How LLMs Are Transforming OCR for the Next Generation
Large Language Models (LLMs) are transforming OCR systems by improving text recognition accuracy, enabling better multilingual support, and seamlessly integrating vision and language understanding to tackle complex tasks like scene text recognition and handwritten content.


Understanding Optical Character Recognition
Optical Character Recognition (OCR) is a technology that converts different types of documents, such as scanned paper documents, PDF files, or images captured by a camera, into editable and searchable data. OCR has a wide range of applications, including document digitization, visual search, and text extraction, etc.
OCR systems have evolved significantly, ranging from general-purpose systems capable of recognizing characters from many different writing systems, to specialized systems designed for specific applications like bank checks and license plates. Traditional OCR primarily relied on recognizing patterns of individual characters or text lines, often followed by some post-processing techniques to improve accuracy, such as spelling correction.
Traditional OCR Techniques
Early OCR systems operated by recognizing individual characters and were often limited by the accuracy of their optical models. With advancements in computing, modern OCR systems have adopted machine learning techniques, integrating language models to predict the likelihood of different word or character sequences. For instance, post-processing using language models has been instrumental in improving OCR output by estimating prior probabilities of text recognition, thus allowing for more accurate results.
The integration of language models into OCR systems has allowed these models to operate as a support mechanism, refining output based on domain-specific contexts. For example, the recognition of medical prescriptions or invoices can be significantly improved by integrating customized vocabulary, making the OCR output more reliable in specialized domains.
Key Components of OCR Systems
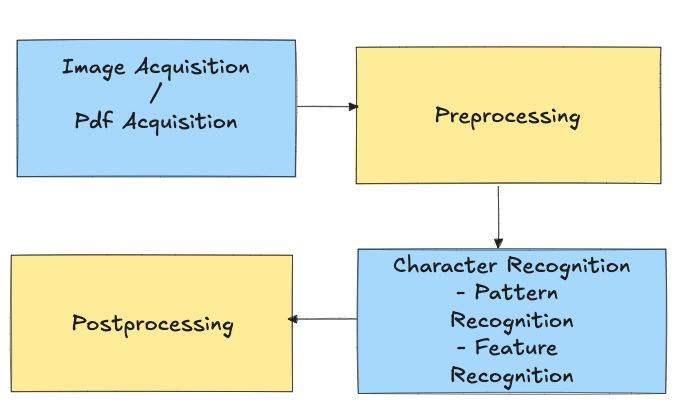
Image Acquisition and Preprocessing
Image acquisition is the first step in an OCR workflow, and its quality can significantly impact OCR performance. Preprocessing techniques, such as noise reduction, binarization, and skew correction, are crucial to enhancing the quality of images for better OCR results. These preprocessing methods prepare the input for subsequent character recognition by making text more distinguishable and ensuring consistency across different input sources.
Text Detection and Recognition
Text detection and segmentation are pivotal in identifying the areas within an image that contain text. This process involves detecting text blocks and then segmenting the text into individual characters or words for recognition. Segmenting correctly ensures that each component of the text can be accurately read and interpreted. The document "Enhancing Multimodal Large Language Models with Vision Detection Models - An Empirical Study" discusses advanced segmentation methods involving the integration of object detection models, which helps in segmenting complex layouts.
Postprocessing for Accuracy
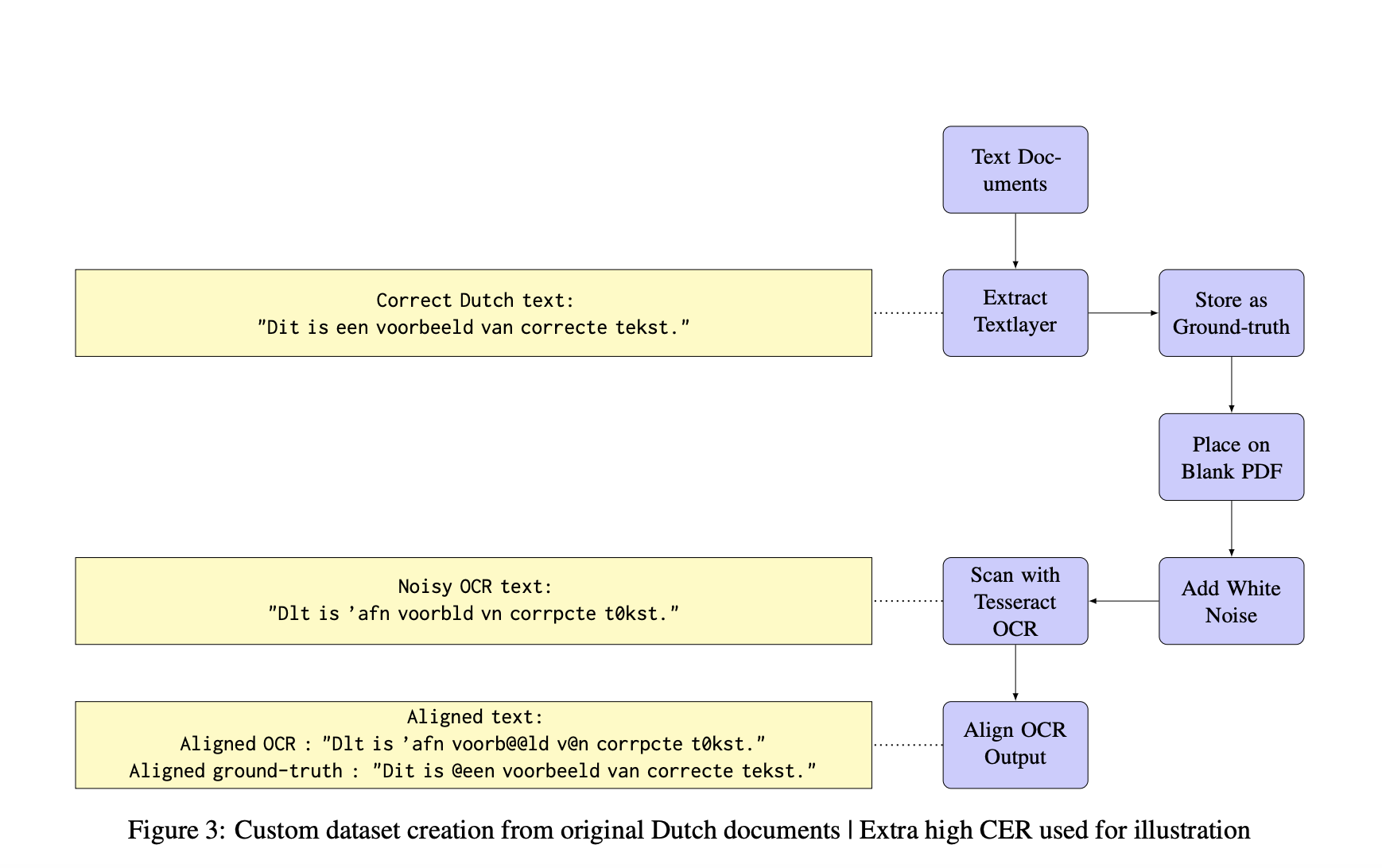
Postprocessing techniques play a crucial role in refining OCR outputs, particularly in cases involving challenging texts such as those with complex fonts or low resolution. Large Language Models (LLMs), like ByT5 and Llama 7B, have been applied successfully for OCR post-correction, leveraging their understanding of context to reduce character error rates significantly. Fine-tuning LLMs specifically for OCR post-correction has proven to improve text coherence and overall recognition accuracy. For instance, a study demonstrated that ByT5, when fine-tuned for this task, reduced the Character Error Rate (CER) by 56%, which was a significant improvement over traditional methods.
Challenges of Traditional OCR Systems
Multilingual and Handwritten Texts
Traditional OCR systems often face significant challenges when dealing with handwritten and multilingual texts. These systems struggle with handwritten texts because of the inherent inconsistencies in human handwriting, which can vary widely even among individual writers. Additionally, recognizing text in multiple languages, especially non-Latin scripts, further complicates the task, as different languages require different sets of character recognizers and language models. Even advanced OCR systems have limitations in recognizing multilingual content, particularly for languages such as Chinese, which exhibit complex visual patterns.

Complex Layouts and Document Quality
OCR systems are also challenged by complex layouts and low-quality documents. This issue becomes evident when dealing with visually rich documents that contain tables, forms, or other non-standard text layouts. Documents with poor image quality, such as those scanned under suboptimal conditions or containing faded text, exacerbate these difficulties. Large multimodal models, while capable of basic OCR tasks, still encounter significant issues when recognizing text from low-quality or blurry images, complex document layouts, and diverse input formats.
How LVLMs are Revolutionizing OCR
Introduction to LLMs in OCR
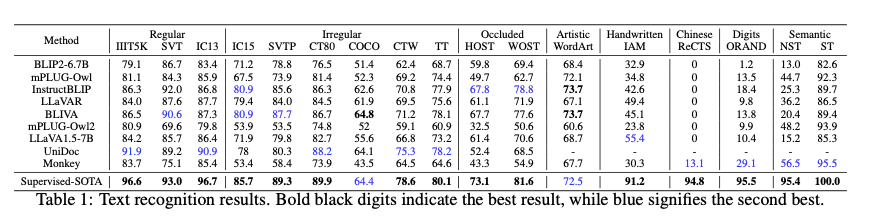
Large Vision Language Models (LVLMs) like GPT-4V, Llama 3.2 11B-Vision, LLaVA-1.5 are playing a pivotal role in advancing Optical Character Recognition (OCR) by incorporating contextual analysis into the recognition process. LVLMs have significantly enhanced OCR by allowing models to understand and interpret complex visual elements, providing a more nuanced and accurate text extraction, especially for multi-lingual complex document. By embedding object detection outputs directly into LLMs, the models can process textual and visual cues in tandem, reducing errors in scenarios involving scene text or complex document layouts. Experiments demonstrate that integrating OCR with multimodal LLMs can lead to performance improvements of up to 12.5% on various visual benchmarks.

Next-Generation OCR Systems Powered by LVLMs
Contextual Accuracy Improvements
Next-generation OCR systems have seen significant improvements in accuracy, largely due to the integration of Large Language Models (LLMs). These models leverage their extensive training on human language and preference to improve text coherence and correct errors more effectively than traditional OCR approaches. For instance, fine-tuning character-level LLMs like ByT5 on OCR-specific tasks has been shown to achieve a substantial reduction in Character Error Rate (CER). The ByT5 model achieved a CER reduction of 56%, compared to 48% from traditional sequence-to-sequence baselines. Such improvements underscore the potential of LLMs in refining OCR results, especially in complex scenarios involving ambiguous or low-quality text.
Advancements in Multilingual Recognition
While traditional OCR systems have faced challenges with non-Latin scripts, LLMs have made strides in addressing these issues, particularly with multilingual text recognition. Multimodal models like GPT-4V demonstrate a strong capability to recognize Latin-based languages such as English, French, and German, but continue to struggle with non-Latin scripts. Research shows that LLMs can improve multilingual OCR accuracy by providing context that helps in disambiguating similar-looking characters. However, the performance gap remains significant for more complex languages like Chinese or Japanese, where specialized models still outperform general-purpose LLMs in OCR tasks.
Future Directions in OCR with LLMs
Unified Multimodal Models
Future advancements in OCR are likely to focus on unified multimodal models that integrate vision and language processing capabilities. These models, such as GPT-4V and LLaVA-1.5, have demonstrated the potential to achieve superior accuracy in text recognition tasks by understanding and combining visual and textual data. However, challenges remain in areas such as non-semantic text, handwritten content, and multilingual text, where these models still underperform compared to domain-specific methods. Increasing the resolution of input images and refining visual tokenization methods are critical steps for improving model performance.
Expanding the Application Landscape
OCR technology powered by LLMs has the potential to transform industries by enabling more complex applications. For instance, applications in healthcare can leverage OCR to process handwritten prescriptions, while financial services can use it for automated document verification. Expanding the training datasets to include diverse and domain-specific content will enhance the robustness of OCR systems, making them more versatile in addressing real-world challenges.
Overcoming Current Limitations
Current OCR systems, even those using advanced LLMs, struggle with non-semantic and multilingual text recognition. To overcome these limitations, future research could focus on designing specialized datasets and architectures tailored for these challenges. Benchmark initiatives such as OCRBench, which provide comprehensive evaluations across various text recognition tasks, will play a vital role in guiding these improvements.
References: