LLM Reliability: Why Evaluation Matters & How to Master It
Prem Studio redefines AI evaluation with agentic rubrics, transparent, scalable, and domain-specific checks that ensure LLMs are production-ready.

Key takeaway: Reliable AI starts with rigorous evaluation. Without robust, interpretable checks, deploying an LLM in production is like flying blind.
Why Model Evaluation Matters - Especially for Enterprises
When language models go from labs to real-world use, the stakes rise quickly. They help customer support agents, summarize financial reports, and extract structured data. An inaccurate, biased, or unpredictable model can damage customer trust, invite compliance risks, or disrupt internal workflows.
In enterprises, LLM outputs must be interpretable, safe, and aligned with business logic. Evaluation isn’t just about performance metrics it’s about risk mitigation, model accountability, and production readiness.
This need for rigorous AI model evaluation has only intensified as we enter 2025. As organizations use more AI systems, stakeholders and regulators want to see clear proof. They want to know that a model is reliable before they use it in production. In other words, LLM reliability isn’t a nice-to-have – it’s become a baseline requirement for business and compliance.
But evaluating LLMs is uniquely hard. Traditional metrics like BLEU or ROUGE barely scratch the surface. Human evaluations are expensive and slow. And LLM-as-Judge setups often lack transparency. Recent research shows that these evaluators can introduce format, knowledge, and positional biases, making their scores unreliable indicators of true model quality (Liu et al., 2024)
Most frustrating of all? Hard to tell why a model failed - or what to do about it.
Prem Studio was built to solve exactly that. At Prem, we’ve designed an evaluation system that moves beyond surface-level scoring. Our approach combines the scalability of LLM-as-Judge with the structure of Prem Agentic evaluation. The result is a flexible, explainable pipeline that works across domains and brings clarity to even the most subjective tasks.
Agentic Evaluation: Simple Setup, Powerful Results
Agentic Evaluation shifts control to domain experts: Instead of relying on generic metrics, you define precise quality standards for AI outputs using natural language rules.
Prem’s Agentic Evaluation flow is designed for teams who want to define their own quality criteria, but don’t have the infrastructure to operationalize it at scale. Essentially, it’s an AI testing framework tailored to your use case, one that encodes human-like expectations as automated checks.
Step 1: Define a Metric
A metric is a definition of what good output looks like. In traditional ML, metrics are often numbers like accuracy or precision. For LLMs, those don’t always work.Take a model that extracts generic ingredients from recipes. You don’t just want the right words. You want them in the right format. No repetition. No extra text.
Just describe what you want to evaluate - in plain language.
For example: “Ensure the generic ingredients match the reference output, are correct, not repeated, and follow a strict Python list format.”
Prem’s internal intelligence then turns that into a set of rules called rubrics that guide evaluation.
Each metric contains:
- Positive rules (e.g., "Output must be a valid Python list")
- Negative rules (e.g., "No duplicate ingredients allowed")
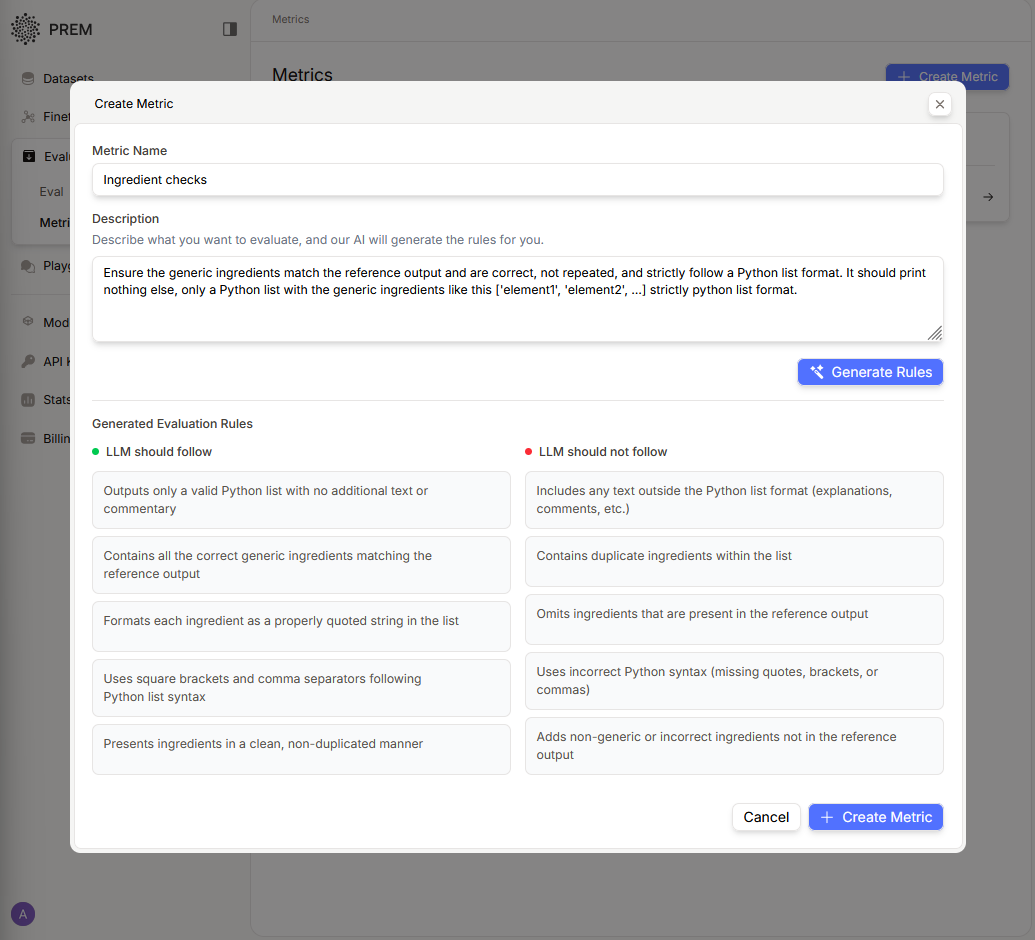
Metrics can be edited anytime so your evaluation logic evolves with your product.
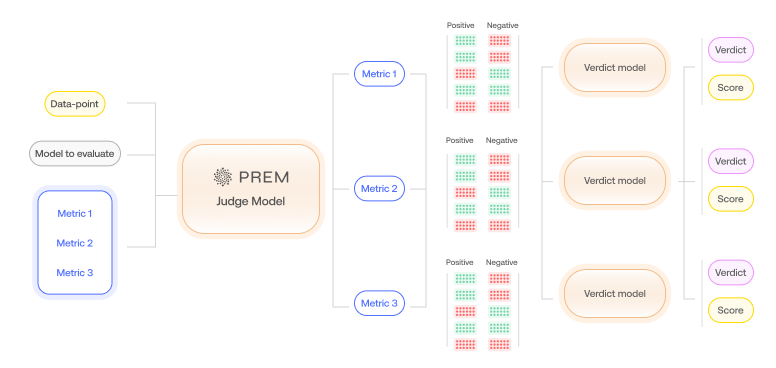
Step 2: Evaluation via Prem Judge
Once your custom metrics (rubrics) are set, you can run evaluations on any dataset using Prem’s built-in judge model. Under the hood, Prem checks each model output against every rule and assigns scores per rule. Each response gets a clear pass/fail verdict for each criterion, along with an explanation. This yields not just an overall score but a transparent report of what went wrong and why for any failures. In other words, our system doesn’t just tell you that a model failed a test it pinpoints how it failed and which rule was violated.
Case Study: Evaluating Ingredient Extraction Models
Let’s walk through a real example.
Suppose you’re building a model to extract generic ingredients from a list of recipe instructions. You care about:
- Only including relevant ingredients
- No repetition
- Outputting in a valid Python list format
We define a custom metric, and evaluate four models including two fine-tuned Qwen models and two GPT-4 variants.
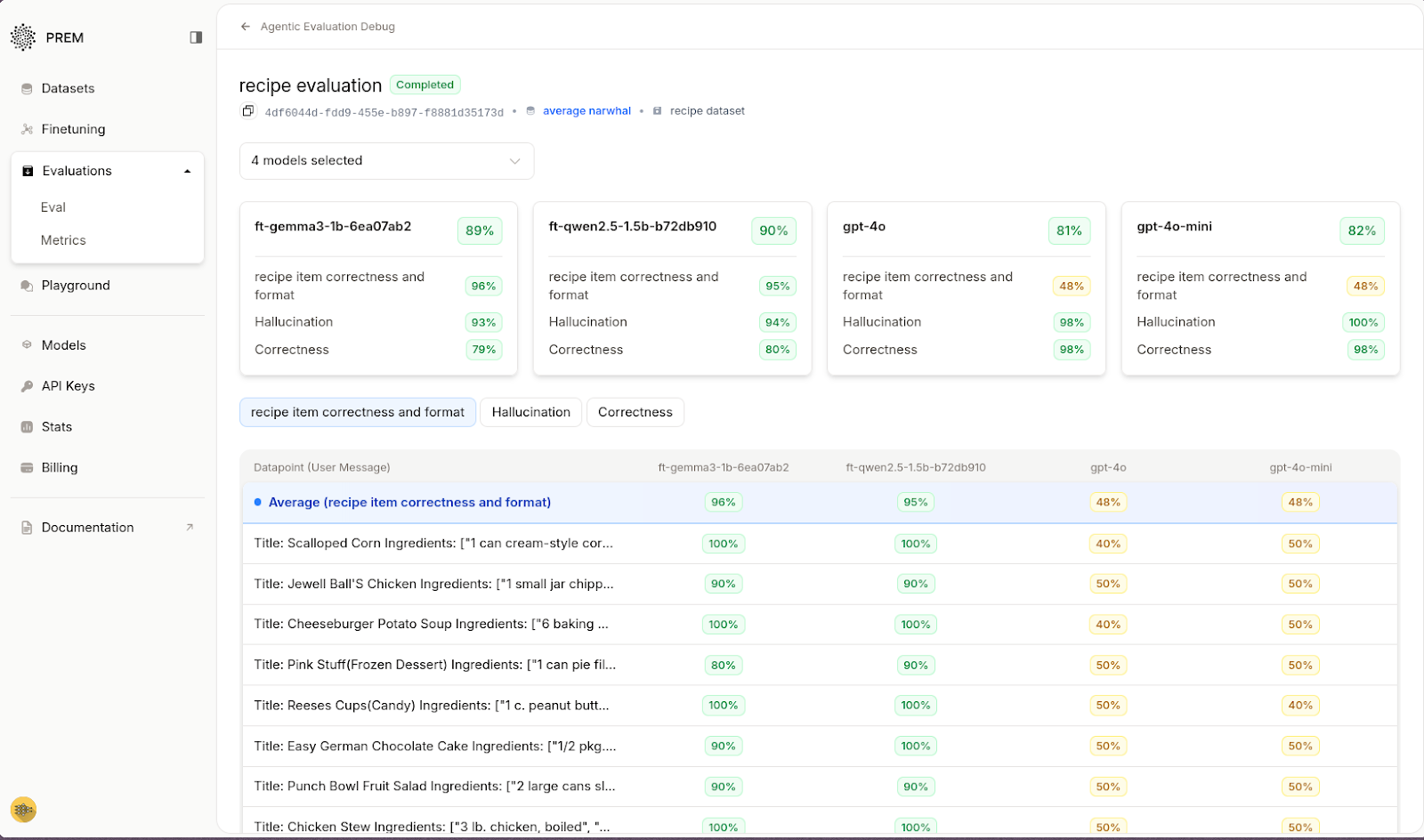
While GPT-4o scored high on general correctness, it failed the structured format checks scoring just 37% on the “Ingredient Checks” metric. The fine-tuned Qwen models performed more reliably across both correctness and structure.
Click into a datapoint:
You’ll see:
- The original prompt
- The model output
- Rule-by-rule grading with detailed verdicts
For example, one fine-tuned Qwen model’s response scored a perfect 100% on our custom metric. It listed all and only the relevant ingredients in proper format.
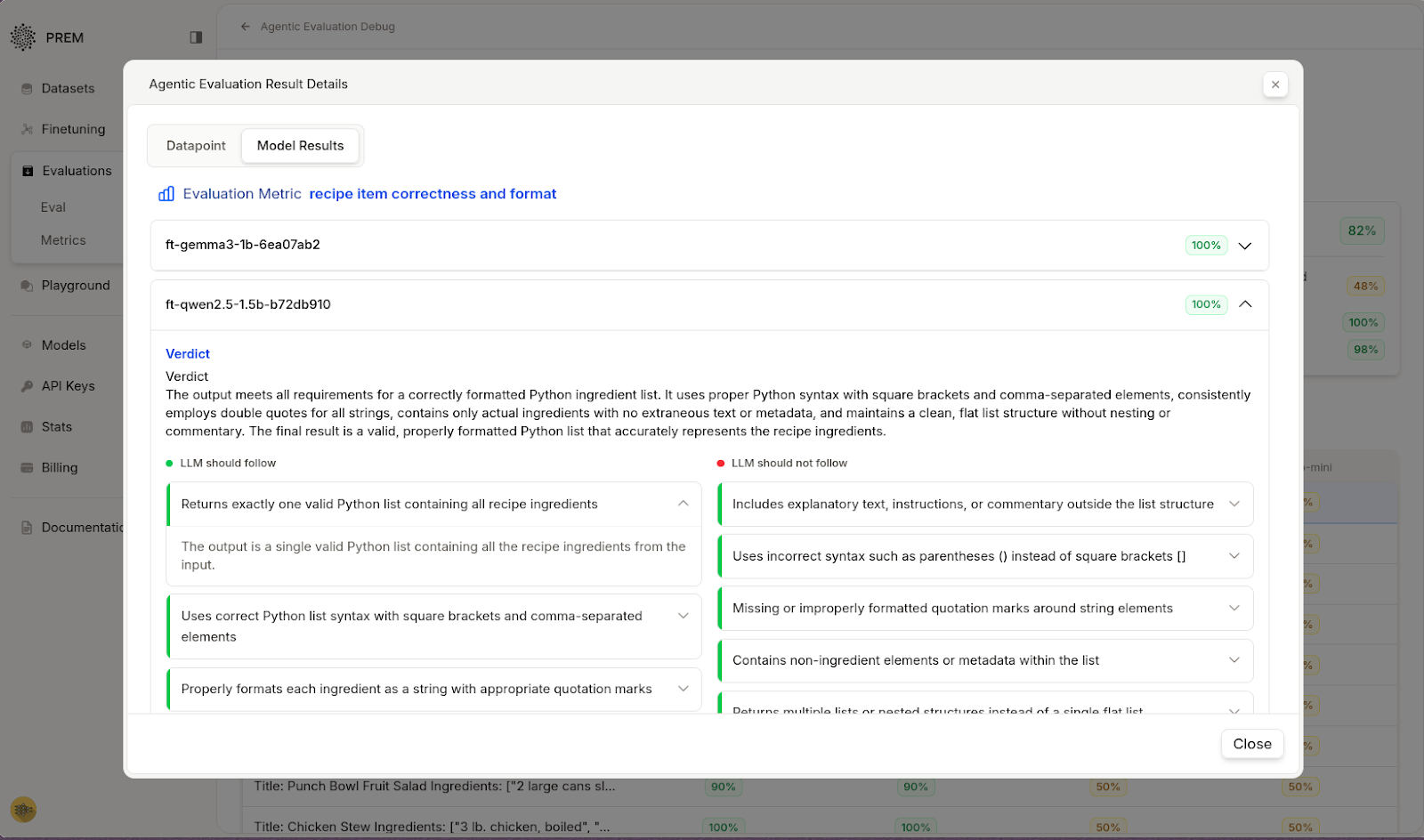
Another model’s output (GPT-4’s) included the right ingredients but formatted them as a bullet-point list instead of a Python array, violating the format rule and earning only 50%
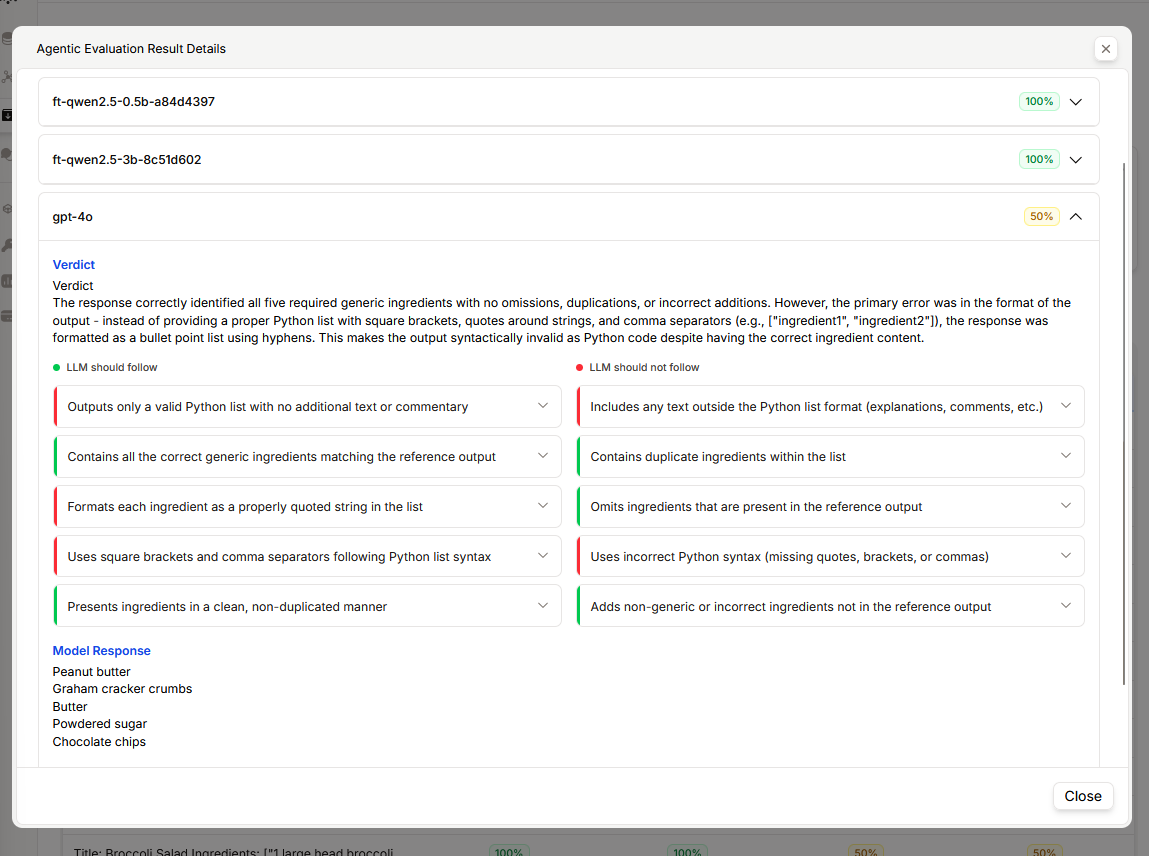
This side-by-side comparison illustrates the power of rubrics: you don’t just learn that one model performed worse than another; you learn exactly how it fell short, and therefore what to fix or where a targeted improvement could be made.
This case study highlights why tailored evaluation is so important. A generic metric or superficial test might have missed GPT-4’s formatting error, since the ingredients were technically correct. By using a domain-specific rubric essentially a specialized AI evaluation metric we uncovered a critical reliability issue. In practice, this kind of focused model performance evaluation ensures that models meet all requirements, not just generic accuracy. It’s a glimpse of an AI testing framework in action: one that catches details crucial for real-world deployment (like output format) which traditional evaluations often overlook.
Why Prem Agentic Evaluation Changes the Game
Prem’s agentic evaluation uses predefined natural language rules (the rubrics) to assess LLM outputs against specific quality criteria. Unlike a simple numerical score, it provides transparent, actionable feedback by breaking down performance into measurable dimensions. In effect, it’s operationalizing what a human evaluator might do, but in a consistent and scalable way.
Traditional LLM-as-Judge setups or even many automated AI testing frameworks tend to deliver a single score or pass/fail outcome with little explanation – a black box where failures remain mysteries. Was the answer factually wrong? Too long? Poorly formatted? You’re left guessing. Prem replaces that guesswork with actionable clarity. Our approach turns evaluation into a checklist that’s easy to understand:
- Did outputs meet all critical requirements?
- Violate any deal-breaker rules?
- Can we trace failures to specific causes?
This granular visibility enables what really matters: actionable improvement. Teams can instantly adapt or refine the rules when new requirements arise whether it’s adding a compliance check, enforcing a specific brand tone, or handling domain-specific quirks. The evaluation isn’t a static score; it’s a dialogue with the model’s output, telling you exactly where it aligns with expectations and where it deviates.
From Evaluation to Evolution: The Continuous Improvement Flywheel
Prem’s agentic evaluation provides the diagnostic clarity needed for true iteration. We turn evaluation from a one-off test into a continuous improvement cycle. Here’s how the flywheel spins:
- Evaluate with precision: Every evaluation run yields a detailed breakdown. Our evaluator’s scoring identifies exact failure points. The score breakdown and verdict reasoning help pinpoint root causes for errors.
- Remediate strategically: Using the insights from evaluation, you can generate targeted fixes. For instance, adding more training examples for weak areas or adjusting your prompt/rules to address recurring issues. Sometimes this involves creating synthetic data specifically to bolster performance on the failure cases.
- Refine and validate: Using the newly generated synthetic data, we fine-tune the model again, then re-evaluate its performance to confirm measurable improvements
The result? Teams move from reactive fixes to predictable quality gains - turning evaluation from a cost center into your competitive advantage.
In practice, this kind of continuous evaluation loop is increasingly viewed as an MLOps best practice. With generative models evolving rapidly, integrating an ongoing test-and-tune cycle has become essential to maintain LLM reliability over time. Rather than hoping a model stays good, you are constantly verifying and improving it so you’re not flying blind at any stage of deployment.
Conclusion: Evaluation is How You Build Trustworthy AI
LLM evaluations aren’t just academic. They’re foundational to delivering AI that works in the real world.
In fact, forward-thinking enterprises now treat robust AI model evaluation as a core part of their AI strategy – a continuous process that underpins trust and accountability for any model deployed.
With Prem Studio, evaluation is no longer a bottleneck; it’s a strategic advantage. Our platform gives teams the tools to define, test, and refine what “good” looks like for their AI models all before those models hit production.
Whether you’re building AI agents for customer service, automating document workflows, or tackling any domain-specific task, Prem’s evaluation system ensures you’re not flying blind. You’re steering with clarity, confidence, and control.
Start evaluating your models today: Prem Studio
Learn advanced fine-tuning techniques: Fine-tuning Documentation
