
LLM360, A true Open Source LLM
LLM360 introduces true open-source AI with its 7B parameter models, Amber and CrystalCoder, providing full transparency by sharing training datasets, preprocessing code, model configurations, intermediate checkpoints, and evaluation metrics, fostering collaborative and reproducible AI research.


Very recently llm360.ai has released LLM360, one of the very first truly open-source models. Popular open-source models, such as Llama2, and Mistral, are not fully open-source. Only the model's weights are released. But just making the weights public does not solve all the problems. Training an LLM from scratch is not an easy task. It is technically challenging but also expensive. Closed-source models (like OpenAI ChatGPT, Gemini, Claude2, etc) or semi-open-source models like Llama2 and Mistral do not provide much/any information about the dataset used, the preprocessing steps, the model's behavior during training, and the intermediate checkpoints.
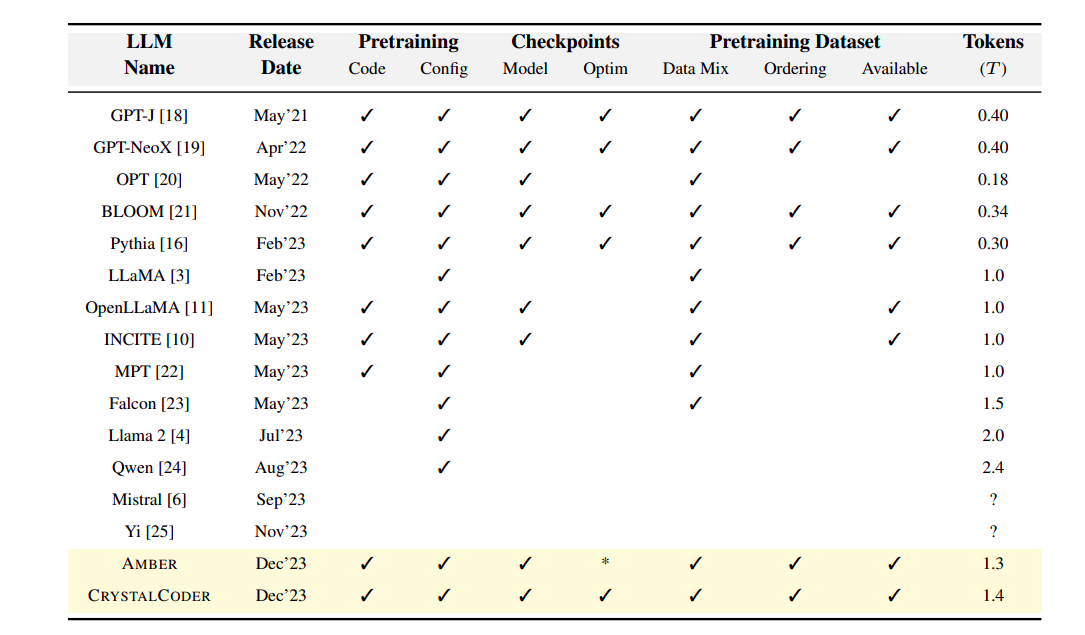
LLM360 by llm360.ai is one of the frameworks that open-sourced everything. They released two foundational models: Amber (A 7B parameter model for generating texts in the English language) and CrystalCoder (Another 7B parameter model to generate code). Not only that, they released a couple of instruction-tuned models like AmberChat and AmberSafe. That's just the beginning, they released all their intermediate model checkpoints, along with the dataset used, preprocessing steps, evaluation frameworks, etc. This blog will try to summarize the paper released by the LLM360 team and also pinpoint the key takeaways from it.

🕵 The need
This question arises naturally on why just releasing the model weights is not enough. The answer is straightforward, pre-training of LLMs is a computationally daunting task. A lot of academic Labs or small research organizations can not afford to conduct such expensive experiments. However, the process of building LLMs is very redundant. So a research organization is not required to invest heavily in building a whole Foundation Model from scratch, just to understand the underlined dataset patterns or the behavior of models on different checkpoints. The novel contribution of LLM360 is that they generously released their whole build journey, such that other researchers can reference it and investigate the part they are interested in and understand the nuanced behaviors of the models w.r.t. the data patterns without putting a large amount of investment.
According to LLM360's released blog post, they are meeting the above-mentioned need by adhering to the following goals:
- Increased Accessibility:
- 0 GPUs: the community can view all important intermediate results as if training just finished.
- 1+ GPUs: intermediate checkpoints can be trained without needing to start from scratch, opening up wider research opportunities.
- Research Advancement, Reproducibility, and Model Understanding:
- The project hopes that it lays the groundwork for future research by offering complete, reproducible resources.
- By replicating studies and verifying results, it fosters a reliable and transparent research environment.
- Environmental Responsibility:
- LLM360 promotes sustainable research by sharing all intermediate results that can be extended upon, thereby reducing unnecessary computation.
🧿 The LLM360 Framework

The LLM360 framework at a high level releases two main foundation models, Amber and Crystal Coder. For each model, it releases:
- Training Dataset and Data Preprocessing Code: Pre-training datasets are the most important part of any pre-trained LLMs. Practitioners need to check the viability of the data and also assess its underlying biases and potential leakages (sometimes benchmark data are already present in the training dataset hence making the benchmark test produce misleading results). Further, it has been seen that training on repeated data for downstream fine-tuning should be avoided since it degrades performance disproportionately [3].
- Model configurations and model checkpoints: LLM360 releases all the model checkpoints (unlike other open-source models, which just released their last or best model checkpoint), along with the hyperparameters, source code for training the model, learning rates, system configurations such as parallelism dimensions, etc are all released.
- Metrics and evaluation: A general LLM pre-training timeline can vary from a few weeks to months. Interestingly, there are a lot of evolution patterns over the training period and it offers some valuable information about the change of behavior in LLMs over time when they are fed more data w.r.t. change in weights. The overall training behaviors are almost agnostic to all LLMs released till now, as they obey to the scaling laws. So, the LLM360 framework released all their training logs including system statistics (e.g., GPU workload), training logs (e.g., loss, gradient norm), evaluation metrics (e.g., perplexity, downstream tasks), etc.
🔥 Amber
Amber is a simple language model trained to generate meaningful completions. We also have AmberChat and AmberSafe which are the fine-tuned (instruction-tuned) version of Amber.
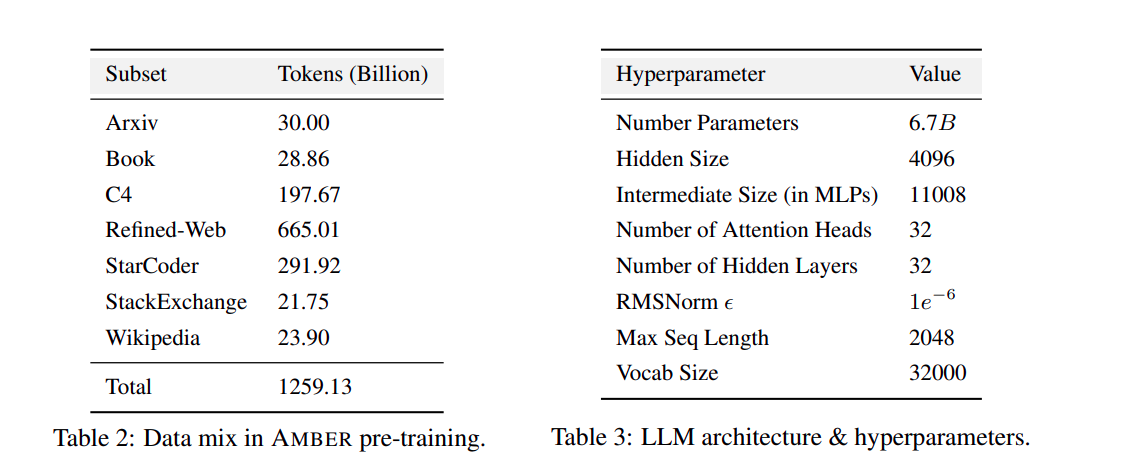
The Dataset
The dataset pre-process step was very similar to OpenLlama, where the data is a mixture of RefinedWeb, StarCoder, and RedPajama-v1, datasets. It also includes the C4 (The dataset in which Googl's T5 model series were trained) dataset. The data comprised 1.26T tokens divided into 360 data chunks.
The Model Architecture and Training
Amber follows the same model architecture as Llama 7B, and it also incorporates Rotary Positional Embeddings (RoPE) at each layer of the network. Amber was trained using the AdamW optimizer with the following HyperParameters:
"β1 = 0.9, β2 = 0.95. The initial learning rate is set to η = 3e −4, following a cosine learning rate schedule that decreases to a final rate of η = 3e −5."
Additionally, it adds a weight decay of 0.1 and uses gradient clipping of 1.0. The model was warmed up over 2K steps. The pre-training batch size was 2,240 (224 GPUs x batch size of 10 each). The model was trained on an in-house GPU cluster which consists of 56 DGX A100 nodes (each equipped with 4 x 80GB A100 GPUs, which equals 17,920GB) where each GPU is connected with 4 NVLinks. Mixed precision was used with BF16 for activations and gradients and FP-32 for model weights while pre-training. Lit-GPT by PyTorch Lightning was used for writing all the training scripts.
Fine-Tuning Amber
Amber also released their fine-tuned version named AmberChat and AmberSafe. Both were trained using instruct training data as used by WizardLM. FastChat was used to fine-tune the models for 3 epochs on 8 A100 (80 GB) distributed by FSDP, with a learning rate of 2 x 10e-5. You can find more details on the HuggingFace Model config. AmberChat was a supervised fine-tuned model. AmberSafe on the other hand is an aligned version of the model, where it is fine-tuned with Direct Parameter Optimization (DPO). AmberSafe was trained on ShareGPT 90K and further optimized on the SafeRLHF dataset.
Evaluation results of Amber
Four benchmark datasets in the OpenLLM leaderboard were used. Those are ARC (AI21 Reasoning Challenge), HellaSwag, MMLU, and TruthfulQA. The evaluation was done on all 360 checkpoints. The figure below shows that evaluation scores show a monotonically increasing property for ARC, MMLU, and HellaSwag. Whereas interestingly the TruthfulQA score seems to decrease as the training proceeds.
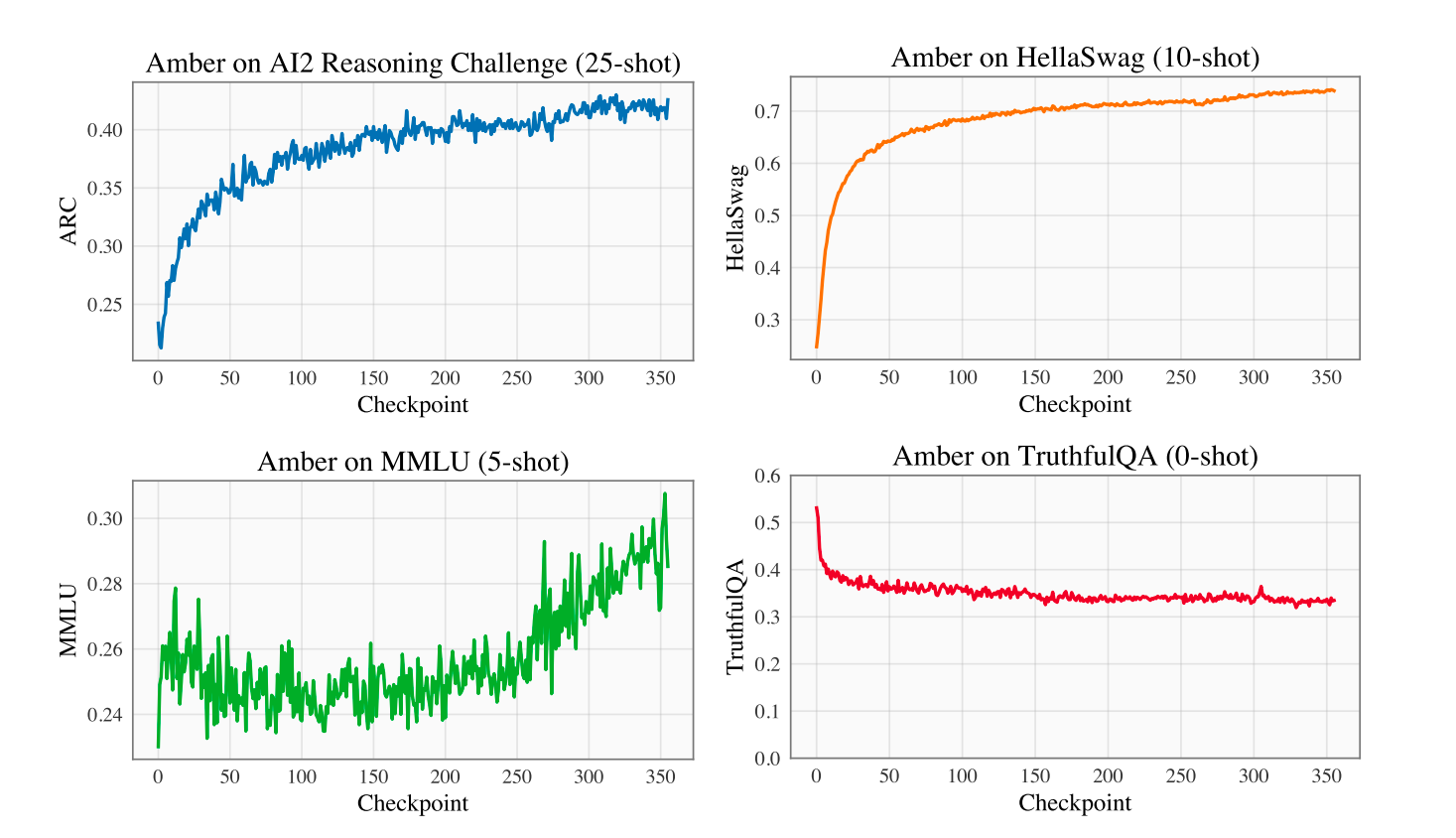
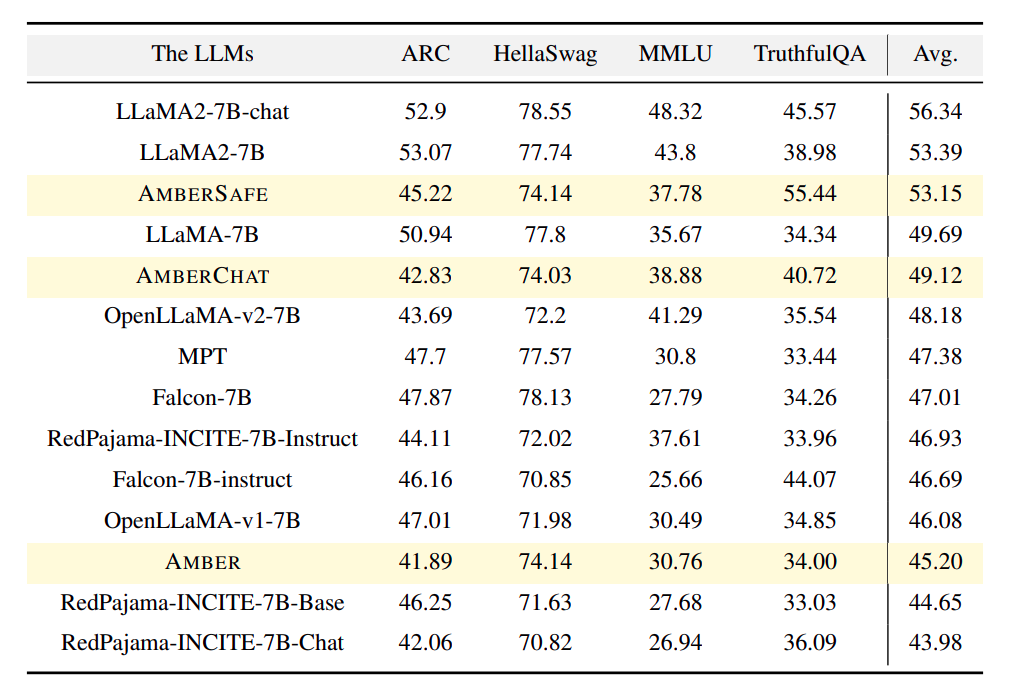
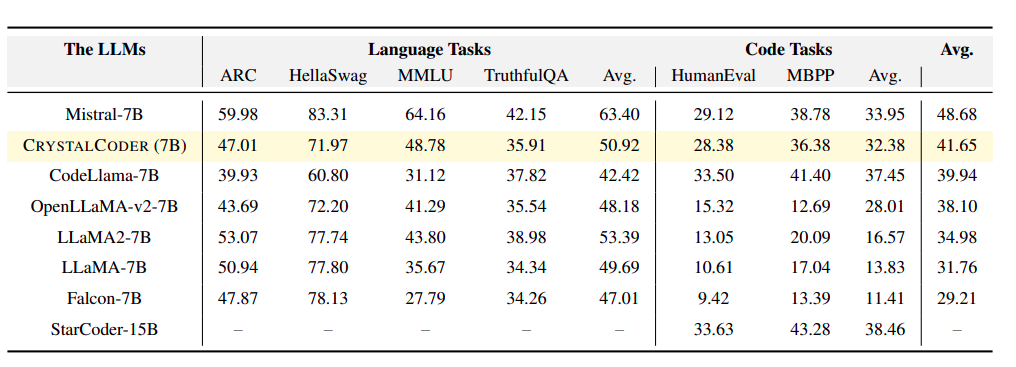
Figure 4, shows the comparison of a few popular LLMs with Amber.
🔮 CrystalCoder
CrystalCoder is a code generation pre-trained language model. It has been trained with a mixture of code and natural language data.
The Dataset
The pre-training dataset in CrystalCoder is a blend of SlimPajama and The Stack dataset. A total of around 1382B tokens were used for training in total. The SlimPajama dataset constituted 355 Billion tokens and StarCoder Data (The Stack) constituted approximately 1027 Billion tokens.
Model Architecture and Training
CrystalCoder uses a model architecture that closely resembles Llama 7B. However, there were certain changes introduced to this model like:
- Incorporates Maximal update parametrization.
- The application of RoPE (Rotary Positional Embeddings) was restricted to the first 25% of hidden dimensions.
- A sequence length of 2048 with an embedding dimension of 23032 was used.
- Simple LayerNorm was used instead of RMSNorm (was done for efficient computing)
The model was trained on Cerebras Condor Galaxy 1 (CG-1), a 4 exaFLOPS, 54 million core, 64-node cloud AI supercomputer. The model was trained sequentially in three stages. The first stage was trained using half of the SlimPajama dataset (which mainly consisted of natural language data) and the second stage, the remaining half of the SlimPajama data was utilized along with two epochs of The Stack Dataset. The third stage was trained on Python and web-related data (HTML, JavaScript, CSS) subsets from the StarCoder dataset and also with an additional sample of SlimPajama data. The best part!!!, All the data pre-processing and mixing scripts are open-sourced.
