Small Models, Big Wins: Agentic AI in Enterprise Explained
Prem Studio breaks down NVIDIA’s latest research, showing how Small Language Models match or surpass large ones, delivering faster, cheaper, and more efficient AI for enterprise workflows.

For years, we've argued that bigger isn't always better in AI. Do you really need a giant 70B model to fetch data or format a report? Probably not.
A new 2025 research paper from NVIDIA now validates our long-held belief. The paper "Small Language Models Are the Future of Agentic AI" shows that SLMs can match larger models for many agent tasks while being far more efficient.
NVIDIA's researchers define SLMs as language models compact enough to run on everyday devices (think <10B parameters) while still delivering low-latency responses for a single user's requests. In contrast to general-purpose Large Language Models (LLMs) like GPT-4 or Claude, these smaller models focus on narrower tasks. And guess what? That focus often makes them better suited for the repetitive, well-defined chores that enterprise AI agents handle daily. Agentic AI handles mostly repetitive, scoped, non-conversational tasks, exactly where massive LLMs often fail to utilize their full potential.
In other words, why use a sledgehammer when a scalpel will do? The NVIDIA paper essentially says the same: SLMs are "sufficiently powerful, inherently more suitable, and necessarily more economical" for many agent operations, and are therefore "the future of agentic AI". This aligns perfectly with what we've seen at Prem. In this post, I'll break down NVIDIA's key findings, share some real-world examples, and explore what this SLM-first approach means for enterprise AI infrastructure. Let's dive in.
NVIDIA’s Findings: Seven Experiments Proving Small Models Can Do Big Things
NVIDIA’s paper doesn’t just make claims; it backs them up with evidence. The authors highlight a series of experiments and benchmarks (from themselves and others) where small models matched or even outperformed their large-model counterparts. Here are seven standout examples that caught our eye:
| Model ↓ (Params) | What It Demonstrates | Headline Stat |
|---|---|---|
| Microsoft Phi-2 (2.7B) | Commonsense reasoning & code generation | Matches 30B peers at 15× lower latency |
| NVIDIA Nemotron-H (2-9B) | Instruction following & coding | 30B-level accuracy with 90% fewer FLOPs |
| Hugging Face SmolLM2 (0.125-1.7B) | Tool use & instruction following | Competes with 14B models |
| NVIDIA Hymba-1.5B | Instruction adherence | Beats 13B rivals, 3.5× higher throughput |
| DeepSeek-R1-Distill (1.5-8B) | Complex reasoning | 7B variant tops Claude 3.5 & GPT-4o on reasoning |
| DeepMind RETRO 7.5B | Retrieval-augmented LM | Matches GPT-3 with 25× fewer parameters |
| Salesforce xLAM-2 8B | Tool calling | Outperforms GPT-4o & Claude 3.5 on tool-use benchmarks |
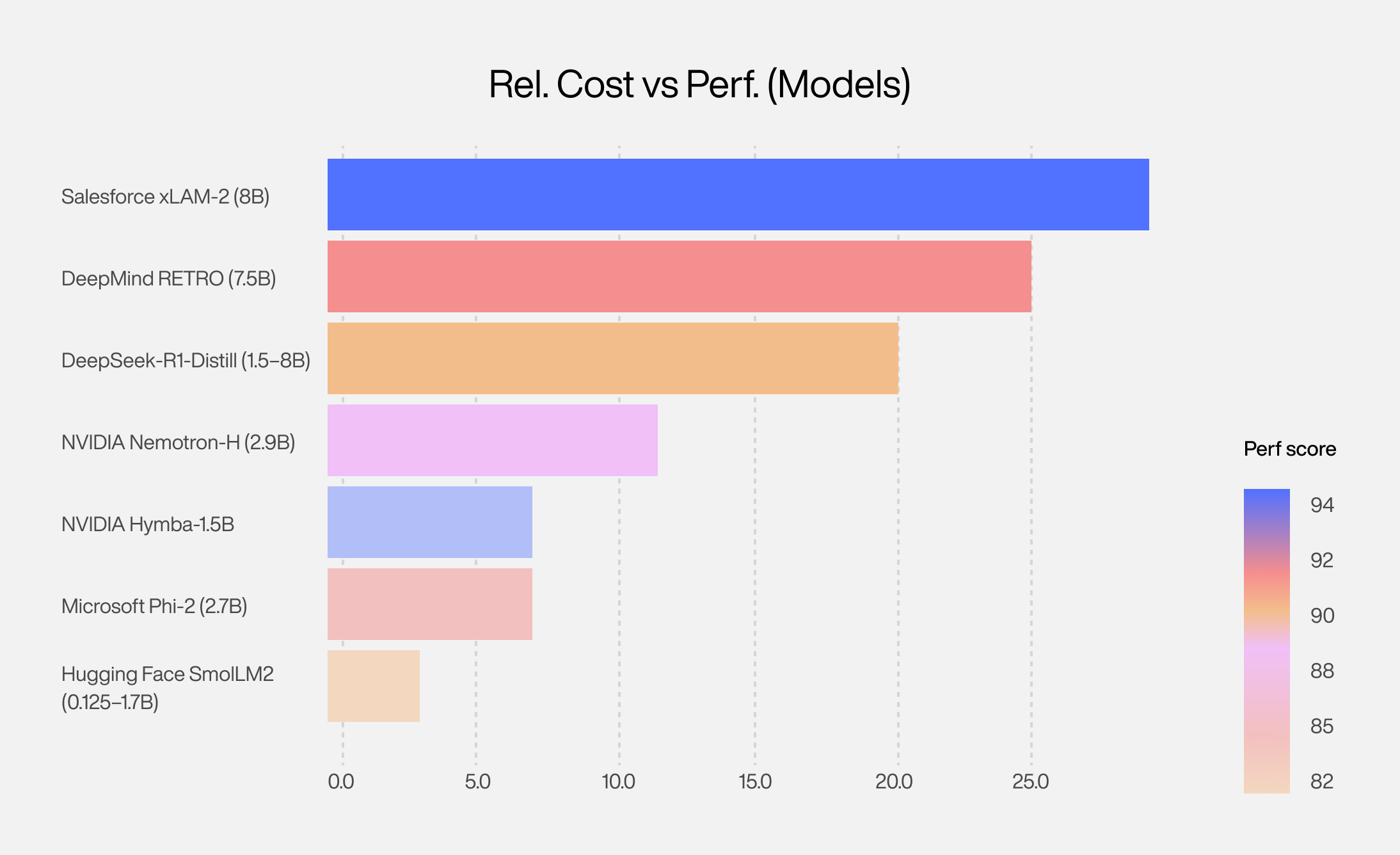
Each of these examples drives home the same point: with modern training techniques and clever architectures, size is no longer the sole determinant of capability. As the NVIDIA team puts it, “capability, not the parameter count, is the binding constraint” now.
In sum, small models today provide sufficient reasoning power for a substantial portion of agentic AI tasks, making them not just viable but often preferable over large models for building modular, scalable AI agents.
Small vs Large Language Models: What Enterprise AI Really Needs
What do these findings mean for those of us building AI systems in the enterprise? In a word: efficiency. Running large models everywhere is both expensive and operationally unwieldy. Small Language Models offer clear economic and practical advantages, especially for the agentic AI workflows becoming common in modern enterprise applications. Let’s break down the benefits:
| Advantage | What It Means in Practice | Useful Stat |
|---|---|---|
| 1. Lower Inference Cost & Energy | Run many queries without melting your GPU bill. Green, too. | 7B model is 10–30× cheaper per token than a 70B–175B LLM |
| 2. Faster Response Times | Snappier UX for end-users, mission-critical speed for ops. | Latency often drops from >1 s to <300 ms on typical hardware |
| 3. Rapid FineTuning | Add domain jargon or new skills overnight, not weeks. | LoRA finetune of a 2B model ≈ hours on one GPU |
| 4. Cloud-to-Edge Flexibility | Deploy on-prem, in VPCs, or even on beefy laptops for true data control. | Consumer-grade GPUs handle real-time SLM inference |
| 5. Lego-Block Modularity | Compose many narrow "experts" instead of one opaque monolith; easier debugging & hot-patching. | Paper calls this "Lego-like composition of agentic intelligence" |
| 6. Alignment & Reliability | Narrow scope → fewer hallucinations, safer automation pipelines. | Format-locked SLMs cut mis-formatted outputs that break workflows |
In short, SLMs hit the sweet spot for enterprise AI: good enough intelligence where needed, but with far better cost-efficiency and manageability.
They let us optimize our AI infrastructure like never before, swapping out the one-size-fits-all paradigm for a collection of right-sized tools. The NVIDIA paper highlights how SLM-based agentic AI systems scale easily, specialize effectively, and run at lower cost—exactly what enterprises are looking for
Rethinking Enterprise AI: The Case for On-Premises SLM Deployment
These ideas aren't just theoretical. NVIDIA's team tested three leading open-source AI agent frameworks to find out how much heavy LLM lifting SLMs could handle instead. The results are eye-opening for anyone running AI agents in production. Across MetaGPT, Open Operator, and Cradle, they found roughly 40% to 70% of the large-model calls could be handled by well-tuned small models today. Here's a quick rundown of each case study:
How Much LLM Workload Can SLMs Steal?
| Open-Source Agent | Current LLM Calls | Replaceable with SLMs | Takeaway |
|---|---|---|---|
| MetaGPT | Multi-agent software engineering | ≈60% | Boilerplate code & docs need speed, not bloat |
| Open Operator | Workflow automation | ≈40% | Intent parsing & templated output go mini |
| Cradle | GUI automation | ≈70% | Repetitive UI clicks are pure SLM territory |
These case studies reinforce a pattern: in real agent systems, a majority of tasks are well within the reach of smaller models. By intelligently partitioning which tasks go to an LLM versus an SLM, we can dramatically cut costs while maintaining performance. A heterogeneous setup, lots of little specialists plus the occasional big generalist when truly needed, is the best of both worlds. It’s exactly how we design scalable architectures in other domains (think microservices in software engineering): use the right-sized component for each job. Agentic AI should be no different.
The Road Ahead with SLMs (and How Prem Studio Can Help)
NVIDIA’s research is a timely reality check for the AI industry. It confirms that small language models aren’t just a niche idea, they’re a practical path forward for enterprise AI infrastructure. By embracing SLMs, companies can build AI agents that are faster, cheaper, and more controllable, all without sacrificing capability on routine tasks. The writing is on the wall: the future of agentic AI will be powered by an army of small, task-specialized brains working in concert, not one mega-brain trying to do it all.
This vision has been at the heart of our work at Prem Studio. We’ve always believed in empowering enterprises with the right models for the job. That’s why we built Prem Studio - your workshop for the SLM revolution.

Prem Studio: Where small models become big solutions
Think of Prem Studio as your all-in-one platform to:
- Fine-tune specialized SLMs for your unique workflows
- Evaluate performance against business-specific metrics
- Deploy compact agents anywhere - cloud, edge, or air-gapped environments
- Manage your fleet of specialized models from one dashboard
Whether you need to:
- Spin up a custom 2B-param model for document processing
- A/B test SLMs against existing LLM workflows
- Create a team of specialized micro-agents
- Deploy on consumer-grade hardware for true data control
Prem Studio makes it simple. No PhD required. No infrastructure headaches. Just small models doing big work.
Ready to build smarter?
The takeaway is simple: you no longer need to default to giant, costly AI models for every problem. As NVIDIA’s paper shows, and our experience confirms, small models deliver outsized value when given the right tools.
The era of Small Language Models is here. Let’s build the future of enterprise AI together, one small model at a time.
The takeaway is simple: you no longer need to default to giant, costly AI models for every problem. As NVIDIA’s paper shows, and our experience confirms, small models can deliver outsized value. If you’re looking to modernize your enterprise AI stack with more efficient, agentic intelligence, let’s talk. The era of Small Language Models is dawning, and Prem Studio is here to help you ride that wave, from breakthrough research to real-world results. Here’s to building the future of enterprise AI; one small model at a time.
Sources:
- Belcak, P. et al. (2025). Small Language Models are the Future of Agentic AI. NVIDIA Research.
- Jindal, S. (2025). "Small Language Models Make More Sense for Agentic AI." Analytics India Magazine.
- NVIDIA Research (2025). Case Studies on SLM Replacement in Open-Source Agents – MetaGPT, Open Operator, Cradle.
- Tensorfuse Blog (2025). "SLMs are the Future of Agentic AI" – Practical summary and insights.