RAG vs Long-Context LLMs: Approaches for Real-World Applications
This article compares Retrieval-Augmented Generation (RAG) with Long-Context Large Language Models (LLMs) in managing extensive data and complex queries, highlighting key technical differences and applications.

RAG vs Long-Context LLMs: Future Directions and Recommendations
The evolution of Large Language Models (LLMs) has led to increasingly diverse approaches for handling vast amounts of data and responding intelligently to complex queries. Among these approaches, Retrieval-Augmented Generation (RAG) and Long-Context (LC) LLMs have emerged as two leading solutions. Both methods address the challenges inherent in processing large amounts of contextual information, but they take fundamentally different approaches to do so.
Retrieval-Augmented Generation (RAG) combines generative capabilities with an external retrieval mechanism to enrich responses with precise, relevant information. This approach ensures that LLMs are not solely reliant on internal data but can actively access and integrate knowledge from external sources. RAG is especially useful in cases where external, up-to-date, or highly specialized information is critical to a task’s success.
On the other hand, Long-Context LLMs aim to handle extensive sequences directly within the model’s internal architecture. By expanding their context window, these models can maintain and utilize long-range dependencies across much larger text inputs, theoretically simplifying the flow by eliminating the need for external retrieval. This makes them particularly suitable for applications requiring in-depth understanding of long sequences without the overhead of managing retrieval systems.
This article dives deep into the comparative performance of RAG and Long-Context LLMs, providing insights into where each excels and highlighting scenarios that might benefit from a hybrid approach.
Understanding RAG and Long-Context LLMs
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) combines the strengths of retrieval-based and generation-based approaches in natural language processing. The process involves two main steps: retrieval and generation. During the retrieval stage, relevant information is fetched from a corpus or database based on a user query, often using embedding-based similarity searches. This retrieved information is then combined with the user query to generate a response using an LLM.
RAG is particularly effective for incorporating up-to-date and domain-specific information into language models. This makes it highly beneficial in scenarios where the internal model knowledge might be outdated or insufficient. The dual-step process enables RAG to provide more precise answers, especially for tasks such as question answering, technical support, and real-time data applications.
However, RAG also has some limitations. The quality of the retrieved information heavily depends on the retriever's efficiency and accuracy. Additionally, integrating external information can sometimes introduce noise, especially if the retrieval process selects irrelevant or redundant data.
References:
- RETRIEVAL MEETS LONG CONTEXT LARGE LANGUAGE MODELS.pdf
- Long Context RAG Performance of Large Language Models.pdf
Comparative Analysis of RAG and Long-Context LLMs
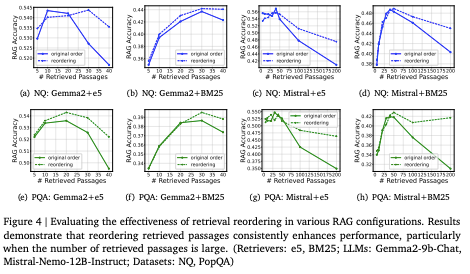
To better understand the comparative performance of Retrieval-Augmented Generation (RAG) and Long-Context (LC) LLMs across various tasks, we present the following visualizations. These figures demonstrate how different LLMs perform when integrated into RAG systems using distinct retrieval strategies and provide insights into their efficiency in handling long-context scenarios.
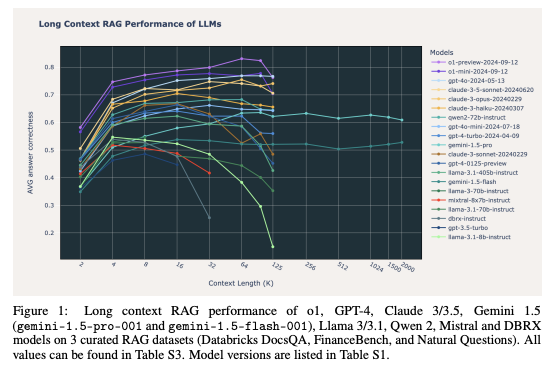
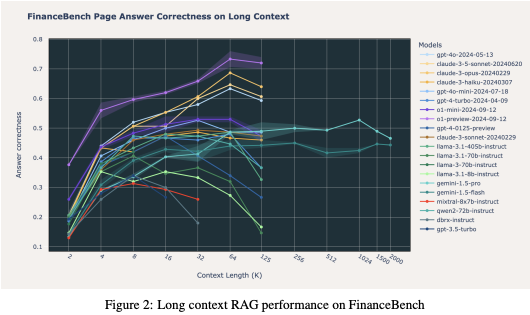
The first figure illustrates the impact of retrieval quality (using retrievers such as e5 and BM25) on the accuracy of different models, highlighting how performance varies with the number of retrieved passages. The second figure compares the overall performance of different LLMs, showcasing their strengths in extended context handling and emphasizing the scenarios where LC models can outperform RAG-based configurations.
These visual comparisons provide a clearer understanding of the strengths and limitations of each approach, allowing us to see where RAG and LC LLMs excel individually and where hybrid solutions might offer an advantage.
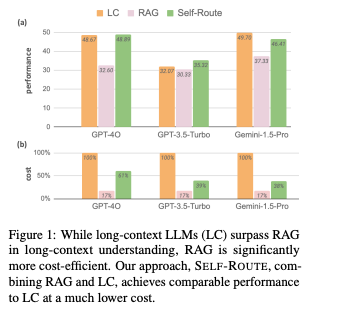
Cost and Computational Efficiency
Another important factor to consider when comparing RAG and LC LLMs is their computational efficiency. RAG generally requires fewer computational resources compared to LC models because it retrieves only the most relevant information, reducing the number of tokens processed by the LLM. This makes RAG a more cost-effective solution, particularly when handling large-scale queries where full context processing is not necessary.
On the other hand, LC LLMs can become computationally expensive due to their requirement to process entire input sequences, which can be especially costly when dealing with very long documents. The quadratic scaling of attention mechanisms in transformers adds to the computational burden as the length of the input increases.
To balance these trade-offs, hybrid methods like SELF-ROUTE have been proposed, where a model decides whether to use RAG or LC based on the nature of the query. This approach allows for significant cost savings while maintaining performance levels close to those of dedicated LC models.
Hybrid Approaches
Hybrid approaches, such as SELF-ROUTE, combine the strengths of both RAG and LC LLMs. SELF-ROUTE works by dynamically routing queries to either a RAG or LC model depending on the task requirements. For example, queries that require current, domain-specific information might be routed to RAG, while those that need a comprehensive understanding of a long context are directed to an LC model.
This approach effectively optimizes both cost and performance. Studies have shown that hybrid systems can achieve results comparable to LC models while significantly reducing the computational cost, particularly for tasks that do not always require processing extensive text inputs.
Failure Modes and Challenges
RAG Challenges
RAG faces several notable challenges, particularly related to the quality and relevance of the retrieved information. The efficiency of RAG is highly dependent on the retriever's accuracy; if the retrieval process selects irrelevant or incorrect data, the quality of the generated response is compromised. This issue becomes especially pronounced when dealing with "hard negatives"—documents that are contextually similar but do not provide the correct answer. Such instances can lead to increased noise in the generation process, ultimately affecting performance.
Moreover, RAG struggles when the retrieval corpus is not well-maintained or lacks the latest information. The reliance on external knowledge bases means that the quality of responses is directly linked to the quality of the data available. This makes RAG particularly vulnerable to outdated or incomplete databases, which can limit its utility for real-time or highly dynamic information needs.
Long-Context LLM Challenges
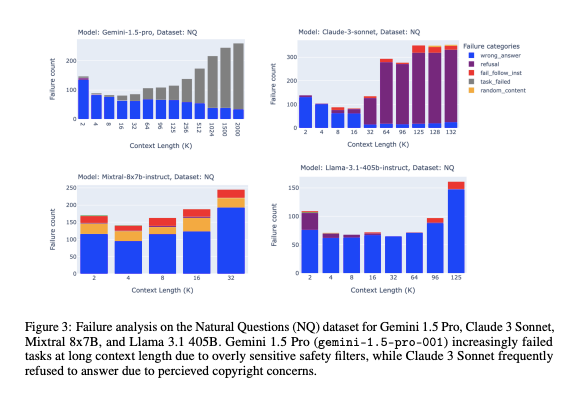
These results illustrate the specific conditions under which different LLMs face increased failure rates, emphasizing the limitations of current retrieval mechanisms in challenging contexts. As shown in Figure 3, the failure rates for models such as Gemini 1.5 Pro and Claude 3 Sonnet increase significantly with longer context lengths
Long-Context LLMs also have their own set of challenges. One major issue is the computational cost associated with processing long sequences. The quadratic scaling of transformer models means that as the input length increases, the computational and memory requirements grow exponentially, making these models resource-intensive and costly to deploy at scale.
Another significant challenge is the "lost in the middle" phenomenon, where information in the middle portions of a long input sequence tends to be overlooked or underutilized by the model. This can lead to reduced accuracy, especially for tasks that require attention to details spread throughout the input text. Addressing this issue often requires advanced techniques such as memory management, hierarchical attention, or splitting the input into smaller, more manageable chunks, which adds further complexity to model design and implementation.
Despite their ability to handle extensive input sequences, LC LLMs may still struggle with retaining the coherence and relevance of long documents, especially when the input exceeds the optimal context length. As a result, LC LLMs are best suited for tasks that can benefit from extended context but do not necessarily require fine-grained understanding of every detail within extremely long documents.
Real-World Applications of RAG and Long-Context LLMs
To illustrate the real-world applications of Retrieval-Augmented Generation (RAG) and Long-Context LLMs, the following figure shows the effectiveness of retrieval reordering in various RAG configurations. It demonstrates how retrieval ordering can enhance performance, particularly as the number of retrieved passages increases. This visualization helps provide insight into the optimization potential of RAG systems in real-world scenarios, such as healthcare, finance, and legal applications.
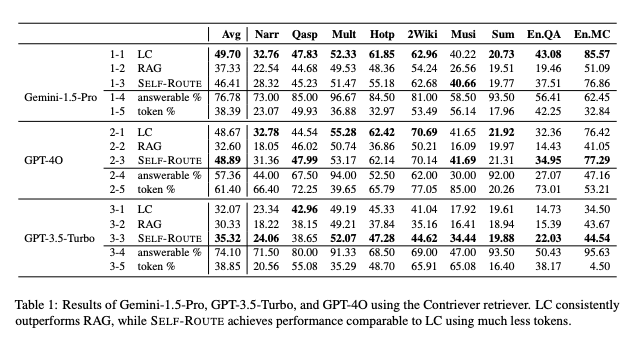
The following table provides a performance comparison of Gemini-1.5-Pro, GPT-3.5-Turbo, and GPT-4O using the Contriever retriever. It includes metrics such as average performance across various datasets, including narrative comprehension (Narr), question answering (Qasp), summarization (Sum), and others. This comparison highlights how Long-Context (LC) LLMs, Retrieval-Augmented Generation (RAG), and the hybrid approach (SELF-ROUTE) perform in different real-world scenarios. Notably, LC models consistently outperform RAG, while the SELF-ROUTE approach provides a balance by achieving similar results to LC with reduced token usage, making it a more computationally efficient choice.
Healthcare and Medical Applications
In the healthcare sector, both RAG and Long-Context LLMs have shown considerable potential. RAG is particularly effective in clinical scenarios that require up-to-date information from medical literature or databases, such as assisting healthcare professionals in diagnostics or treatment recommendations. For example, RAG can quickly retrieve relevant clinical studies or the latest medical guidelines to support doctors in decision-making processes.
Long-Context LLMs, on the other hand, are well-suited for summarizing long patient records or analyzing complex medical cases that require understanding extensive historical patient data. These models can help in comprehending multi-page medical records, ensuring that no crucial information is lost while providing a cohesive summary of the patient’s health status.
Finance and Economics
In finance, RAG’s ability to incorporate real-time information from economic databases, market trends, and financial disclosures can significantly enhance financial analysis and decision-making processes. For instance, financial analysts can use RAG-based systems to gather the latest data, ensuring that reports are based on the most current information available.
Long-Context LLMs are valuable in performing comprehensive analyses of extensive financial reports or market studies. Their capacity to process long sequences makes them ideal for understanding lengthy documents like annual reports, regulatory filings, or market analysis reports without the need to break the content into smaller chunks.
Legal and Compliance
Legal professionals often deal with voluminous legal texts and case histories. RAG can assist by retrieving relevant precedents, statutes, or regulations that are essential for building a legal argument. It helps lawyers find pertinent information quickly, reducing the time spent on research.
On the other hand, Long-Context LLMs can provide value by processing and summarizing entire legal documents or contracts. They help in understanding the intricacies of legal clauses and offer a coherent summary that can be crucial during contract reviews or compliance checks.
Advertising and Marketing
In advertising, RAG can be used to generate content that is in tune with current consumer trends by retrieving real-time market data and consumer behavior insights. This allows marketing teams to craft messages that are relevant and resonate with the target audience.
Long-Context LLMs are useful for creating in-depth marketing strategies and reports that require a thorough understanding of historical campaign performance, consumer feedback, and market analysis. Their ability to manage long text inputs helps in developing cohesive strategies without overlooking critical insights from past data.
RAG vs Long-Context LLMs: Future Directions and Recommendations
References: