Introducing Prem-1B
Prem AI introduces Prem-1B, an open-source Small Language Model built for Retrieval-Augmented Generation (RAG) tasks. Based on a decoder-only transformer architecture, it supports up to 8192 tokens. The model is available on Hugging Face under Apache 2.0.

With great enthusiasm, we unveil the Prem-1B series, an open-source, multipurpose large language model developed by Prem AI. This cutting-edge SLM offers the open community and enterprises the opportunity to harness capabilities that were once exclusively available through closed-model APIs, empowering them to build their advanced language models. The weights of the base model (Prem-1B base) and the finetuned chat model (Prem-1B Chat) are available on HuggingFace under APACHE LICENSE 2.0.
🎯 Our Objective
We aim to develop a model that excels at Retrieval-Augmented Generation (RAG). While Large Language Models (LLMs) store a vast amount of information within their parameters, RAG operates differently by ingesting information during runtime. This approach suggests that for RAG applications, we may not require models of immense size. With this initiative, we aim to create a Small Language Model (SLM) with an extended context length of 8192 tokens, enabling it to handle multi-turn conversations effectively. This endeavor represents our inaugural attempt to craft an SLM tailored for RAG tasks. Read more about our hypothesis here.
💻 Infra Setup
Our infrastructure dedicated to model training is equipped with 16 H100 GPUs, distributed across two nodes, each hosting 8 GPUs. To facilitate multi-GPU training, these nodes are interconnected through the utilization of Ray, a distributed computing framework. We faced a few challenges while setting up the environment, which we explored in our previous blog, link below 👇


🏛️ Architecture
Prem-1B is a transformer-based decoder-only SLM that was trained using next-token prediction. The architecture is based on Llama 2 used by TinyLlama with flash-attention. Note that TinyLlama was trained with a context length of 2048, but Prem-1B supports a context length of up to 8192. Considering the recent release of Llama 2 and Llama 3 and their amazing performance and benchmarks, we went with this Llama architecture based on transformers. We explored Mamba architecture, Mixture of Experts (MOE) architectures, and recent technical reports of H2O-Danube-1.8B, Stable LM 2 1.6B, Phi3, and Llama3 models, and figured it’s not about architecture, but mainly about diverse quality data.
🏋️♂️ Pre-training
During the pre-training stage, we employed SlimPajama. We adopted Llama's tokenizer to process the data corpus. In the pre-processing phase, we packed multiple instances of data up to the defined context length of 8192 tokens, minimizing the need for excessive padding. The core objective behind pre-training is to ingest information and enable the large language model to comprehend sentence formation and perform text completion tasks effectively. We tried pre-training the model without packing the datasets, but it didn’t perform well. Mainly because most of the available open-source datasets don’t have long context data points, and if you don’t pack them during pre-training, most of the tokens will just be pad tokens, and the model will not learn anything.
In preparing the packed dataset, we utilized Lightning Data, a tool designed for efficient data handling and pre-processing. As the primary purpose of this model is to perform well on English content, we filtered out any data points containing code-specific information. After the pre-processing phase, we had accumulated 600B tokens, which were trained over the course of two epochs, totaling 1.2T tokens. Considering the research objective of developing an exceptional RAG SLM, we adopted an extended context length of 8192 tokens. We spent a total of 8500 GPU hours on pre-training.
Here is the final training config for pre-training:
model:
model_args:
model_name: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
max_position_embeddings: 8192
flash_attention: true
dtype: bfloat16
optimizer_args:
lr: 0.0004
betas: [0.9, 0.95]
weight_decay: 0.1
lr_scheduler_args:
num_warmup_percentage: 0.1
data:
train_path: "<train_data>"
val_path: "<train_data>"
max_seq_length: 8192
batch_size: 2
trainer:
accelerator: auto
precision: bf16-mixed
log_every_n_steps: 1
gradient_clip_val: 1
accumulate_grad_batches: 16
max_epochs: 2
val_check_interval: 92000
limit_val_batches: 1.0
limit_train_batches: 1.0
reload_dataloaders_every_n_epochs: 1
💬 Chat-Finetuning (SFT)
The pre-trained model serves as a foundation, a base model. However, base models are not designed for conversational interactions, so they are unsuitable for chat applications. To transform the base model into a capable assistant, we employ a process called chat fine-tuning. At a high level, this approach involves creating a structured prompt and ingesting it instead of raw data. The structured prompt is designed to simulate a conversation between a human and an assistant, and the model is trained to predict the assistant's response. The process of chat fine-tuning can be summarized as follows:
- Added a prompt template. For this, we adopted the Llama 3 chat template.
- Used dataset with multi-turn conversation data points. In a few of the datasets, we didn’t have a system prompt, so we just added a very generic base system prompt.
- The model was trained on 4-H100 GPUs for 12 hours.
- No data-packing like we did in the pre-training stage.
Following are the config/hyperparameters for the chat-finetuning stage:
model:
model_args:
model_name: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
max_position_embeddings: 8192
flash_attention: true
dtype: bfloat16
optimizer_args:
lr: 0.00005
betas: [0.9, 0.95]
weight_decay: 0.1
lr_scheduler_args:
num_warmup_percentage: 0.1
data:
train_path: "<train_dataset>"
val_path: "<val_dataset>"
max_seq_length: 8192
batch_size: 2
dataset_tokenizer: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
trainer:
accelerator: auto
precision: bf16-mixed
log_every_n_steps: 1
gradient_clip_val: 1
accumulate_grad_batches: 16
max_epochs: 3
limit_val_batches: 1.0
limit_train_batches: 1.0
Masked the whole prompt except the assistant responses while calculating the loss. This ensures that we only calculate the loss for the assistant tokens. Even in the case of multi-turn conversation data points, we masked all the assistant responses. For eg. consider the following data point formatted with the template:
<s><|start_header_id|>system<|end_header_id|>
You are a helpful AI assistant.<|eot_id|>
<|start_header_id|>user<|end_header_id|>hi<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
Hello! How can I help you today?<|eot_id|> (Not MASKED)
<|start_header_id|>user<|end_header_id|>
who is the CEO of google?<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
The CEO of Google is Sundar Pichai<|eot_id|> (Not MASKED)
<|start_header_id|>user<|end_header_id|>
who is the CEO of Twitter?<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
...
We used the following datasets while finetuning. These datasets are selected based on their quality and the diverse nature of prompts:
- Ultrachat 200k
- Deita 10K V0
- Slim Orca
- WizardLM Evol Instruct V2
- Capybara
- MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
🤝 DPO and Alignment
We followed SFT, by Direct Preference Optimization (DPO). It is one of the techniques used to align our model to generate better responses. Large, unsupervised language models lack precise control over their behavior due to their unsupervised training. Existing methods like Reinforcement Learning From Human Feedback (RLHF) use complex procedures to fine-tune the models to align with human preferences. DPO is a stable and computationally efficient algorithm that solves the RLHF problem using a simple classification loss, eliminating the need for sampling or significant hyperparameter tuning. You can learn more about model alignment in this blogpost. The following datasets were used for DPO finetuning:
This stage of training is performed using the Alignment Handbook.
We used the following config for DPO finetuning. You can check the parameters in DPOConfig.
bf16: true
beta: 0.01
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
learning_rate: 4.0e-6
lr_scheduler_type: cosine
max_length: 8192
max_prompt_length: 1000
num_train_epochs: 1
optim: adamw_torch
per_device_train_batch_size: 2
seed: 42
warmup_ratio: 0.1
loss_type: sigmoid
🔢 Results
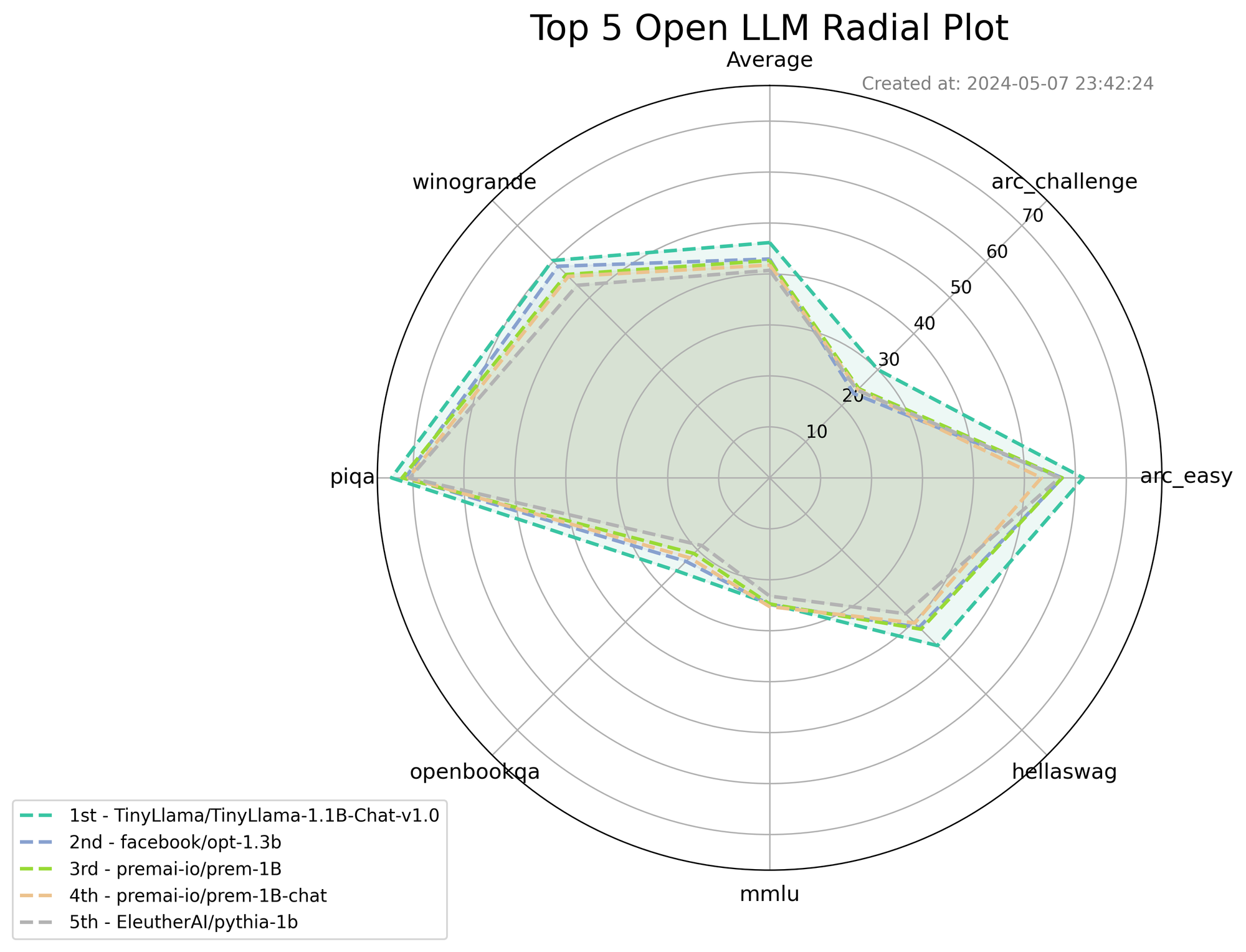
| Model | Avg | Arc-c | Arc-e | Hellaswag | MMLU | Obqa | Piqa | Winogrande |
|---|---|---|---|---|---|---|---|---|
| prem-1B | 42.64 | 24.74 | 57.40 | 42.01 | 24.75 | 21.00 | 72.14 | 56.43 |
| prem-1B-chat | 41.76 | 24.48 | 53.32 | 40.28 | 25.27 | 22.20 | 70.89 | 55.88 |
| TinyLlama-1.1B-Chat-v1.0 | 46.16 | 30.03 | 61.53 | 46.56 | 24.72 | 25.80 | 74.21 | 60.29 |
| opt-1.3b | 42.94 | 23.37 | 57.44 | 41.49 | 24.86 | 23.20 | 71.49 | 58.72 |
| pythia-1b | 40.71 | 24.31 | 56.90 | 37.72 | 23.20 | 18.80 | 70.62 | 53.43 |
🔎 Future plans
- Improve our existing model. Potentially, our focus will be on adding more quality data during pre-training and finetuning.
- We want to improve model alignment. We will be exploring model alignment techniques discussed.
- We noticed that there are a few rare cases where model generation repeats the data during inference. We need to tackle this problem.
- Usually, models released by organizations have self-knowledge about the organization and their creators. This topic is still not discussed in detail in research papers, and we will be exploring this path and sharing the results.
- Recent open-source model releases in the SLM space are around 1.6B-2B parameter models. We will be exploring some architectures in that range in our next iteration.
Other than Prem-1B, our research team at PremAI heavily worked on building the smallest and performant Text to SQL models. We also present Prem-1B-SQL which is a 1.3B parameter model (fully fine-tuned from DeepSeek 1.3B model) which is on par with GPT-3.5 and claude-2 and many other bigger open source models (like Llama 3 70B and Qwen 32B) for Text to SQL tasks.
Prem-1B-SQL is loved by the open source community. We reached more than 10K+ monthly downloads on Hugging Face and also 8K+ PremSQL library downloads. Check out our Prem-1B-SQL release blog to learn more.

🚀 Try it now!
Try it on Huggingface Chat: https://huggingface.co/premai-io/prem-1B-chat.
Or you can use the models now using Huggingface pipelines.
With model and tokenizer:
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("premai-io/prem-1B-chat")
model = AutoModelForCausalLM.from_pretrained('premai-io/prem-1B-chat', torch_dtype=torch.bfloat16)
model = model.to('cuda')
# Setup terminators
terminators = [tokenizer.eos_token_id, tokenizer.encode('<|eot_id|>', add_special_tokens=False)[0]]
# Prepare the prompt
messages = [
{
"role": "system",
"content": "You are a helpful AI assistant. You should give concise responses to very simple questions, but provide thorough responses to more complex and open-ended questions."
},
{
'role': 'user',
'content': 'Help me understand machine learning.'
}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Generate
inputs = tokenizer(prompt, return_attention_mask=False, return_tensors="pt", add_special_tokens=False)
input_ids = inputs['input_ids']
input_ids = input_ids.to(model.device)
res = model.generate(input_ids=input_ids, max_new_tokens=400, pad_token_id=tokenizer.pad_token_id, eos_token_id=terminators)
generated_text = tokenizer.decode(res[0][input_ids.shape[1]:], skip_special_tokens=True).strip()
print(generated_text)
Using pipelines:
import torch
from transformers import pipeline
# Load the pipeline
pipe = pipeline("text-generation", model="premai-io/prem-1B-chat", torch_dtype=torch.bfloat16, device=0)
# Prepare prompt
messages = [
{
"role": "system",
"content": "You are a helpful AI assistant. You should give concise responses to very simple questions, but provide thorough responses to more complex and open-ended questions."
},
{
'role': 'user',
'content': 'Help me understand machine learning.'
}
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Setup terminators
terminators = [pipe.tokenizer.eos_token_id, pipe.tokenizer.encode('<|eot_id|>', add_special_tokens=False)[0]]
# Generate
outputs = pipe(prompt, max_new_tokens=400, do_sample=True, temperature=0.7, top_k=50, top_p=0.95, pad_token_id=pipe.tokenizer.pad_token_id, eos_token_id=terminators)
print(outputs[0]["generated_text"][len(prompt):])📚 References