Multilingual LLMs: Progress, Challenges, and Future Directions
Multilingual LLMs face challenges like cross-lingual knowledge barriers, data imbalances, and performance disparities in low-resource languages. Key advancements include multilingual fine-tuning, retrieval-augmented generation (RAG), and adaptive architectures.

This article explores the state of multilingual capabilities in Large Language Models (LLMs), evaluating how well these models manage cross-lingual understanding, knowledge transfer, and safety concerns. By analyzing recent research and advancements, we assess whether multilinguality is a solved problem or if significant challenges remain. Key topics include cross-lingual knowledge barriers, performance disparities between high- and low-resource languages, safety risks, and innovative solutions to enhance multilingual performance.
The Rise of Multilingual LLMs
Multilingual Large Language Models (LLMs) have revolutionized natural language processing (NLP), enabling tasks such as machine translation, summarization, and sentiment analysis across multiple languages. As global reliance on AI-powered tools increases, the demand for multilingual capabilities becomes critical for equitable access and inclusivity.
Early advancements like mBERT and XLM-R paved the way for handling multiple languages by training on multilingual corpora, leveraging linguistic similarities across languages to enhance performance. However, these models often struggled with low-resource languages due to limited training data.
Recent models like GPT-4 and BLOOM have expanded multilingual capabilities, incorporating diverse datasets to support over 50 languages. Despite these advancements, significant gaps remain. High-resource languages like English dominate training corpora, leading to disparities in performance. Furthermore, challenges such as cross-lingual knowledge transfer and safety risks in low-resource languages highlight that multilinguality is far from a solved problem.
Multilingual vs. Cross-Lingual Capabilities
While multilingual LLMs are designed to handle multiple languages, distinguishing between multilingual and cross-lingual capabilities is essential to understand their true performance.
- Multilingual capability refers to a model's ability to understand and generate text in multiple languages.
- Cross-lingual capability involves transferring knowledge learned in one language to perform tasks in another, which is far more complex and requires deeper understanding.
Understanding Multilingual Performance
Modern LLMs show impressive results in multilingual tasks, especially for high-resource languages like English, Spanish, and Chinese. Models such as GPT-4 and LLaMA perform exceptionally well on benchmarks like MMLU and FLORES-101 in these languages. However, their performance drops significantly when tested on low-resource languages due to imbalanced training data. This creates a gap in accessibility and functionality across languages.
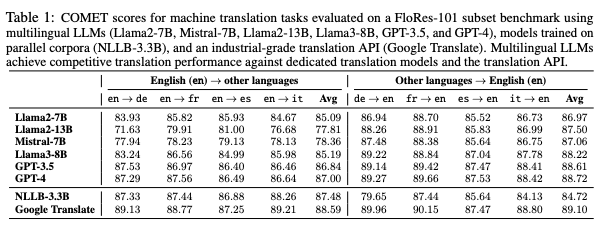
The Cross-Lingual Knowledge Barrier

A major challenge is the cross-lingual knowledge barrier—LLMs often fail to transfer knowledge from one language to another. For example, a model might correctly answer a question in English but fail when the same question is asked in Swahili or Igbo. This issue is most visible in tasks requiring implicit reasoning or domain-specific knowledge, where translation alone isn’t enough.
Efforts to overcome this barrier include:
- Mixed-language training: Introducing multilingual data during training to encourage knowledge transfer.
- Retrieval-Augmented Generation (RAG): Providing contextually relevant information during inference to aid understanding.
Despite these efforts, models still exhibit significant performance gaps between high- and low-resource languages.
Evaluating Multilingual and Cross-Lingual Performance
Accurately measuring these capabilities requires comprehensive benchmarking. Metrics such as:
- BLEU and COMET for translation quality,
- Cross-lingual QA benchmarks for reasoning tasks,
are used to evaluate how well models generalize across languages. Findings show that while models perform well in translation, they struggle with reasoning and domain-specific tasks in multiple languages.
Recognizing the difference between multilingual and cross-lingual capabilities is critical for building truly global and inclusive AI systems. Bridging this gap is essential for creating models that serve users effectively, no matter their language.
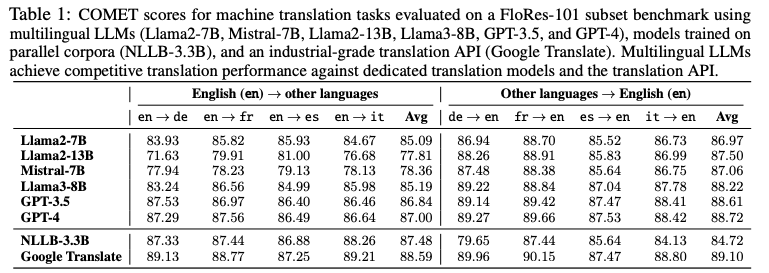
Challenges in Multilingual LLMs
Despite remarkable progress in developing multilingual LLMs, significant challenges hinder their ability to perform equally well across diverse languages. These challenges stem from data imbalances, biases, and safety risks, especially in handling low-resource languages. Addressing these issues is crucial for building more inclusive and reliable AI systems.
Bias and Language Imbalance
One of the most pressing challenges is the imbalance in training data. High-resource languages like English, Chinese, and Spanish dominate the datasets used to train most LLMs, while low-resource languages are severely underrepresented. This imbalance leads to:
- Performance disparities: LLMs excel in high-resource languages but often produce inaccurate or low-quality outputs in low-resource languages.
- Cultural bias: Models trained predominantly on content from specific regions may reflect cultural assumptions or norms that are not globally representative.
- Linguistic bias: Languages with complex scripts or grammar (e.g., Amharic, Khmer) are often poorly represented, causing the model to misinterpret or mishandle these languages.
Even when low-resource languages are included, the quality of data can vary. Informal, unverified content might dominate, leading to biased or unreliable model outputs.
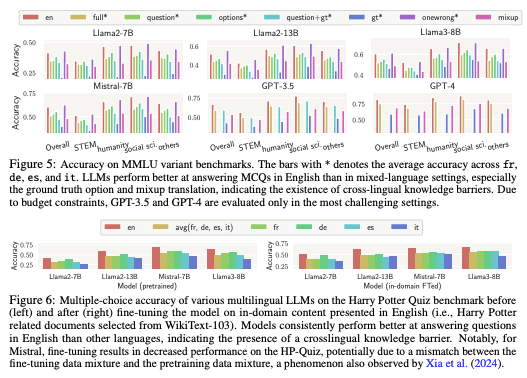
Safety and Alignment Concerns
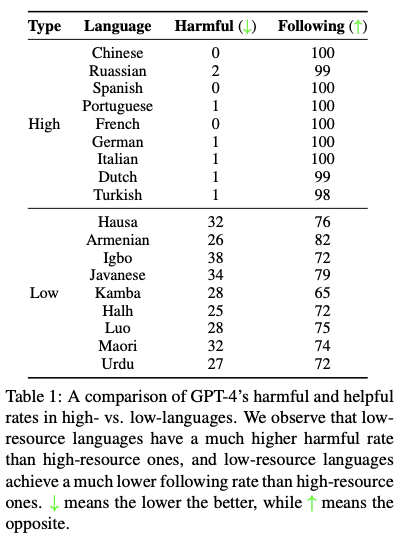
Safety is another major concern for multilingual LLMs. Research shows that these models are more vulnerable to generating harmful, irrelevant, or unsafe content in low-resource languages compared to high-resource ones. Two key risks include:
- Harmfulness curse: Models are more likely to generate harmful responses when prompted in low-resource languages due to inadequate safety alignment.
- Relevance curse: Models tend to produce irrelevant or nonsensical content when handling complex instructions in low-resource languages.
Standard safety alignment techniques, like Reinforcement Learning from Human Feedback (RLHF), have been less effective in addressing these risks across multiple languages. Aligning models to follow human values and avoid harmful outputs remains a significant challenge, especially when safety datasets lack linguistic diversity.
Cross-Lingual Transfer Limitations
While many LLMs demonstrate strong performance in multilingual tasks (where both the input and output are in the same language), they often fail in cross-lingual scenarios. Examples include:
- Cross-lingual QA: Struggles to apply knowledge learned in English to answer questions in Hindi or Swahili.
- Domain-specific tasks: Poor performance in applying specialized knowledge (e.g., legal or medical) across languages due to domain-specific data scarcity in low-resource languages.
These issues highlight the cross-lingual knowledge barrier, where the model's ability to transfer knowledge across languages remains limited.
Evaluation and Benchmarking Gaps
Evaluating multilingual models presents its own set of challenges. Most benchmarks focus on high-resource languages, making it difficult to assess how well models handle linguistic diversity. Existing benchmarks, like MMLU and FLORES-101, provide some insights but still lack comprehensive coverage for:
- Low-resource languages
- Multimodal multilingual tasks
- Culturally nuanced content
Without robust, representative benchmarks, it becomes difficult to measure true progress in multilinguality and identify areas needing improvement.
