
Privacy-Preserving LLM Inference

Today, when enterprises send prompts to cloud LLMs, those prompts are visible to the provider. For many use cases this is acceptable. For healthcare, legal, and financial applications, it often isn't.
For the last 18 months, we've been working on this problem at Prem, recently completed a technical survey of the approaches that exist for privacy-preserving LLM inference in collaboration with our research partners SUPSI: Scuola universitaria professionale della Svizzera italiana in Lugano.
The goal of this study was to understand what's actually possible today, what the trade-offs are, and where the field privacy-preserving AI is heading. Today, we're publishing it as a white-paper for our community to be informed and for independent research teams to build on top of.
The core question is whether it's possible to run large generate models (LLMs, STT, TTS, etc) in the cloud such that no one except the end user can access the prompts or responses. Not through policy commitments, but through technical guarantees.
The landscape
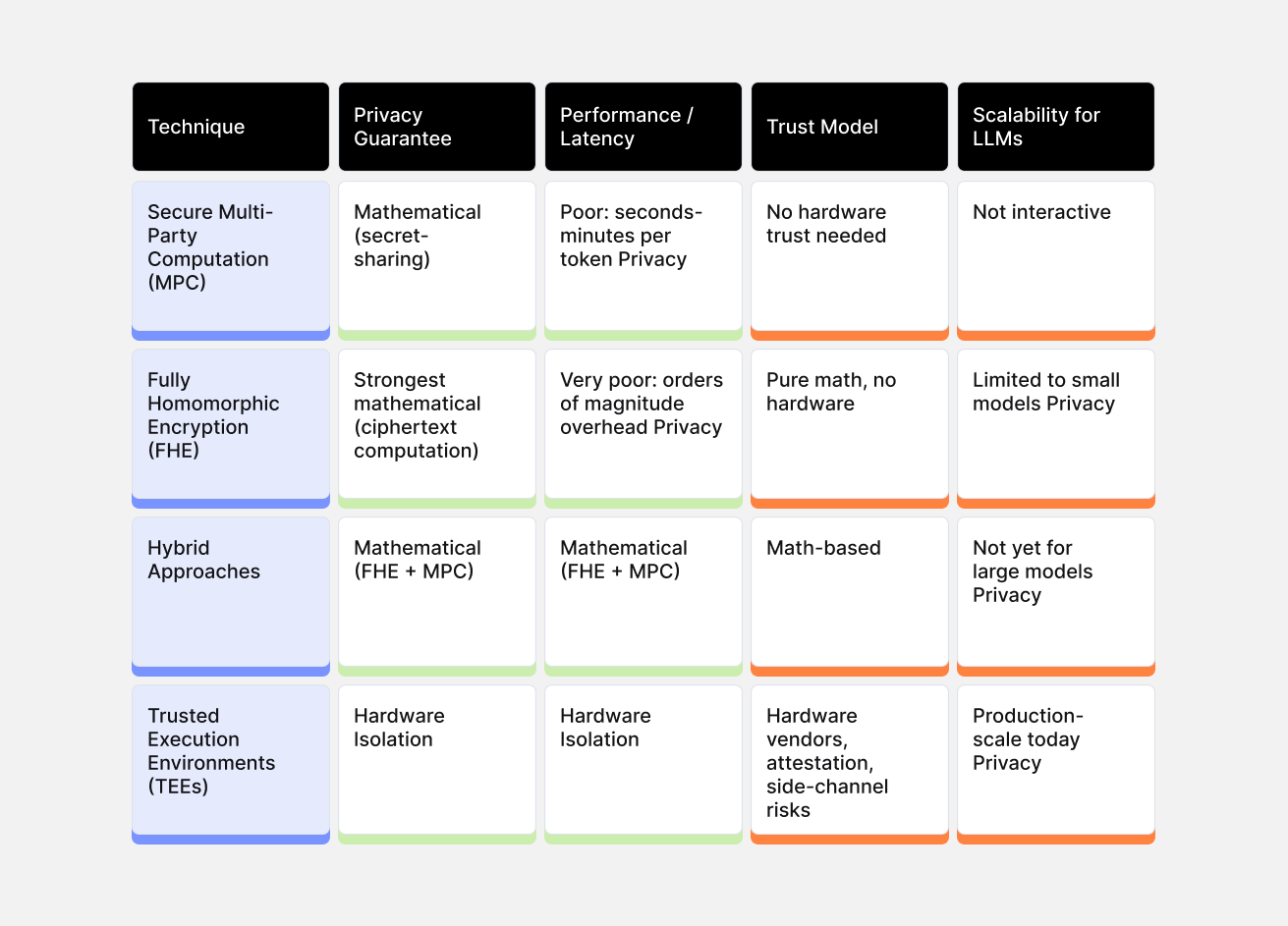
Over the last few years, teams have taken different approaches to enabling privacy-preserving AI inference, though none have reached definitive consensus. Four techniques have emerged as the most promising:
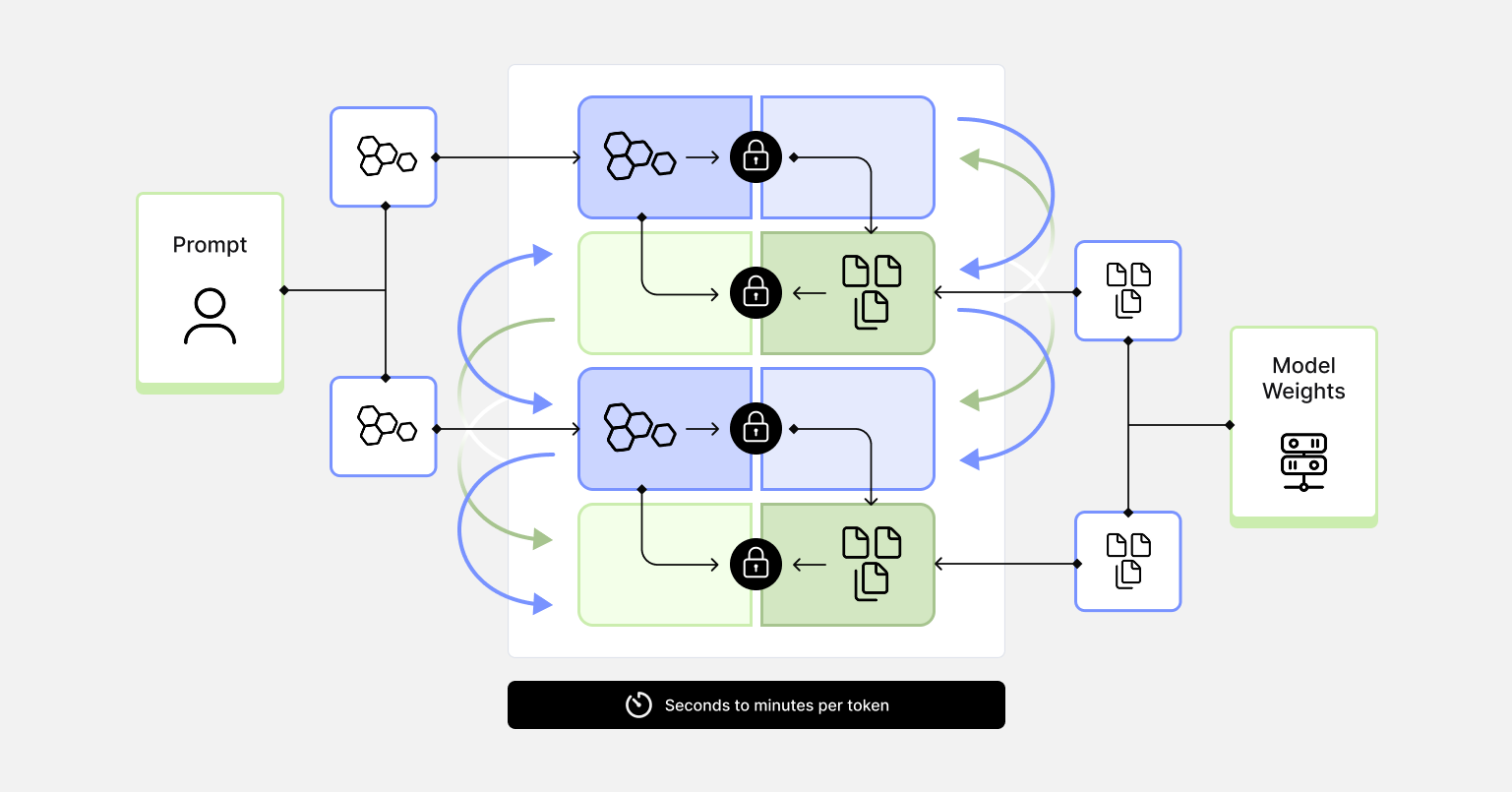
- Secure Multi-Party Computation: allows the user and provider to jointly compute inference without either party seeing the other's data in plaintext. MPC protocols allow two or more parties, typically a client holding a private prompt and a server holding private model parameters, to jointly compute inference without either party seeing the other's data in plaintext. The computation is performed over secret-shared values, meaning no single party ever possesses enough information to reconstruct the sensitive inputs. While the cryptographic guarantees are strong, but latency remains a significant barrier. Current systems require seconds to minutes per token for large models, which rules out interactive applications.
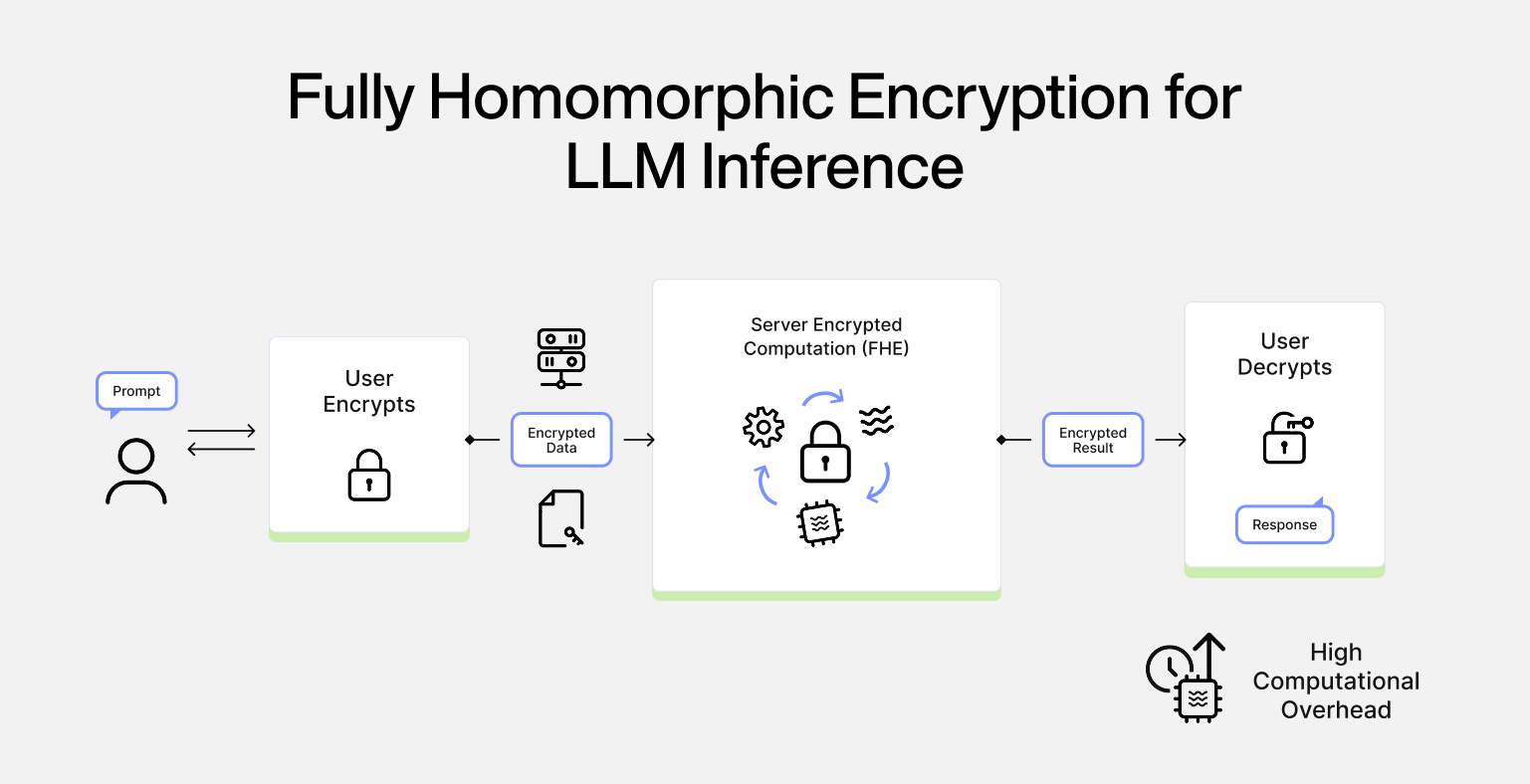
- Fully Homomorphic Encryption: enables computation directly on encrypted data without ever decrypting it. The client encrypts their prompt, sends it to the server, the server evaluates the entire model homomorphically over ciphertexts, and returns an encrypted result that only the client can decrypt. The server learns nothing not the input, not the output, not even intermediate activations. While this is the theoretical ideal, the computational overhead currently limits practical applications to smaller models and shorter sequences. Homomorphic operations are orders of magnitude more expensive than their plaintext equivalents. Non-linear functions must be approximated by low-degree polynomials, and accumulated noise in ciphertexts requires periodic "bootstrapping" operations that are themselves costly.
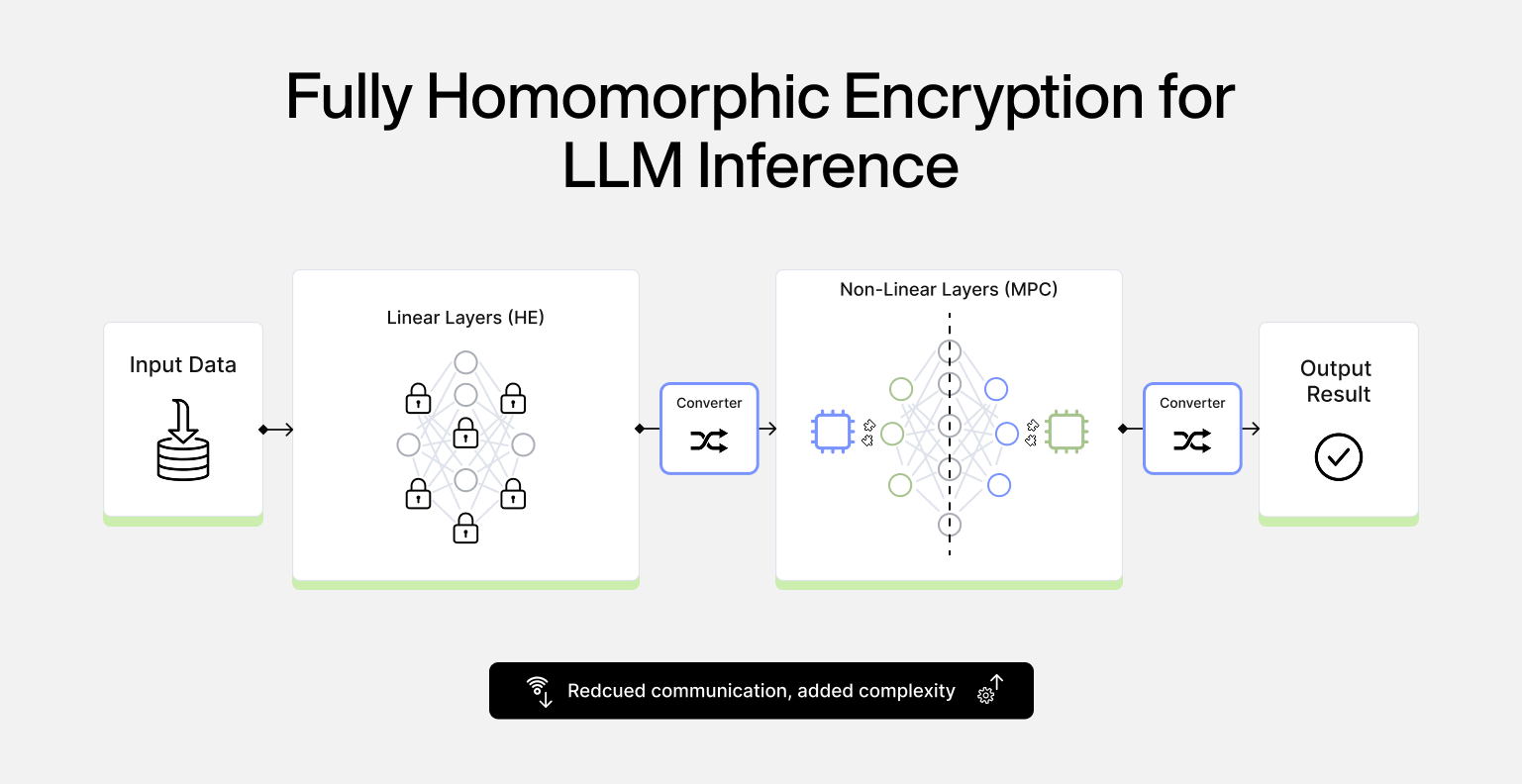
- Hybrid Approaches: combine homomorphic encryption for bandwidth-heavy linear layers with MPC for non-linear operations, exploiting the complementary strengths of each paradigm. Large matrix multiplications which dominate the computational cost of Transformers can be evaluated homomorphically with efficient SIMD-style packing, reducing the communication overhead that plagues pure MPC. Meanwhile, comparisons, activations, and decoding logic remain in MPC, where they can be handled with well-understood interactive protocols. These reduce communication costs compared to pure MPC, but add protocol complexity and don't yet achieve production-grade latency for large models.
- Trusted Execution Environments: take a different approach. Instead of cryptographic computation, TEEs use hardware isolation to create protected enclaves that are isolated from the rest of the system, including the operating system. The model runs in plaintext inside the enclave, but nothing outside can access that memory or execution state. The workflow relies on remote attestation: before sending any sensitive data, the client verifies that the expected code is running inside a genuine TEE. Only then are session keys provisioned and an encrypted channel established. Prompts are decrypted exclusively inside the enclave, processed in plaintext, and completions are encrypted before leaving.
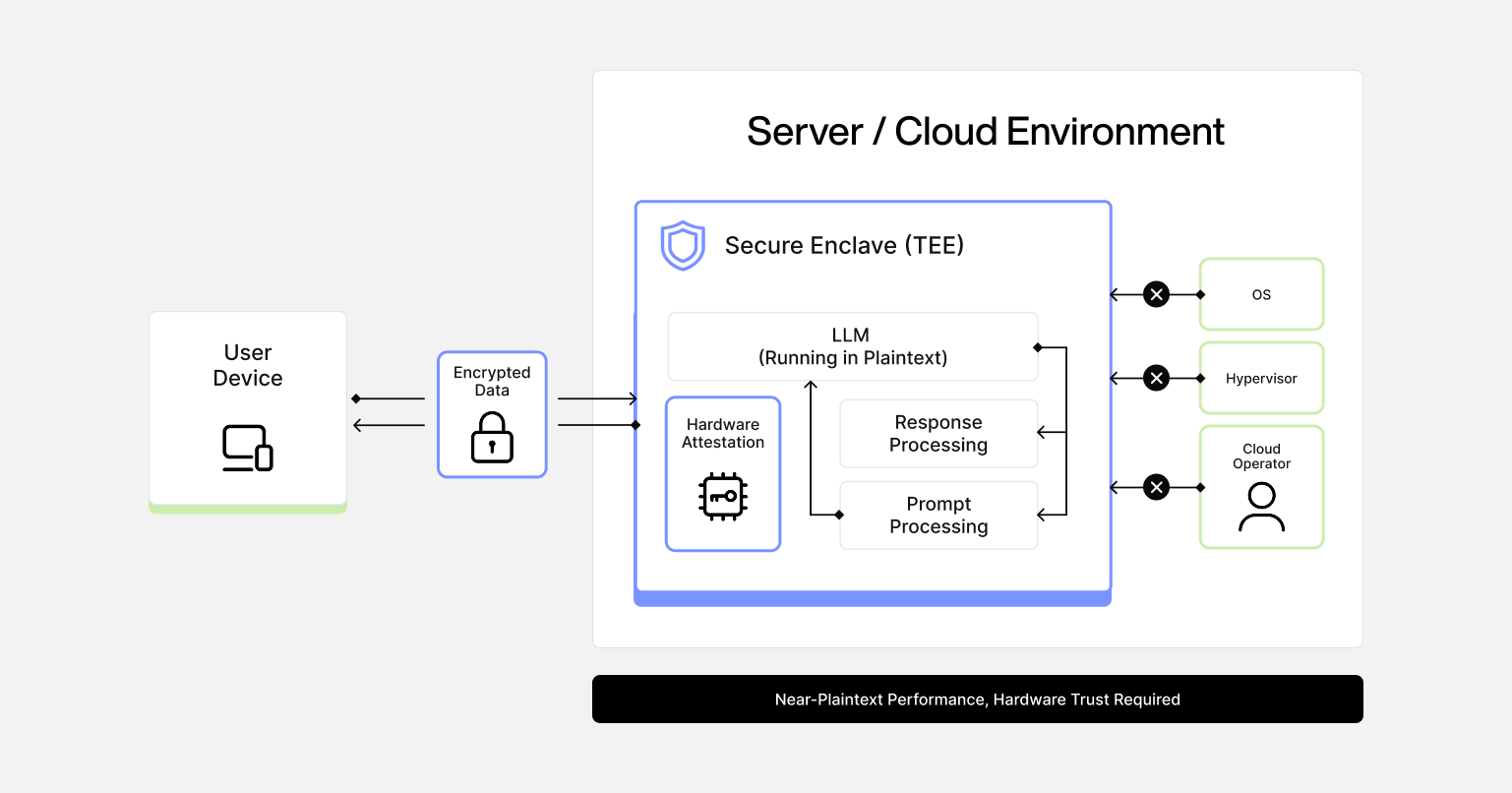
TEEs are currently the only approach that supports full-scale LLMs with acceptable latency. Benchmarks show models like LLaMA-3 running inside Intel TDX with overhead that remains within practical bounds.
Trade-offs
The distinction between these approaches comes down to trust assumptions.
With MPC or FHE, privacy guarantees derive from mathematics. With TEEs, they derive from hardware implementation. You're trusting that the enclave was built correctly and that the attestation chain is secure. Side-channel vulnerabilities have been found in TEE implementations, and the trust model depends on CPU vendors.
This is a real trade-off, not a limitation to be solved. Cryptographic approaches offer stronger guarantees but can't currently run production workloads. Hardware approaches work at scale but require trusting the silicon.
What we think matters
The field is moving toward what we'd describe as trust minimising architectures. TEEs provide a deployable foundation today. Cryptographic techniques can layer on top to reduce hardware trust over time. FHE remains the long-term target as computational costs decrease.
Each step along this path shrinks the set of things users have to trust. That trajectory feels like the right way to think about building privacy-preserving AI infrastructure.
The Paper
The paper digs deeper into each approach. MPC protocols, FHE schemes, hybrid systems, and TEE implementations. You'll find the actual systems researchers have built, their benchmarks, and the specific problems still blocking production use. More importantly, it lays out what's deployable today versus what's still in research. If you're evaluating privacy-preserving inference for healthcare, finance, or legal workloads, this gives you the technical map without the hype. Use it to spec your next architecture or kick off your own R&D.
You can read the full paper here:https://eprint.iacr.org/2026/105