Large Language Models for Next-Generation Recommendation Systems
Large Language Models (LLMs) transform recommendation systems by addressing challenges like domain-specific limitations, cold-start issues, and explainability gaps. They enable personalized, explainable, and conversational recommendations through zero-shot learning and open-domain knowledge.

Unlocking the Power of Large Language Models for Advanced Recommendation Systems
The rapid evolution of online services and e-commerce platforms has led to an overwhelming amount of information for users to process. Recommender systems have emerged as crucial tools to help users navigate this vast landscape by providing personalized suggestions, but traditional models like Collaborative Filtering and Content-based Filtering face significant challenges. These include a reliance on domain-specific data, limited generalization capabilities, and an inability to provide clear explanations for recommendations.
Large Language Models (LLMs), such as GPT-4, LLaMA, and others, represent a paradigm shift in artificial intelligence. These models are pre-trained on vast amounts of data, enabling them to develop a deep understanding of language and reasoning capabilities that can be directly applied to recommendation tasks. Unlike traditional models, LLMs can handle both structured user-item interaction data and unstructured, open-domain knowledge, providing a more flexible and powerful foundation for building recommender systems.
In this article, we delve into how LLMs are being integrated into modern recommendation systems, focusing on their technical capabilities. We will explore the ways LLMs enhance feature engineering, user interaction, and explainability, and examine the emerging challenges and opportunities that arise as we adopt these advanced models in the recommender systems landscape.
Challenges in Traditional Recommendation Systems
Traditional recommendation systems, such as Collaborative Filtering (CF) and Content-Based Filtering (CBF), have been widely used in the industry to personalize user experiences. However, they have several limitations:
- Domain-Specific Limitations: Collaborative Filtering and CBF rely heavily on domain-specific data, which means they can struggle when dealing with cold-start problems (i.e., new users or items with limited interaction history). These systems are limited in their ability to generalize and learn from external sources of information.
- Explainability Issues: Traditional models often operate as black boxes, making it difficult to provide meaningful explanations for recommendations. Users are left wondering why a particular item is recommended, which can undermine trust in the system.
- Complexity in Capturing User Preferences: Advanced techniques like Graph Neural Networks (GNNs) and Self-Supervised Learning (SSL) have been used to improve CF models by capturing high-order dependencies among users and items. However, these models tend to be complex and still lack transparency when explaining user preferences.
- Limited User Interaction Capabilities: Traditional recommendation systems are not well-equipped to handle conversational or interactive recommendations. They generally lack the ability to engage in natural language exchanges, which limits the personalization and responsiveness of recommendations.
These challenges call for new solutions that can leverage open-domain knowledge, provide better explainability, and enable more natural user interactions.
How Large Language Models Are Changing the Landscape
Large Language Models are transforming recommendation systems by introducing capabilities that traditional models lack. Some key areas of impact include:

- Feature Engineering: LLMs can automatically generate auxiliary features for both users and items, enhancing the input data used for recommendations. By incorporating open-domain knowledge, LLMs enrich user-item profiles with additional context that is not explicitly available in structured datasets.
- Explainable Recommendations: LLMs are well-suited for generating textual explanations that can accompany recommendations. For example, using a framework like XRec, LLMs can explain user-item interactions by integrating collaborative signals with natural language generation, helping users understand why specific items are suggested.
- Conversational Recommendations: With their capability for natural language understanding, LLMs can significantly improve conversational recommenders. They can directly engage with users to understand their preferences in real-time, leading to more personalized and adaptive recommendations.
These advancements make LLMs an attractive option for building the next generation of recommendation systems that are more flexible, transparent, and capable of handling complex user interactions.
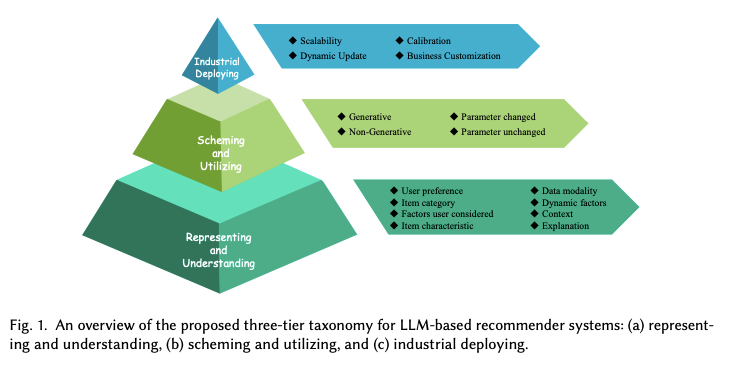
Applications of Large Language Models in Modern Recommender Systems
Large Language Models are being integrated into modern recommendation systems in several impactful ways:
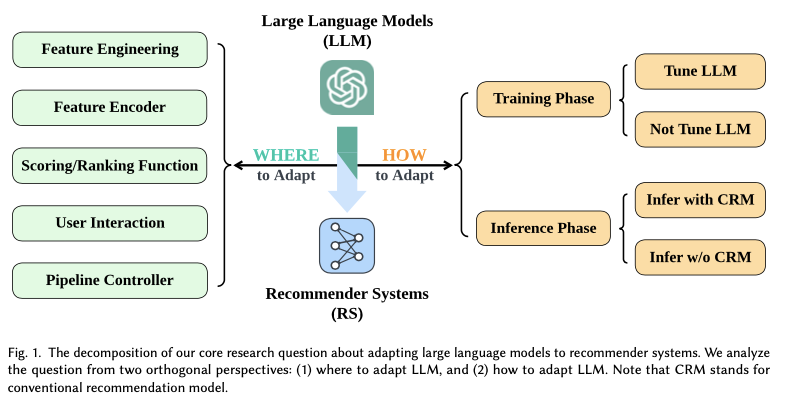
- LLMs as Feature Encoders: LLMs can encode features such as user reviews, product descriptions, and metadata to enrich the user-item interaction matrix. These enriched features can help recommendation models understand users' preferences at a deeper level. For example, using Prem-AI’s API, you can generate user and item embeddings that combine natural language and structured data, improving the performance of recommendation algorithms.
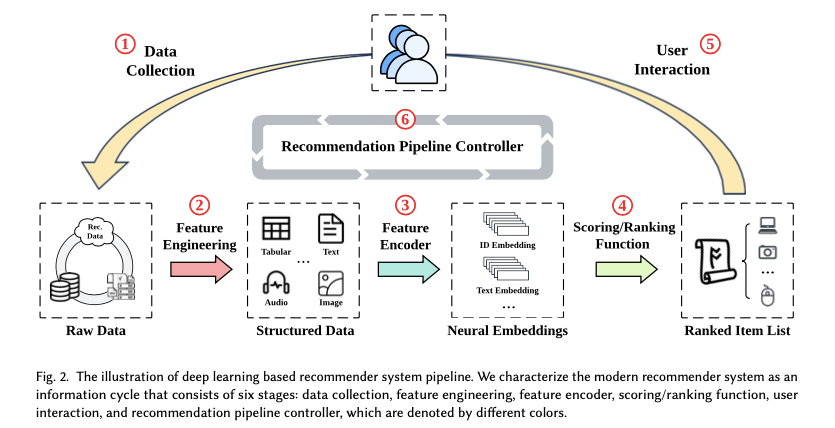
- Personalized Content Generation: LLMs are used to generate personalized content, such as product summaries or review highlights, tailored to specific users. By understanding a user's preferences, LLMs can generate content that enhances the user experience by providing more relevant information.
- Zero-Shot and Few-Shot Recommendations: LLMs have shown significant capabilities in zero-shot and few-shot learning, where they can recommend items without the need for extensive fine-tuning. By leveraging their pre-trained knowledge, LLMs can offer recommendations for items that the system has little to no prior data on.
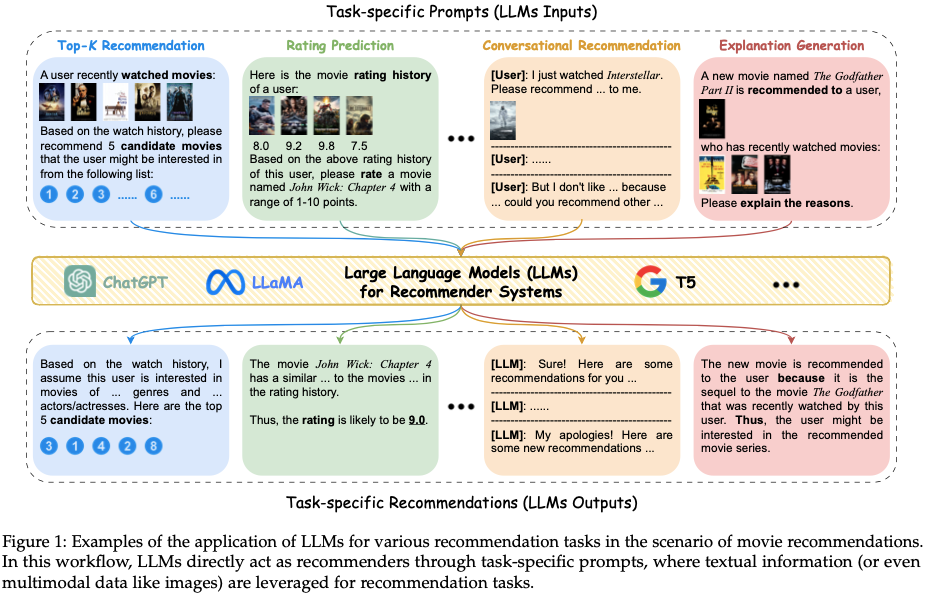
- Prompting Strategies for LLM-Based Recommendations: LLMs use sophisticated prompt engineering to maximize their recommendation capabilities. By employing effective prompting strategies, such as task descriptions, user interest modeling, and candidate item construction, LLMs can generate more precise and personalized recommendations. These prompting strategies play a critical role in adapting LLMs to various recommendation scenarios.
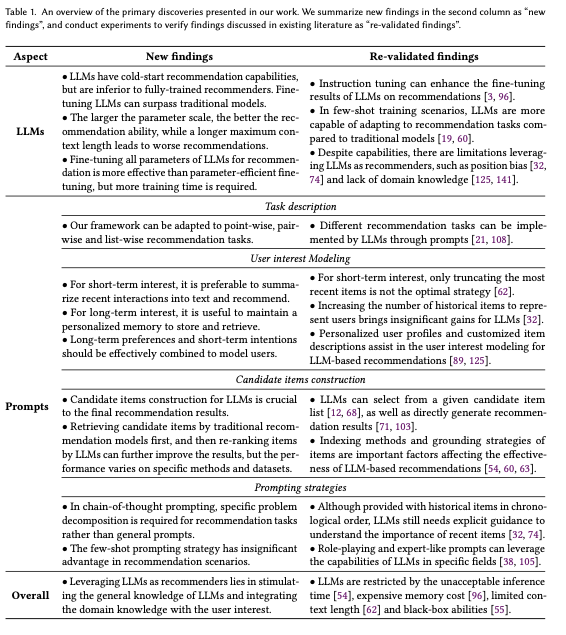
The Table below provides a comprehensive overview of the key components in prompting strategies for LLM-based recommendation systems, including task descriptions, candidate item construction, and prompting methods.
- Enhancing Explainability with LLMs: Traditional recommenders struggle to explain why a particular item was recommended. LLMs, however, can generate natural language explanations for recommendations, which can be used to improve user trust and satisfaction. This is particularly useful in domains like e-commerce and streaming services, where understanding user engagement is crucial.
- Hybrid Models: Hybrid recommender models that combine LLMs with other traditional recommendation methods (e.g., matrix factorization) can lead to performance improvements. LLMs can add contextual understanding to user-item relationships, while traditional methods ensure computational efficiency.
Evaluation of LLM-Based Recommenders
Evaluating LLM-based recommender systems requires a comprehensive approach that considers both quantitative and qualitative metrics to capture the diverse aspects of performance:
- Quantitative Metrics: LLM-based recommenders are often evaluated on traditional recommendation tasks, such as rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Key metrics used include Root Mean Square Error (RMSE), Mean Absolute Error (MAE), Hit Ratio (HR@k), Normalized Discounted Cumulative Gain (NDCG@k), and BLEU/ROUGE scores for tasks that require natural language generation.
- Benchmarking with LLMRec: The LLMRec framework is designed specifically for benchmarking the performance of LLMs on various recommendation tasks. Off-the-shelf LLMs such as ChatGPT, LLaMA, and others demonstrate moderate proficiency in accuracy-driven tasks like sequential and direct recommendation. However, they excel in explainability-based tasks, showing competitive performance in generating coherent and context-aware explanations.
- Supervised Fine-Tuning: Supervised fine-tuning (SFT) can significantly improve the instruction compliance and recommendation quality of LLMs. For instance, fine-tuning LLMs like ChatGLM with prompt-based training helps align model outputs to structured recommendation tasks, leading to improved metrics in both quantitative and qualitative evaluations.
- Qualitative Evaluation: Qualitative evaluations are crucial for understanding the quality of the generated recommendations and explanations. LLMs like ChatGPT are noted for generating clearer and more contextually relevant explanations compared to traditional models. This enhances the user experience by providing transparency and building trust in the recommendations.
- Challenges in Accuracy-Based Tasks: LLMs face challenges in accuracy-driven tasks, such as rating prediction and sequential recommendation, primarily due to the lack of task-specific fine-tuning data. However, fine-tuning with appropriate prompts and domain-specific data can help bridge this gap and improve performance.
These evaluation metrics and methods provide a holistic view of how LLMs perform across different recommendation scenarios, highlighting both their strengths in generating explainable and context-rich recommendations and the areas where
Challenges and Opportunities in Integrating Large Language Models into Recommender Systems
The integration of Large Language Models (LLMs) into recommender systems presents several challenges and opportunities. These can be categorized into technical, ethical, and practical aspects that influence how effectively these models can be adopted for recommendation tasks.
Technical Challenges
- Knowledge Misalignment: LLMs excel at natural language understanding but often lack the recommendation-specific knowledge needed for optimal performance. This knowledge misalignment arises because LLMs are trained primarily on open-domain text, while recommendation tasks require specialized understanding of user-item interactions. Techniques such as fine-tuning with auxiliary data samples that simulate operations like Masked Item Modeling (MIM) and Bayesian Personalized Ranking (BPR) are being explored to bridge this gap.
- Scalability and Efficiency: LLMs are computationally expensive, particularly when used for real-time recommendation tasks. The large number of parameters and the resource-intensive nature of inference pose significant challenges for scalability. Strategies like prompt engineering, efficient sampling, and the use of lightweight adapters have been suggested to mitigate these costs.
- Cold-Start Problem: Despite the ability of LLMs to generate contextual embeddings for unseen items or users, addressing the cold-start problem remains a challenge, particularly when there is insufficient domain-specific data. Using LLMs as feature generators for cold-start scenarios is promising, but this approach requires further optimization to be fully effective.
- Integration with Traditional Systems: Integrating LLMs into existing recommendation pipelines involves compatibility issues with traditional ID-based systems. Current methods often involve hybrid models that combine LLMs with traditional recommendation methods, such as matrix factorization, to ensure computational efficiency while benefiting from the contextual richness of LLMs.
Ethical Challenges
- Bias and Fairness: LLMs inherit biases from the large corpora of text used during their training. This can lead to biased recommendations that may perpetuate stereotypes or unfair treatment of certain groups of users. Addressing these biases is a key challenge, and ongoing research is focused on debiasing methods to ensure fairness in recommendation outcomes.
- Privacy Concerns: LLMs, by their very nature, can process large volumes of user data, which raises privacy concerns. Users may be uncomfortable with the idea of their data being used to train models that operate on a global scale. Ensuring privacy-preserving techniques, such as differential privacy and federated learning, is crucial to gaining user trust.
- Explainability and User Trust: Providing explanations for LLM-generated recommendations is important for building user trust. However, the complexity of LLMs makes it challenging to offer clear and understandable explanations. Solutions like explainable LLM architectures and post-hoc explanation methods are being explored to enhance transparency.
Opportunities
- Enhanced Personalization: The ability of LLMs to leverage open-domain knowledge allows for highly personalized recommendations that take into account a broader context, including user preferences inferred from natural language inputs. This presents an opportunity for building more responsive and context-aware recommendation systems.
- Unified Cross-Domain Recommendation: LLMs can serve as a bridge between different domains, enabling cross-domain recommendations by leveraging their understanding of user behavior across multiple contexts. This could significantly improve recommendations in scenarios where data from different domains can be aggregated to enhance personalization.
- Conversational Recommenders: LLMs excel in natural language understanding, making them well-suited for conversational recommendation systems. By engaging in real-time dialogue with users, LLMs can adapt recommendations dynamically, leading to more satisfying user experiences and better engagement.
- Rapid Adaptation through Few-Shot Learning: LLMs have demonstrated capabilities in zero-shot and few-shot learning, which can be leveraged to adapt quickly to new recommendation tasks or domains with minimal additional training. This ability to generalize effectively makes them particularly valuable in rapidly changing domains, such as news or trending content.
- Explainable AI Improvements: Leveraging LLMs to provide natural language explanations for recommendations can improve the transparency and trustworthiness of recommender systems. This aligns well with the increasing demand for AI systems that are not only effective but also explainable to end-users.
Future Directions
The future of LLM-based recommender systems looks promising, with several avenues for improvement and exploration:
- Fine-Tuning for Domain-Specific Knowledge: Further research is needed to develop better fine-tuning techniques that can effectively inject domain-specific recommendation knowledge into LLMs, ensuring they can handle complex user-item interactions with greater accuracy.
- Scalable Deployment Strategies: Developing strategies for the efficient deployment of LLMs in large-scale recommendation systems is crucial. Techniques such as distillation, pruning, and the use of efficient transformers can help reduce computational overhead and make LLMs more suitable for real-time applications.
- Ethics and Fairness: Continued focus on ethical considerations, such as reducing biases in LLM outputs and ensuring fairness in recommendations, will be essential. Methods that incorporate fairness constraints directly into the training process could help achieve more equitable outcomes.
- Privacy-First Recommendations: As privacy concerns become increasingly prominent, research into privacy-preserving LLM techniques will be crucial. Approaches like federated learning, where user data remains on-device, could help alleviate privacy concerns while still benefiting from LLM capabilities.
In conclusion, while the integration of LLMs into recommender systems presents several challenges, it also offers substantial opportunities to enhance personalization, explainability, and cross-domain recommendation capabilities. The key lies in addressing the technical and ethical challenges to make these systems more robust, scalable, and user-friendly. By leveraging LLMs' strengths and mitigating their weaknesses, we can usher in a new era of recommendation systems that are not only more effective but also more aligned with user needs and societal values.
References: