RAGs are cool, but what about their privacy?
This article explores privacy concerns in Retrieval-Augmented Generation (RAG) applications, highlighting data protection challenges and offering actionable solutions to ensure secure and compliant AI systems while leveraging the benefits of RAG.
With the boom of Generative AI and Large Language Models, RAG or Retrieval Augmented Generations are playing a major role in question answering on private documents. A huge number of practitioners are turning to hosted vector database services (like PineCone, Weaviate, Milvus, etc) to execute embedding searches at scale. For privacy-focused use cases, the data owners mostly send the embeddings of text data to the service and keep the data with themselves. But suppose today someone gets access to the embeddings and if they manage to reverse the embedding back to the text, then the person can get access to all the sensitive information without breaching the actual private data source. Scary 😱 but is this even possible? This blog post discusses that in a brief. You will also learn:
- What is Embedding Inversion
- Vec2Text model
- Results of the model.
- A case study of MMIC dataset.
- Defense again embedding inversion attacks.
- Try it yourself.
- Conclusion and future research scopes.
- References.
TLDR: The paper "Text Embeddings Reveal Almost as Much as Text" by Cornell University researchers offers a startling insight into text embeddings' privacy implications. It demonstrates that contrary to popular belief, dense text embeddings can reveal a significant portion of the original text. The paper introduces an innovative multi-step method, "Vec2Text", capable of reconstructing up to 92% of 32-token text inputs exactly, raising significant privacy concerns for embedding-based applications.
🙃 Embedding Inversion
The problem of embedding inversion is to reconstruct the full text from dense text embeddings. Traditional naive models perform poorly at this task. This paper frames this as a multi-step controlled generation problem where the goal is to generate the best approximation of text from a given embedding.
👋 Say Hi, to Vec2Text
High level this is how the algorithm works during training; For each example in our dataset
- First, get the target embedding from the target text (the embedding that we want to invert).
- Start with an initial hypothesis generation (for simplicity think of it as a random set of tokens) and convert it to its embedding using the target embedding model.
- Feed the initial hypothesis embedding, the target embedding, and the difference between the target and hypothesis embedding into three different neural networks to undergo some transformations.
- Concatenate the representations of all three embeddings and pass them to a Seq2Seq transformer model (here Google-T5 was used) and decode the text.
- Compute the standard language modeling loss with the newly decoded text (correct hypothesis) and the target text.
- Get the embedding of the new decoded text (corrected hypothesis) replace the previous text and embedding, with the new ones, and prepare for the next iteration.
- Repeat the above steps till the re-constructed text closely aligns with the original text.
During the time of inference, you will not be given the target text, rather you will have access to the unknown embedding and the embedding model. So then you will start with that and try to re-construct the text from the given unknown embedding.
Here is the annotated figure that helps to understand the model and the algorithm from the paper.
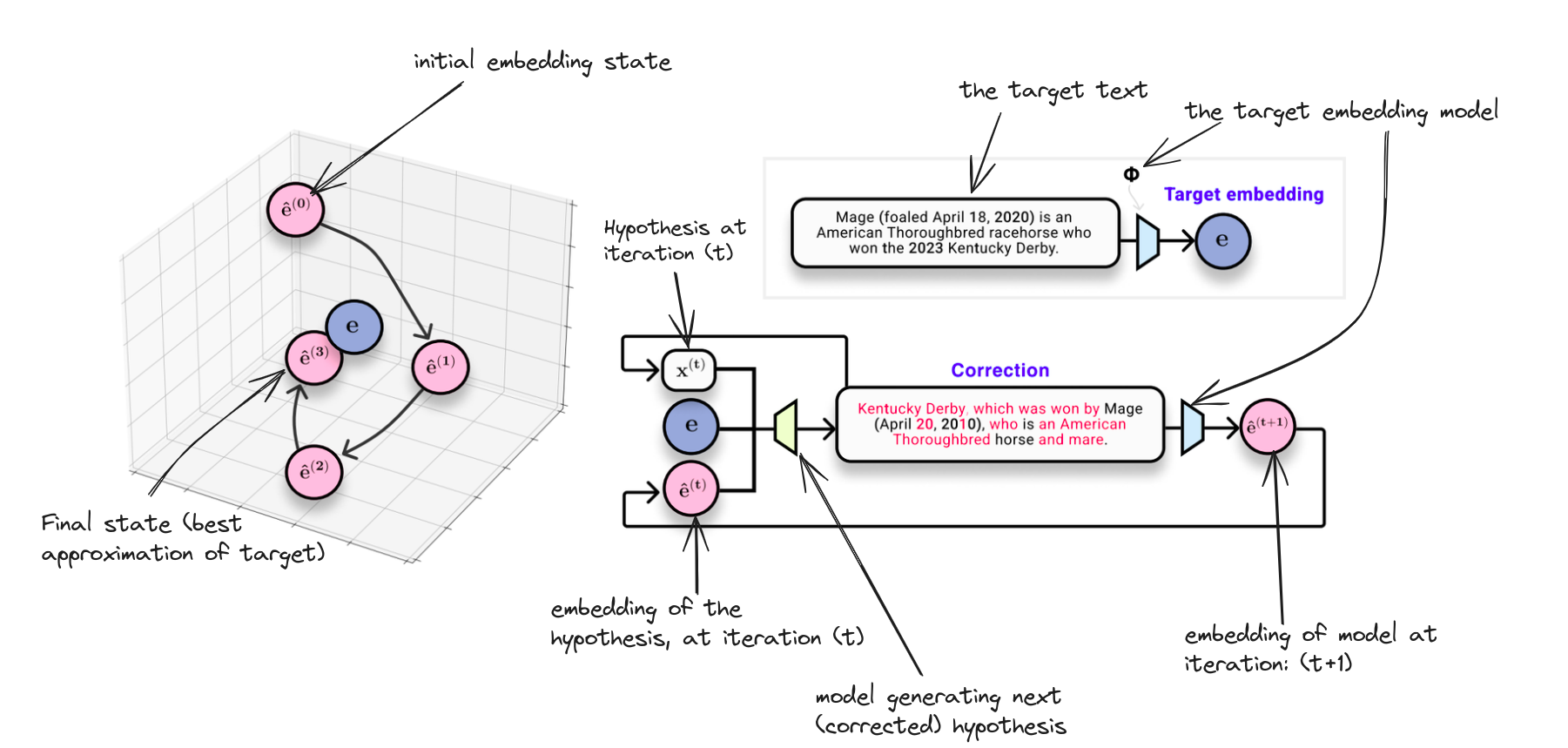
So to recap, at every step (t), start with an initial hypothesis sequence (x_t) and its embedding (e_t) and target embedding (e). Pass the whole (concatenated encoded) representation inside the transformer encoder-decoder model. Get the generated text, and train using standard language modelling loss. Finallyt, update the initial embedding and hypothesis text with the newly generated text and its corresponding embedding embedded by the target embedded model.
Here is a more simplified diagram of the above example:
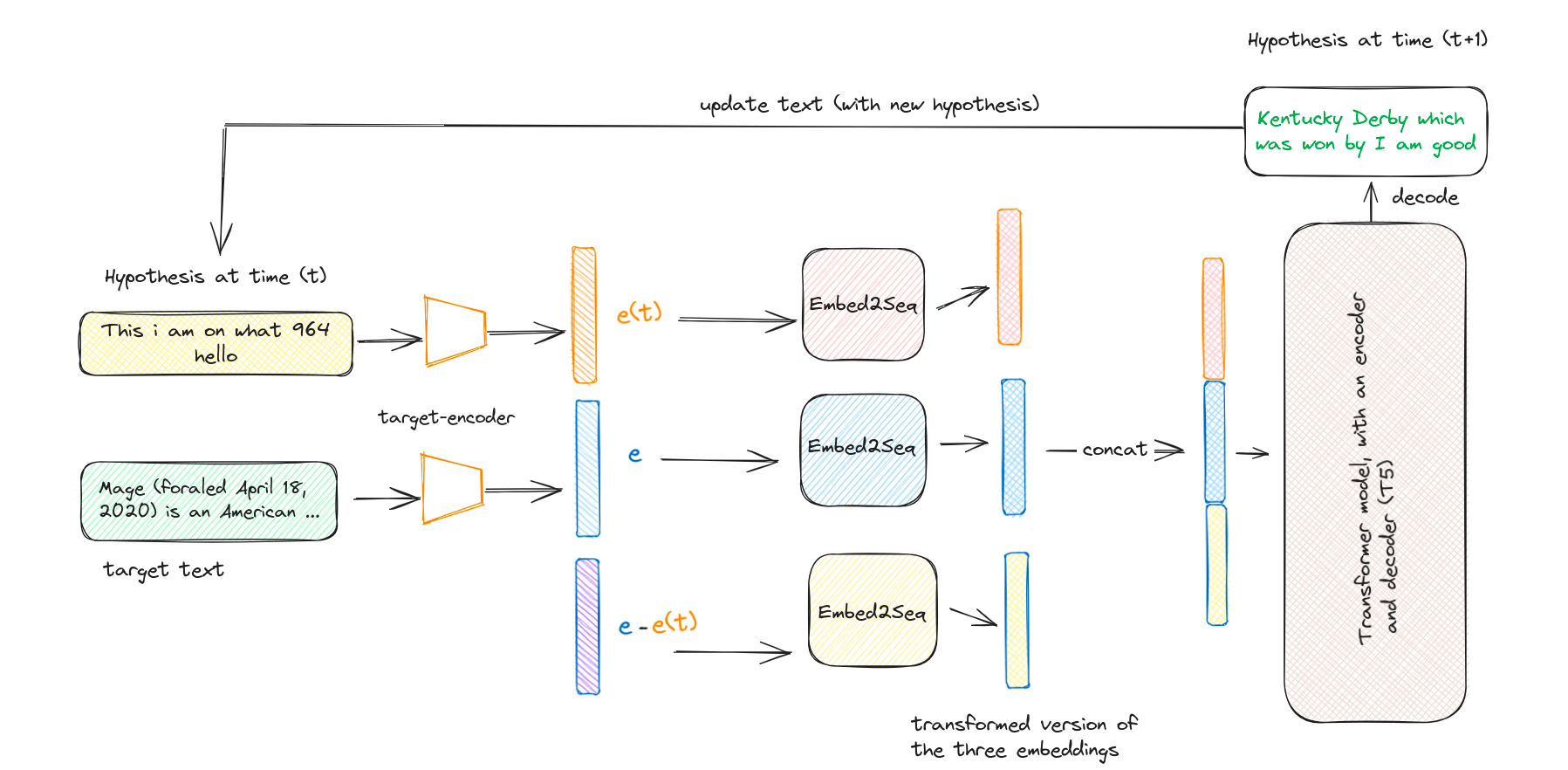
Here Embed2Seq is nothing but, think of it as a transformation by a Neural Network. For each of the three embeddings, three different neural networks were used for transformations.
Results of this model
The researchers tested their approach on various datasets, including clinical notes, and embedding models like GTR-base and OpenAI API. The results were astounding, with a 92% exact match and a 97 BLEU score in many cases. Interestingly, the reconstruction ability was robust even for out-of-distribution data, though performance slightly decreased with longer text sequences. Here is a table from the paper, for more details on the metrics.
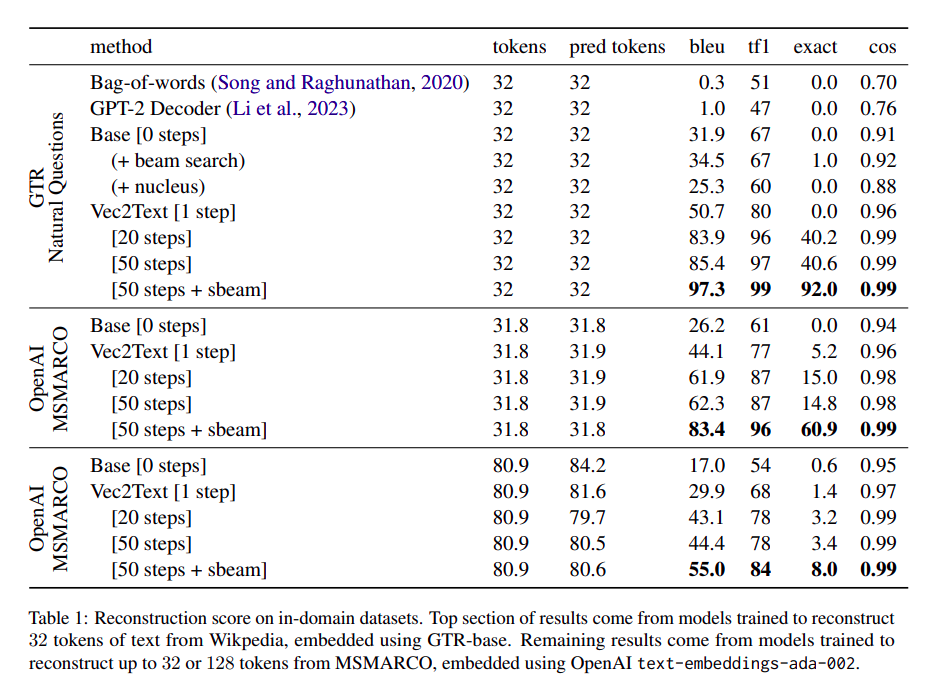
The above figure shows the evaluation results for various In-Domain (sets of data that have very similar types of examples or distribution to the training data). Not only that, this model also shows promising results (66% recovery from the Quora dataset belonging to the BEIR benchmark, and cosine similarity of over 0.95 to the true embeddings for all the datasets belonging to the BEIR benchmark.) for out-of-domain (data with very little similarity or falling under a different distribution than training).
MIMIC Case study
Now, here things become scarier, as this case study sheds some light on what can happen in some practical scenarios. The MIMIC III clinical notes is a large freely available database comprising unidentified (the personal info is masked) health-related data associated with over forty thousand patients who stayed in critical care units. For testing the authors used "pseudo re-identified" (the masked personal info is replaced with some fake/dummy info). This data is used for testing Vec2Text and the figure below shows some astounding results:
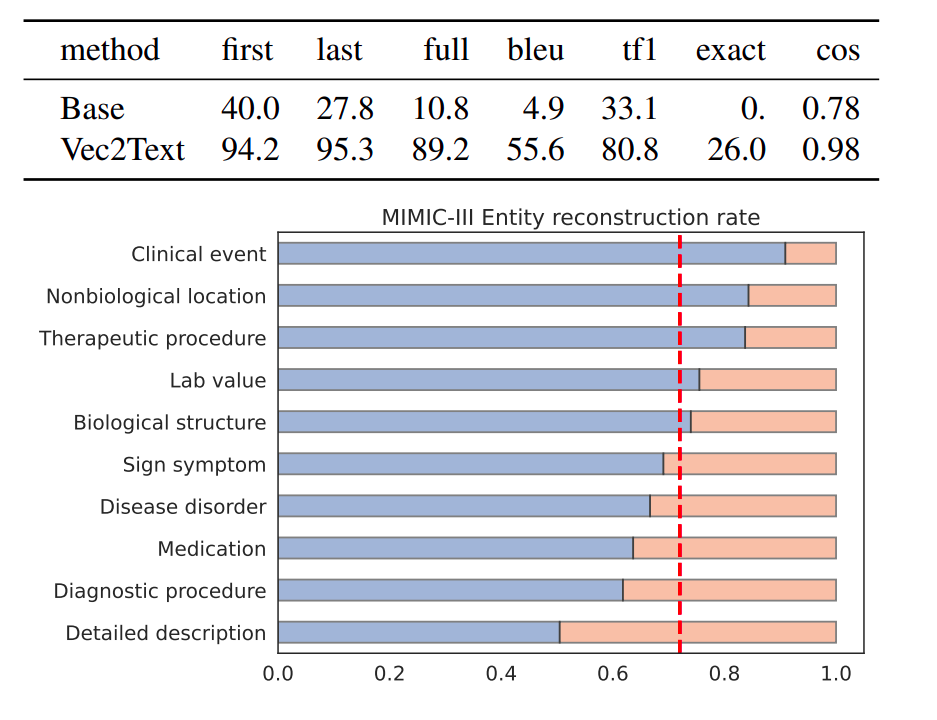
As you can see, Vec2Text can recover 94% of the first names of the patients, 95% of the last names, and around 89% of the last names. Also, it was able to recover 26% of the overall documents exactly.
Defense against this inversion attacks
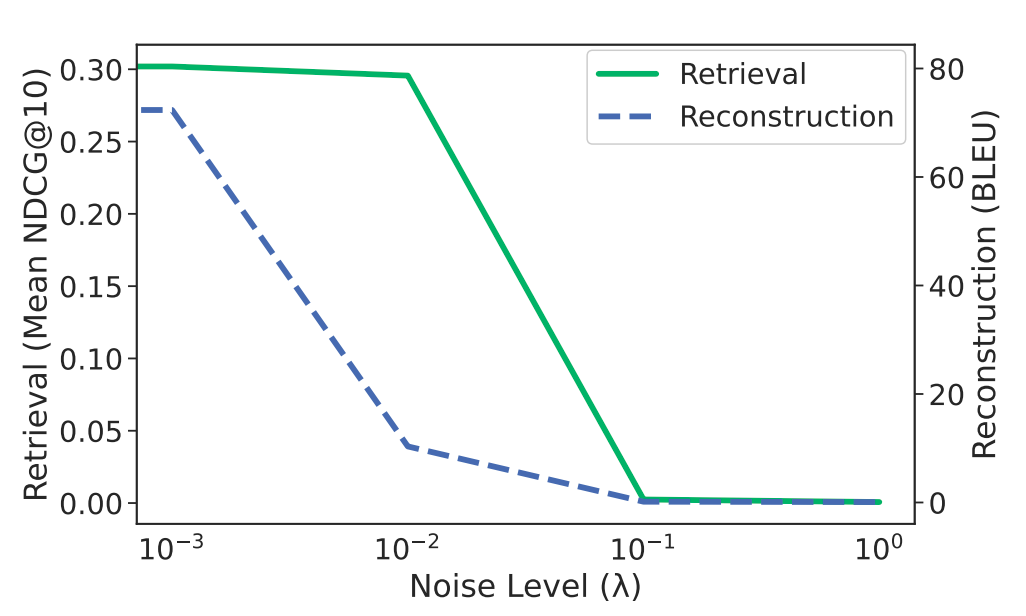
The authors did an amazing job of not only finding out the problem with embeddings and RAG-based systems but also documenting some baseline methods to defend against privacy invasion. One of the ways to implement defense is to add some level of Gaussian noise directly to each embedding where the goal is to defend the inversion attacks but also to keep the properties of embedding (similar text should stay together in embedding space) preserved. However, this comes with an unavoidable tradeoff shown in the graph below:
🕵 Try it yourself
Vec2Text also has its implementation in this GitHub repository. You can get started by simply installing the vec2text package.
pip install vec2textBelow is a simple example of how you can re-construct the embeddings formed by text-embedding-ada-002, which is a closed-source Open AI embedding model.
import torch
def get_embeddings_openai(text_list, model="text-embedding-ada-002") -> torch.Tensor:
response = openai.Embedding.create(
input=text_list,
model=model,
encoding_format="float", # override default base64 encoding...
)
outputs.extend([e["embedding"] for e in response["data"]])
return torch.tensor(outputs)
embeddings = get_embeddings_openai([
"Jack Morris is a PhD student at Cornell Tech in New York City",
"It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity"
])
vec2text.invert_embeddings(
embeddings=embeddings.cuda(),
corrector=corrector
)Here are the results:
['Morris is a PhD student at Cornell University in New York City',
'It was the age of incredulity, the age of wisdom, the age of apocalypse, the age of apocalypse, it was the age of faith, the age of best faith, it was the age of foolishness']Shocking right!!! Try more examples by visiting their repo.
💡Conclusion and Future Research Scope
Although this paper has shown great potential in how embedding inversion can turn out to be a huge threat to privacy in RAG-based applications. This paper also comes with some potential challenges as follows:
- All of the experimentations were done with 32 tokens text input length. With the increase in the number of tokens, the reconstruction loss was getting high and hence quality was affected.
- The current Vec2Text model gets affected by the addition of Gaussian noise (also acting as a defense mechanism), however future work of this paper mentions to adapt with these noises or defenses.
- The model in the paper (threat model) assumes that the advisory has black-box access to the model used to generate the embeddings. This is a realistic assumption, since in the real world, practitioners rely on a few large open-source or closed-source models. However future work aims to put out a more generalized approach that is robust and agnostic to embedding access.