Prem-1B-SQL: Fully Local Performant SLM for Text to SQL

Last week, we open-sourced PremSQL, a local first library that created customized Text-to-SQL solutions. When deploying RAG-based services (whether on documents or databases) for enterprises, it becomes crucial that the underlined data is not exposed to third-party APIs. With PremSQL, you can use our ready-made pipelines or customize and create your own Text-to-SQL pipelines and models on your private databases. Don't forget to give a star to our GitHub repository.
 Anindyadeep Sannigrahi
Anindyadeep Sannigrahi
Today, we release Prem-1B-SQL, our first fine-tuned Small Language Model dedicated to generating SQL from natural language queries. It is a 1.3B paramter model fully-finetuned from DeepSeek-1.3B. This blog will discuss the benchmark result on standard Text-to-SQL tasks and share our fine-tuning process and all the learnings. Prem-1B-SQL is available to use in huggingface.
Prem-1B-SQL is loved by the open source community. We reached more than 10K+ monthly downloads on Hugging Face and also 8K+ PremSQL library downloads. Checkout our model to learn more.

Evaluation procedure
In the general Text-to-s SQL evaluation process, we start with a model we want to evaluate. We pass the model to popular evaluation datasets (like BirdBench or Spider), where a user query and the database schema are passed along. The model generates an SQL query, which is then executed in the database. We check if the execution is done successfully and whether the retrieved answer matches the actual answer. Typically, three types of metrics are used for the evaluation process.
- Execution Accuracy: Execution accuracy is just a normal accuracy metric. It is considered to be correct if the table from LLM-generated SQL matches the gold SQL.
- Valid Efficiency Score: This metric asses the relative execution efficiency of the model vs the actual ground truth SQL. So if the execution accuracy is one, then it tries to measure the ratio of execution efficiency (time required to execute) by both SQLs.
- Soft-F1 score: This is the standard F1 score.
If you want to know more about the evaluation process and how you can do evaluations with premSQL, check out our documentation
Evaluation Scores
We evaluated our model on two popular benchmark datasets: BirdBench and Spider. BirdBench consists of a public validation dataset (with 1534 data points) and a private test dataset. Spider comes up with only a public validation dataset. Here are the results:
| Dataset | Execution Accuracy |
|---|---|
| BirdBench (validation) | 46% |
| BirdBench (private test) | 51.54% |
| Spider | 85% |
The BirdBench dataset is distributed across different difficulty levels. Here is a detailed view of the private results across different difficulty levels. (The Data is based on the current BirdBench leaderboard.)
| Difficulty | Count | EX | Soft F1 |
|---|---|---|---|
| Simple | 949 | 60.70 | 61.48 |
| Moderate | 555 | 47.39 | 49.06 |
| Challenging | 285 | 29.12 | 31.83 |
| Total | 1789 | 51.54 | 52.90 |
Our model hallucinates more with increasing difficulty. The coming sections discuss a more detailed error observation. Here is a more detailed comparison of popular closed- and open-source models.
| Model | # Params (in Billion) | BirdBench Test Scores |
|---|---|---|
| AskData + GPT-4o (current winner) | NA | 72.39 |
| DeepSeek coder 236B | 236 | 56.68 |
| GPT-4 (2023) | NA | 54.89 |
| PremSQL 1B (ours) | 1 | 51.4 |
| Qwen 2.5 7B Instruct | 7 | 51.1 |
| Claude 2 Base (2023) | NA | 49.02 |
Here is the graph plot for the above Table

We are excited to share that we are the first 1B parameter model to achieve 50% accuracy on the BirdBench private dataset, surpassing the Claude 2 Baseline and just below the GPT-4 baseline results. It also performs better than Qwen 2.5-coder 7B-instruct (a recently released 7B parameter model). In the future, we are aiming for much higher scores. We are just getting started.
Inference approach of Prem-1B-SQL
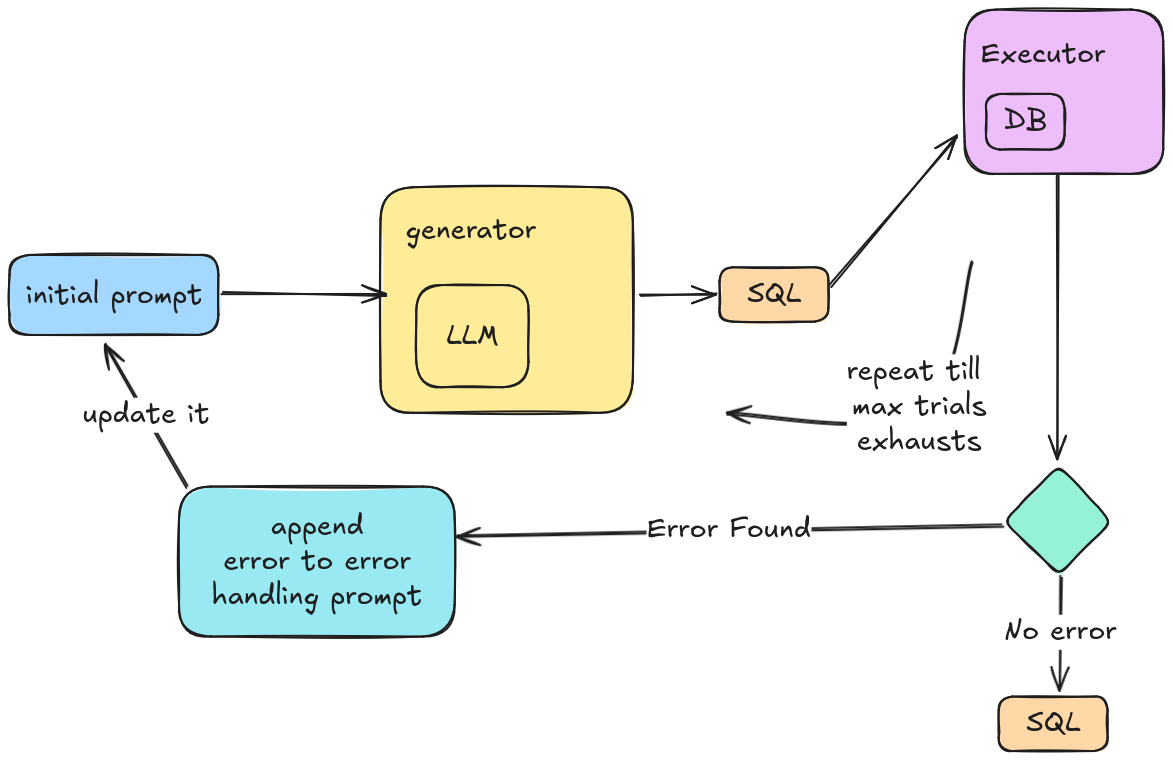
Our inference approach (which was also submitted to BirdBench private evaluation) was fairly simple. Once our model was correctly fine-tuned, we used execution-guided decoding as our primary method for making inferences. We start with a simple baseline prompt (containing the database schema, proper instruction, and the user's query) and pass it on to our SLM.
We get an SQL query back and execute the SQL to our target database. If there is an error in execution, we collect the error, append it to the prompt (and make an error-handling prompt) and then pass it to the SLM (this time, it is instructed to correct itself from the old SQL query) and again, we generate the SQL. This thing happens till the max retries get exhausted (by default, it is set to 5). Here is a diagram to understand it in more detail:
You can even use this for your use case with PremSQL. Here is the code snippet for that.
from premsql.generators import Text2SQLGeneratorHF
from premsql.executors import SQLiteExecutor
executor = SQLiteExecutor()
generator = Text2SQLGeneratorHF(
model_or_name_or_path="premai-io/prem-1B-SQL",
experiment_name="test_generators",
device="cuda:0",
type="test"
)
question = "show me the yearly sales from 2019 to 2020"
db_path = "some/db/path.sqlite"
response = generator.generate(
data_blob={
"prompt": question,
"db_path": db_path,
},
temperature=0.1,
max_new_tokens=256,
executor=executor,
)
print(response)
You can learn more about generation approaches in our documentation. This approach, although simple, works well.
We have seen that we gained almost 3-4% when using execution-guided decoding compared to when we did not. Besides execution-guided decoding, we also experimented with multi-beam decoding (where we choose the beam that either has max cumulative log probability or produces the same table as the other). However, this approach did not work well, so we skipped it since it was an extra overkill with very little outcome.
Fine-tuning Prem-1B SQL and Key Learnings
Prem-1B SQL is based on the DeepSeek Coder 1.3B model. We fully fine-tuned the model to focus on the Natural Language to SQL (NL2SQL) task. This section will discuss the dataset preparation process and the settings used during the fine-tuning procedure.
Datasets
Text-to-SQL is quite different from other generative language modelling tasks. It is an accuracy-first problem, meaning that the goal is not to generate "SQL-like" strings but efficient executable SQL queries that retrieve the correct data or tables.
When working with small open-source models, the dataset's quality is crucial. To achieve our current results, we used a combination of real and synthetic datasets, including the following:
- BirdBench Training Dataset (provided by the BirdBench community)
- Spider Training Dataset (includes Spider Realistic, Spider DK, Spider Syn, Dr. Spider)
- Bank Financials and Aminer Simplified Datasets (we collectively refer to these as "Domains")
- GretelAI Synthetic Dataset: We used a subset of GretelAI’s open-source synthetic Text-to-SQL dataset.
Our prompt structure was simple: we appended the database schema and any additional DB/domain-specific information, followed by the user’s query at the end. All these datasets are available under the PremSQL datasets.
Additionally, we created an error-handling dataset by evaluating our early fine-tuned model on the BirdBench, Spider, and Domains training datasets. The evaluation was not to measure performance but to collect different errors, such as column mismatches, table mismatches, and syntax errors. These errors were appended to an error-handling prompt, which included the base prompt, the wrong SQL string generated by the model, the error message, and a request for correction.
In total, we fine-tuned the model on around 122,420,557 tokens. Let's now discuss our fine-tuning approach and the lessons learned.
Fine-tuning Setup and Key Learnings
We used Hugging Faces transformers library to fully fine-tune the DeepSeek 1.3B Instruct model. The context length was set to 1024. Fine-tuning was conducted using Distributed Data Parallel (DDP) on 4 A100 GPUs, with a batch size 4 per device. We trained the model for approximately 6,000 steps. During the process, we periodically evaluated it on a small subset of the BirdBench validation set using PremSQL’s custom evaluation callback, specifically designed for text-to-SQL tasks.
We experimented with various base instruct models like Google's Gemma-2B and IBM's Granite-3B but observed limited improvements with those models. The DeepSeek-1.3B model, however, yielded the best performance.
During fine-tuning, we achieved validation accuracy between 43-45% on the BirdBench public validation dataset, with the following accuracy distribution across different difficulty levels:
- Simple: 50.16%
- Moderate: 33.62%
- Challenging: 26.89%
The validation dataset contained 1,534 samples, with the following results:
- 1,278 SQL generations were error-free.
- Of these, 659 were correct (i.e., the generated SQL returned the same results as the ground truth).
- 619 were incorrect, likely due to reasoning errors (i.e., the SQL executed without syntax errors but returned incorrect results).
- 256 SQL generations contained syntax-based errors.
- 237 of these errors were "No such column" errors, where the model hallucinated column names (e.g., generating "PersonAge" instead of the correct "Person Age").
- The remaining 19 were other syntax-related errors.
These numbers were significantly worse before introducing the error-handling dataset, which led to a notable improvement in performance.
One important lesson we learned is that model performance can sometimes be parameter-agnostic. For instance, we expected the IBM-Granite-3B-Coder model to outperform DeepSeek-1.3B, but it did not. Similarly, the Google-Gemma 2B model failed to deliver better results. We also observed that smaller language models struggle with generalization. These models may perform poorly when applied to private datasets outside of their training distribution.
Conclusion
Our primary objective was to build a local-first solution for text-to-SQL tasks. Today, we are proud to release the first version of PremSQL, along with the performant 1B parameter Text-to-SQL model. We chose a 1B parameter model because it is small, resource-efficient, and fast. We plan to scale up to a 7B parameter model and continue improving.
Future releases will focus on enhanced agentic inference methods and synthetic data generation techniques to align the model with more diverse datasets. Additionally, we will introduce new features to the PremSQL library.
Stay tuned for updates, and try out the model with your databases. Star our repository, and feel free to open issues for feature requests or bug reports.
Until next time!
