Small vs Large Guard LLM Models: Accuracy, Cost, and Latency
MiniGuard-v0.1 is the smallest guardrail model built for enterprise and Private AI. Learn how Prem AI delivers fast, low-cost AI safety without large-model tradeoffs.

Why the Smallest Guardrail LLM Wins in Production
As enterprises scale AI systems, safety models increasingly sit in the critical path of every user interaction. Before a prompt ever reaches a core LLM, a guardrail model must classify it, meaning latency, throughput, and cost matter just as much as accuracy.
This is especially true for teams building Private AI systems, where infrastructure efficiency and predictable costs are non-negotiable.
To understand the real-world trade-offs, we benchmarked MiniGuard-v0.1 (0.6B), the smallest guardrail model in production (trained using Prem Studio), against Nemotron-Safety-Guard-8B, across modern and cost-efficient GPU environments.
The Deployment Reality: Throughput, Latency, and the “H200 Tax”
Large guardrail models can score well on benchmarks, but they come with a hidden cost. To achieve acceptable latency, models like Nemotron-8B often require premium GPUs such as NVIDIA H100 or H200.
For startups and enterprises alike, this creates a “Safety Tax”:
- Higher cloud bills
- Reduced deployment flexibility
- Overprovisioned hardware just to keep guardrails fast
At Prem AI, we designed MiniGuard-v0.1 to eliminate this trade-off.
The Memory Wall Problem on Commodity GPUs
When deployed on NVIDIA L40S (AWS g6e) instances, Nemotron-8B quickly hits a memory bandwidth wall. The GPU spends more time moving ~16GB of weights than performing inference, causing latency to spike almost immediately as traffic grows.
MiniGuard avoids this entirely.
At just ~1.2GB, MiniGuard-v0.1 is 93% smaller, allowing it to:
- Fully utilize compute cores
- Maintain stable latency under load
- Scale safely on commodity hardware
This makes it ideal for Private AI deployments, on-prem setups, and cost-controlled cloud environments.
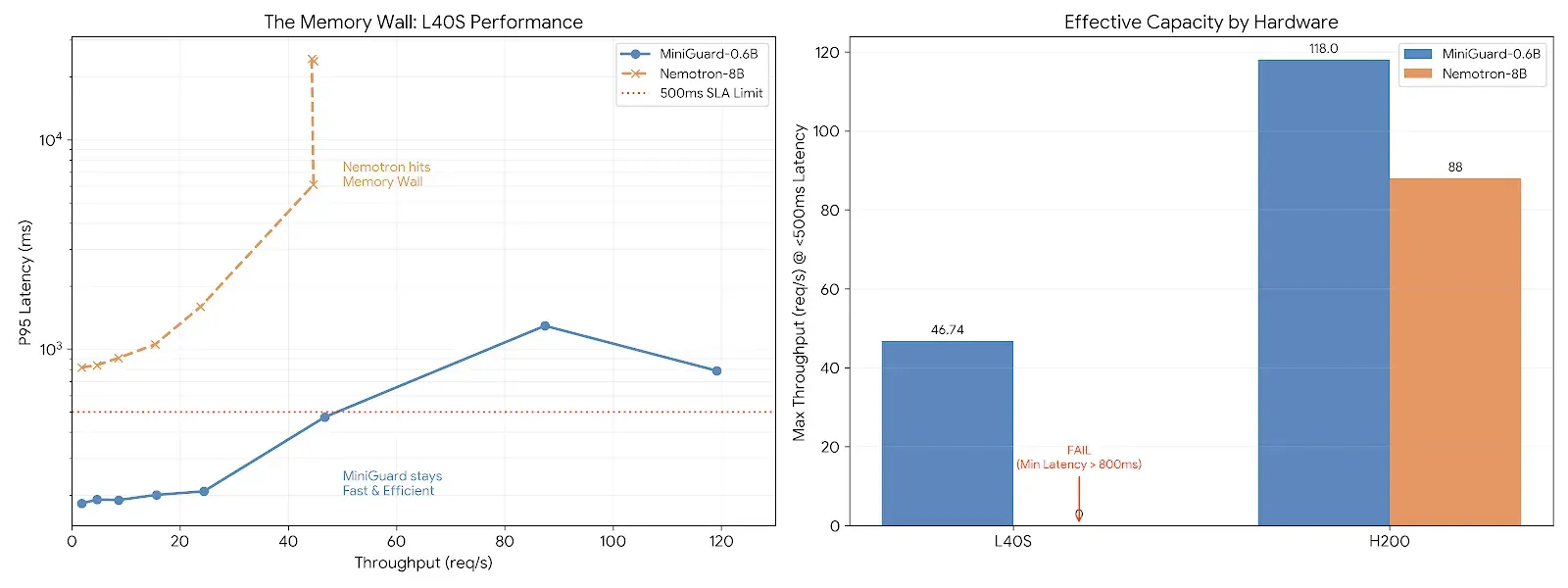
Benchmark Results on L40S
| Metric | Nemotron-8B | MiniGuard-0.6B | Impact |
|---|---|---|---|
| P95 Latency | >800 ms | 183 ms | 4× faster |
| Max Throughput | ~44 req/s | ~119 req/s | 2.7× higher capacity |
| Scalability | Latency spikes at 50 RPS | Stable to 150 RPS | Production-ready |
Why This Matters for Enterprises and Founders
You can run large guardrail models fast, but only by paying for top-tier GPUs. For most organizations, that doesn’t scale.
The smallest guardrail LLM changes the equation.
With MiniGuard-v0.1, enterprises get:
- H200-class performance on L40S hardware
- ~3× lower inference costs
- Low-latency safety checks without premium GPUs
- Guardrails that don’t degrade user experience
For founders, this means faster go-to-market.
For enterprises, it means predictable costs and safer Private AI systems at scale.
The Prem AI Perspective
At Prem AI, we believe safety should enable scale, not limit it. MiniGuard-v0.1 proves that accuracy, cost, and latency don’t have to sit on a Pareto frontier.
You don’t need massive models for reliable guardrails. You need the right model, trained for production reality.
FAQs
1. What is the smallest guardrail LLM available today?
The smallest guardrail LLM in production is MiniGuard-v0.1 by Prem AI, a 0.6B-parameter safety model that delivers enterprise-grade accuracy with significantly lower cost and latency than large guard models.
2. Why does the smallest guardrail model matter for enterprise AI?
Smaller guardrail models reduce latency, infrastructure cost, and hardware dependency, making them ideal for enterprise and Private AI deployments where safety checks sit in the critical path.
3. How does MiniGuard compare to large guardrail models like Nemotron-8B?
MiniGuard-v0.1 achieves over 99% of Nemotron-8B’s benchmark accuracy while being 13× smaller, 2–4× faster, and ~3× cheaper to run in production.
4. Can the smallest guardrail LLM run on commodity GPUs?
Yes. MiniGuard-v0.1 is designed to run efficiently on commodity GPUs like NVIDIA L40S, avoiding memory bottlenecks that slow down large guardrail models.
5. Is MiniGuard suitable for Private AI deployments?
Absolutely. MiniGuard is ideal for Private AI, on-prem, and regulated environments where predictable cost, low latency, and full control over infrastructure are required.
6. Does a smaller guardrail model compromise safety or accuracy?
No. MiniGuard uses targeted synthetic data, reasoning-based distillation, and optimized quantization to preserve safety performance while dramatically reducing model size.
7. Who should use the smallest guardrail model?
Enterprises, startups, and AI teams building chatbots, agents, and content systems where safety must be fast, scalable, and cost-efficient.