Open-Source Code Language Models: DeepSeek, Qwen, and Beyond
Open-source CodeLLMs like DeepSeek-Coder and Qwen2.5-Coder revolutionize code intelligence by offering repository-level training, multilingual support, and advanced features. These models rival proprietary solutions, fostering transparency, collaboration, and customization.

The Current Landscape of Open Source CodeLLMs
The evolution of Large Language Models (LLMs) has ushered in a new era for code intelligence, enabling developers to automate tasks like bug detection, code generation, and optimization with unprecedented efficiency. However, the dominance of proprietary solutions, such as OpenAI's GPT-4 and Anthropic's Claude, often leaves independent researchers and developers grappling with accessibility issues. In this context, open-source initiatives like DeepSeek-Coder, Qwen2.5-Coder, and others have emerged as critical players in democratizing access to advanced code intelligence technologies.
Why Open Source Matters
The open-source philosophy in code LLMs transcends technological advancement; it fosters collaboration, transparency, and innovation. Unlike closed systems, open-source models provide full access to training methodologies, datasets, and architectures. This openness enables independent audits, ethical use, and extensive customization, ensuring that models like DeepSeek-Coder and Qwen2.5-Coder align with diverse community needs.
Highlights of Key Open Source Players
- DeepSeek-Coder Series:
- The DeepSeek-Coder lineup represents a robust suite of models, spanning parameter sizes from 1.3B to 33B. Trained on over 2 trillion tokens and featuring cutting-edge techniques like Fill-In-Middle (FIM) for better code completion, these models deliver exceptional performance in both project-level code understanding and multilingual support.
- Advancements: Repository-level training and deduplication at the code repository scale significantly enhance the model's ability to comprehend dependencies across files.
- Benchmark Success: DeepSeek-Coder's top-tier models, such as the 33B variant, rival proprietary solutions like OpenAI's Codex and GPT-3.5 on standard coding benchmarks.
- Qwen2.5-Coder Series:
- Alibaba's Qwen2.5-Coder series showcases a diverse range of models tailored for varying computational capacities, from 0.5B to 32B parameters. The models employ advanced pre-training on 5.5 trillion tokens, integrating file-level and repository-level instruction tuning.
- Special Features: A fine-tuned focus on tokenization and context management allows Qwen2.5-Coder to handle complex coding tasks with sequence lengths up to 128K tokens.
- Performance Benchmarks: The Qwen2.5-Coder series demonstrates state-of-the-art results in multiple code-specific benchmarks, narrowing the performance gap with GPT-4.
Challenges in the Ecosystem
Despite their promise, open-source CodeLLMs face challenges in matching the scalability, resource optimization, and fine-tuned performance of proprietary systems. For instance, closed systems often benefit from vast computational resources and exclusive datasets, which remain out of reach for many open-source projects.
The Path Ahead
The open-source community continues to innovate through collaborative efforts, focusing on bridging the performance gap with proprietary models. As open-source models like DeepSeek-Coder and Qwen2.5-Coder refine their architectures and expand their datasets, they not only empower developers but also pave the way for ethical and accessible AI applications in software development.
A Technical Dive into DeepSeek Coder
DeepSeek-Coder represents a significant advancement in the field of open-source code intelligence, offering state-of-the-art features and capabilities that bridge the gap between open-source and proprietary large language models. Designed to enhance productivity and streamline software development workflows, DeepSeek-Coder incorporates several innovative strategies that set it apart from its peers.
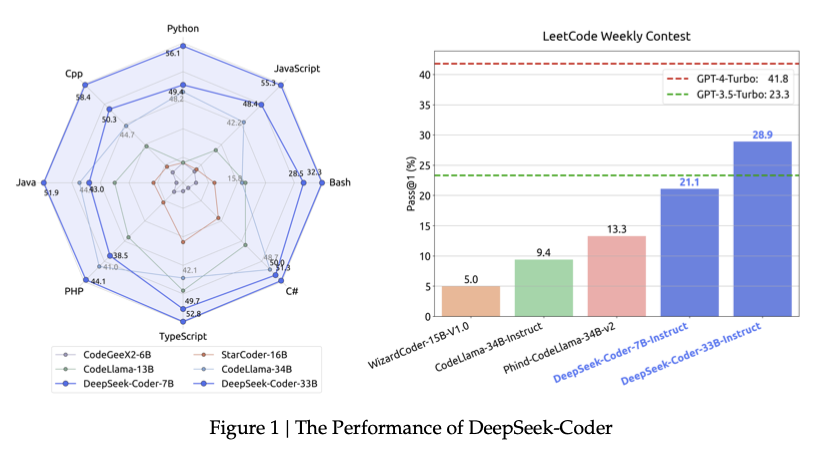
Core Features and Innovations
- Repository-Level Training:
- Unlike traditional file-level training, DeepSeek Coder leverages repository-level training to account for cross-file dependencies. This approach improves the model's ability to understand project structures and resolve complex coding challenges that span multiple files.
- The training corpus includes 87 programming languages and spans over 2 trillion tokens, ensuring comprehensive coverage of real-world coding scenarios.
- Enhanced Context Length:
- DeepSeek Coder supports a context length of up to 16,384 tokens, which has been further extended to 128K in the latest versions. This capability allows for effective handling of long and complex codebases, making it ideal for large-scale software projects.
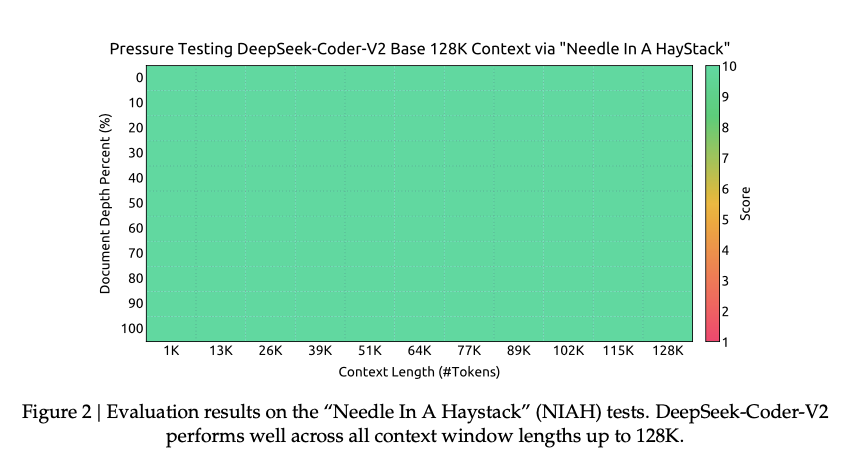
- Fill-In-the-Middle (FIM) Training:
- The FIM training strategy is a standout feature of DeepSeek Coder. It enables the model to generate and complete code blocks by filling gaps in the middle of a given sequence. This method improves the model’s ability to perform code infilling tasks, which are critical for debugging and code completion.
- Instruction Tuning:
- By fine-tuning the model with instruction-based data, DeepSeek Coder achieves enhanced performance in code-specific tasks. This makes it highly effective in generating accurate and contextually relevant code snippets for a variety of programming challenges.
Performance Benchmarks
DeepSeek Coder’s performance has been rigorously evaluated against industry-standard benchmarks:
- Code Generation:
- Achieves state-of-the-art results on HumanEval and MBPP benchmarks, outperforming several leading models in accuracy.
- Mathematical Reasoning:
- Demonstrates superior reasoning capabilities in tasks requiring logical problem-solving and code generation for mathematical problems.
- Cross-File Code Completion:
- Excels in understanding and generating code that spans multiple files within a repository, thanks to its repository-level pre-training.
Challenges and Future Directions
Despite its impressive capabilities, DeepSeek Coder faces challenges in areas such as instruction-following and scalability. Future iterations aim to address these issues by enhancing the model’s alignment with real-world programming scenarios and expanding its multilingual support.
Understanding the Qwen Series
The Qwen series, developed by Alibaba, represents a new frontier in open-source CodeLLMs, showcasing powerful coding capabilities alongside general and mathematical reasoning. The Qwen2.5-Coder models, an evolution of the Qwen architecture, are specifically optimized for code-related tasks and designed to address the needs of developers seeking efficient and flexible solutions.
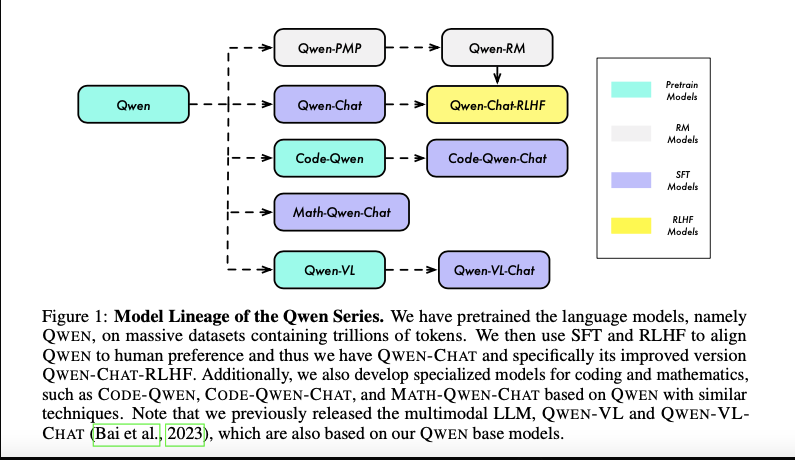
Key Features of the Qwen2.5-Coder Models
- Model Architecture:
- Built upon the Qwen2.5 architecture, the series spans six sizes: 0.5B, 1.5B, 3B, 7B, 14B, and 32B parameters. The architecture supports advanced features like Rotary Position Embeddings (RoPE) and Fill-in-the-Middle (FIM) tokenization for context-aware code generation.
- Larger models like Qwen2.5-Coder-32B include enhanced capacity with 64 layers and 8 key-value heads, optimizing long-context understanding and multitasking.
- Pretraining and Fine-Tuning:
- Trained on 5.5 trillion tokens from diverse datasets, including source code, text-code grounding data, synthetic code, and mathematics, Qwen2.5-Coder models balance coding expertise with general capabilities.
- Repo-level pretraining extends context length to 128K tokens, allowing the models to process large-scale projects effectively.
- Instruction tuning and Direct Preference Optimization (DPO) enhance alignment with coding tasks and reduce hallucinations in generated code.

To illustrate how Qwen2.5 can be applied in practical scenarios, here is an example of how to use the Qwen2.5-Instruct model with Hugging Face Transformers. This code snippet walks through setting up the model, creating prompts, and executing code generation tasks
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language models."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenizer=tokenizer,
add_generation_prompt=True
)
model_inputs = tokenizer(text, return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
This code snippet demonstrates how easily developers can leverage Qwen2.5 for natural language tasks. With just a few lines of code, the model is instantiated, prompted, and able to generate meaningful responses. The integration with Hugging Face's Transformers library makes deployment straightforward, adding accessibility for a wide range of developers.
- Specialized Tokenization:
1. The series introduces task-specific tokens like <|fim_prefix|> and <|repo_name|> to handle repository-level data and complex code structures efficiently.
Performance Insights
- Benchmarks:
- Achieves state-of-the-art results in code-specific benchmarks such as HumanEval and MBPP, outperforming larger proprietary models in specific tasks.
- The Qwen2.5-Coder-32B model surpasses DeepSeek-Coder-33B on key metrics like code generation and reasoning.
- Multi-Language Proficiency:
- Demonstrates versatility across programming languages, excelling in tasks involving Python, JavaScript, C++, and others.
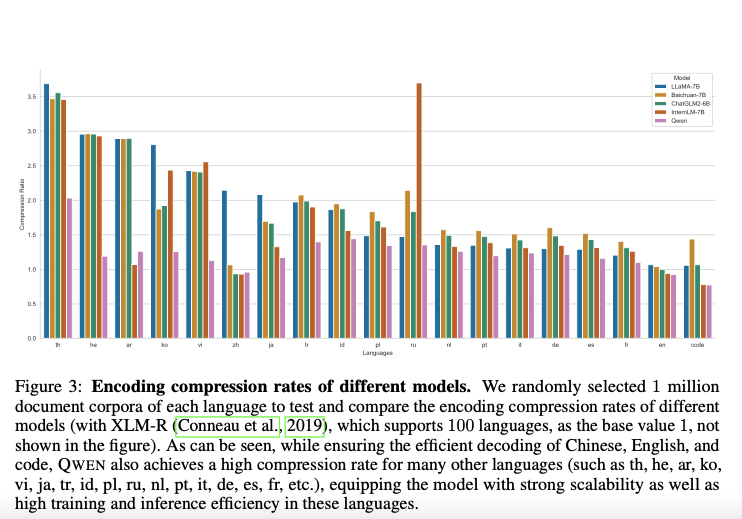
- Real-World Applications:
1. The Qwen2.5-Coder series integrates seamlessly into scenarios like code assistants, artifact generation, and software debugging, offering practical solutions for developers.
Challenges and Future Directions
While the Qwen2.5-Coder models push the boundaries of open-source CodeLLMs, challenges remain in scaling efficiently and matching the precision of proprietary counterparts like GPT-4. Future iterations aim to refine multilingual support, reduce token overhead, and enhance context handling.
Comparative Analysis: DeepSeek vs. Qwen
DeepSeek and Qwen represent two leading open-source initiatives in the CodeLLM ecosystem, each bringing unique innovations to the table. While both aim to empower developers by bridging the gap between open-source and proprietary models, they differ significantly in architecture, training methodologies, and practical applications.
Model Design and Architecture
- DeepSeek-Coder:
- Mixture-of-Experts (MoE) Framework:
- DeepSeek utilizes an MoE-based architecture, offering scalability and efficiency by activating subsets of parameters for specific tasks.
- Context Length:
- Supports a context length of up to 128K tokens, optimized for handling repository-level dependencies and long-context scenarios.
- Mixture-of-Experts (MoE) Framework:
- Qwen2.5-Coder:
- Dense Transformer Framework:
- Built on a dense transformer model with scalable architecture across multiple parameter sizes (0.5B to 32B).
- Tokenization Innovations:
- Introduces specialized tokens such as
<|repo_name|>and<|fim_middle|>to enhance context understanding and improve task-specific performance.
- Introduces specialized tokens such as
- Dense Transformer Framework:
Training and Data Strategies
- Data Composition:
- DeepSeek Coder leverages 10.2 trillion tokens across 338 programming languages, with a balanced mix of code, math, and natural language.
- Qwen2.5-Coder focuses on a curated dataset of 5.5 trillion tokens, emphasizing repository-level training with a balance of 70% code, 20% text, and 10% math.
- Training Objectives:
- DeepSeek employs a Fill-In-the-Middle (FIM) strategy, boosting code completion capabilities(DEEPSEEKCODERV2)(when the LLMs mEET pRO).
- Qwen2.5-Coder enhances instruction alignment using Direct Preference Optimization (DPO) and repository-level FIM for cross-file dependencies(Qwen2.5-Coder Technical…).
Performance Benchmarks
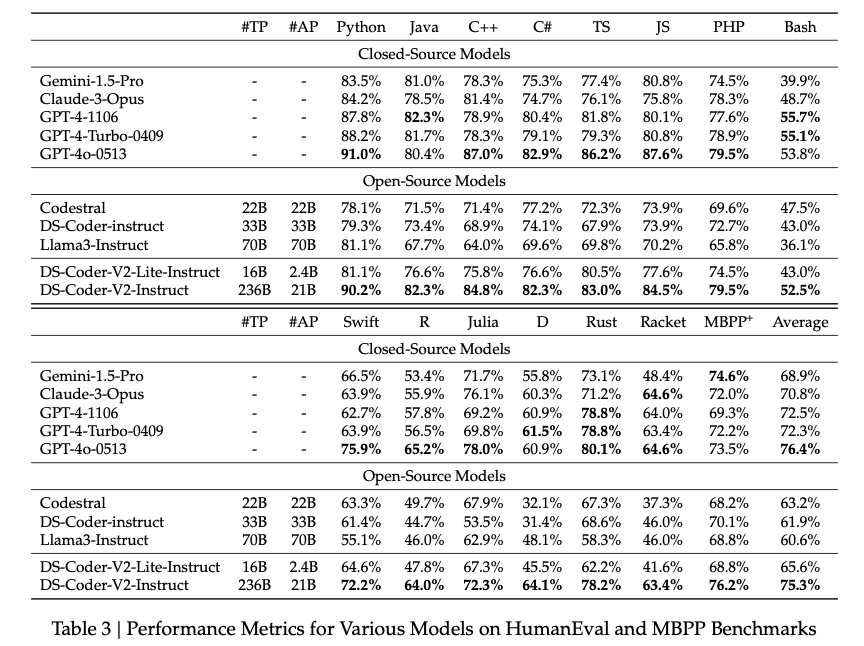
Code Generation:
- HumanEval:
- DeepSeek-Coder-33B achieves 90.2% accuracy, surpassing most open-source and proprietary models.
- Qwen2.5-Coder-32B scores 88.3%, reflecting robust performance with slightly fewer parameters.
- Multilingual Proficiency:
- DeepSeek supports 338 programming languages, offering broader applicability.
- Qwen demonstrates competitive results across eight core languages, such as Python, C++, and JavaScript, with a tailored multilingual instruction dataset.
- Code Completion:
- Qwen2.5-Coder excels in cross-file and repository-level completion, outperforming DeepSeek in long-context benchmarks like RepoEval.
Strengths and Limitations
- Strengths:
- DeepSeek:
- Superior long-context handling and multilingual coverage.
- Permissive licensing for commercial applications.
- Qwen:
- Advanced tokenization strategies and scalable architecture.
- DeepSeek:
- Limitations:
- DeepSeek: Higher computational requirements due to its MoE architecture.
- Qwen: Slightly behind in multilingual breadth compared to DeepSeek.
Challenges and Opportunities in Open-Source CodeLLMs
The open-source ecosystem for CodeLLMs has made significant strides, but it remains a field with both immense potential and notable challenges. Models like DeepSeek-Coder and Qwen2.5-Coder exemplify the progress achieved, yet their development highlights key areas that require attention to fully bridge the gap with proprietary solutions like GPT-4 and Claude.
Key Challenges
- Scalability and Resource Demands:
- Training large open-source models necessitates extensive computational resources and robust datasets. Models like DeepSeek-Coder and Qwen2.5-Coder have demonstrated performance comparable to proprietary models, but scaling these models beyond 33B and 32B parameters, respectively, is resource-intensive.
- Data Curation and Quality:
- Open-source models rely on publicly available datasets, which may lack the depth and quality of proprietary datasets. For instance, while Qwen employs advanced data-cleaning pipelines, challenges persist in balancing diverse programming languages and maintaining data quality at scale.
- Ethical and Legal Considerations:
- The permissive licenses that enable open-source innovation also pose risks of misuse. Furthermore, ensuring datasets are free from copyrighted or sensitive content remains a challenge.
- Performance Parity with Proprietary Models:
- While benchmarks like HumanEval and MBPP show competitive results, achieving equivalent performance across diverse real-world tasks, especially in multilingual and multi-modal settings, remains difficult for open-source models.
- Adoption Barriers:
- Despite their potential, many open-source models face adoption barriers due to complex configurations, insufficient documentation, or lack of enterprise-grade features like integrated APIs.
Opportunities for Growth
- Collaborative Ecosystems:
- Open-source communities thrive on collaboration. Initiatives like DeepSeek and Qwen can benefit from partnerships with academic institutions, cloud providers, and developers to share resources and drive innovation.
- Focus on Specialized Use Cases:
- Targeting niche domains, such as repository-level code understanding or multi-lingual programming support, can help open-source models establish leadership in areas where proprietary solutions are less effective.
- Advances in Fine-Tuning and Alignment:
- Techniques like Direct Preference Optimization (DPO) and reinforcement learning offer pathways to refine open-source models for specific applications, narrowing the performance gap with proprietary alternatives.
- Accessible Deployment Solutions:
- Simplifying model deployment with containerized solutions, accessible APIs, and integration with popular development platforms (e.g., VS Code) can lower adoption barriers and encourage broader use.
- Ethical Leadership in Open-Source AI:
- Open-source initiatives can lead the way in transparent AI practices, ensuring models are free from bias and aligned with ethical guidelines. This can establish trust and differentiate open-source solutions from opaque proprietary systems.
The Road Ahead: Unified Progress in Open-Source Code Intelligence
The journey of open-source CodeLLMs, epitomized by models like DeepSeek-Coder and Qwen2.5-Coder, underscores the transformative potential of collaborative, transparent AI development. While the models discussed in this article represent the cutting edge of open-source innovation, they are also a testament to the challenges and opportunities that define the field’s future.
Emerging Opportunities in Open-Source Code Intelligence
- Advanced Repository-Level Understanding:
- DeepSeek’s repository-level training and Qwen’s multi-file optimization strategies point towards a future where models can seamlessly navigate complex dependencies across entire projects.
- Anticipated advancements could lead to the development of models capable of providing project-wide code insights, enhancing productivity and reducing errors.
- Scalable Specialization:
- As demonstrated by Qwen’s multilingual capabilities and DeepSeek’s FIM strategies, the next generation of CodeLLMs could focus on tailored solutions for niche domains such as embedded systems, secure coding practices, or specialized programming languages.
- Enhanced Fine-Tuning Techniques:
- Combining innovative instruction tuning, DPO (Direct Preference Optimization), and human feedback could further align models with real-world coding tasks, creating adaptive systems capable of addressing developer needs dynamically.
Challenges to Overcome
- Data Accessibility and Ethics:
- Ensuring high-quality, unbiased datasets remains a critical hurdle. Future models must prioritize ethical sourcing and inclusivity to maintain trust and utility across diverse developer communities.

- Performance vs. Scalability:
- While open-source models like Qwen2.5-Coder and DeepSeek-Coder demonstrate remarkable performance, achieving consistent scalability without sacrificing efficiency remains a pressing challenge.
- Community-Driven Innovation:
- Fostering a robust ecosystem of contributors is essential. Open-source initiatives must incentivize collaboration through transparent licensing and accessible tooling.
Towards a Collaborative Ecosystem
The future of open-source CodeLLMs lies in building a collaborative ecosystem that bridges the performance gap with proprietary counterparts while offering unparalleled accessibility and transparency. By leveraging the strengths of community-driven development and prioritizing ethical AI practices, models like DeepSeek and Qwen can redefine how developers approach code intelligence.
References:

https://arxiv.org/pdf/2406.11931
https://arxiv.org/pdf/2401.14196
https://arxiv.org/pdf/2409.12186