
Model Merging
Discover LLM model merging, a technique to combine multiple Large Language Models (LLMs) into a single, more powerful model without extra training. Explore top merging methods like Linear, SLERP, Task Arithmetic, TIES, and DARE, with YAML configs and practical use cases.

Model merging refers to combining multiple distinct Large Language Models (LLMs) into a single unified LLM without requiring additional training or fine-tuning. The primary rationale behind this approach is that different LLMs, each optimized to excel at specific tasks, can be merged to enhance performance across the combined expertise of both models. However, within the realm of LLMs, merging can take various forms. This blog post aims to explore the different types of LLM merging and discuss various examples of LLMs created through a merge operation. We will also talk about the mergekit python library used for the same.

📰 Linear
The linear method employs a weighted average to combine two or more models, with the weight parameter allowing users to precisely control the contribution of each model's characteristics to the final merged model.
Here is a YAML configuration from the mergekit library for linear merge of three models:
models:
- model: psmathur/orca_mini_v3_13b
parameters:
weight: 1.0
- model: WizardLM/WizardLM-13B-V1.2
parameters:
weight: 0.3
- model: garage-bAInd/Platypus2-13B
parameters:
weight: 0.5
merge_method: linear
dtype: float16
🌐 SLERP
The Spherical Linear Interpolation (SLERP) method blends the capabilities of LLMs by interpolating between their parameters in a high dimensional space. By treating the models' parameters as points on a hypersphere, SLERP calculates the shortest path between them, ensuring a constant rate of change and maintaining the geometric properties inherent to the models' operational space.
In situations where the models have orthogonal or divergent features, normal averaging could result in a canceling-out effect or a compromise that weakens the resultant model. SLERP, by following the curvature of the space, can more effectively blend these differences, leveraging the diversity of the models' knowledge.
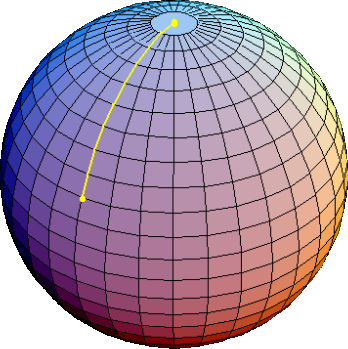
Here is a yaml for SLERP:
- One of the two models participating must be set as
base_model. t- interpolation factor. Att=0will returnbase_model, att=1will return the other one.slices: Defines slices of layers from different models to be used. This field is mutually exclusive withmodels.
Check out the detailed merge configuration and parameter specification (for keys under parameters) for explanations on each of the YAML keys used below.
slices:
- sources:
- model: psmathur/orca_mini_v3_13b
layer_range: [0, 40]
- model: garage-bAInd/Platypus2-13B
layer_range: [0, 40]
merge_method: slerp
base_model: psmathur/orca_mini_v3_13b
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5 # fallback for rest of tensors
dtype: float16You might be asking, what does value: [1, 0.5, 0.7, 0.3, 0] mean? This is called the BlockMerge Gradient interpolation technique. Suppose you provide the gradient values as [1.0, 0.5, 0.0]. This tells the script to start by blending tensors with 100% of model2's values, gradually transition to a 50-50 blend between the two models, and finally, to use only model1's values.
🥼 Task Arithmetic
The Task Arithmetic method utilizes "task vectors," created by subtracting the weights of a base model from those of the same model that has been fine-tuned for a specific task. This process effectively captures the directional shifts within the model's weight space, enhancing performance on that task. These task vectors are then linearly combined and reintegrated with the base model's weights. This technique is particularly effective for models fine-tuned from a common ancestor, offering a seamless method for improving model performance. Moreover, it is an invaluable conceptual framework for understanding and implementing complex model-merging strategies.
Note: The mergekit parameters for task arithmetic are identical to the more straightforward Linear above.
Below is a YAML configuration used to produce Hermes-low-tune-2.
base_model: teknium/OpenHermes-2.5-Mistral-7B
dtype: bfloat16
merge_method: task_arithmetic
slices:
- sources:
- layer_range: [0, 32]
model: teknium/OpenHermes-2.5-Mistral-7B
- layer_range: [0, 32]
model: simonveitner/Math-OpenHermes-2.5-Mistral-7B
parameters:
weight: 0.25
- layer_range: [0, 32]
model: openaccess-ai-collective/dpopenhermes-alpha-v0
parameters:
weight: 0.25
- layer_range: [0, 32]
model: mlabonne/NeuralHermes-2.5-Mistral-7B
parameters:
weight: 0.25
- layer_range: [0, 32]
model: mlabonne/NeuralHermes-2.5-Mistral-7B-laser
parameters:
weight: 0.25
🎀 TIES
TIES-merging is currently the most popular model merging method in the LLM community due to its ability to merge more than two models simultaneously.
The TIES-Merging method utilizes the task arithmetic framework to efficiently combine multiple task-specific models into a single multitask model, addressing the challenges of parameter interference and redundancy. TIES-Merging, in a way, builds upon the work of Task Arithmetic discussed above.
The TIES-Merging method minimizes the loss of valuable information due to redundant parameter values and sign disagreements across models, which specifies task vectors and applies a sign consensus algorithm.
The TIES-Merging method involves three key steps:
- Trim: This step reduces redundancy in task-specific models by retaining only the most significant parameters based on a predefined density parameter and setting the rest to zero. It identifies the top-k % most significant changes made during fine-tuning and discards the less impactful ones.
- Elect Sign: This step creates a unified sign vector to resolve conflicts from different models suggesting opposing adjustments to the same parameter. This vector represents the most dominant direction of change (positive or negative) across all models based on the cumulative magnitude of the changes.
- Disjoint Merge: In the final step, parameter values aligning with the unified sign vector are averaged, excluding zero values. This process ensures that only parameters contributing to the agreed-upon direction of change are merged, enhancing the coherence and performance of the resulting multitask model.

Here is a YAML configuration for ties:
density- a fraction of weights in differences from the base model to retain.
models:
- model: psmathur/orca_mini_v3_13b
parameters:
density: [1, 0.7, 0.1] # density gradient
weight: 1.0
- model: garage-bAInd/Platypus2-13B
parameters:
density: 0.5
weight: [0, 0.3, 0.7, 1] # weight gradient
- model: WizardLM/WizardMath-13B-V1.0
parameters:
density: 0.33
weight:
- filter: mlp
value: 0.5
- value: 0
merge_method: ties
base_model: TheBloke/Llama-2-13B-fp16
parameters:
normalize: true
int8_mask: true
dtype: float16👔 DARE TIES/Task Arithmetic
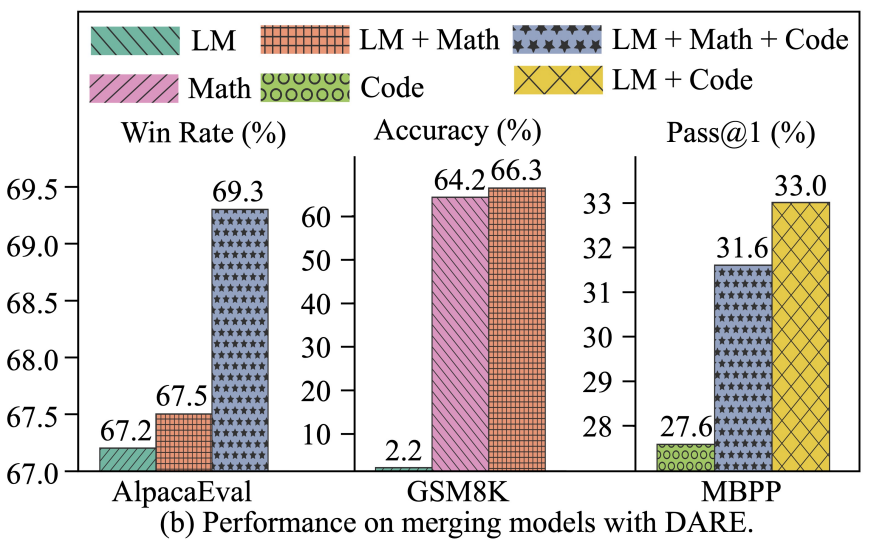
The DARE (Drop And REscale) method introduces a novel approach to LLM merging, strategically sparsifying delta parameters (differences between fine-tuned and pre-trained parameters) to mitigate interference and enhance performance. Here's a breakdown:
1. Pruning (Sparsification): DARE employs random pruning, resetting fine-tuned weights back to their original values, discarding less impactful changes, and focusing on critical modifications.
2. Rescaling: Following pruning, DARE rescales the remaining weights to maintain output expectations using a calculated scale factor, preserving the performance characteristics of the original models.
3. Merging Variants: DARE offers two options:
- With Sign Consensus (dare_ties): Incorporates a sign consensus algorithm, resolving conflicts and unifying parameter adjustment directions for better coherence.
- Without Sign Consensus (dare arithmetic): Merges parameters directly for a more straightforward approach, suitable when sign consensus is unnecessary or computationally expensive.
4. Plug-and-Play Capability: DARE works across multiple SFT (Supervised Fine-Tuning) homologous models, enabling their efficient fusion into a single model with diverse capabilities.
5. Performance Enhancement: By strategically eliminating up to 90% or 99% of delta parameters with minimal value ranges, DARE streamlines architecture and demonstrably improves performance. This method successfully merges task-specific LLMs into a unified model with enhanced abilities across various tasks.
🧟 FrankenMerges
Also known as Passthrough, this method concatenates layers from different models, enabling the creation of models with a unique number of parameters, such as combining two 7B models to form a 9B model. Termed "frankenmerges" or "Frankenstein models" within the community, this approach has produced significant models like goliath-120b from two Llama 2 70B models and SOLAR-10.7B-v1.0, employing depth-up scaling. Despite its experimental nature, passthrough facilitates the direct passage of input tensors through unmodified, ideal for layer-stacking type merges. Here is a YAML for frankenmerge:
slices:
- sources:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
layer_range: [0, 16]
- sources:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
layer_range: [6, 22]
merge_method: passthrough
dtype: float16
🤔 Some Open Questions
Which tokenizer does the merged result follow?
Yes, the tokenizer is also merged. The chosen method determines how tokens from different models are integrated, using either the base model's tokenizer, a union of all tokens, or a tokenizer from a specific model.
tokenizer_source is set to union, mergekit combines all tokens from the involved models into a single tokenizer, allowing a merged model to understand and generate text using the combined vocabulary of all original models.Can MoEs act like a model merge technique?
It can. The mergekit library provides a mergekit-moe script for combining Mistral or Llama family models of the same size into MoE models. It combines the self-attention and layer-normalization parameters from a "base" model with the MLP parameters from a set of "expert" models. See the below YAML for creating Phixtral using 4 Phi-2 models:
base_model: cognitivecomputations/dolphin-2_6-phi-2
gate_mode: cheap_embed
experts:
- source_model: cognitivecomputations/dolphin-2_6-phi-2
positive_prompts: [""]
- source_model: lxuechen/phi-2-dpo
positive_prompts: [""]
- source_model: Yhyu13/phi-2-sft-dpo-gpt4_en-ep1
positive_prompts: [""]
- source_model: mrm8488/phi-2-coder
positive_prompts: [""]
cheap_embed uses only the raw token embedding of the prompts, using the gate parameters for every layer. For more info on this and other gate_mode: methods, look into Gate Modes.💻 Create your first merged model
Let's perform a merge operation using a free tier colab notebook (link here). First, clone and install the mergekit library.
!git clone https://github.com/cg123/mergekit.git
!cd mergekit && pip install -q -e .Now we create a YAML config file. You can refer to the examples in the mergekit repo for reference.
import yaml
MODEL_NAME = "ucalyptus-13B-slerp"
yaml_config = """
slices:
- sources:
- model: psmathur/orca_mini_v3_13b
layer_range: [0, 40]
- model: garage-bAInd/Platypus2-13B
layer_range: [0, 40]
merge_method: slerp
base_model: psmathur/orca_mini_v3_13b
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5 # fallback for rest of tensors
dtype: float16
"""
# Save config as yaml file
with open('config.yaml', 'w', encoding="utf-8") as f:
f.write(yaml_config)
Now we use mergekit-yaml cli tool to merge the two models using SLERP.
!mergekit-yaml config.yaml merge --cuda --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpickle--cudaenables the matrix arithmetic on GPU.--copy-tokenizerenables copying a tokenizer to the output.--allow-crimesenables mixing of architectures.--out-shard-size <size>specifies the number of parameters per output shard of the model. Default is set at 5B.--lazy-unpickleuses an experimental lazy unpickler for lower memory usage. This setting is useful for performing merges on a free tier colab notebook.- Other important flags are specified here.
Next, we ready the README.md file before uploading the merged model to huggingface_hub. This involves specifying a MODEL_NAME for the merge output and using the HF_TOKEN to permit write access to huggingface hub.
We start by installing the required dependencies.
!pip install -qU huggingface_hub
!pip install -qU transformers accelerateAfter this, we create a simple template to make it reusable for different models.
template_text = """
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
{%- for model in models %}
- {{ model }}
{%- endfor %}
---
# {{ model_name }}
{{ model_name }} is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
{%- for model in models %}
* [{{ model }}](https://huggingface.co/{{ model }})
{%- endfor %}
## Configuration
\```yaml
{{- yaml_config -}}
\```
"""Now, we use this template to write our Model Card that was used for the merge.
from huggingface_hub import ModelCard, ModelCardData
from jinja2 import Template
username = "ucalyptus"
# Create a Jinja template object
jinja_template = Template(template_text.strip())
# Get list of models from config
data = yaml.safe_load(yaml_config)
if "models" in data:
models = [data["models"][i]["model"] for i in range(len(data["models"])) if "parameters" in data["models"][i]]
elif "parameters" in data:
models = [data["slices"][0]["sources"][i]["model"] for i in range(len(data["slices"][0]["sources"]))]
elif "slices" in data:
models = [data["slices"][i]["sources"][0]["model"] for i in range(len(data["slices"]))]
else:
raise Exception("No models or slices found in yaml config")
# Fill the template
content = jinja_template.render(
model_name=MODEL_NAME,
models=models,
yaml_config=yaml_config,
username=username,
)
# Save the model card
card = ModelCard(content)
card.save('merge/README.md')
Lastly, we use the Huggingface API to push the changes to the HF repo automatically created.
from google.colab import userdata
from huggingface_hub import HfApi
username = "ucalyptus"
# Defined in the secrets tab in Google Colab
api = HfApi(token=userdata.get("HF_TOKEN"))
api.create_repo(
repo_id=f"{username}/{MODEL_NAME}",
repo_type="model"
)
api.upload_folder(
repo_id=f"{username}/{MODEL_NAME}",
folder_path="merge",
)
You can now use the model created using the script below:
from transformers import AutoTokenizer
import transformers
import torch
model = "ucalyptus/ucalyptus-13B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
🧮 Conclusion
Exploring model merging techniques like Linear, SLERP, Task Arithmetic, TIES, and DARE illuminates the potential to amalgamate various LLMs' strengths into a singular, more potent entity. These methods not only enhance performance but also broaden the applicability of LLMs across diverse tasks. The innovative approaches to merging underscore the evolving landscape of artificial intelligence, promising significant strides in model efficiency and capability.
How to evaluate your merged models?
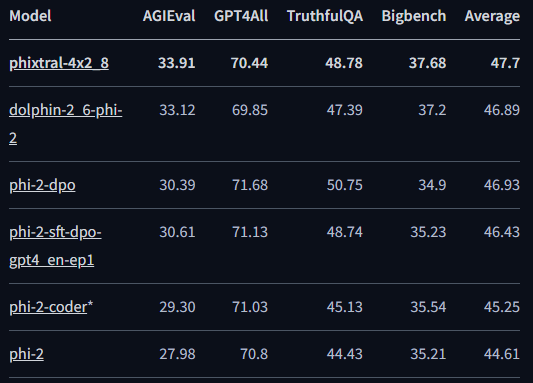
Try the🧐 LLM AutoEval colab notebook on Nous suite by Maxime Llabone. Below is an evaluation performed on Phixtral-4x2_8:
📜 References
- Model Merging Papers collection
- Merging LLM and testing with Private data sets
- r/LocalLlama post on benefits of model merging
- Here is a Twitter post on merging two 7B models using Apple's MLX
- Merge example code from Apple's MLX
- Check out the mixtral branch in the mergekit repository on how to create Phixtral
- LazyMergeKit colab notebook
- SLERP-type interpolation methods have been previously used for GAN image interpolation
- SLERP code to interpolate on two tensors