How to Train a Small Language Model: The Complete Guide for 2026
Training a small language model costs 50x less than running LLM APIs long-term. Learn three practical paths to build your own SLM, from dataset to deployment.

A single GPT-4 API call costs roughly $0.03. Run 10,000 queries a day for six months, and you're looking at over $50,000. A fine-tuned small language model running on a $1,500 GPU does the same job for a fraction of that, with your data never leaving your servers.
That's the real reason SLMs are taking over enterprise AI.
This guide walks through three practical paths to train a small language model: building from scratch, fine-tuning, and distilling from a larger model. Each path has different cost, timeline, and skill requirements.
What Counts as a Small Language Model?
There's no hard rule, but most practitioners draw the line at 14 billion parameters or fewer. Anything above that starts requiring multi-GPU setups and serious infrastructure.
Here's where the most capable SLMs sit today:
These models punch well above their size. Phi-4 Mini scores 91.1% on SimpleQA factual benchmarks. That's competitive with models 10x its size. The gap between small language models and large language models is closing fast, especially for domain-specific tasks.
Three Paths to Train a Small Language Model
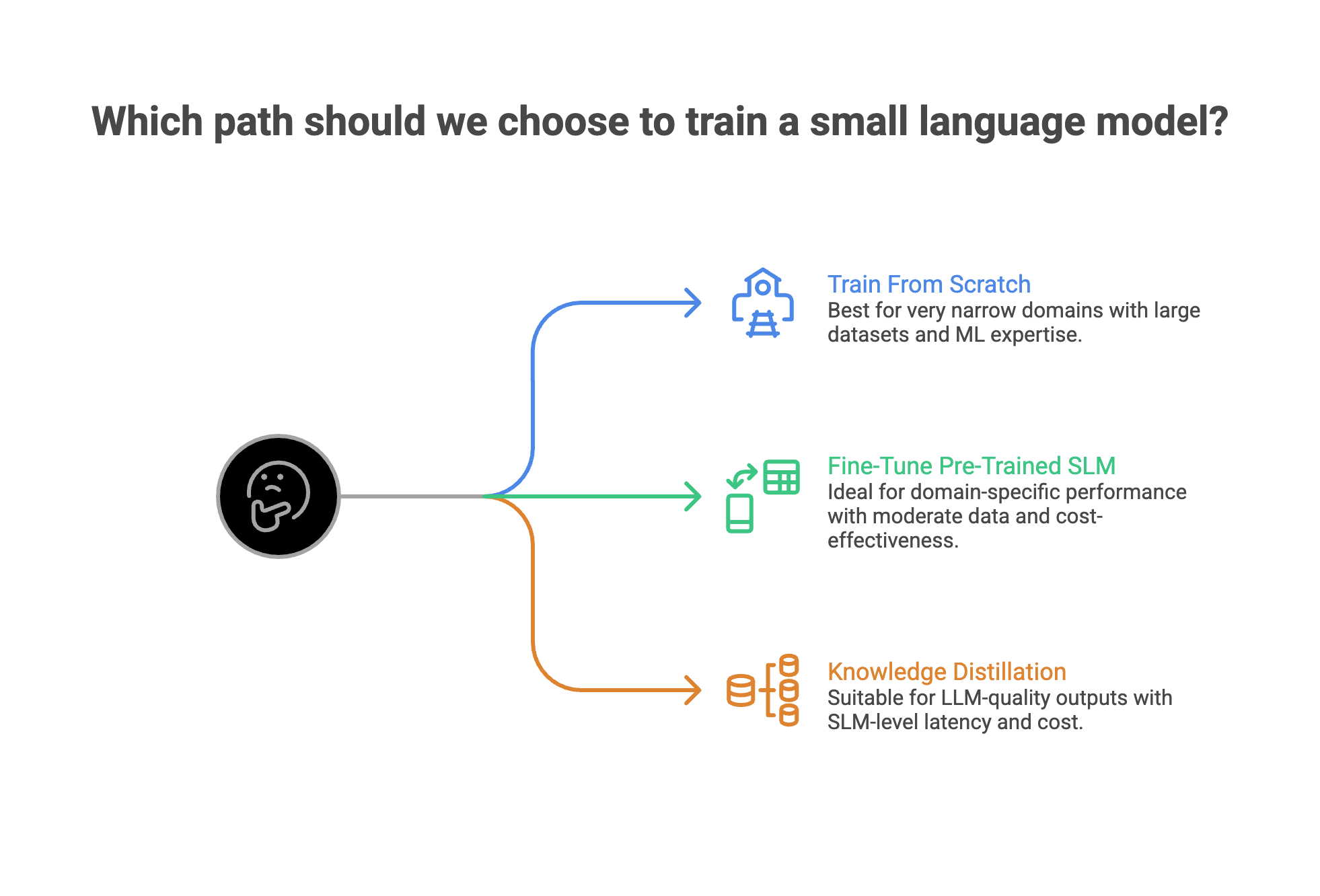
Most guides frame this as a binary choice: build from scratch or fine-tune. That misses a third option that's often the best fit for enterprise teams.
Path 1: Train From Scratch
You design the model architecture, prepare a training dataset from the ground up, and train every parameter.
When it makes sense: You need a model under 100M parameters for a very narrow domain (like parsing internal log formats or handling a proprietary language). You have enough domain-specific training data, usually millions of examples. And you have ML engineers who can handle architecture decisions.
Cost: $500-$5,000 in compute for a sub-1B model on cloud GPUs. Weeks to months of engineering time.
Tradeoff: Full control, but you're starting cold. The model has zero world knowledge until you train it.
Path 2: Fine-Tune a Pre-Trained SLM
Start with an existing model (Phi-4, Gemma, Llama) and adapt it to your specific task using your domain data. Techniques like LoRA and QLoRA make this possible on a single consumer GPU.
When it makes sense: You want domain-specific performance but don't need to reinvent the wheel. You have hundreds to thousands of labeled examples. This covers 80% of enterprise SLM use cases.
Cost: $10-$100 in compute per fine-tuning run. Hours to days, not weeks.
Tradeoff: Best cost-to-performance ratio. You keep the base model's general knowledge and add your specialization on top.
Path 3: Knowledge Distillation
Use a large model (the "teacher") to generate high-quality outputs, then train a smaller model (the "student") to replicate those outputs. The student learns the teacher's behavior without needing the teacher's size.
When it makes sense: You want LLM-quality outputs but need SLM-level latency and cost. You can afford to run the teacher model temporarily to generate training data.
Cost: Teacher model inference cost (variable) plus fine-tuning cost. Usually $200-$2,000 depending on dataset size.
Tradeoff: You get 10x smaller models with comparable inference speed, but you're bounded by the teacher's capabilities.
Here's a quick decision framework:
Step 1: Prepare Your Dataset (The Part Everyone Skips)
Data quality matters more than model size. Microsoft proved this with Phi-3: they trained on "textbook-quality" synthetic data and got a 3.8B model that competes with models 25x larger.
The takeaway is straightforward. A clean dataset of 5,000 examples often outperforms a noisy dataset of 50,000.
Here's what good SLM training data looks like:
1. Format consistency.
Pick one format (JSONL is standard for fine-tuning) and stick to it. Every example should follow the same structure: input/output pairs, or instruction/response pairs for chat-style models.
2. Domain relevance.
If you're training a customer support model, every example should come from actual support conversations. Generic web data dilutes performance. Models trained on domain-specific data consistently outperform larger general-purpose models on the tasks they're built for.
3. PII handling.
Enterprise data almost always contains sensitive information. Strip it before training. This isn't optional if you're in a regulated industry. Automated PII redaction tools can handle this at scale without manual review, saving roughly 75% of the manual effort typically spent on data cleaning.
4. Balance and diversity.
If 90% of your training examples are about one topic, the model will overfit to that topic. Ensure your dataset covers the full range of inputs you expect in production.
5. Synthetic data augmentation.
When you don't have enough real examples, synthetic data generation can fill the gap. Use a larger model to create variations of your existing examples. This works especially well for the distillation path.
Step 2: Pick Your Base Model and Training Setup
For fine-tuning (the most common path), your base model choice depends on your task and hardware.
For general text tasks: Llama 3.2 3B or Qwen 2.5 3B. Strong all-rounders with active communities.
For reasoning-heavy tasks: Phi-4 Mini. Best-in-class reasoning at the 3-4B parameter range. Worth reading about how custom reasoning models are built.
For multilingual tasks: Qwen 2.5 or Gemma 3. Both handle 20+ languages natively.
For edge deployment: SmolLM2 1.7B or Gemma 3 270M. Small enough to run on mobile devices and IoT hardware.
Hardware Requirements
You don't need a data center. A single GPU handles most SLM training jobs.
With 4-bit quantization (QLoRA), you can fine-tune a 7B model on an RTX 4090. That's a consumer card. Enterprise AI doesn't always need enterprise hardware.
Step 3: Train or Fine-Tune Your SLM
Fine-Tuning with LoRA (Most Common)
LoRA (Low-Rank Adaptation) freezes the base model and trains small adapter layers on top. This cuts memory requirements by up to 90% and trains 2-3x faster than full fine-tuning.
A typical fine-tuning workflow looks like this:
Collect domain data → Clean and format → Configure LoRA parameters → Train → Evaluate → Deploy
Key LoRA settings that matter:
- Rank (r): 8-16 for most tasks. Higher rank = more capacity but more memory.
- Alpha: Usually 2x the rank. Controls the learning rate scaling.
- Target modules: Apply LoRA to attention layers (q_proj, v_proj) for best results.
Platforms like Prem Studio handle this workflow end-to-end. You upload your dataset, pick a base model from 30+ options, and the autonomous fine-tuning system handles hyperparameter selection, training, and evaluation. This cuts the typical fine-tuning timeline from days of experimentation to hours.
Training From Scratch (For Small Custom Models)
If you're building a sub-100M parameter model, you'll define a transformer architecture from the ground up: tokenizer (BPE is standard), embedding layer, transformer blocks (self-attention + feed-forward), and an output head. For a 15M parameter model, 6 transformer layers with 384-dimensional embeddings is a reasonable starting point. Train on your domain corpus using next-token prediction.
Step 4: Evaluate Before You Ship
Deploying without proper evaluation is how companies end up with chatbots that hallucinate confidently. SLMs need tighter evaluation than LLMs because they have less room for error.
Evaluation approaches that work:
Benchmark testing. Run your fine-tuned model against standard benchmarks relevant to your task. Compare against the base model to measure improvement.
LLM-as-a-judge. Use a larger model to score your SLM's outputs on accuracy, relevance, and quality. This scales better than human evaluation. Proper evaluation methodology is the difference between a model that demos well and one that works in production.
Side-by-side comparison. Run the same prompts through your SLM and a baseline. Human evaluators compare outputs blind. Prem Studio's evaluations module supports all these approaches, including custom rubrics for domain-specific criteria.
A/B testing in production. Route a percentage of real traffic to the new model and monitor metrics. Final validation before full rollout.
Step 5: Deploy and Keep the Model Fresh
Training is half the work. Deployment and ongoing maintenance are the other half.
Deployment Options
Self-hosted inference. Run your model on your own infrastructure with tools like vLLM or Ollama. Target sub-100ms latency for real-time applications. Self-hosting guides cover the setup.
Edge deployment. Models under 2B parameters can deploy directly to edge devices like phones or IoT hardware. No cloud dependency, no data leaving the device.
Hybrid setup. Use the SLM for routine queries locally, route complex ones to a larger model in the cloud. Most production systems use this approach to balance cost and capability.
Model Drift Is Real
Your SLM will degrade over time as real-world data shifts away from the training distribution. A customer support model trained on 2024 conversations will start underperforming when product names, policies, and common issues change in 2025.
Plan for continual learning from the start. Set up a pipeline that collects new data from production, flags performance drops, and triggers retraining cycles. Quarterly retraining is a reasonable starting cadence for most use cases.
When Small Language Models Are the Wrong Choice
SLMs aren't a universal solution. They genuinely struggle with multi-step reasoning over long contexts, cross-domain generalization, creative generation that needs consistent novelty, and complex code generation across full applications.
The honest assessment: if your use case requires broad knowledge across many domains with high accuracy, an LLM (or a cost-optimized LLM API setup) is the better fit. SLMs win when the task is specific, the data is focused, and latency or privacy matters.
FAQ
1. How many parameters is considered a small language model?
Most practitioners define SLMs as models with fewer than 14 billion parameters. The sweet spot for enterprise use cases is 1B to 7B parameters, which balances capability with reasonable hardware requirements.
2. Can I train a small language model on a laptop?
For fine-tuning with QLoRA, yes. A laptop with an RTX 3060 (6GB VRAM) can fine-tune models up to about 3B parameters. Training from scratch requires more compute, but models under 100M parameters are still feasible on consumer hardware.
3. How much data do I need to fine-tune an SLM?
It depends on your task complexity. For straightforward classification or extraction tasks, 500-1,000 high-quality examples can be enough. For more nuanced generation tasks, aim for 5,000-10,000 examples. Quality beats quantity every time, so invest in dataset curation over volume.
Conclusion
Small language model training isn't a research exercise anymore. The tools, base models, and workflows exist to go from dataset to production in days.
The biggest mistake teams make is defaulting to an LLM API when a fine-tuned 3B model would handle the job at 1/50th the cost with better latency and full data control. The second biggest is skipping dataset preparation and evaluation, then wondering why the model hallucinates.
Fine-tuning covers most enterprise use cases. Distillation works when you need to compress LLM-quality outputs into something small enough for edge devices. Training from scratch is reserved for genuinely unique domains where no existing model gets close.
To skip the infrastructure setup and get straight to fine-tuning, Prem Studio handles the full pipeline from dataset upload to deployment. Get started here.