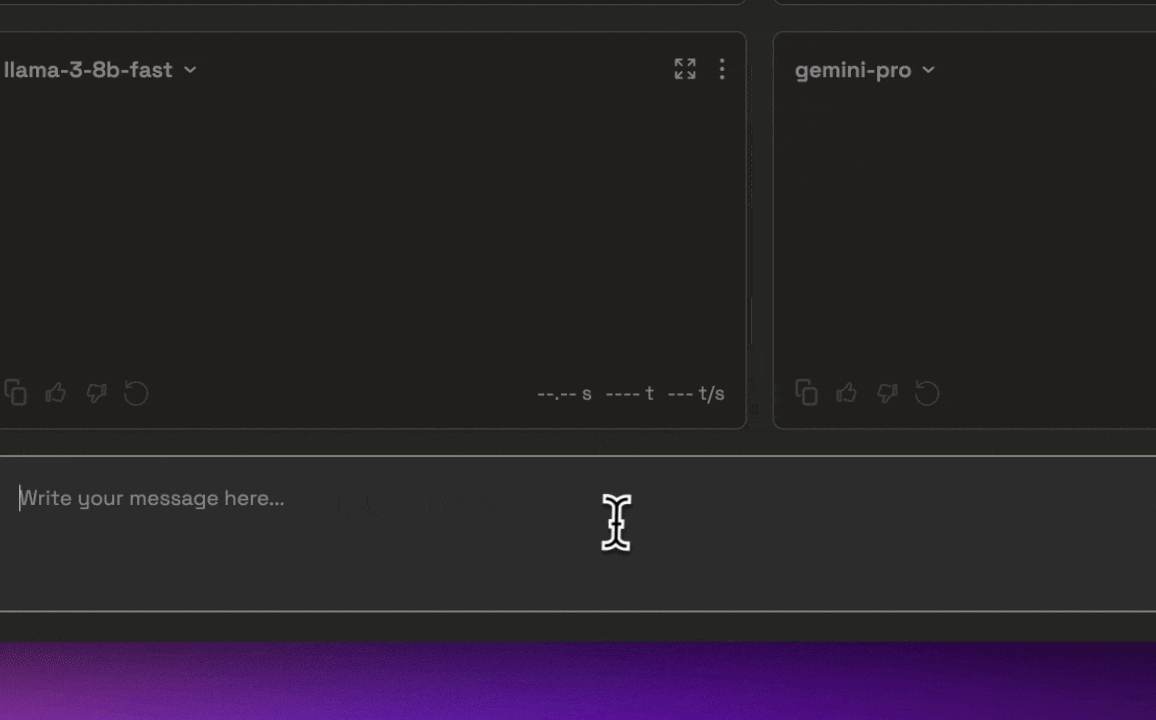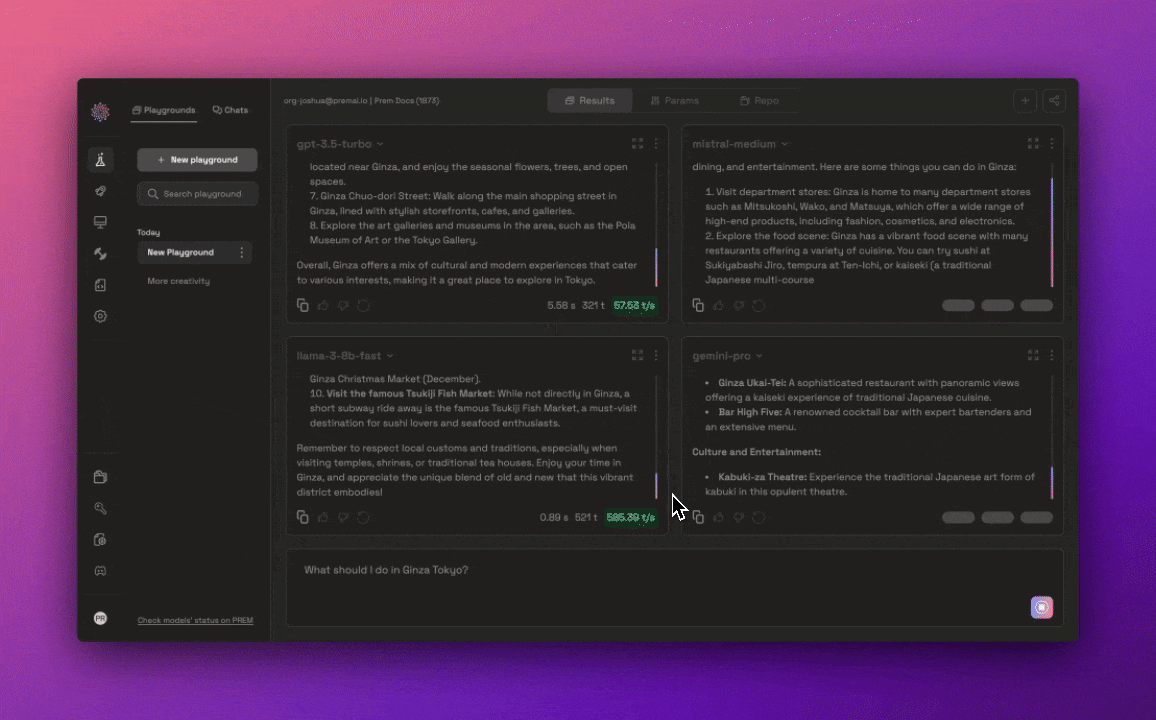
By offering a seamless and intuitive interface for comparing models, Prem Lab significantly reduces the time and effort required for model selection. This feature is particularly valuable for teams that need to balance performance with cost efficiency, as the platform allows developers to see how various models handle specific tasks before committing to one for production.
Streamlining AI Deployment with Launchpad
After selecting and optimizing a model, developers face the challenge of deploying it into production environments. Traditional deployment processes often involve complex configuration steps, which can delay time-to-market and introduce errors. Prem AI’s Launchpad simplifies this process by automating the deployment of AI