Current Solutions to Multilingual Challenges
To address the significant challenges facing multilingual LLMs—such as data imbalance, bias, safety concerns, and cross-lingual knowledge transfer—researchers have developed various innovative solutions. These strategies aim to enhance model performance, increase linguistic inclusivity, and ensure safer, more reliable outputs across languages.
Mixed-Language Training and Fine-Tuning
One of the most promising approaches to improving multilingual performance is mixed-language training. This method involves incorporating multiple languages into the training process to encourage better cross-lingual understanding. Key strategies include:
- Multilingual Fine-Tuning: Fine-tuning LLMs on datasets that combine high- and low-resource languages can help models generalize knowledge across languages. For example, introducing low-resource languages alongside high-resource ones during training has been shown to reduce performance disparities.
- Dynamic Data Sampling: Adjusting data sampling rates during training to prioritize underrepresented languages without sacrificing overall performance. This strategy ensures that low-resource languages receive more attention during model updates.
These techniques have been successful in reducing the cross-lingual knowledge barrier, allowing models to better transfer knowledge across languages. However, challenges remain, particularly in preserving performance for high-resource languages while improving low-resource support.
Cross-Lingual Feedback and Instruction Tuning
Another effective solution involves aligning models with human preferences across languages through cross-lingual feedback and instruction tuning. This approach focuses on improving a model's understanding and response generation in multiple languages. Notable methods include:
- Cross-Lingual Human Feedback: Collecting human feedback in multiple languages to fine-tune models and align them with culturally relevant norms and safety standards.
- Instruction Tuning with Multilingual Data: Expanding instruction-tuning datasets to cover diverse languages and tasks, enabling models to better follow instructions across linguistic contexts.
For example, the development of models like xLLMs-100, which leverage instruction datasets in 100 languages and cross-lingual human feedback, has demonstrated significant improvements in both understanding and generation tasks across multiple languages.

Retrieval-Augmented Generation (RAG) and Vector Databases
Retrieval-Augmented Generation (RAG) integrates external knowledge retrieval into the generation process, helping models provide more accurate and context-aware responses, particularly in low-resource languages. This approach involves:
- External Knowledge Integration: During inference, the model retrieves relevant information from external knowledge bases or vector databases to supplement its responses.
- Contextual Adaptation: RAG models adapt responses based on culturally and linguistically appropriate information, reducing the likelihood of hallucinations and improving translation accuracy.
By grounding model outputs in reliable data sources, RAG mitigates the hallucination problem and enhances performance in languages with limited training data.
Multilingual Model Scaling and Specialized Architectures
Scaling models to handle more languages and introducing specialized components have also been effective strategies for improving multilingual performance. These methods include:
- Model Scaling: Expanding models to support hundreds of languages, as seen in models like NLLB (No Language Left Behind) and PaLM 2, improves cross-lingual understanding by training on diverse linguistic data.
- Language-Adaptive Layers: Incorporating specialized layers or adapters that fine-tune model behavior for specific languages without retraining the entire model. This technique enables efficient adaptation to low-resource languages with minimal computational overhead.
Addressing Bias and Safety
Efforts to reduce bias and improve safety in multilingual models have focused on two main strategies:
- Balanced Data Curation: Actively sourcing high-quality, balanced datasets across languages and cultures to minimize bias and ensure fair representation.
- Multilingual Safety Alignment: Expanding safety alignment techniques, such as RLHF, to include low-resource languages and culturally specific safety checks. This ensures that models respond safely and appropriately in all supported languages
Future Directions in Multilingual LLMs
While significant progress has been made in enhancing the multilingual capabilities of Large Language Models (LLMs), there is still considerable work to be done to achieve true global inclusivity and balanced performance across all languages. Future research and development must focus on overcoming remaining challenges related to data diversity, model scalability, bias mitigation, and contextual understanding. This section explores promising directions to further advance multilingual LLMs.
Expanding and Diversifying Training Data
The foundation of any effective multilingual model lies in the diversity and quality of its training data. Current models are heavily skewed toward high-resource languages, leaving many low-resource languages underrepresented. Future efforts must prioritize:
- Curating High-Quality Multilingual Datasets: Creating balanced datasets that represent a wide range of languages, dialects, and cultural contexts. This includes sourcing data from indigenous communities, local media, and educational content.
- Data Augmentation for Low-Resource Languages: Using synthetic data generation, back-translation, and data augmentation techniques to expand the availability of low-resource language data without compromising quality.
- Community-Driven Data Collection: Collaborating with native speakers and linguists to gather authentic language data that captures cultural nuances and idiomatic expressions.
These strategies will help reduce the data imbalance and enable models to better understand and generate content in diverse languages.
Improving Cross-Lingual Knowledge Transfer
Overcoming the cross-lingual knowledge barrier remains a critical challenge. Future research should focus on developing more robust mechanisms for knowledge transfer between languages, including:
- Multilingual Knowledge Distillation: Transferring knowledge from high-resource language models to low-resource models using teacher-student frameworks to enhance performance in underserved languages.
- Adaptive Multilingual Architectures: Designing models that can dynamically adjust their internal representations based on linguistic and cultural contexts, improving the transfer of complex concepts across languages.
- Universal Language Representations: Advancing research in universal embeddings and representations that bridge linguistic gaps, enabling models to apply learned knowledge across diverse languages more effectively.
By strengthening cross-lingual knowledge transfer, models can become more versatile and accurate across tasks in multiple languages.
Ethical AI and Bias Mitigation
Bias in multilingual LLMs remains a significant ethical concern. To build equitable AI systems, future research must prioritize bias detection and mitigation strategies, such as:
- Fair Representation in Training Data: Ensuring that training datasets are free from cultural, gender, and societal biases by diversifying data sources and applying rigorous filtering techniques.
- Bias Auditing Tools for Multilingual Models: Developing tools and benchmarks specifically designed to detect and measure bias across languages, helping researchers identify and address harmful patterns.
- Ethical Alignment Across Cultures: Incorporating culturally sensitive alignment methods that reflect diverse values and ethical standards, ensuring that models behave responsibly in different linguistic and cultural contexts.
Proactively addressing these concerns will contribute to safer and fairer multilingual AI systems.
Enhancing Contextual and Cultural Understanding
Current LLMs often lack the ability to fully grasp cultural nuances and contextual subtleties in different languages. Future developments should focus on:
- Context-Aware Learning: Training models to better interpret and adapt to various social, historical, and cultural contexts within different languages, improving the relevance and appropriateness of generated content.
- Multimodal Multilingual Learning: Integrating multimodal inputs (e.g., text, audio, images) to enrich models’ understanding of cultural references, idiomatic expressions, and non-verbal communication cues.
- Localized Model Customization: Allowing users and developers to fine-tune models for specific regions or communities, enabling more accurate and culturally appropriate outputs.
Improving contextual understanding will enhance the usability and relevance of multilingual models for global users.
Scalable and Efficient Model Architectures
As LLMs grow larger, computational efficiency and scalability become more critical, especially when supporting numerous languages. Future research should explore:
- Parameter-Efficient Training: Developing more efficient fine-tuning methods (e.g., adapters, LoRA) to scale models without excessive computational resources.
- Edge Deployment for Multilingual Models: Optimizing models for deployment on edge devices, enabling real-time multilingual processing in resource-constrained environments.
- Sustainable AI Development: Balancing performance improvements with energy efficiency to minimize the environmental impact of training and deploying large-scale multilingual models.
These advancements will make multilingual AI more accessible and sustainable for widespread use.
Conclusion and Future Outlook
The journey toward achieving true multilinguality in Large Language Models (LLMs) has seen significant progress, yet critical challenges remain. Current models like GPT-4, LLaMA, and BLOOM have expanded the boundaries of what AI can accomplish across multiple languages, but their performance remains uneven, favoring high-resource languages while underperforming in low-resource and culturally diverse contexts.
Key challenges such as data imbalance, cross-lingual knowledge transfer barriers, bias, and safety concerns continue to hinder the effectiveness of these models globally. Although promising solutions—such as mixed-language training, cross-lingual feedback, retrieval-augmented generation (RAG), and multilingual fine-tuning—have shown potential in reducing these gaps, achieving truly inclusive and equitable AI systems demands further innovation.
Looking forward, the future of multilingual LLMs will depend on addressing several critical areas:
- Diversifying and balancing training datasets to better represent low-resource languages and cultural nuances.
- Enhancing cross-lingual knowledge transfer through adaptive architectures and multilingual knowledge distillation.
- Mitigating biases and ensuring safety with culturally sensitive alignment and ethical AI practices.
- Improving contextual and cultural understanding to deliver more relevant and accurate outputs across languages.
- Scaling models efficiently with sustainable AI practices to ensure accessibility and environmental responsibility.
The next generation of multilingual models must prioritize fairness, inclusivity, and reliability to serve global users effectively. Achieving this vision will require collaboration between AI researchers, linguists, policymakers, and local communities to build models that reflect the rich diversity of human language and culture.
While multilinguality in LLMs is not yet a solved problem, the path forward is clear. Through continued innovation and collective effort, we can create AI systems that truly understand and communicate with the world.
References:


https://multilingual.com/magazine/september-2024/overcoming-the-limitations-