LLM Observability: Practices, Tools, and Trends
Explore LLM observability with this comprehensive guide. Understand metrics, logs, traces, and tools like Langfuse and SigNoz. Learn best practices, handle production challenges, and stay ahead with trends like multi-modal monitoring and AI-driven anomaly detection.

Observability in Large Language Models (LLMs) involves gathering data to understand, evaluate, and optimize their performance. Unlike traditional software systems, LLMs are non-deterministic, producing varied outputs even with identical inputs. This unpredictability makes ensuring reliability particularly challenging, especially in production.
LLMs power a variety of AI applications, from chatbots to retrieval-augmented generation (RAG) systems. Observability enables developers to gain visibility into model behavior, uncover root causes of issues, and optimize performance. It goes beyond traditional monitoring by focusing on the "why" behind system behavior.
Why LLM Observability Matters and it's Core pilars
Key reasons include:
- Non-Deterministic Outputs: LLMs generate unpredictable responses, requiring observability to ensure reliability.
- High Resource Demands: Observability monitors GPU, CPU, and memory usage to optimize performance and manage costs.
- User Expectations: Real-time observability ensures latency and throughput meet user needs.
By integrating metrics, logs, traces, and evaluations, observability becomes essential for maintaining high-performing LLM systems.
The MELT Framework
The MELT framework—Metrics, Events, Logs, and Traces—forms the foundation of observability practices in LLM systems. Each pillar provides specific insights into system performance and behavior:
- Metrics:
- Metrics capture key performance indicators such as latency, token production rates, throughput, and resource utilization (CPU, GPU, memory).
- By analyzing these metrics, developers can identify performance bottlenecks and ensure optimal resource allocation for demanding workflows like inference or training.
- Events and Logs:
- Events include triggers such as API calls, model invocations, or retrieval operations, while logs capture details like input-output pairs and errors.
- Structured logging enables developers to track the model's decision-making process and identify patterns or anomalies across workflows.
- Traces:
- Traces map the journey of a request through multiple components of an LLM application, offering a holistic view of dependencies and bottlenecks.
- This is particularly useful in complex systems like Retrieval-Augmented Generation (RAG), where requests flow through embedding generation, vector databases, and the LLM.
Extended Pillars for LLMs
In addition to the MELT framework, LLM observability incorporates several extended pillars tailored to the unique characteristics of these systems:
- Prompts and Feedback:
- Prompts: Observability begins with capturing structured data about the prompts sent to the LLM. This includes metadata like the version of the prompt template and the context used.
- User Feedback: Gathering explicit feedback, such as thumbs up/down ratings or qualitative comments, provides valuable data for iterative improvements. Feedback can also help refine the alignment between user expectations and model outputs.
- LLM Evaluations:
- Automated Quality Metrics: Metrics like BLEU, ROUGE, and cosine similarity measure the relevance and coherence of model outputs, automating routine evaluations.
- Human-in-the-Loop Evaluations: For nuanced applications, human evaluators assess LLM outputs for context-specific accuracy, appropriateness, and alignment with ethical standards.
- Retrieval Analysis:
- In Retrieval-Augmented Generation systems, the retrieval component plays a critical role in providing the context for the LLM’s responses. Observability involves monitoring retrieval accuracy, response relevance, and latency in these systems.
Integration of Pillars for Comprehensive Observability
By integrating metrics, events, logs, traces, prompts, feedback, and evaluations, observability offers a comprehensive view of how LLM systems perform in real-world scenarios. It ensures that:
- Bottlenecks are identified and resolved quickly.
- Model outputs meet quality and performance benchmarks.
- Retrieval systems complement LLM capabilities effectively.
This multi-layered approach to observability equips developers and operators with the tools they need to optimize workflows, improve reliability, and maintain user satisfaction.
Implementing LLM Observability in Production
Deploying LLM observability in production environments presents several challenges:
- Complex Workflows:
- LLMs often interact with various components such as vector databases, APIs, and retrieval systems. Tracing these interactions is crucial for identifying dependencies and bottlenecks.
- Resource Demands:
- LLMs are resource-intensive, requiring efficient monitoring of GPU, CPU, and memory usage to ensure scalability and cost-effectiveness.
- Non-Determinism:
- Due to their stochastic nature, LLMs may produce different outputs for the same input. Logging and evaluating these outputs over time is essential for maintaining consistency and quality.
Core Components for Effective Implementation
- Data Collection and Persistence:
- Tools like Splunk and Snowflake enable structured logging of prompts, responses, and metadata (e.g., prompt versions, API endpoints). Indexed data facilitates rapid analysis and debugging.
- Resource Monitoring:
- Use platforms like Prometheus and Grafana to track resource usage in real-time. Monitoring GPU utilization during inference helps identify inefficiencies and optimize configurations.
- Tracing Across Workflows:
- Implement tracing tools such as OpenTelemetry and SigNoz to visualize the end-to-end flow of requests. Tracing highlights delays or errors in multi-component systems, including RAG workflows.
- Dashboards and Alerts:
- Dashboards: Tools like Grafana provide visual insights into latency, throughput, error rates, and resource utilization. Customizable dashboards enable quick assessments of system health.
- Alerts: Set thresholds for critical metrics (e.g., latency spikes, high memory usage) to trigger alerts, enabling proactive maintenance before user experience is impacted.
- LLM-Specific Evaluations:
Workflow Optimization in Production
Implementing observability requires continuous iteration and refinement:
- Proactive Monitoring: Observability is not static. Regularly review logs, traces, and metrics to identify emerging patterns or issues.
- Feedback Loops: Correlate user feedback with observability data to refine prompts and configurations.
- Cost Efficiency: Monitor and analyze token usage to manage operational costs, particularly in high-demand systems.
The Role of Observability Tools
Modern observability tools simplify production-grade implementation:
- LangSmith: Focused on tracing and feedback integration.
- SigNoz: Offers open-source flexibility for small teams.
- Helicone: Tracks costs and manages prompt experiments effectively.
By combining these components and practices, organizations can maintain robust, scalable, and efficient LLM systems in production environments.
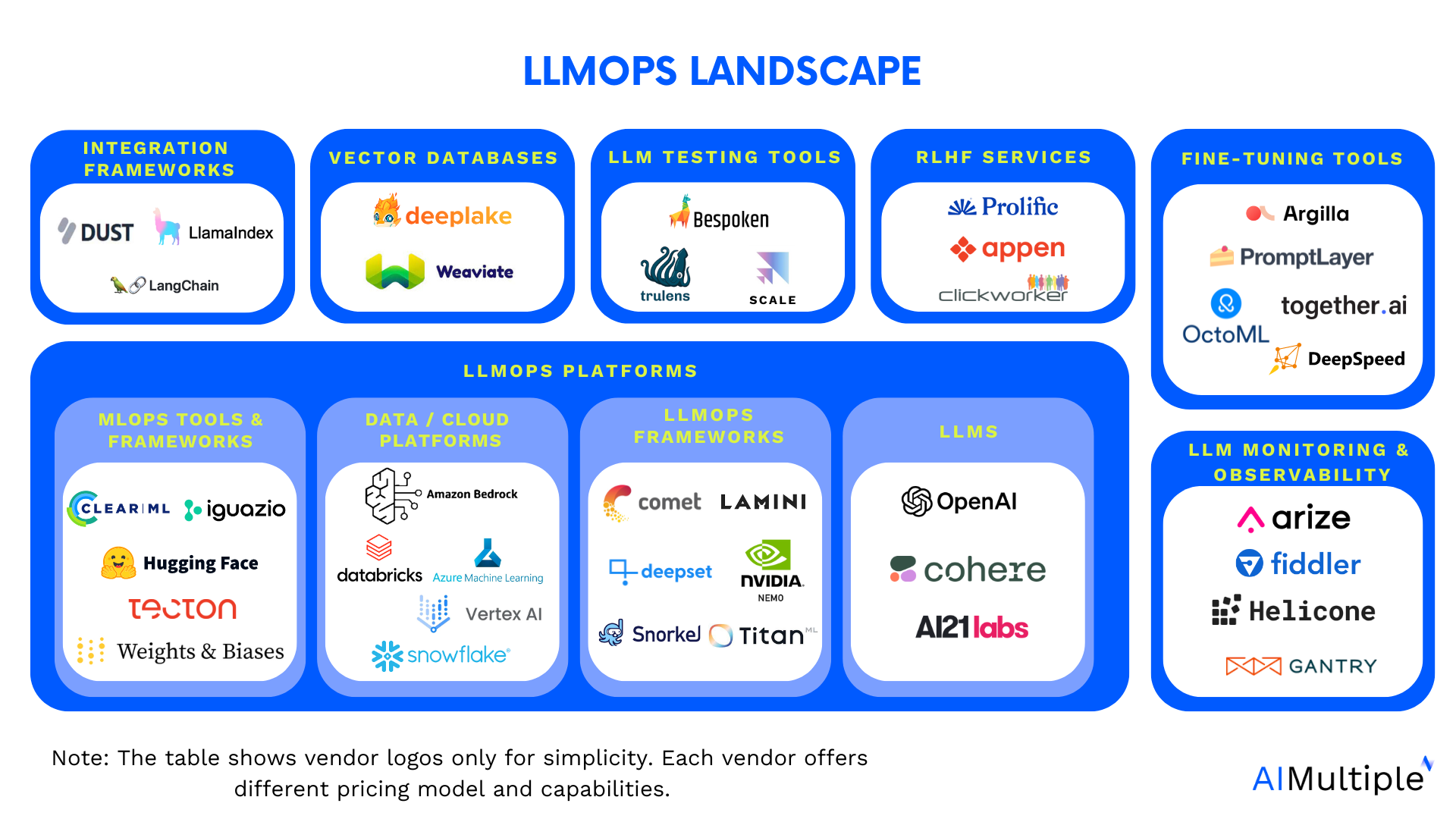
Essential Tools for LLM Observability
Key Observability Tools
A wide range of tools are available to address the specific needs of LLM observability, each offering unique capabilities. Here are the most prominent options:
- LangSmith:
- Core Features: Tracing workflows, feedback collection, and prompt evaluation.
- Best For: Developers needing robust prompt management and evaluative feedback integration.
- Langfuse:
- Core Features: Detailed dashboards, prompt versioning, and cost analysis.
- Best For: Comprehensive monitoring and cost tracking in enterprise-grade LLM applications.
- SigNoz:
- Core Features: Open-source tracing, metrics, and log aggregation.
- Best For: Teams looking for flexible, customizable observability without heavy investment.
- Helicone:
- Core Features: Token usage tracking, cost breakdowns, and version control for prompts.
- Best For: Cost-sensitive applications with a focus on efficient resource management.
- WhyLabs:
- Core Features: Metrics for evaluating text quality, relevance, and detecting issues like hallucinations or biases.
- Best For: Applications requiring granular quality assessments.
Comparison of Tools
The following table highlights the strengths of each tool:
| Feature | LangSmith | Langfuse | SigNoz | Helicone | WhyLabs |
|---|---|---|---|---|---|
| Open Source | ✖ | ✖ | ✔ | ✖ | Partially |
| Prompt Management | ✔ | ✔ | ✖ | ✔ | ✖ |
| Tracing | ✔ | ✔ | ✔ | ✔ | ✖ |
| Cost Tracking | ✖ | ✔ | ✖ | ✔ | ✖ |
| Quality Evaluations | ✔ | ✔ | ✖ | ✔ | ✔ |
How to Choose the Right Tool
- For Startups or Small Teams:
- Open-source tools like SigNoz provide robust observability features with minimal cost.
- For Enterprises:
- Comprehensive solutions like Langfuse combine metrics, feedback, and cost monitoring for complex workflows.
- For Specific Use Cases:
Tool Integration Best Practices
- Unified Dashboards: Integrate multiple tools into a single interface to reduce complexity.
- Iterative Selection: Start with one core tool and expand as needs evolve.
- Custom Alerts: Configure alerts across tools to identify issues before they escalate.
By leveraging the strengths of these tools, teams can enhance their observability practices and maintain seamless, efficient LLM operations.
Best Practices for Implementing LLM Observability
To ensure successful observability in LLM systems, consider the following best practices:
- Structured Logging:
- What to Log: Capture prompts, responses, errors, and metadata such as API endpoints and latency.
- Tools: Use structured logging platforms like Splunk or Snowflaketo organize data for efficient querying and analysis.
- Comprehensive Tracing:
- Purpose: Map the flow of requests across workflows to diagnose performance bottlenecks and trace errors.
- Tools: Implement tracing frameworks such as OpenTelemetry or SigNoz for end-to-end visibility, especially in multi-component systems like Retrieval-Augmented Generation (RAG).
- Monitor Resource Utilization:
- Why It’s Important: LLMs are resource-intensive, and monitoring CPU, GPU, and memory usage ensures efficient performance.
- Tools: Platforms like Prometheus and Grafana help visualize real-time resource usage and identify inefficiencies.
- Real-Time Dashboards and Alerts:
- Dashboards: Use tools like Grafana to display key performance metrics such as latency, error rates, and throughput.
- Alerts: Configure automated alerts to detect anomalies early, such as sudden spikes in latency or resource consumption.
- Regular Evaluations:
- User Feedback Integration:
- Mechanisms: Collect user feedback (e.g., thumbs up/down) to identify areas for improvement.
- Integration: Link feedback data to traces and logs to refine prompts and responses effectively.
- Cost and Performance Optimization:
- Token Tracking: Monitor token usage and costs with tools like Helicone.
- Scalability: Regularly evaluate workflows to ensure they meet performance and budget goals.
- Guardrails for Safety and Ethics:
- Set Limits: Implement boundaries to prevent inappropriate outputs using prompt constraints and validation steps.
- Data Insights: Use observability data to enhance guardrails and address emerging risks.
Iterative Observability Practices
Observability is a continuous process that evolves with system requirements:
- Proactive Monitoring: Regularly review observability data to identify trends and emerging issues.
- Collaboration: Foster a culture of observability across teams to ensure tools and insights are used effectively.
- Periodic Refinement: Iterate on observability practices to adapt to new challenges, such as scaling or shifting user needs.
Future Trends in LLM Observability
Emerging Needs in Observability
As LLM technologies evolve, observability practices must keep pace with increasing complexity. The following trends are shaping the future of LLM observability:
- Multi-Modal Models:
- New Challenges: Multi-modal LLMs process text, images, audio, and video, requiring observability tools to capture telemetry data across diverse inputs and outputs.
- Unified Tracing: Future observability frameworks must integrate traces across modalities, connecting workflows from input to output.
- Edge Deployments:
- Constraints: Edge environments have limited computational resources, necessitating lightweight yet effective observability solutions.
- Adaptation: Tools like LangKit and SigNoz are evolving to support low-latency, resource-efficient monitoring for edge-based LLM deployments.
Automation and AI-Augmented Observability
- Self-Monitoring Models:
- Capabilities: LLMs themselves will assist in observability by evaluating their outputs, detecting anomalies, and suggesting optimizations.
- Impact: This will reduce the manual workload and enhance proactive monitoring.
- AI-Driven Anomaly Detection:
- Features: Advanced tools will automatically detect unusual patterns in system behavior, such as performance drops or model drift.
- Benefits: Early detection minimizes the risk of service disruptions and enhances reliability.
Ethical Observability
- Bias and Hallucination Detection:
- Focus: Observability systems will increasingly integrate tools to detect and mitigate biases and hallucinations in LLM outputs.
- Compliance: Ethical observability frameworks will ensure outputs align with regulatory and organizational policies.
- Transparency and Accountability:
- Traceability: Observability tools will provide detailed logs and traces of model decisions to support transparency in critical applications like healthcare and finance.
Expanding the Observability Ecosystem
- Workflow-Oriented Insights:
- Scope: Observability will extend beyond the LLM to include upstream and downstream systems, such as vector databases and pre/post-processing pipelines.
- Integration: Tools will enable developers to monitor the entire workflow and assess how external systems impact LLM performance.
- Cost Efficiency:
- Optimization: Future observability platforms will integrate cost-tracking features to manage operational expenses and optimize resource utilization.
Conclusion
The future of LLM observability lies in integrating cutting-edge automation, ethical safeguards, and holistic monitoring solutions. As LLM systems grow more complex and versatile, observability will remain critical for ensuring reliability, efficiency, and compliance. By adopting these forward-looking practices, organizations can stay ahead of the curve and deliver robust, trustworthy AI applications.
References: