LLMs Evaluation: Benchmarks, Challenges, and Future Trends
The evaluation of Large Language Models (LLMs) focuses on benchmarks, scalability, ethical challenges, and multimodal testing. Dynamic frameworks and emerging trends drive robust, adaptive AI performance, ensuring safer, efficient deployment in sensitive fields like healthcare, finance, and law.

In the dynamic field of artificial intelligence, Large Language Models (LLMs) have emerged as a cornerstone of technological innovation, demonstrating remarkable capabilities across domains such as natural language understanding, reasoning, and creative text generation. The evaluation of these models has become increasingly critical, not just for understanding their performance but also for ensuring their safe deployment in real-world applications.
The evolution of LLM evaluation methodologies parallels the rapid advancements in their design. Early approaches relied on task-specific benchmarks like GLUE and SuperGLUE to assess isolated capabilities such as syntactic parsing and question answering. However, with the advent of models like GPT-3, ChatGPT, and GPT-4, evaluation frameworks have expanded to accommodate complex, multi-faceted performance dimensions.
Key motivations for evaluating LLMs include:
- Performance Benchmarking: Ensuring models meet task-specific requirements across diverse applications.
- Safety and Trustworthiness: Addressing concerns such as data privacy, toxicity, and misinformation to mitigate societal risks.
- Alignment and Ethics: Aligning model outputs with human values and minimizing biases.
Current research underscores the importance of developing robust, adaptive evaluation frameworks that address these goals. The growing integration of LLMs into sensitive domains like healthcare, law, and finance further emphasizes the need for rigorous and comprehensive evaluations.
Objectives of LLM Evaluation
Evaluating Large Language Models (LLMs) serves multiple critical objectives, each essential for ensuring their effective deployment and integration into real-world systems. As these models are increasingly embedded in sensitive applications such as healthcare, law, and finance, rigorous evaluation becomes paramount. The key objectives of LLM evaluation include:
1. Performance Benchmarking
- Definition: Benchmarking aims to quantify an LLM's performance across diverse tasks, such as language understanding, reasoning, and generation.
- Examples: Metrics like accuracy, perplexity, and F1 scores help evaluate language comprehension and fluency.
- Impact: This enables developers to compare models, select optimal architectures, and identify areas for improvement.
2. Understanding Limitations
- Challenges Addressed: Identifying model weaknesses such as hallucination, factual inaccuracies, or poor generalization to out-of-distribution (OOD) data.
- Strategies:
- Using datasets like AdvGLUE for adversarial robustness testing.
- Employing benchmarks such as GLUE-X for OOD performance.
- Outcome: Clear insights into scenarios where models may fail, enabling risk mitigation.
3. Ensuring Safety and Trustworthiness
- Focus Areas:
- Avoidance of harmful outputs, such as bias, toxicity, and misinformation.
- Protection against adversarial attacks and robustness to perturbations in input data.
- Benchmarks:
- Safety-specific datasets (e.g., RealToxicityPrompts, AdvGLUE).
- Comprehensive evaluations of alignment with ethical norms and human values.
4. Alignment with Human Values
- Purpose: Evaluating how closely the outputs of LLMs align with societal and ethical expectations.
- Challenges:
- Detecting bias and stereotypes using datasets like StereoSet and CrowS-Pairs.
- Measuring ethical alignment with frameworks such as ETHICS.
- Goal: To develop systems that are inclusive, unbiased, and adaptable to diverse cultural contexts.
5. Risk Mitigation in Deployment
- Why Important:
- Mitigating risks such as data leakage, system manipulation, or operational failures.
- Evaluation Tools:
- Red-teaming methods to probe for vulnerabilities.
- Robustness metrics to measure stability under adversarial conditions.
- Real-World Example: Testing ChatGPT's ability to handle medical and legal queries without propagating misinformation.
By fulfilling these objectives, LLM evaluations ensure not only technical excellence but also societal trust and safety, laying the groundwork for responsible AI deployment across industries.
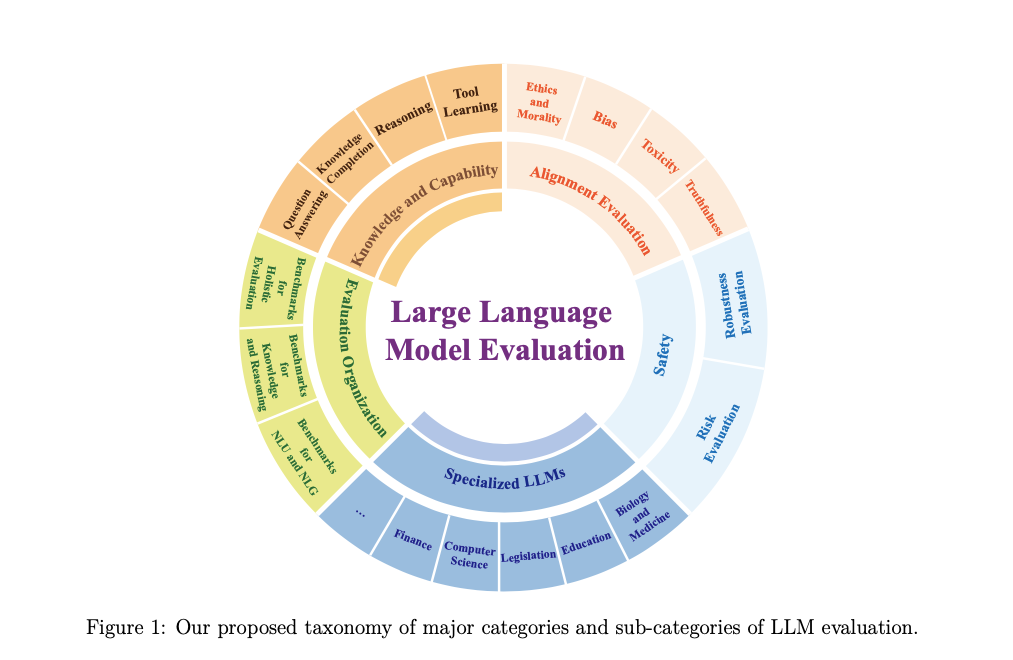
Dimensions of LLM Evaluation
Understanding the dimensions of LLM evaluation is critical to designing robust benchmarks and protocols that align with their evolving capabilities and use cases. The key dimensions encompass the what, where, and how of evaluation, which provide a structured framework for assessing LLM performance across diverse domains and tasks.
1. What to Evaluate
- General Capabilities: These include tasks such as natural language understanding, reasoning, and natural language generation. Evaluations often measure fluency, coherence, and contextual relevance of responses. MSTEMP, for example, introduces out-of-distribution (OOD) semantic templates to rigorously test these aspects.
- Domain-Specific Capabilities: Performance tailored to specialized domains, such as legal, medical, or financial sectors, is critical. Benchmarks like PubMedQA and LSAT are specifically designed for these settings.
- Safety and Ethical Considerations: Assessments of bias, toxicity, and alignment with human values are essential for ensuring trustworthy deployment. Tools like RealToxicityPrompts and StereoSet are commonly used in this area.
2. Where to Evaluate
- Standardized Benchmarks: Datasets like GLUE, SuperGLUE, and Big-Bench have been central to assessing general capabilities. However, their static nature may limit their ability to test adaptive performance.
- Dynamic Frameworks: Advanced tools like DYVAL and MSTEMP emphasize generating dynamic, OOD datasets to evaluate robustness and adaptability. This approach addresses limitations of static benchmarks by introducing variability in input styles and semantics.
3. How to Evaluate
- Static Metrics: Conventional metrics such as accuracy, F1-score, and perplexity measure baseline performance. However, they may not capture nuances like contextual relevance or user alignment.
- Dynamic Approaches: Evaluation tools like PandaLM integrate dynamic benchmarks to test models under varying conditions, including adversarial scenarios.
- Human and Model Scoring: Human evaluators often provide qualitative insights into coherence and alignment, whereas automated evaluators (e.g., GPT-4 as a scoring model) offer scalability and cost-efficiency.
By combining insights from standardized benchmarks and emerging dynamic frameworks, LLM evaluation can achieve a balance between scalability, depth, and adaptability.
Current Evaluation Strategies
Evaluating Large Language Models (LLMs) involves a range of strategies that address various performance dimensions, from basic accuracy to robustness under adversarial and out-of-distribution (OOD) conditions. This section outlines the current methodologies for evaluating LLMs, emphasizing the evolution from static benchmarks to adaptive, dynamic evaluation frameworks.
1. Static Benchmarks
- Definition: Static benchmarks consist of pre-defined datasets that evaluate specific capabilities of LLMs, such as natural language understanding, reasoning, and generation. Examples include GLUE, SuperGLUE, and MMLU.
- Challenges:
- Data Contamination: Static datasets often overlap with training data, leading to inflated evaluation metrics.
- Limited Robustness Testing: These benchmarks struggle to test real-world adaptability, including adversarial inputs or OOD generalization.
- Examples:
- GLUE: A multi-task benchmark for natural language understanding.
- SuperGLUE: An improved version of GLUE with more challenging tasks.
2. Dynamic Evaluation
- Overview: Dynamic evaluations adapt test conditions to better assess model robustness and contextual understanding.
- Frameworks:
- Advantages:
- Improved Robustness: Dynamic evaluation exposes models to diverse and unpredictable test cases.
- Reduced Bias: Incorporates human-like subjectivity for a more comprehensive assessment.
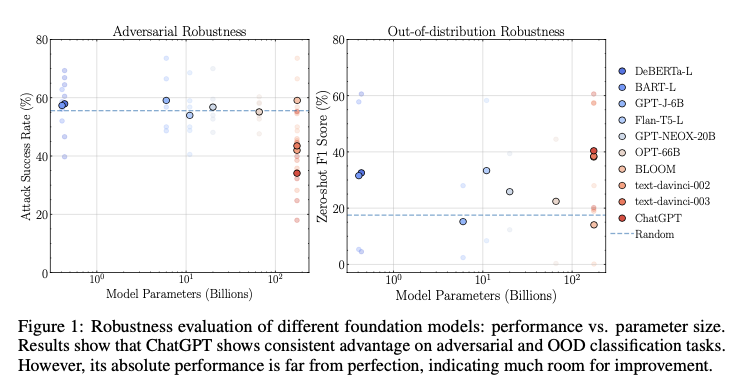
3. Adversarial and Out-of-Distribution (OOD) Testing
- Adversarial Testing:
- Focuses on evaluating models under intentional input distortions (e.g., typographical errors, sentence-level distractions).
- Tools like AdvGLUE assess adversarial robustness by introducing text perturbations.
- OOD Testing:
- Evaluates how well models perform on data outside their training distribution.
- Benchmarks like Flipkart and DDXPlus are used to test real-world applicability.
4. Human-in-the-Loop Evaluation
- Definition: Combines automated metrics with human judgment to evaluate subjective qualities like coherence, alignment, and ethical considerations.
- Applications:
- Used in frameworks like PandaLM, where human annotations validate automated assessments.
- Reduces reliance on static accuracy metrics by considering qualitative feedback.
5. Emerging Trends
- Hybrid Approaches:
- Combining static and dynamic evaluations to balance scalability and depth.
- Leveraging adaptive frameworks like PandaLM for automated, scalable evaluations.
- Real-World Testing:
- Incorporating domain-specific datasets (e.g., PubMedQA, LSAT) to simulate practical applications.
These strategies illustrate the shift towards more nuanced and adaptive evaluation methodologies, ensuring LLMs meet the complex demands of real-world deployment.
Emerging Trends and Benchmarks
The field of LLM evaluation is rapidly evolving, with new trends and benchmarks emerging to address the growing complexity and diverse applications of these models. These advancements aim to tackle existing gaps in evaluation methodologies, focusing on robustness, domain-specific testing, and ethical considerations.
1. Multi-Modal Evaluation
- Definition: Multi-modal evaluations assess LLMs on their ability to process and integrate inputs from diverse data types, such as text, images, and audio.
- Examples:
- MSTEMP uses semantic templates to evaluate LLMs on tasks requiring cross-modal reasoning.
- Applications include medical imaging reports, legal document parsing, and multimedia content generation.
- Significance: Ensures that models can handle real-world scenarios involving multi-modal inputs effectively.
2. Adaptive and Dynamic Benchmarks
- Overview: Dynamic evaluation frameworks like DYVAL and PandaLM enable models to adapt to evolving task requirements and diverse user inputs.
- Applications:
- Real-time updates to benchmarks ensure evaluation remains relevant as models improve.
- Use in out-of-distribution testing to assess adaptability and robustness.
- Advantages:
- Mitigates the risk of data contamination in training datasets.
- Enhances real-world applicability by dynamically generating test cases.
3. Ethical and Safety-Centric Testing
- Key Focus Areas:
- Reducing bias and toxicity in generated outputs.
- Addressing alignment with ethical standards through frameworks like ETHICS.
- Benchmarks:
- RealToxicityPrompts tests models' responses to provocative or ethically sensitive prompts.
- StereoSet and CrowS-Pairs evaluate biases in gender, race, and profession.
- Outcome: Promotes fairness and inclusivity in model deployment.
4. Domain-Specific Benchmarks
- Examples:
- PubMedQA for medical reasoning.
- LSAT and ReClor for legal and logical reasoning.
- Purpose: Ensures models meet the stringent requirements of specialized industries, such as healthcare, law, and finance.
5. Unified Benchmarking Platforms
- Examples:
- HELM (Holistic Evaluation of Language Models) aggregates multiple dimensions of evaluation, including performance, robustness, and ethical alignment.
- Leaderboards such as OpenAI’s Evals offer standardized comparisons across models.
- Significance: Streamlines the evaluation process by providing a comprehensive view of model capabilities and limitations.
6. Focus on Explainability and Interpretability
- Definition: Emphasis on making models' decision-making processes transparent and understandable to users.
- Current Efforts:
- Mechanistic interpretability studies aim to dissect how models arrive at specific outputs.
- Benchmarks assess models’ ability to explain reasoning and decision-making processes.
- Applications: Critical for deployment in sensitive domains like healthcare and legal systems.
These emerging trends signify a paradigm shift in LLM evaluation, ensuring that benchmarks remain relevant, adaptive, and aligned with the ethical, societal, and technical demands of the future.
Key Challenges in LLM Evaluation
Despite significant advancements in the evaluation of Large Language Models (LLMs), several challenges persist, limiting the efficacy and reliability of current methodologies. This section highlights the most pressing issues in LLM evaluation, encompassing data contamination, robustness, scalability, and ethical concerns.
1. Data Contamination
- Definition: Data contamination occurs when evaluation benchmarks overlap with the training datasets of LLMs, leading to inflated performance metrics.
- Impact:
- Distorted understanding of model capabilities.
- Overestimation of generalization and adaptability.
- Proposed Solutions:
2. Robustness
- Challenges:
- Adversarial inputs, such as minor perturbations or rephrased prompts, often lead to degraded performance.
- Poor generalization to OOD samples, where models encounter inputs outside their training distribution.
- Examples:
- Future Directions:
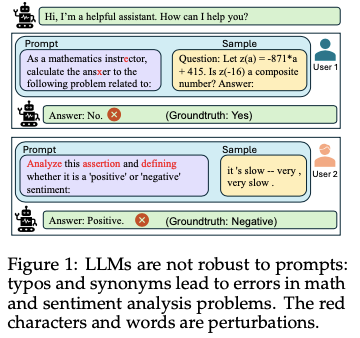
3. Scalability
- Issue:
- Evaluation frameworks struggle to scale with increasingly larger models, such as GPT-4 and beyond, which involve billions of parameters.
- Computational and financial costs of evaluating models at scale are prohibitive.
- Proposed Solutions:
- Zero-shot evaluation techniques reduce computational demands while maintaining meaningful insights.
- Optimized benchmarking platforms, such as HELM, that integrate diverse evaluation metrics across multiple domains.
4. Ethical and Safety Concerns
- Bias and Toxicity:
- Persistent societal biases in LLM outputs, as evaluated using benchmarks like StereoSet and RealToxicityPrompts, remain unresolved.
- Models often fail to meet safety standards in sensitive applications like healthcare and education.
- Hallucinations:
- LLMs generate incorrect or misleading information, particularly on fact-heavy tasks.
- Recommendations:
- Incorporate ethical alignment benchmarks, such as ETHICS, to evaluate bias and alignment with human values.
- Employ interpretability methods to identify and mitigate hallucinations in real-time applications.
Addressing these challenges requires a combination of novel benchmarks, adaptive evaluation strategies, and interdisciplinary research to ensure that LLM evaluation keeps pace with advancements in AI technologies.
Looking Forward - Future Challenges and Opportunities in LLM Evaluation
The landscape of Large Language Model (LLM) evaluation is both dynamic and multifaceted, reflecting the rapid evolution of the models themselves. As we look to the future, addressing current gaps and embracing new opportunities will be pivotal in advancing both the utility and trustworthiness of LLMs.
| Category | Focus Areas | Examples of Benchmarks |
|---|---|---|
| General Capabilities | Natural language understanding, reasoning, generation | GLUE, SuperGLUE, MMLU, BIG-bench |
| Domain-Specific Capabilities | Industry-specific tasks (Medical, Legal, Financial) | PubMedQA, MultiMedQA, LSAT, ReClor, FinQA, FiQA |
| Safety and Trustworthiness | Bias, toxicity, adversarial robustness | StereoSet, CrowS-Pairs, RealToxicityPrompts, AdvGLUE |
| Extreme Risks | Dangerous capabilities, alignment risks | Red-teaming scenarios, frontier alignment benchmarks |
| Undesirable Use Cases | Misinformation detection, inappropriate content | FEVER, TruthfulQA, SafetyBench |
Table 1: Summary of benchmarks categorized by general capabilities, domain specificity, safety and trustworthiness, extreme risks, and undesirable use cases.
1. Bridging Context-Specific Gaps
- Challenge: Most evaluation frameworks focus on general benchmarks, often neglecting the nuanced demands of domain-specific applications such as healthcare, finance, or education.
- Opportunities:
- Development of tailored benchmarks for specialized fields like law (e.g., LSAT datasets) and medicine (e.g., PubMedQA).
- Incorporation of cultural and linguistic diversity to address biases in multilingual and multicultural contexts.
2. Enhancing Ethical and Safety Evaluations
- Challenge: Persistent issues like bias, toxicity, and misinformation demand continuous innovation in evaluation methodologies..
- Opportunities:
- Broader adoption of tools like RealToxicityPrompts and StereoSet to identify harmful content.
- Advanced interpretability techniques to better understand model behavior and decision-making processes.
- Expansion of frameworks like ETHICS to cover more nuanced moral and societal dimensions.
3. Addressing Scalability and Environmental Sustainability
- Challenge: The increasing computational and environmental costs of training and evaluating LLMs are significant barriers.
- Opportunities:
- Adoption of efficient evaluation protocols like zero-shot and few-shot learning.
- Research into greener AI practices to minimize the environmental impact of large-scale evaluations.
4. Developing Standards and Best Practices
- Challenge: The lack of standardized evaluation methodologies often results in inconsistent results, making cross-study comparisons difficult.
- Opportunities:
- Creation of universal benchmarks that encompass diverse capabilities, safety, and ethical dimensions.
- Introduction of collaborative frameworks for benchmarking and sharing insights, such as HELM and APIBench.
5. Embracing Multimodal and Adaptive Evaluations
- Challenge: Traditional evaluation strategies often fail to accommodate multimodal capabilities or adaptive performance under dynamic conditions.
- Opportunities:
6. Long-Term Implications and Emerging Risks
- Challenge: The potential for LLM misuse and unintended consequences necessitates proactive risk management.
- Opportunities:
- Exploration of evaluation protocols for extreme risks, such as alignment failures or misuse in adversarial scenarios.
- Continuous research into the societal impacts of widespread LLM deployment, ensuring alignment with human values and governance frameworks.