models with just a few clicks. The Launchpad handles the necessary configuration and infrastructure setup, ensuring that the model is ready for production without the need for manual intervention.
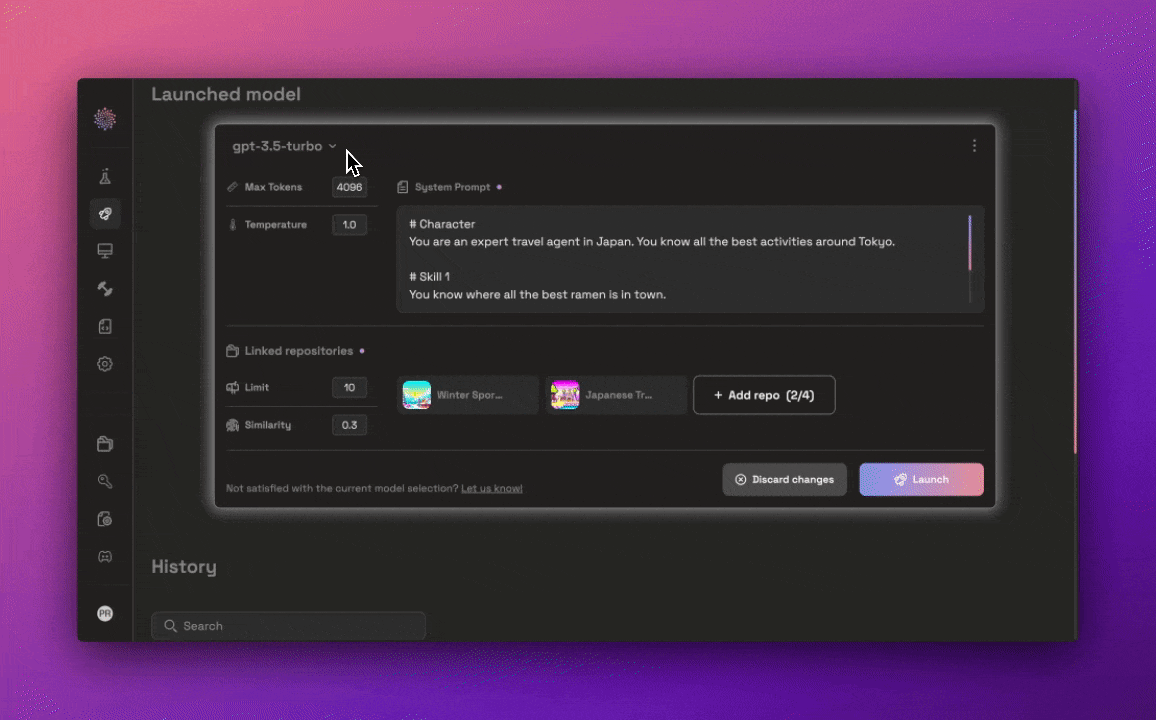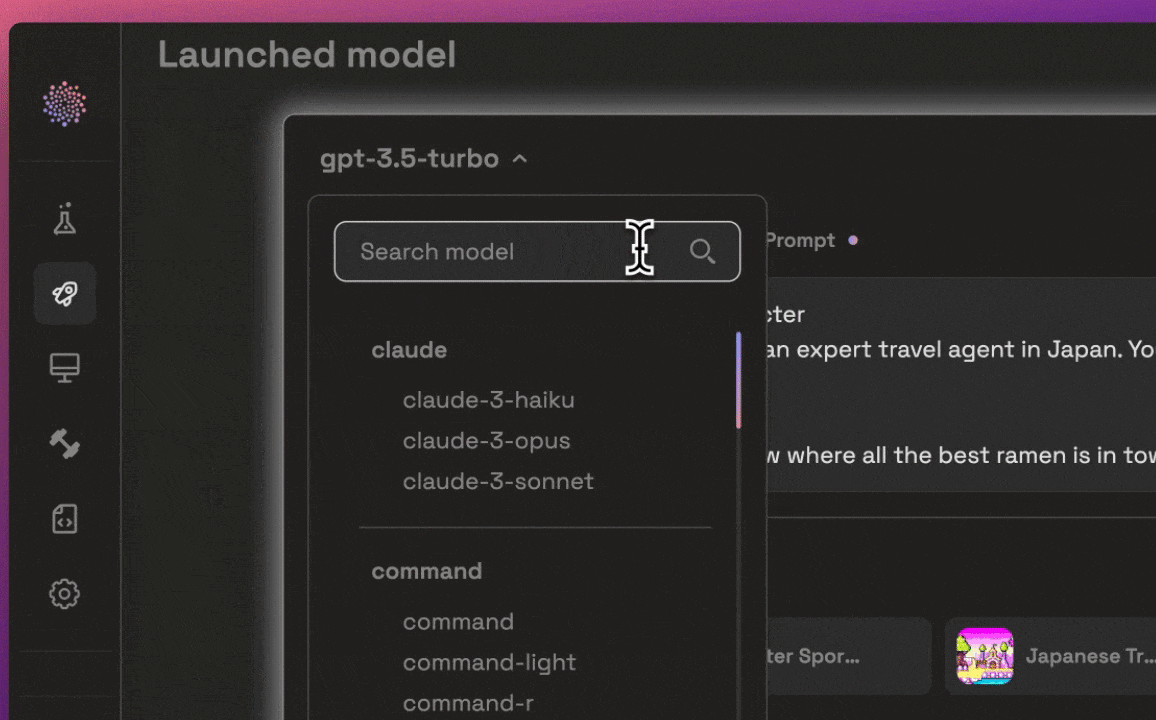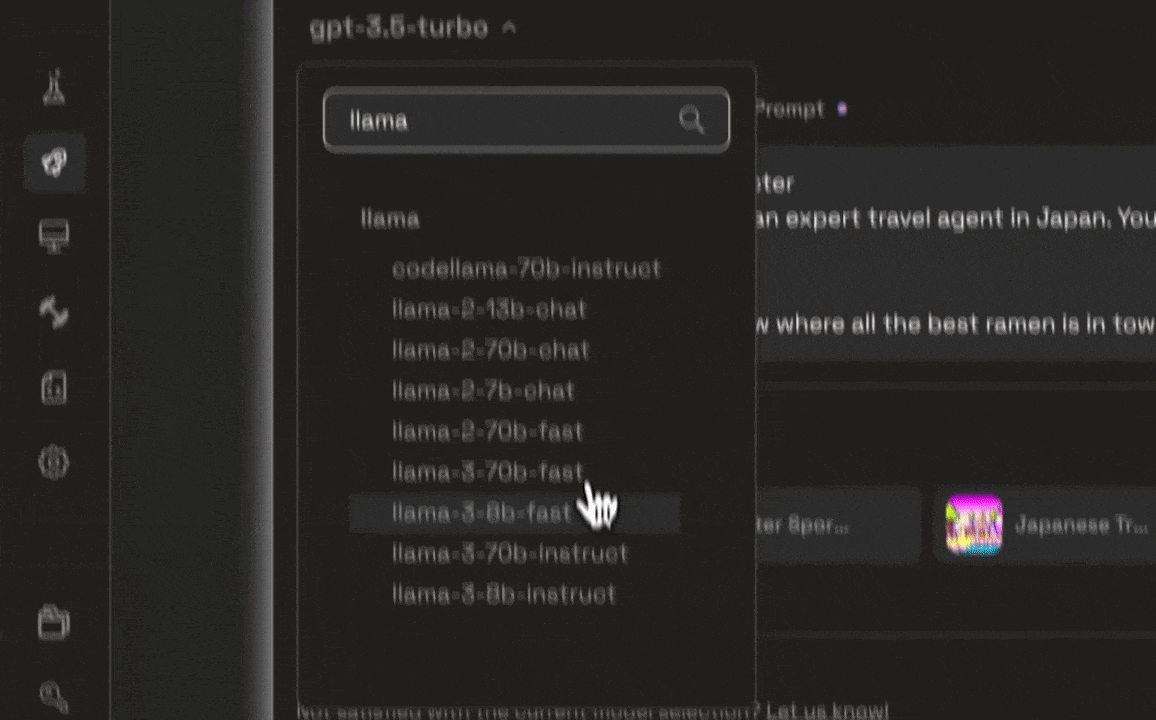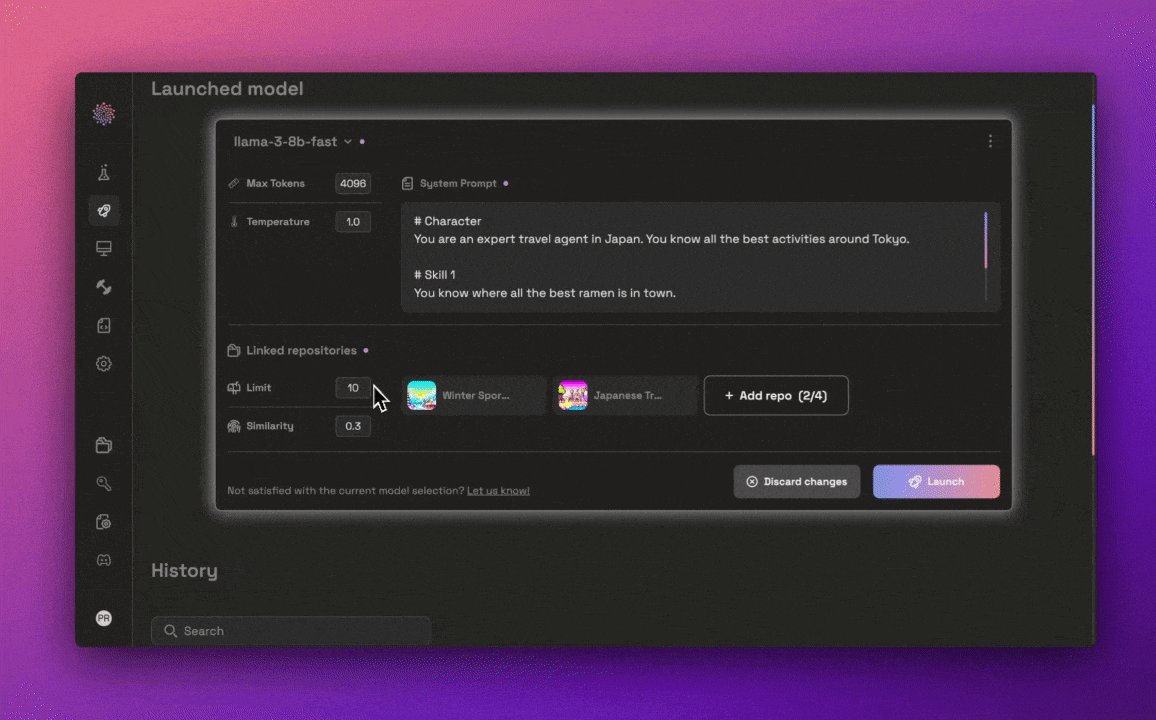
In addition to deployment, the Launchpad allows developers to make final adjustments and optimize model settings to tailor the AI's behavior to their application's specific needs. This ensures that the AI functions efficiently under real-world conditions, supporting scaling and high-performance demands.
Automating Fine-Tuning with Prem Gym
Fine-tuning is essential for adapting AI models to meet specific business requirements, but the process traditionally requires extensive machine learning expertise and significant computational resources. Prem AI’s Prem Gym automates the fine-tuning process, making it accessible to developers who may not have in-depth AI knowledge.
In Prem Gym, developers can input their proprietary data, and the platform will continuously optimize the model. This ensures that the AI evolves and adapts to the specific data provided, improving accuracy and performance over time. Whether the task is generating domain-specific reports or handling specialized customer interactions, Prem Gym makes it easy to customize models for particular use cases. This feature is especially valuable for industries requiring high precision, such as healthcare, finance, and legal sectors, where fine-tuning AI for accuracy is paramount.
Simplifying Retrieval-Augmented Generation (RAG) with RAG-Based Assistants
Another area where Prem AI excels is Retrieval-Augmented Generation (RAG), which enhances AI responses by incorporating external, up-to-date information from user-uploaded documents. Prem AI’s RAG-based assistants enable developers to upload their proprietary documents directly into the platform. The AI can then pull relevant data from these documents during the generation process, ensuring that its outputs are contextually accurate and informed by real-world, domain-specific information.
This feature is particularly useful for companies in industries such as legal, healthcare, and education, where access to accurate, real-time information is critical. With Prem’s repository management tools, developers can organize and index their document repositories for fast, efficient retrieval, ensuring that their AI systems stay up to date without needing frequent retraining
Bridging the Gap for Python and JavaScript Developers with SDKs
Prem AI provides robust SDKs for both Python and JavaScript, ensuring that developers can seamlessly integrate AI functionalities into their applications without needing to learn a new language. The Python SDK is tailored for back-end systems and advanced AI tasks like model training and fine-tuning, while the JavaScript SDK enables web developers to incorporate AI-driven features such as natural language processing and content generation directly into web apps.
By supporting both Python and JavaScript, Prem AI empowers developers to leverage AI within their preferred languages and frameworks, streamlining the integration process and accelerating AI-driven development.
Monitoring, Tracing, and Optimization with Prem AI
Once an AI model is deployed, ensuring its optimal performance and transparency is crucial. Prem AI offers real-time monitoring and detailed tracing tools, enabling developers to track key performance metrics such as latency, throughput, and response times. These features allow for continuous optimization and help maintain transparency by providing insights into how the AI is making decisions.
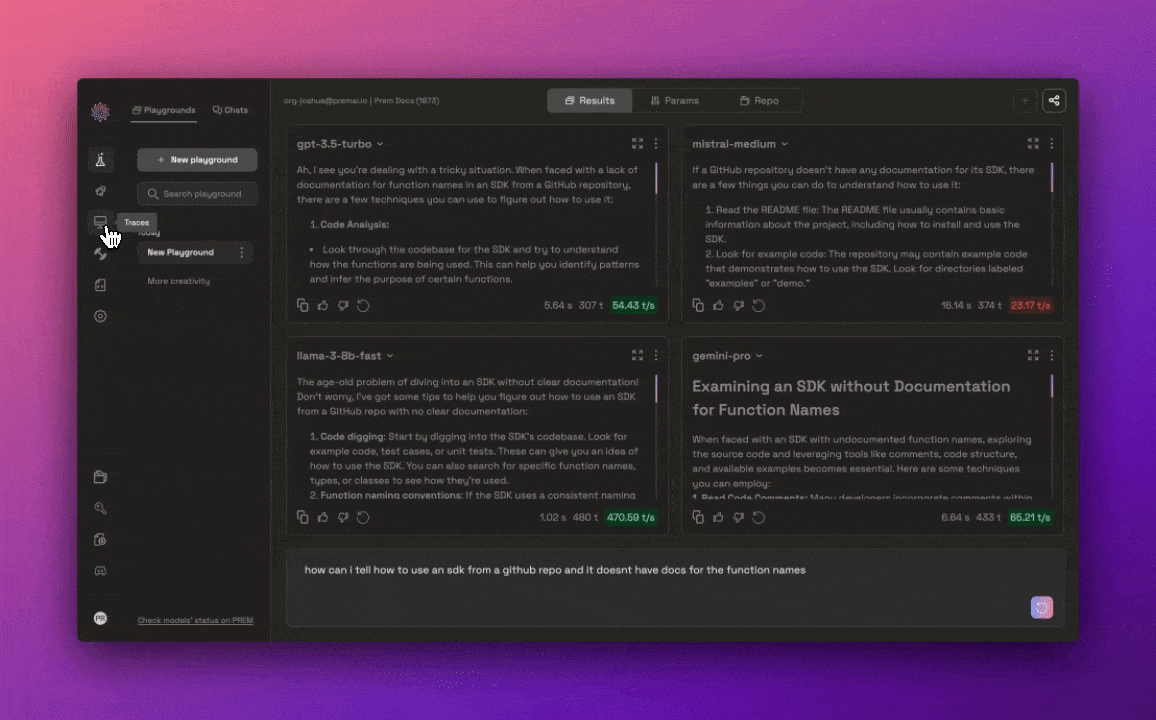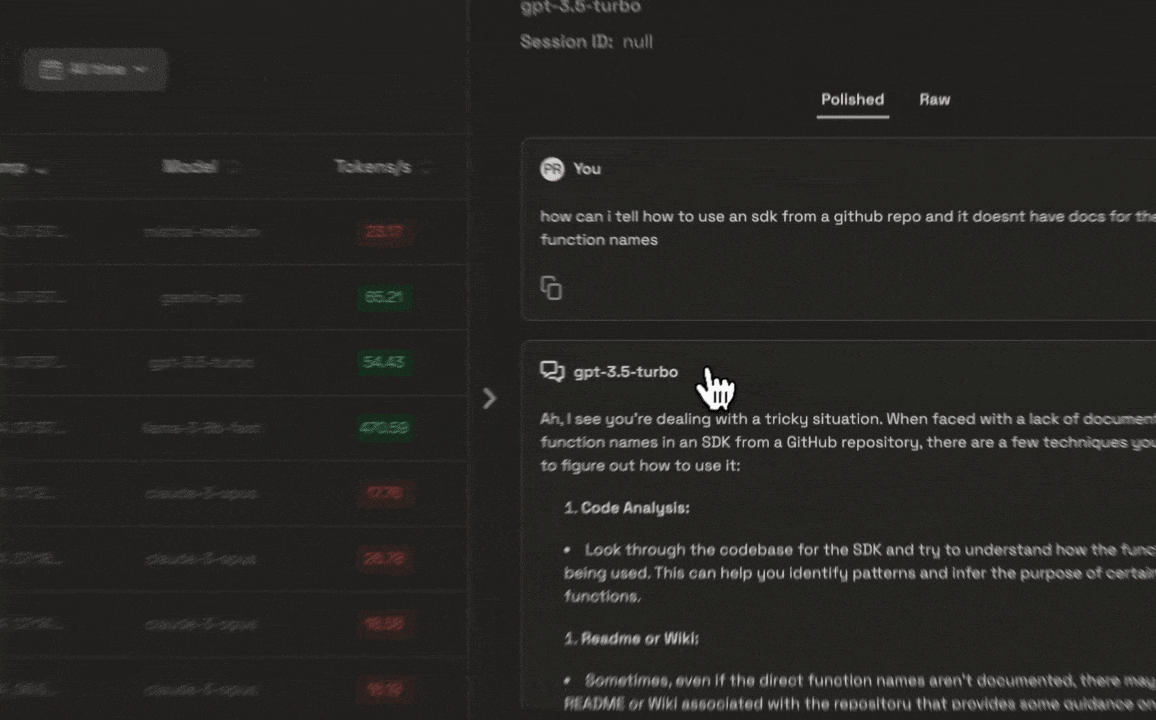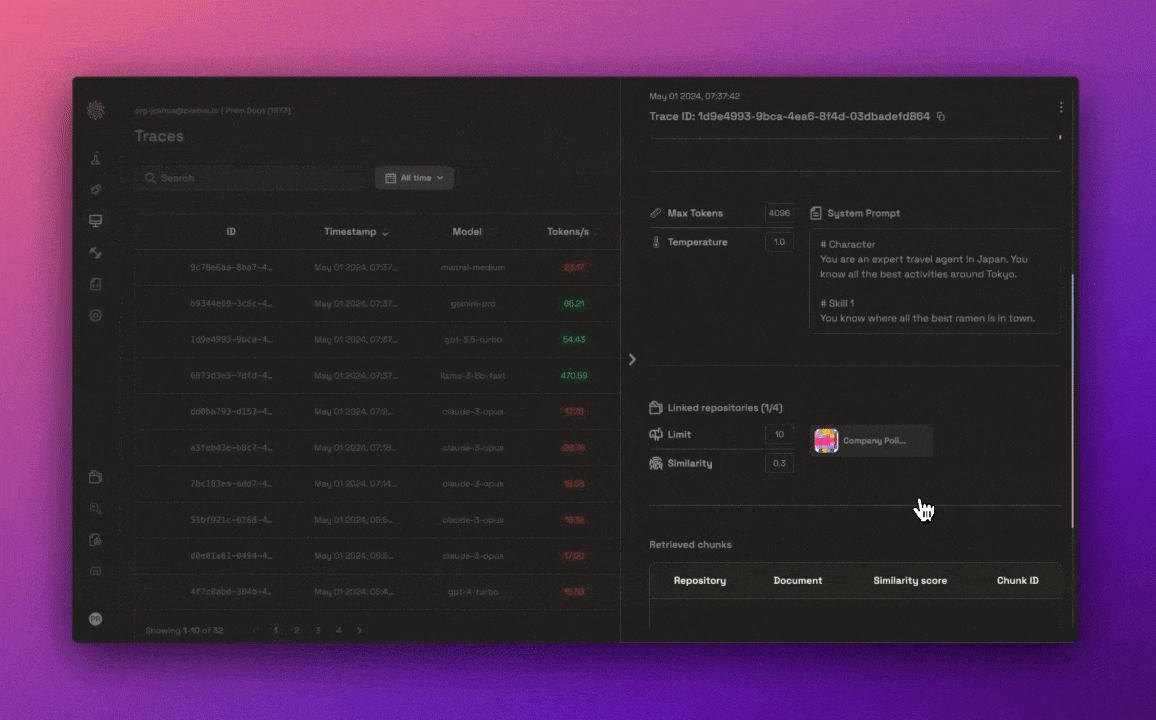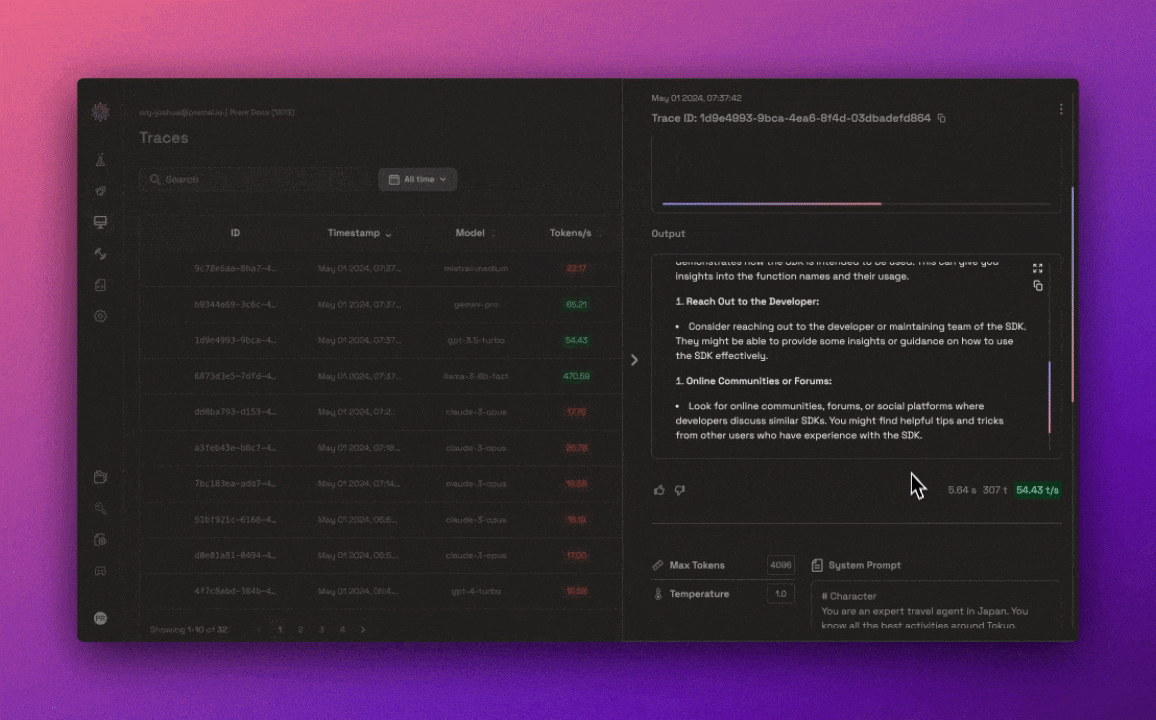
Developers can also use trace feedback to refine the model’s performance over time, improving the accuracy of outputs based on real-world feedback. This level of control ensures that AI systems not only meet initial performance standards but continue to improve as they are used in production environments.
References: