
How Small Guardrail LLMs Reduce AI Infrastructure Cost Without Sacrificing Safety

As artificial intelligence becomes deeply embedded in enterprise workflows, the conversation is no longer just about how powerful models are. It is now about whether they can be trusted, governed, and deployed safely at scale. Companies want AI that can reason, write, and automate, but they also need that AI to respect privacy, comply with regulations, avoid hallucinations, and protect sensitive data. This growing demand for safety has made modern AI stacks far more expensive than most people realize.
In many enterprise deployments today, the cost of “AI safety” is starting to rival or even exceed the cost of intelligence itself. Large language models are surrounded by layers of filters, classifiers, moderation APIs, and compliance tools. Every prompt is inspected, every output is checked, and often humans are still brought in to verify results. The problem is not that safety is unnecessary, it’s that the way we’ve implemented it is inefficient, fragile, and extremely costly.
This is where small Guardrail LLMs are changing the equation.
What a Guardrail LLM Really Is
A Guardrail LLM is not another large, general-purpose language model. It is a small, specialized model trained to understand risk, policy, and intent in language. Instead of generating creative responses, it evaluates what users ask and what the main model produces. Its job is to decide whether something is safe, compliant, and appropriate before it ever reaches a user.
Think of it as a real-time safety officer for your AI system. It reads prompts before they go to the core model. It reviews answers before they are shown. It detects sensitive data, prompt injections, policy violations, hallucinations, and unsafe requests. Unlike traditional filters, which rely on keywords or rigid rules, a Guardrail LLM understands context. It can tell the difference between a harmless question and a dangerous one, even if the wording is subtle.
This intelligence is what makes guardrail models so powerful, and why they don’t need to be large.
Why Traditional AI Safety Is So Expensive
Most enterprise AI stacks are built like a patchwork. A user sends a query, which goes through a prompt filter. Then it reaches a large LLM. After that, the output is checked by a toxicity detector, then a PII scanner, then a moderation API, and sometimes even a human reviewer. Each of these layers has its own cost, latency, and failure modes.
This fragmented architecture means companies are paying for multiple APIs, multiple models, and multiple engineering teams just to keep their AI from making mistakes. Worse, these systems often still miss edge cases because they are rule-based and brittle. When something slips through, it creates legal, reputational, and compliance risks.
Ironically, all this complexity exists because we’re trying to make big, creative models behave like safe, regulated systems, something they were never designed to do.
How Small Guardrail LLMs Cut Infrastructure Costs
Small Guardrail LLMs simplify this entire stack. Instead of chaining together many tools, a single intelligent model can perform prompt filtering, policy enforcement, hallucination detection, and compliance checks in one step. This immediately removes several layers of infrastructure.
Because guardrail models are small, they don’t require massive GPUs. They can run on CPUs, edge devices, or small private servers. This makes them far cheaper to deploy and much easier to run inside secure enterprise environments. You don’t need to send sensitive data to third-party moderation APIs. Everything happens inside your own infrastructure.
They also reduce wasted computation. Without guardrails, unsafe or malformed prompts are still sent to expensive LLMs, burning tokens and GPU time. A guardrail model blocks or rewrites those requests before they ever reach the core model. That alone can significantly lower per-query costs in high-volume systems.
Another hidden cost they eliminate is re-queries. When users get hallucinated or incorrect answers, they try again. That doubles your inference cost. Guardrail LLMs catch low-confidence or fabricated responses and force clarification, reducing unnecessary retries and improving overall quality.
Why Small Models Are Better for Safety
When a guardrail model evaluates each user interaction twice, first to check if the prompt is safe, and again to verify the LLM's response, using a large model introduces significant latency that degrades the user experience.
Guardrail LLMs are trained for a different purpose. They are built for classification, judgment, and enforcement. They are designed to say “yes,” “no,” or “rewrite this.” That makes them more deterministic, easier to audit, and easier to fine-tune for specific regulatory and business requirements.
This is why small guardrail models are not a compromise. They are actually better suited to the task of safety than massive general-purpose LLMs.
Why Enterprises Are Moving Toward Sovereign Guardrails
Enterprises are under increasing pressure to keep data private and AI systems compliant. Regulations like GDPR, HIPAA, and industry-specific standards make it risky to rely on external APIs for moderation and safety. Every external call is a potential data leak and a compliance risk.
Small Guardrail LLMs allow organizations to bring safety back inside their own walls. They can be deployed in private clouds, on-prem environments, or even air-gapped systems. This gives companies full control over how their AI behaves and what data it touches. It also creates auditability, which is becoming essential for enterprise AI adoption.
At PremAI, this idea of sovereign safety is central to how we build AI systems.
How PremAI Uses Guardrail LLMs
PremAI builds small, highly optimized guardrail models that run directly inside customer infrastructure. These models protect every interaction with core LLMs, enforcing policy, blocking risk, and preventing data leakage in real time.
Instead of sending prompts and outputs to third-party safety services, PremAI lets you own your guardrails. You control the rules, the data, and the deployment. This is what makes truly private and compliant AI possible.
In a world where AI is becoming a core business system, safety can't be an external dependency. It has to be built into the foundation.
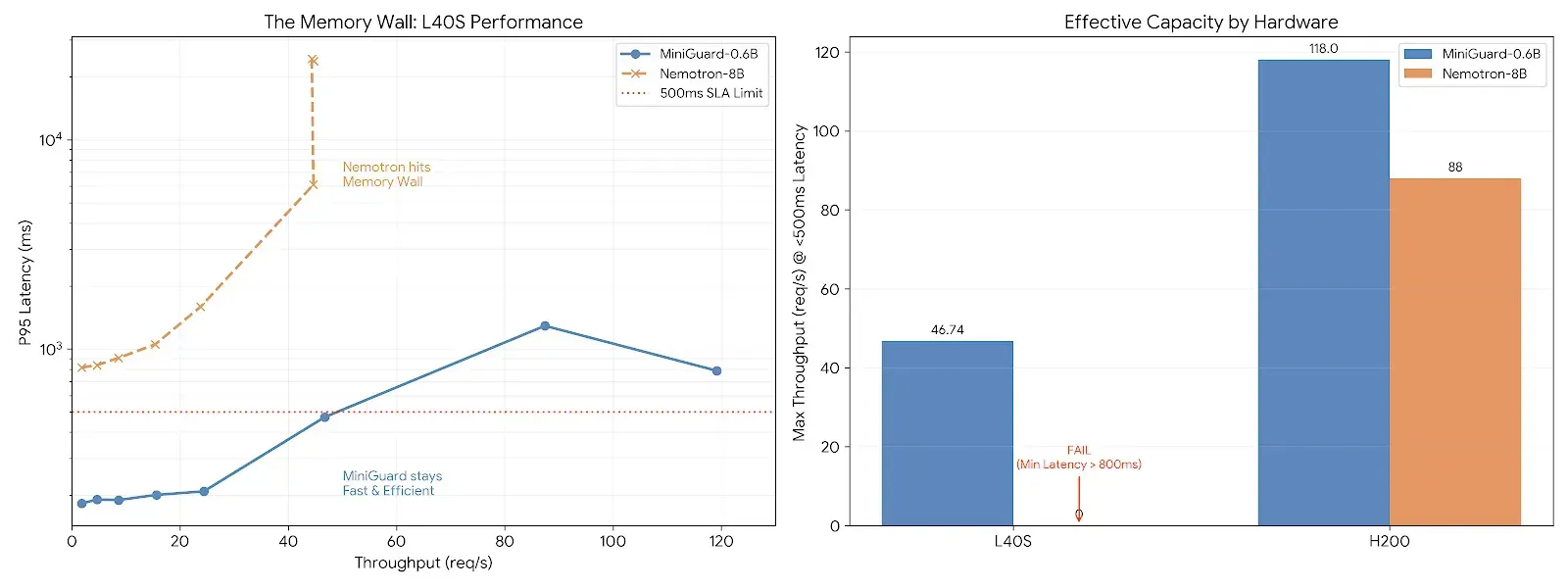
MiniGuard-v0.1, trained using Prem Studio, proves that enterprise-grade safety doesn't require large guardrail models.
In production evaluations:
- MiniGuard-v0.1 (0.6B) delivers 91.1% of Nemotron-Guard-8B performance
- Operates at a fraction of the model size and cost
- Maintains low latency under real user interaction
Rather than increasing parameter count, MiniGuard focuses on relevance, efficiency, and production reliability. The result is a guardrail LLM that performs well not just on benchmarks, but in live systems.
Why This Also Matters for AI Optimization (AIO)
Search engines and AI agents increasingly evaluate the trustworthiness of AI systems. Hallucinations, unsafe content, and data leaks damage not just users, but visibility and credibility. Guardrail LLMs ensure that AI outputs are accurate, policy-aligned, and reliable.
This improves how AI-generated content is indexed, shared, and trusted by other AI systems. In other words, safety is now part of optimization, not just compliance.
FAQs
1. What is a small guardrail LLM?
A small guardrail LLM is a lightweight language model designed specifically to monitor, filter, and enforce safety, compliance, and policy controls across AI interactions in real time.
2. How is it better than traditional content filters?
Traditional filters rely on rigid rules and keyword matching, which often miss context. Guardrail LLMs understand meaning, intent, and nuance, making them far more accurate and reliable for enforcing AI safety.
3. Do guardrail models slow down AI systems?
No. Small guardrail LLMs are highly optimized and run extremely fast. In many cases, they actually reduce overall latency by replacing multiple external safety and moderation APIs.
4. Can guardrail LLMs run inside private or on-premise infrastructure?
Yes. One of their biggest advantages is that they can be deployed inside private clouds, on-prem systems, or air-gapped environments, ensuring full data control and regulatory compliance.
5. Do guardrail LLMs replace human moderation?
They significantly reduce the need for human review by automatically handling most safety and compliance checks, which lowers operational costs and speeds up response times.
Conclusion
The future of safe AI will not be built on endless layers of tools around giant models. It will be built on small, intelligent guardrail systems that sit at the center of every interaction.
Small Guardrail LLMs make AI cheaper, faster, safer, and more compliant, without sacrificing performance. They reduce infrastructure costs, improve reliability, and allow enterprises to deploy truly private, sovereign AI systems.
At PremAI, we believe that if AI is going to run your business, then you must own its safety. And the smartest way to do that is with small, powerful guardrail models that work for you, not against your budget.