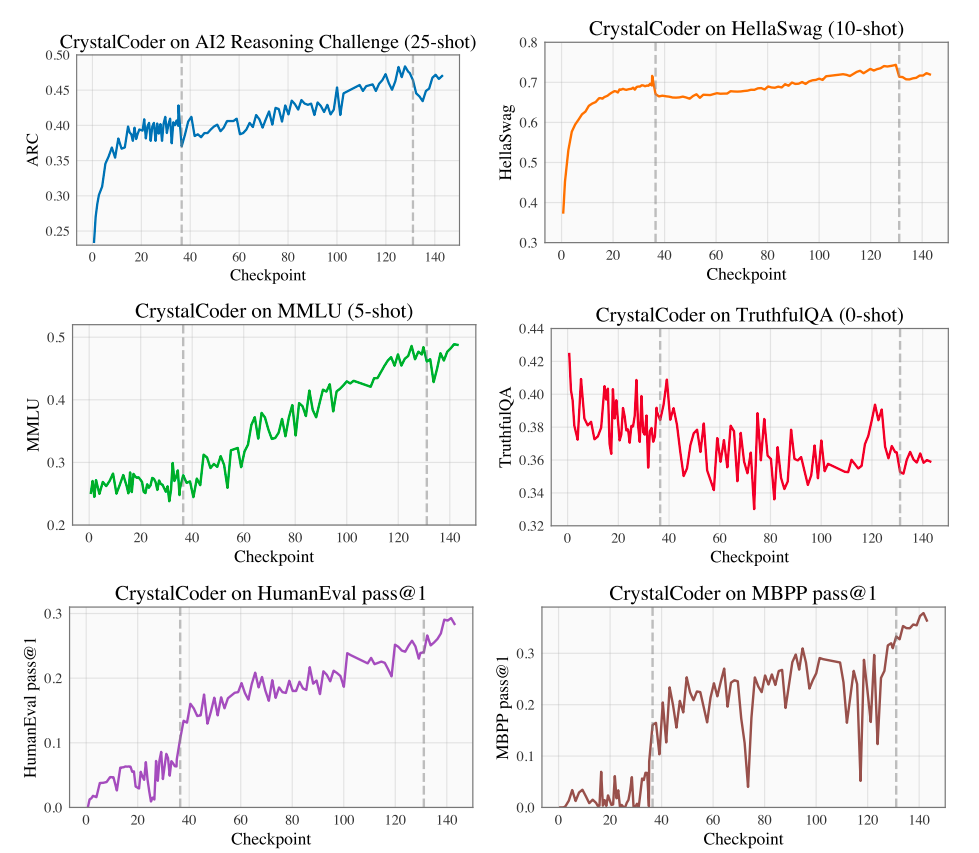
We can see that other than TruthfulQA, all of the other evaluation benchmarks have shown almost (sometimes noisy in the case of MBPP) monotonic behavior.
Evaluation Results of CrystalCoder
The model was benchmarked on four standard benchmark datasets for natural language (ARC, HellaSwag, MMLU, TruthfulAQ), similar to Amber, and datasets including HumanEval pass@1, MBPP pass@1 code benchmarks were included to evaluate Amber on code generation.
💾 The Memorization Problem and Analysis 360
A lot of recent works show that LLMs tend to memorize a significant part of the training data, and those data can be extracted with appropriate prompting. And this memorization property of LLMs raises a huge concern when fine-tuned using private data. Not only this LLMs possess a lot of interesting behavior in their generation capabilities at different checkpoints. The paper in Pythia shows an insightful study on different intermediate checkpoints of the model and how those properties changed when scaled both in terms of data and number of parameters.
LLM360 teams release a package called Analysis360, which analyses model behavior on different examples. One very good example was quantifying model memorization. They implemented the memorization-score , originally from this paper, where the model memorization score indicates the accuracy of tokens in the continuation of length l with a prompt length of k where the prompt is special. Here are some amazing results
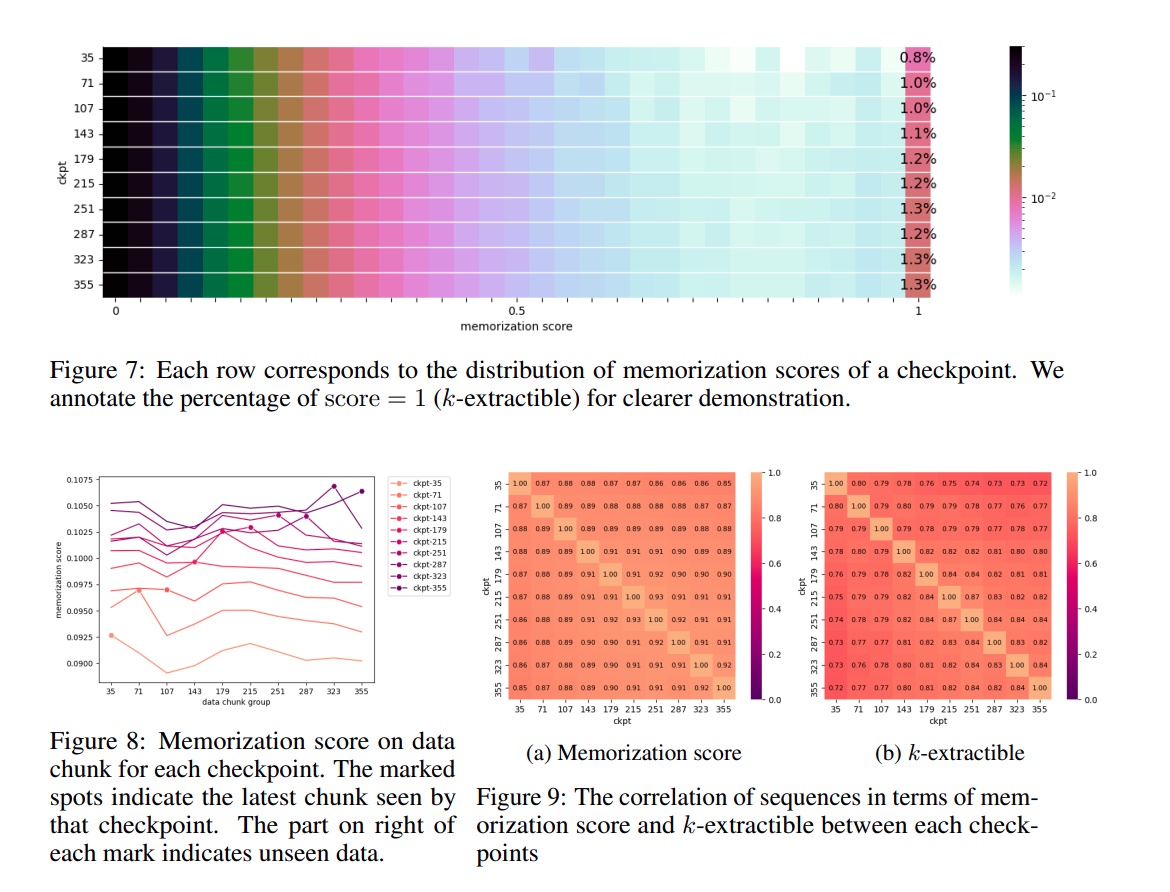
Where "K-extractible" (from the above figure) refers to sequences within a language model (in this case, LLMs) that can be accurately reproduced or extracted given a specific prompt or context of a certain length, denoted as "k.". So here are the key findings:
- More than 1% of sequences were found to be 32-extractible from a checkpoint called AMBER.
- AMBER improves in its memorization abilities as training progresses.
- The model can memorize more tokens than the defined threshold (32) suggests, consistent with previous research.
- AMBER checkpoints tend to memorize the latest seen data more than previous data.
- While the memorization score initially drops slightly with additional training on each data chunk, it gradually increases afterward.
- In Figure 9 (of the above Figure 7) we can see that, There is a strong correlation between memorization scores of different checkpoints.
Coming versions of Analysis360 promise to support more such findings and visualizations. You can check out their Analysis360 GitHub repository here.
📙 Key Takeaways
Now this is my favourite part. One very important aspect of doing experiments with LLMs are the problems faced and the key takeaways. A lot of model reports or papers do not share these problems fully. Here are all the key takeaways from the paper and their learnings. This section is divided into three sections. First, we try to understand the problems they faced while training LLMs, followed by "Take-Home" messages, and finally the main key learnings.
Problems Encountered:
- NaN Losses in Training: Periodic occurrences of NaN losses during pre-training, potentially influenced by random states, training precision, or data quality issues.
- Missing Optimizer States: Inadequate saving of optimizer states during pre-training led to instability, affecting model training across checkpoints.
- Checkpoint Precision Discrepancies: Initial checkpoint precision discrepancies (BF16 instead of FP32) might have potentially contributed to accuracy discrepancies.
- "Misbehaved" Data Chunks: Specific data chunks were problematic, causing NaN losses persistently regardless of when they were trained, suggesting potential data quality issues.
Take-home Messages:
- Handling NaN Losses: Amber's pre-training encountered NaN losses periodically, possibly due to random states, training precision, or data quality. Attempts to address this involved switching random seeds or skipping problematic data chunks, but some chunks remained troublesome regardless of training order.
- Optimizing Parallelism Strategies: Experimentation with parallelism strategies—data, tensor-model, and pipeline—showed superior system throughput compared to other methods like FSDP, especially in distributed clusters with limited intra-node bandwidth.
- Data Quality & Mixing Ratios: The significance of data cleaning, data quality filtering, and defining pre-training data categories (e.g., CommonCrawl, Books, StarCoder) was highlighted. Despite closely aligning hyperparameters with LLaMA, AMBER's performance lagged, partly due to insufficient details about LLaMA's exact pre-training dataset.
- Importance of Dataset Composition: Detailed crafting of datasets, as exemplified by CrystalCoder, blending English and coding data, yielded competitive performance on Open LLM Leaderboard and Code Evaluation benchmarks.
- Community Collaboration for Optimization: The entire LLM open-source community actively explores optimal strategies for data cleaning, quality filtering, and dataset composition, recognizing these as pivotal elements for successful LLM pre-training.
Main Learnings:
- Identifying & Addressing NaN Losses: Strategies involving different random seeds or chunk skipping were attempted to mitigate NaN losses. Understanding problematic data chunks remains a challenge.
- Optimal Parallelism Strategies: Leveraging hybrid parallelism strategies, including data, tensor model, and pipeline, showcased improved throughput compared to other methods in certain distributed setups.
- Data Quality & Pre-training Dataset Definition: Emphasis on meticulous data cleaning, quality filtering, and precisely defining pre-training data categories is critical for model performance.
- Impact of Dataset Composition: Careful composition and crafting of datasets, combining different data types, can significantly influence model performance.
- Continuous Community Collaboration: Collaboration within the LLM open-source community is pivotal in evolving effective strategies for data handling and model training, acknowledging the evolving nature of these challenges.
🍀 Conclusion
LLM360 framework and their work show us what true open-source research and open-source AI should look like. In this paper, we got extensive information on how these foundation models are trained and made, their data preprocessing and considerations, and the different frameworks they were trained on. Additionally, we learned a lot of awesome insights into the model's checkpoint-specific behaviors and memorization problems in a quantified manner. For papers like LLM360 and Pythia lot of researchers do not have to train their foundation models just to understand the underlined behaviour and patterns of data and model. Some potent forms of research that can carry forward from here would be:
- to conduct experimental studies of fine-tuning of LLMs at different stages of LLMs (i.e. from different checkpoints) and see if some domain-specific behavior at one intermediate checkpoint outperforms another.
- conducting experiments to see how behavior changes when a certain percentage of some genre of the dataset is changed (like seeing how the LLM behaves by decreasing the ratio of the Wikipedia dataset and in some increasing the same).
Projects like LLM360, Pythia, and OpenLlama show the true potential of Open Science and research. More and more model implementations should be fully open-sourced including their training logs and dataset preprocess techniques, so that the process can be as transparent as possible and there could be fewer redundant research expenditures.
🌀 References
- The LLM360 blog
- Scaling Laws and interoperability of learning from repeated data.
- OpenLLaMA, a permissively licensed open-source reproduction of Meta AI’s LLaMA 7B trained on the RedPajama dataset
- StarCoder: May the source be with you.
- Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling