LLM Routing: AI Costs Optimisation Without Sacrificing Quality
LLM routing revolutionizes AI deployment by dynamically assigning tasks to the best models, reducing costs by up to 75% while maintaining high-quality outputs. Explore its role in customer support, content creation, and developer tools, and learn how it optimizes efficiency across industries.


The Cost-Quality Dilemma in Large Language Models
The rapid evolution of Large Language Models (LLMs) has revolutionized natural language processing (NLP), enabling high-quality performance across tasks such as question answering, summarization, and code generation. However, this progress comes with a significant trade-off between cost and performance. Advanced LLMs, such as GPT-4 and Claude, offer exceptional response quality but require substantial computational resources, making them expensive to deploy. Conversely, smaller models like Llama-2 or Mixtral provide cost-effective alternatives but often fail to match the performance of their larger counterparts.
This dynamic has created a pressing need for strategies that optimize resource utilization while maintaining response quality. Organizations face increasing challenges in deploying AI systems at scale due to the growing diversity of models and their associated costs. Furthermore, the rising number of LLMs, each with unique strengths and weaknesses, complicates the decision-making process for model selection.
One promising solution to this problem is LLM routing. By intelligently assigning tasks to the most appropriate model based on query complexity, LLM routing offers a pathway to significant cost savings without compromising quality. This approach ensures that simpler tasks are handled by cost-efficient models, while more complex queries are routed to high-performance models.
The remainder of this article explores the technical and practical aspects of LLM routing, evaluating its effectiveness in achieving an optimal balance between cost and performance. Through an in-depth look at routing algorithms, benchmarks, and real-world applications, we aim to answer the question: Is LLM routing truly worth it for optimized usage with lower costs?
LLM Routing: A Tailored Approach for Efficiency
LLM routing is a strategy designed to address the inherent trade-offs in deploying large language models by dynamically selecting the most appropriate model for a given query. This approach leverages the unique capabilities of different models to optimize costs while ensuring high-quality responses.
How LLM Routing Works
At its core, LLM routing involves a routing function that acts as an intelligent classifier. Given a query, the routing system evaluates its complexity and assigns it to one of two types of models:
- Strong Models: High-performance, resource-intensive models like GPT-4 or Claude, reserved for complex or critical queries.
- Weak Models: Cost-efficient models like Llama-2 or Mixtral, suitable for simpler queries.
This decision-making process is informed by metrics such as query intent, domain, and complexity, ensuring that each query is matched with the model best equipped to handle it effectively. For example, a customer support chatbot might route straightforward questions like “What are your operating hours?” to a smaller model, while directing nuanced questions requiring detailed understanding to a larger model.
Key Components of an LLM Router
- Router Algorithms:
- Deterministic and probabilistic algorithms analyze query attributes to predict the model that will deliver the desired performance at the lowest cost.
- Advanced techniques like hybrid routing combine multiple strategies for greater flexibility and adaptability.
- Dynamic Thresholds:
- Routers often use thresholds to define quality and cost boundaries. By adjusting these thresholds, systems can seamlessly prioritize cost or quality based on operational requirements.
- Evaluation Metrics:
- Metrics such as response quality (e.g., BART score) and cost per token help measure the effectiveness of routing decisions. These metrics are continuously monitored and fine-tuned for optimal performance.
Why LLM Routing Matters
LLM routing is not just a cost-saving mechanism but also a means to maximize the utility of an organization’s AI infrastructure. By leveraging a router, businesses can:
- Reduce reliance on expensive models for routine tasks.
- Enhance user experiences by maintaining response quality across diverse use cases.
- Dynamically adapt to evolving workloads and model capabilities.
With its ability to balance quality and cost, LLM routing has emerged as a critical tool in the efficient deployment of AI systems.
Technical Foundations of LLM Routing
The success of LLM routing lies in its ability to dynamically evaluate queries and allocate them to the most cost-effective model without compromising quality. This process is underpinned by sophisticated routing algorithms, tailored metrics, and cutting-edge implementation frameworks.
Routing Models and Algorithms
Routing algorithms are the backbone of LLM routing, enabling efficient query assignment. Several approaches have been developed to address different operational requirements:
- Deterministic Routing:
- Routes queries based on predefined rules or thresholds, such as query length or domain keywords.
- While simple, this method often lacks the flexibility to adapt to varying query complexities.
- Probabilistic Routing:
- Utilizes statistical models to predict the likelihood that a specific model will meet quality targets for a given query.
- Incorporates uncertainty handling, especially in non-deterministic LLM outputs, to improve decision-making.
- Hybrid Routing:
- Combines deterministic and probabilistic methods to create a flexible and adaptive system.
- Can dynamically adjust routing thresholds to trade off quality and cost, making it ideal for scenarios with fluctuating workloads.
- Cascading Systems:
- Queries are passed sequentially through a hierarchy of models, escalating only when a model cannot meet predefined confidence thresholds.
- While effective, cascading systems may introduce latency due to sequential evaluations.
Evaluation Metrics
The efficiency of a routing system is measured by its ability to balance cost and quality. Commonly used metrics include:
- Cost Efficiency:
- Percentage of queries routed to smaller, cost-effective models.
- Reduction in average cost per query.
- Response Quality:
- Metrics like BART score or GPT-ranking evaluate the correctness and fluency of model responses.
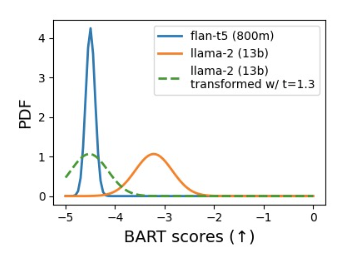
As shown in Figure the quality gap between FLAN-t5 and Llama-2 demonstrates the challenges and opportunities for efficient routing
- Performance Gap Recovered (PGR):
- Measures how much of the performance difference between weak and strong models is recovered by the routing system.
Implementation Frameworks
Practical deployment of LLM routing requires robust frameworks and tools. Key examples include:
- RouteLLM Framework:
- RouterBench:
- A benchmark suite for evaluating routing systems across diverse tasks and datasets.
- Includes metrics for both cost and performance, enabling a holistic assessment of routing strategies.
- Data Augmentation Techniques:
- Enrich training datasets with labeled examples to improve router performance on out-of-domain queries.
- Leverages golden-label datasets like MMLU and GPT-4 judged responses for enhanced training.
Key Insights
LLM routing systems are designed to minimize costs while maintaining high response quality. By leveraging advanced algorithms and metrics, they enable businesses to adapt dynamically to operational demands.
Performance Benchmarks: Evaluating LLM Routing Systems
Performance benchmarks are essential for assessing the efficiency and effectiveness of LLM routing systems. They provide quantitative insights into how well these systems balance cost reduction and quality retention across diverse scenarios.

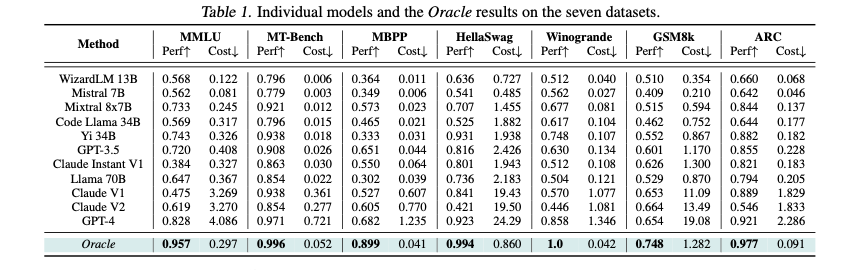
Table 1 illustrates the performance and cost metrics across various benchmarks
Overview of Benchmarking Frameworks
- ROUTERBENCH:
- A comprehensive evaluation framework specifically designed for LLM routing systems.
- Includes tasks spanning commonsense reasoning, mathematics, knowledge retrieval, and coding.
- Provides pre-generated LLM responses and quality metrics, enabling cost-efficient evaluations without requiring live inference.
- MT Bench:
- Focuses on open-ended conversational tasks, using GPT-4 as a judge for response quality.
- Evaluates routing decisions based on performance metrics like Call-Performance Threshold (CPT) and Average Performance Gap Recovered (APGR).
- Hybrid LLM Evaluation:
- Examines hybrid routing setups, where queries are dynamically routed between smaller edge models and larger cloud-based models.
- Highlights scenarios where small models achieve comparable quality for a subset of queries.
Key Metrics for Evaluation
Benchmarks typically measure routing performance using the following metrics:
- Cost Efficiency:
- Percentage reduction in high-cost model usage compared to baseline systems.
- For example, hybrid systems demonstrate up to 40% fewer calls to expensive models like GPT-4 with negligible quality loss.
- Quality Metrics:
- BART Score: A neural-based metric for evaluating response quality across diverse tasks.
- GPT-Ranking: Uses GPT-4 to assess and rank responses, correlating well with human judgments.
- Call-Performance Threshold (CPT):
- The minimum percentage of strong model calls required to achieve a desired quality level, e.g., 90% of GPT-4’s performance.
- Performance Gap Recovered (PGR):
- Quantifies how much of the quality difference between weak and strong models is recovered by the routing system.
Comparative Results from Benchmarks
- ROUTERBENCH Outcomes:
- Hybrid routing systems consistently outperform random baselines, reducing costs by up to 75% while maintaining 90% of GPT-4’s quality.
- Matrix Factorization routers demonstrated superior adaptability, excelling in low-data regimes.
- MT Bench Insights:
- Similarity-weighted routers achieved a 22% improvement in APGR over random routing, demonstrating their capability to efficiently handle varied query complexities.
- Cost-Quality Trade-Offs:
- Hybrid systems dynamically adjust thresholds to optimize cost-quality balance, achieving 22% fewer calls to high-cost models with only a 1% quality drop.
Practical Implications
Performance benchmarks highlight the transformative potential of LLM routing:
- Businesses can achieve significant cost savings without degrading user experience.
- Systems like ROUTERBENCH ensure that routing strategies are robust across diverse datasets and real-world tasks.
Unleashing the Benefits of LLM Routing
LLM routing is more than a cost-saving mechanism; it is a transformative approach to AI deployment, offering scalability, adaptability, and efficiency. By dynamically assigning queries to the most suitable models, routing systems unlock the full potential of LLMs, enabling businesses to balance quality and cost effectively.
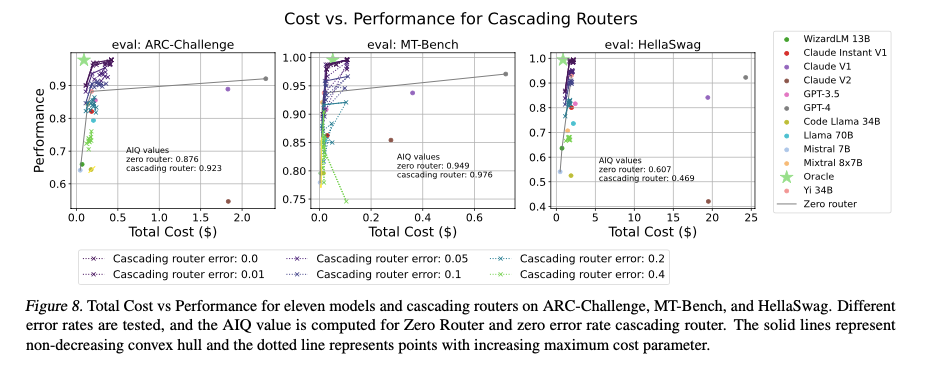
This Figure demonstrates how cascading routers adaptively allocate queries to balance cost and performance.
1. Cost Reduction
- Minimized Reliance on High-Cost Models:
- LLM routing ensures that simpler queries are handled by smaller, cost-effective models, significantly reducing the number of calls to high-performance models like GPT-4.
- Studies demonstrate up to 75% cost savings while maintaining 90% of the larger model's quality.
- Efficient Resource Allocation:
- Organizations can optimize computational resources by directing tasks to models based on complexity, ensuring cost-efficient operations without quality compromise.
2. Scalability and Adaptability
- Dynamic Thresholds for Diverse Workloads:
- Routing systems dynamically adjust quality thresholds based on operational needs, making them suitable for fluctuating workloads.
- This adaptability is critical in applications like customer support, where query complexity varies widely.
- Future-Proofing AI Deployments:
- As new models emerge, routing systems can integrate them seamlessly, ensuring that organizations remain at the cutting edge of AI technology.
3. Enhanced User Experience
- Maintained Response Quality:
- By routing complex queries to high-performance models, LLM routing ensures high-quality responses where they matter most.
- Smaller models efficiently handle routine tasks, delivering fast responses without burdening system resources.
- Consistency Across Use Cases:
- Routing systems balance performance across diverse tasks, from conversational AI to document summarization, ensuring a uniform user experience.
4. Data Privacy and Customization
- Edge-Centric Routing:
- Queries requiring sensitive data processing can be routed to locally hosted small models, enhancing data privacy.
- Tailored Query Handling:
- Custom routers can be configured to prioritize specific quality benchmarks or response characteristics, offering businesses granular control over their AI systems.
5. Real-World Applications
- Customer Support Systems:
- Automates triage by routing straightforward inquiries to smaller models, reserving advanced models for complex or high-priority queries.
- Content Creation:
- Streamlines the generation of creative content, with smaller models handling repetitive tasks while larger models provide nuanced responses.
- Code Assistance:
- In developer tools, routing systems dynamically select models for debugging or code generation based on task complexity.
The benefits of LLM routing extend beyond cost efficiency, offering scalable, adaptable, and high-quality solutions for modern AI challenges.
Challenges and Limitations of LLM Routing
While LLM routing offers significant advantages, its implementation is not without challenges. These limitations highlight areas for improvement and innovation to fully harness its potential.
1. Data Sparsity and Labeling Issues
- Sparse Training Data:
- Robust routers rely on high-quality preference data to distinguish between strong and weak models for different queries. However, obtaining sufficient labeled data for all query types is a persistent challenge.
- Domain-Specific Challenges:
- Out-of-domain queries often expose weaknesses in routing systems trained on narrow datasets, reducing their effectiveness in real-world applications.
2. Generalizability Across Models
- Model-Specific Bias:
- Routers trained with specific model pairs may struggle to generalize when new models are introduced.
- Quality gaps and performance metrics may differ significantly across models, requiring continuous retraining or fine-tuning of the router.
- Evolving Model Landscape:
- The rapid emergence of new LLMs with varying architectures and capabilities demands adaptable routing frameworks, which is difficult to achieve with static systems.
3. Computational Overheads
- Router Latency:
- Although minimal compared to LLM inference costs, router latency can impact overall system responsiveness, particularly in high-throughput environments.
- Inference Complexity:
- Some advanced routing mechanisms, such as cascading systems, may introduce additional computational overheads due to sequential evaluations.
4. Quality vs. Cost Trade-Offs
- Fine-Tuning Thresholds:
- Setting the correct quality thresholds to balance cost and performance requires careful calibration and domain-specific tuning.
- Potential Quality Degradation:
- Over-reliance on smaller models for cost savings can lead to noticeable quality drops in complex tasks, negatively affecting user experience.
5. Ethical and Privacy Concerns
- Data Sensitivity:
- Routing systems need to account for privacy concerns when queries involve sensitive data. Routing such queries to cloud-based high-performance models may raise compliance issues.
- Bias in Routing Decisions:
- Routers trained on biased datasets may inadvertently reinforce model biases, leading to inequitable performance across user groups.
6. Lack of Standardization
- Evaluation Benchmarks:
- While frameworks like ROUTERBENCH provide a baseline, there is no universal standard for evaluating LLM routing systems, making cross-comparison difficult.
- Metrics Alignment:
- Response quality metrics, such as BART score or GPT-ranking, may not always align with user expectations, creating gaps in perceived versus measured performance.
Addressing these challenges requires a combination of advanced techniques, better training datasets, and adaptive routing strategies
Real-World Applications of LLM Routing
The practical applications of LLM routing illustrate its transformative potential in balancing quality and cost across a variety of industries. These case studies showcase how routing systems address real-world challenges and deliver measurable improvements in efficiency.
1. Customer Support Systems
- Dynamic Query Handling:
- LLM routing allows customer support systems to intelligently triage queries. Straightforward inquiries, such as order status updates, are routed to smaller models, while nuanced or high-priority questions are directed to advanced models.
- For example, Chatbot Arena data demonstrates how queries can be dynamically allocated to optimize response quality and operational costs.
- Enhanced Scalability:
- Organizations can scale support services without proportional increases in costs by leveraging smaller models for routine tasks.
2. Content Generation and Creative Tools
- Optimized Workflows:
- In applications like marketing and content creation, routing systems streamline workflows by assigning repetitive tasks (e.g., generating basic text) to smaller models, while larger models handle complex creative tasks such as scriptwriting.
- Customizable Quality Levels:
- Content platforms can adjust routing thresholds to meet specific quality standards, ensuring flexibility across projects.
3. Developer Assistance
- Code Generation and Debugging:
- Developer tools benefit from LLM routing by dynamically selecting models for tasks such as debugging, code optimization, or documentation generation based on the complexity of the query.
- Hybrid systems have shown that smaller models can handle up to 40% of developer queries with minimal quality degradation, significantly reducing computational costs.
4. Education and e-Learning
- Adaptive Learning Systems:
- In e-learning platforms, LLM routing tailors responses to student queries based on difficulty. Simple fact-based questions are answered by smaller models, while complex conceptual explanations are handled by high-performance models.
- Cost-Effective Scaling:
- By routing easier tasks to smaller models, educational platforms can serve larger user bases without exponential cost increases.
5. Healthcare Applications
- Preliminary Query Processing:
- Healthcare chatbots leverage routing systems to handle preliminary inquiries, such as appointment scheduling or symptom checking, with cost-effective models, reserving advanced models for detailed medical advice.
- Privacy-Aware Deployments:
- Sensitive patient data is routed to local edge-based models to ensure compliance with privacy regulations.
6. Research and Knowledge Management
- Information Retrieval:
- LLM routing enhances retrieval-augmented generation (RAG) systems by routing fact-based queries to efficient models, while complex, multi-step reasoning queries are directed to stronger models.
- Efficient Collaboration:
- Research teams utilize routing to balance cost and quality when processing large-scale datasets or generating reports.
These case studies underscore the versatility of LLM routing in addressing diverse challenges across industries. By intelligently allocating queries, organizations can achieve significant efficiency gains while maintaining high-quality outcomes.
References: