Qwen 2.5 vs Llama 3.2 vs DeepSeek R1: Enterprise Model Comparison (2026)
Compare Qwen 2.5, Llama 3.2, and DeepSeek R1 for enterprise deployment. Covers benchmarks, licensing, compliance considerations, and deployment costs for 2026.

Three open-source model families now dominate enterprise AI deployments: Alibaba's Qwen, Meta's Llama, and DeepSeek's reasoning-focused R1.
Each takes a different approach to licensing, architecture, and performance optimization. The choice between them depends on your compliance requirements, deployment infrastructure, and whether you need general-purpose capabilities or specialized reasoning.
Qwen 2.5 leads on multilingual benchmarks with support for 100+ languages. Llama 3.2 offers the most permissive commercial terms for companies under 700M monthly active users. DeepSeek R1 costs 95% less than comparable reasoning models and matches OpenAI o1 on math and coding tasks. All three are production-ready for enterprise workloads in 2026.
This comparison covers what actually matters for enterprise deployment: licensing restrictions, benchmark performance, compliance considerations, and total cost of ownership.
Quick Comparison Table
| Feature | Qwen 2.5 | Llama 3.2 | DeepSeek R1 |
|---|---|---|---|
| Developer | Alibaba (China) | Meta (USA) | DeepSeek/High-Flyer (China) |
| Latest Version | Qwen 2.5-Max, Qwen3 | Llama 3.2, Llama 4 | R1, V3.2 |
| Parameter Range | 0.5B to 235B | 1B to 405B | 1.5B to 671B |
| Architecture | Dense + MoE variants | Dense | MoE (671B total, 37B active) |
| License | Apache 2.0 (most models) | Llama Community License | MIT |
| Commercial Use | Yes, unrestricted | Yes, <700M MAU | Yes, unrestricted |
| Context Window | Up to 128K tokens | Up to 128K tokens | Up to 128K tokens |
| Languages | 100+ | 8 primary | Chinese/English primary |
| Training Data | 18T+ tokens | 15T tokens | Not disclosed |
| Best For | Multilingual, coding | General purpose, agents | Reasoning, math, coding |
Qwen 2.5: The Multilingual Leader
Alibaba's Qwen series has evolved from a regional model to a global competitor. Qwen 2.5, released in late 2024, and the newer Qwen3 family (April 2025) consistently outperform models of similar size on coding, math, and multilingual benchmarks.
Architecture and Model Sizes
Qwen 2.5 offers dense models from 0.5B to 72B parameters. The flagship Qwen 2.5-Max uses a Mixture of Experts (MoE) architecture, pretrained on 20+ trillion tokens. The Qwen3 family extends this with 235B total parameters (22B active) in its largest variant.
Model configurations available:
- Qwen 2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B (dense)
- Qwen 2.5-Max: MoE architecture (size undisclosed)
- Qwen3: 0.6B to 235B including MoE variants
The 72B instruct model outperforms Llama-3-405B on several benchmarks despite being 5x smaller. This efficiency advantage translates directly to lower deployment costs.
Benchmark Performance
Qwen 2.5-72B-Instruct scores:
- MMLU: 79.7 (general knowledge)
- BBH: 78.2 (reasoning)
- MATH: 57.7 (32B variant)
- MBPP: 84.5 (32B coding)
- HumanEval: Competitive with GPT-4
Qwen 2.5-Max benchmarks:
- Arena-Hard: Outperforms DeepSeek V3
- LiveBench: Exceeds DeepSeek V3
- LiveCodeBench: Superior to DeepSeek V3
- GPQA-Diamond: Higher than DeepSeek V3
The Qwen3-Coder variant achieved 69.6% on SWE-Bench Verified, placing it among the top coding models globally. For reference, this outperforms many proprietary alternatives.
Licensing and Commercial Terms
Most Qwen models use Apache 2.0 licensing, the most permissive option among major model families. This means:
- Unrestricted commercial use
- No user count limits
- Full modification and redistribution rights
- No attribution requirements in products
Qwen 2.5-Max was initially announced for open-source release but remained proprietary. Enterprise access requires Alibaba Cloud Model Studio.
Enterprise Considerations
Strengths:
- 100+ language support with strong Asian language performance
- Apache 2.0 licensing removes commercial restrictions
- Specialized variants (Qwen-Coder, Qwen-Math) for domain tasks
- Active development with rapid iteration
Concerns:
- Alibaba/China origin raises data sovereignty questions for some industries
- Some enterprise compliance frameworks require US or EU-based vendors
- Qwen 2.5-Max API requires Alibaba Cloud account
500+ enterprises have customized Qwen for their business needs according to Alibaba. The model powers 10,000+ applications globally.
Llama 3.2: The Enterprise Standard
Meta's Llama has become the default choice for enterprises needing open-source LLMs with clear commercial terms. Over 50% of Fortune 500 companies have piloted Llama-based solutions. Major deployments include AT&T, Spotify, DoorDash, and Accenture.
Architecture and Model Sizes
Llama 3.2 spans from edge-deployable to datacenter-scale:
- Llama 3.2 1B/3B: Lightweight models for mobile and edge
- Llama 3.2 11B/90B: Vision-capable multimodal variants
- Llama 3.1 8B/70B/405B: Text-focused production models
The 405B model represents Meta's flagship, trained on 15 trillion tokens. Llama 4 (released 2025) introduces Scout, Maverick, and Behemoth variants with native multimodal capabilities and MoE architectures.
Benchmark Performance
Llama 3.1-70B scores:
- GSM8K: 56.8% (math reasoning)
- MMLU: Competitive with GPT-4
- HumanEval: Strong code generation
- Context: 128K tokens (16x improvement over Llama 3)
Llama 4 Maverick benchmarks:
- Structured image + text reasoning: Matches or exceeds closed-source models
- Multimodal tasks: Native support for text + images
- Code generation: Competitive with specialized coding models
The 128K context window enables processing entire documents, lengthy conversations, or large codebases without truncation.
Licensing and Commercial Terms
The Llama Community License permits commercial use with restrictions:
- Free for organizations under 700 million monthly active users
- Larger organizations require separate Meta agreement
- Prohibits use in critical infrastructure and certain government applications
- Competitors with 700M+ MAU need explicit permission
This threshold effectively makes Llama free for all but the largest tech companies. AT&T, Accenture, and similar enterprises use Llama in production without licensing fees.
Enterprise Considerations
Strengths:
- US-based vendor simplifies compliance for regulated industries
- Largest ecosystem of tools, integrations, and community support
- Meta actively invests in enterprise features (Llama Guard, CodeShield)
- Clear legal framework with established commercial precedent
- Llama Stack provides enterprise tooling and safety measures
Concerns:
- 700M MAU limit affects very large platforms
- Some government/military applications explicitly prohibited
- Multimodal support still developing compared to proprietary options
Enterprise spending on Llama-based solutions is projected to reach $2.5 billion by 2026. The model's integration into Meta's consumer products provides a feedback loop for continuous improvement.
DeepSeek R1: The Reasoning Specialist
DeepSeek shocked Silicon Valley in January 2025. A Chinese hedge fund (High-Flyer, $8B AUM) trained a reasoning model for $294,000 that outperformed OpenAI's o1 on math benchmarks. The model went viral, becoming the #1 free app in both US and China app stores.
Architecture and Model Sizes
DeepSeek R1 uses a Mixture of Experts architecture:
- 671 billion total parameters
- 37 billion active per forward pass
- Built on DeepSeek-V3-Base foundation
Distilled versions available:
- 1.5B, 7B, 8B, 14B, 32B, 70B checkpoints
- Based on Qwen 2.5 and Llama 3 series
- Smaller models retain reasoning capabilities
The MoE structure keeps computational costs low while enabling frontier-level reasoning. Running the full 671B model requires 641GB at full precision or 128GB RAM with 2.71-bit quantization.
Benchmark Performance
DeepSeek R1 reasoning benchmarks:
- AIME 2024: 96.3% (vs OpenAI o1: 79.2%)
- MATH-500: 97.3% pass@1
- Codeforces: 2,029 Elo (outperforms 96.3% of humans)
- MMLU: 90.8% (matches GPT-4o/Claude 3.5)
The model's reinforcement learning training enables:
- Chain-of-thought reasoning with visible steps
- Self-verification and error correction
- Long reasoning chains for complex problems
Think mode shows full reasoning process. Non-Think mode provides direct answers. This flexibility lets developers optimize for accuracy vs latency.
Licensing and Commercial Terms
MIT License (most permissive):
- Full commercial use permitted
- Modification and derivative works allowed
- Distillation for training other models explicitly permitted
- No user count restrictions
- No attribution requirements
The distilled models inherit base model licenses (Apache 2.0 for Qwen-based, Llama license for Llama-based).
Enterprise Considerations
Strengths:
- MIT license removes all commercial restrictions
- API costs 95% lower than OpenAI o1
- Reasoning capabilities match or exceed proprietary alternatives
- Open weights enable full customization
- Active research community (most liked model on Hugging Face)
Concerns:
- Chinese origin triggers data sovereignty concerns
- Think mode adds 10-15 seconds latency vs 2 seconds for GPT-4
- Content moderation aligned with Chinese regulations
- Limited enterprise support infrastructure
DeepSeek V3 (based on R1 technology) matches GPT-4o quality at 30x lower cost. Microsoft Azure AI now hosts R1, signaling enterprise acceptance despite origin concerns.
Head-to-Head Benchmark Comparison
| Benchmark | Qwen 2.5-72B | Llama 3.1-70B | DeepSeek R1 |
|---|---|---|---|
| MMLU | 79.7 | ~75 | 90.8 |
| MATH | 57.7 (32B) | ~55 | 97.3 |
| HumanEval | 84.5 (MBPP) | ~70 | Strong |
| AIME | ~70 | ~65 | 96.3 |
| Context | 128K | 128K | 128K |
| Languages | 100+ | 8 | 2 (EN/ZH) |
Note: Benchmarks vary by evaluation methodology. These represent approximate performance ranges from multiple sources.
Key observations:
DeepSeek R1 dominates reasoning tasks. The reinforcement learning approach produces measurably better math and coding performance than supervised fine-tuning alone.
Qwen 2.5 leads multilingual applications. If your enterprise serves global markets or processes documents in multiple languages, Qwen's 100+ language support provides clear advantages.
Llama 3.2 offers the safest enterprise path. US origin, clear licensing, and extensive ecosystem make it the default choice for compliance-sensitive deployments.
Licensing Comparison for Enterprise
| Aspect | Qwen 2.5 | Llama 3.2 | DeepSeek R1 |
|---|---|---|---|
| License Type | Apache 2.0 | Llama Community | MIT |
| Commercial Use | Unrestricted | <700M MAU | Unrestricted |
| Modification | Allowed | Allowed | Allowed |
| Distillation | Allowed | Allowed | Explicitly allowed |
| Attribution | Not required | Not required | Not required |
| Government Use | Allowed | Restricted | Allowed |
| Military Use | Allowed | Restricted | Allowed |
Enterprise licensing guidance:
For most enterprises, all three licenses permit commercial deployment. The critical differences:
- Large platforms (700M+ MAU): Avoid Llama without Meta agreement. Qwen or DeepSeek have no restrictions.
- Government/defense: Llama explicitly restricts certain applications. Qwen and DeepSeek technically permit all uses, but origin concerns may override licensing.
- Derivative works: DeepSeek MIT license most explicitly permits distillation for training new models.
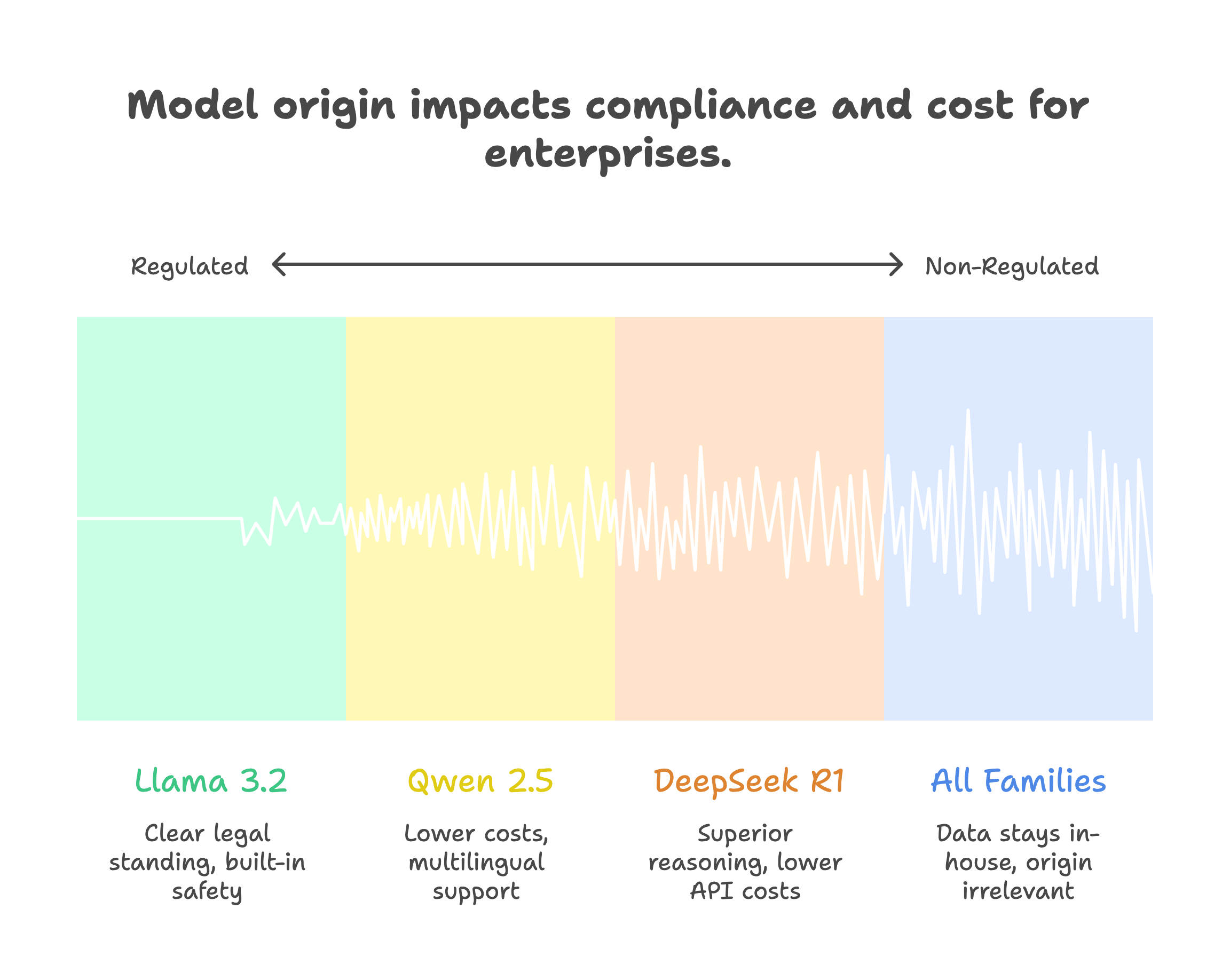
Data Sovereignty and Compliance
Enterprise compliance requires evaluating model origin, not just licensing terms.
US/EU Regulated Industries
Recommended: Llama 3.2
US-based Meta provides clearest legal standing for:
- HIPAA-covered healthcare applications
- Financial services under SOC 2/PCI requirements
- Government contractors
- Defense-adjacent applications
Llama Guard and CodeShield provide built-in safety measures that compliance teams can document.
Global Enterprises (Non-Regulated)
Consider: Qwen 2.5 or DeepSeek R1
If data sovereignty isn't mandated by regulation:
- Lower costs (especially DeepSeek API)
- Better multilingual support (Qwen)
- Superior reasoning (DeepSeek R1)
Self-hosting eliminates origin concerns since data never leaves your infrastructure.
Self-Hosted Deployments
All three model families support full self-hosting:
- Download weights from Hugging Face
- No external API calls required
- Data stays within your infrastructure
- Origin becomes less relevant
Hardware requirements for 70B class models:
- Minimum: 140GB VRAM (full precision)
- Practical: 48GB+ with quantization
- Recommended: NVIDIA A100/H100 clusters
Quantized versions run on consumer hardware. DeepSeek R1 distilled models work on laptops.
Cost Comparison
API Pricing (per million tokens)
| Provider | Input | Output | Notes |
|---|---|---|---|
| DeepSeek R1 | $0.55 | $2.19 | 95% cheaper than o1 |
| Qwen via Alibaba | ~$0.80 | ~$2.00 | Varies by model |
| Llama via Together | ~$0.90 | ~$0.90 | Various providers |
| OpenAI o1 | $15.00 | $60.00 | Comparison point |
| GPT-4o | $2.50 | $10.00 | Comparison point |
Self-Hosting Economics
Enterprise breakeven analysis for self-hosted deployment:
- Upfront cost: $50K-500K (GPU infrastructure)
- Monthly operating: $5K-20K (power, maintenance)
- Breakeven point: 12-18 months at 500M+ tokens/month
- Post-breakeven savings: 50-70% vs cloud APIs
A 100K token context that costs $5.50 on GPT-4 costs approximately $0.90 on DeepSeek V3.
Total Cost of Ownership
For enterprises processing 1B tokens monthly:
| Model | API Cost/Month | Self-Host/Month | Recommendation |
|---|---|---|---|
| DeepSeek R1 | ~$2,700 | ~$8,000 | API for reasoning tasks |
| Qwen 2.5 | ~$2,800 | ~$8,000 | Self-host for multilingual |
| Llama 3.1 | ~$1,800 | ~$8,000 | Self-host for compliance |
Self-hosting makes sense when:
- Monthly API costs exceed $10K
- Data sovereignty is mandatory
- You need fine-tuned models
- Latency requirements demand local inference
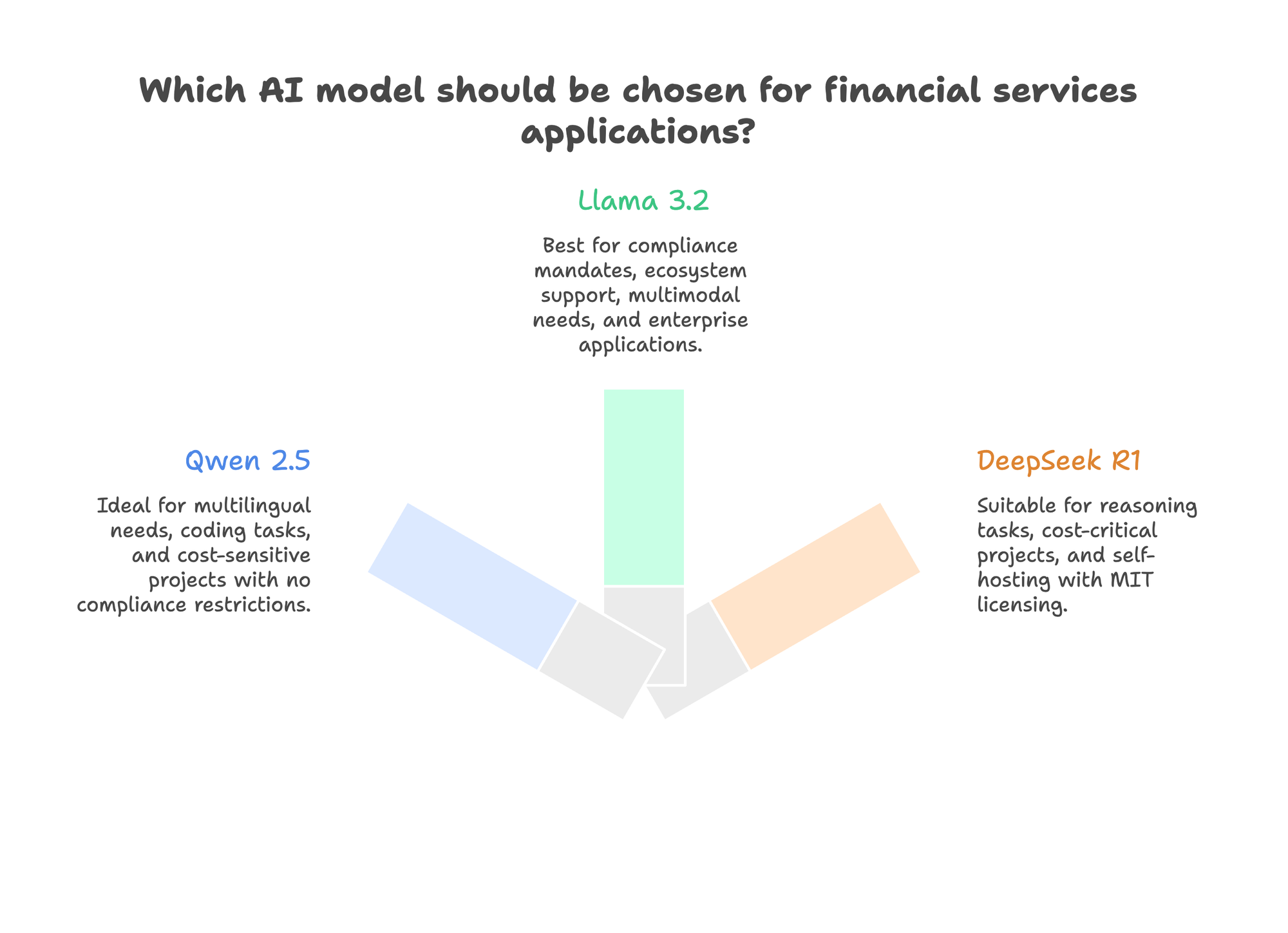
When to Choose Each Model
Choose Qwen 2.5 When:
- Multilingual requirements: 100+ languages with strong Asian language support
- Coding tasks: Qwen-Coder achieves 69.6% on SWE-Bench Verified
- No compliance restrictions: Apache 2.0 licensing with no user limits
- Alibaba Cloud integration: Existing relationship simplifies deployment
- Cost sensitivity: Strong performance at smaller parameter counts
Choose Llama 3.2 When:
- Compliance mandates US vendors: Healthcare, finance, government applications
- Ecosystem matters: Most tools, integrations, and community support
- Multimodal needs: Native vision capabilities in 11B/90B variants
- Enterprise support required: Meta provides enterprise tooling and guidance
- Risk-averse environment: Most established commercial track record
Choose DeepSeek R1 When:
- Reasoning is primary use case: Math, coding, logical analysis tasks
- Cost is critical: 95% cheaper than comparable reasoning APIs
- MIT licensing needed: Most permissive terms for derivative works
- Self-hosting planned: Open weights enable full customization
- Cutting-edge performance required: Matches o1 on reasoning benchmarks
Fine-Tuning Considerations
All three families support fine-tuning, but approaches differ:
Qwen 2.5: Standard LoRA and full fine-tuning work well. 4-bit quantization with QLoRA enables training on consumer hardware. Alibaba provides limited fine-tuning guidance.
Llama 3.2: Most extensive fine-tuning documentation. Meta publishes guides for domain adaptation, safety fine-tuning, and efficiency optimization. Largest community of fine-tuning practitioners.
DeepSeek R1: Distilled models explicitly designed for further fine-tuning. The MIT license permits using R1 reasoning data to train other models. However, reproducing the RL training pipeline requires significant infrastructure.
Deploying Open-Source Models in Production: The Platform Gap
Choosing between Qwen, Llama, and DeepSeek is step one. Actually deploying them in production is where most enterprise projects stall.
The common challenges:
Infrastructure complexity. Running a 70B model requires GPU clusters, load balancing, and inference optimization. Most enterprises lack dedicated ML infrastructure teams.
Fine-tuning without ML expertise. Downloading weights is easy. Training a model that outperforms the base on your specific use case requires data pipelines, hyperparameter tuning, and evaluation frameworks.
Compliance gaps. Open-source models have no built-in compliance. You inherit full responsibility for SOC 2, HIPAA, and GDPR requirements.
Model sprawl. Testing Qwen for multilingual, Llama for general tasks, and DeepSeek for reasoning creates three separate infrastructure stacks.
How Prem AI Solves Enterprise Deployment
Prem AI provides the missing layer between open-source models and enterprise production. The platform supports all three model families covered in this comparison, plus 30+ additional base models.
Unified fine-tuning across model families. Upload your data once. Fine-tune Qwen, Llama, or DeepSeek variants through the same interface. The autonomous fine-tuning system runs up to 6 concurrent experiments, handling hyperparameter optimization automatically. No ML engineering required.
Built-in compliance. SOC 2 Type II certified. HIPAA compliant with BAA available. GDPR compliant. Swiss jurisdiction under FADP provides additional privacy protections. The compliance infrastructure that would take 12+ months to build internally comes included.
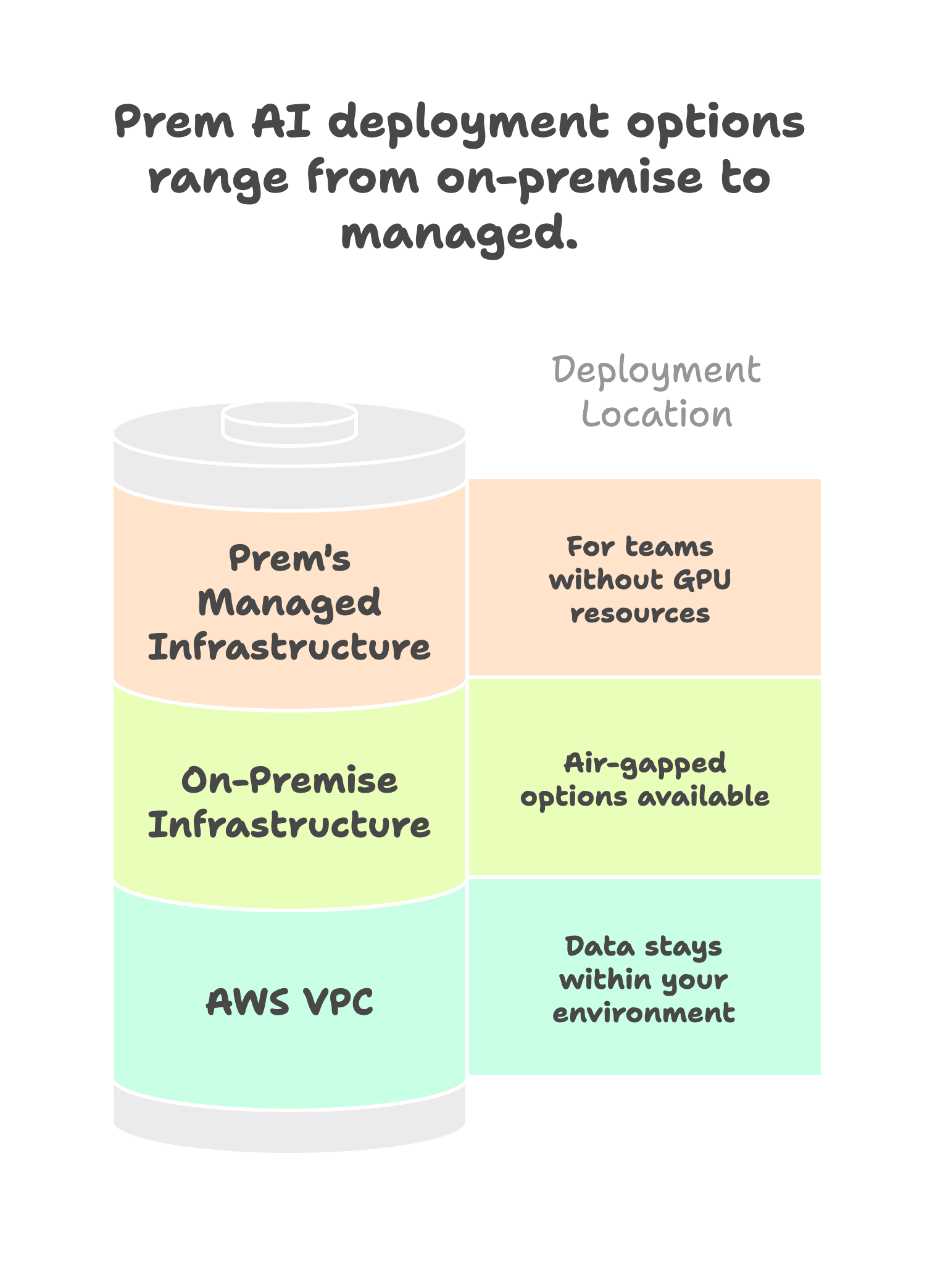
Flexible deployment options. Deploy fine-tuned models to:
- Your AWS VPC (data never leaves your environment)
- On-premise infrastructure (air-gapped options available)
- Prem's managed infrastructure (for teams without GPU resources)
Evaluation before deployment. LLM-as-a-judge scoring, side-by-side model comparisons, and custom evaluation rubrics ensure your fine-tuned model actually outperforms the base before going to production.
Export without lock-in. Download model weights in standard formats (GGUF, SafeTensors). Deploy via vLLM, Ollama, or Hugging Face. The platform accelerates development without creating vendor dependency.
When Prem AI Makes Sense
The platform fits enterprises that:
- Need fine-tuned models but lack ML engineering resources
- Require compliance certifications for regulated industries
- Want to evaluate multiple model families without separate infrastructure
- Prefer managed fine-tuning with self-hosted inference
For teams with established ML infrastructure and dedicated model training expertise, direct deployment of open-source models remains viable. Prem AI targets the gap between "downloaded weights" and "production-ready custom model."
Grand (Advisense subsidiary serving 700 financial institutions) uses Prem AI for compliance automation. Sellix built fraud detection achieving 80%+ accuracy improvement over baseline models. These represent the use case: domain-specific fine-tuning with enterprise compliance requirements.
Frequently Asked Questions
Which model is most accurate?
Depends on the task. DeepSeek R1 leads on reasoning and math. Qwen 2.5 leads on multilingual tasks. Llama 3.2 provides balanced general-purpose performance. For most enterprise applications, differences are marginal compared to deployment considerations.
Can we use Chinese models in regulated US industries?
Technically yes, but practically complex. Self-hosting eliminates data transfer concerns, but some compliance frameworks require US-origin vendors. Consult your compliance team. Llama provides the safest path for heavily regulated industries.
What hardware do we need to self-host?
For 70B class models: 2-4x NVIDIA A100 (40GB) or 1-2x H100. Quantized versions reduce requirements significantly. DeepSeek R1 distilled models (7B-14B) run on single consumer GPUs. Edge deployment possible with Llama 1B/3B or Qwen 0.5B/1.5B.
How do these compare to GPT-4 or Claude?
On benchmarks: DeepSeek R1 matches or exceeds o1 on reasoning. Qwen 2.5-Max matches GPT-4o on most tasks. Llama 3.1-405B approaches GPT-4 performance. The gap between open and proprietary models has largely closed for most enterprise applications.
Which has the best enterprise support?
Llama via Meta has the most enterprise infrastructure. Qwen via Alibaba Cloud provides commercial support in Asia. DeepSeek offers API support but limited enterprise programs. For self-hosted deployments, community support is extensive for all three.
Conclusion
The choice between Qwen 2.5, Llama 3.2, and DeepSeek R1 comes down to three factors: compliance requirements, primary use case, and deployment model.
For regulated US enterprises: Start with Llama 3.2. The US origin, clear licensing, and extensive ecosystem minimize compliance risk while providing competitive performance.
For global multilingual applications: Evaluate Qwen 2.5. The 100+ language support and Apache 2.0 licensing provide flexibility that Llama's 8 languages cannot match.
For reasoning-intensive workloads: Consider DeepSeek R1 for math, coding, and logical analysis tasks. The 95% cost reduction vs proprietary alternatives makes it compelling for reasoning-heavy applications.
For maximum flexibility: Self-host any of these models. Origin concerns diminish when data never leaves your infrastructure. Fine-tuning unlocks domain-specific performance that exceeds any base model.
The practical path for most enterprises: select your model family based on the criteria above, then use a platform like Prem AI to handle fine-tuning and deployment. This approach gets custom models into production without building ML infrastructure from scratch.
All three families are production-ready for enterprise deployment in 2026. The question isn't whether open-source models can compete with proprietary alternatives. They already do. The question is which open-source model fits your specific compliance, performance, and cost requirements.