Open Source Audio Models: Text-to-Speech and Speech-to-Text
Open-source frameworks like BASE TTS, ESPnet, and FunASR are transforming Text-to-Speech and Speech-to-Text technologies in 2025. With advancements in scalability, natural prosody, and low-resource deployment, these tools make high-quality speech AI accessible and customizable globally.


Open-source advancements in audio processing have reshaped the fields of Text-to-Speech (TTS) and Speech-to-Text (STT), democratizing access to cutting-edge technology. This article explores the recent developments, tools, and models that are driving the field forward in 2025, highlighting their performance, versatility, and integration capabilities. We discuss the ecosystem of open-source audio models, benchmark comparisons, and the practical implications for industries and developers worldwide.
Evolution of Open-Source Audio Models
The adoption of open-source audio models has revolutionized Text-to-Speech (TTS) and Speech-to-Text (STT) technologies, opening new opportunities for innovation and accessibility. This section explores the factors driving the rise of open-source frameworks, the challenges they address, and the significant milestones achieved in the field.
The Shift Towards Open Source
The rise of open-source audio models marks a paradigm shift in the field of speech technologies. Until recently, the development of advanced speech-to-text (STT) and text-to-speech (TTS) systems was dominated by proprietary solutions. These platforms, while powerful, often required significant financial investment, creating barriers for small businesses and individual developers. In contrast, open-source frameworks like Mozilla’s DeepSpeech and FunASR are democratizing access to cutting-edge speech technologies. By eliminating licensing fees and fostering collaborative innovation, these frameworks have enabled a broader audience to experiment with and deploy advanced models.
A critical factor driving this shift is the open availability of large-scale datasets and pre-trained models. For instance, FunASR leverages industrial-scale datasets, offering plug-and-play solutions like Paraformer for STT tasks. Similarly, ESPnet-TTS integrates speech recognition (ASR) and TTS models within a unified framework, further simplifying adoption for research and industry.
Milestones in TTS and STT Models
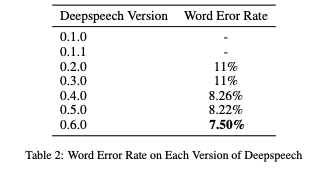
The journey of open-source audio models has been marked by a series of technological milestones. Early frameworks like DeepSpeech pioneered end-to-end STT systems, focusing on low-resource environments such as Raspberry Pi. Over time, these systems evolved to incorporate transformer-based architectures and advanced decoding mechanisms, as demonstrated in FAIRSEQ S2T and ESPnet-TTS.
In the TTS domain, the emergence of models like BASE TTS highlights the impact of scaling both datasets and parameters. BASE TTS, with its billion-parameter architecture, sets new benchmarks in naturalness and prosody, rivaling proprietary systems in quality. Meanwhile, benchmarks like TTS Arena allow developers to objectively compare open-source and proprietary models, fostering transparency and competition.
As of 2025, open-source frameworks now provide highly modular systems that are easier to train, fine-tune, and deploy. Whether through tools like ESPnet-TTS or Paraformer, developers can integrate speech capabilities with minimal effort, significantly reducing the time-to-market for AI-driven applications.
Text-to-Speech (TTS) Technologies in 2025
Text-to-Speech (TTS) technology has undergone remarkable advancements, driven by open-source models that are making high-quality, human-like speech synthesis widely accessible. This section explores leading frameworks, benchmark comparisons, and how innovations like Kokoro-82M and other models are shaping the field.
Key Open-Source Frameworks
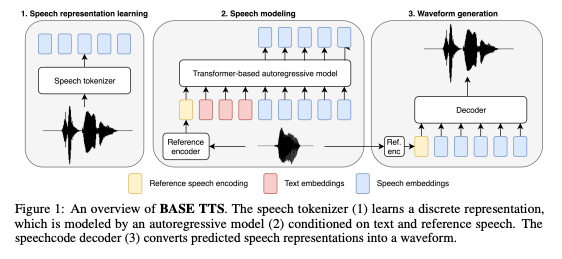
The landscape of open-source TTS frameworks continues to expand, offering developers versatile and powerful tools. ESPnet-TTS leads the way by providing a unified platform for building state-of-the-art TTS models, such as Tacotron 2 and Transformer TTS. These models simplify deployment with pre-trained options and recipe-style training pipelines for multilingual and multi-speaker scenarios.
BASE TTS, another standout innovation, pushes the boundaries of large-scale TTS systems. It leverages a billion-parameter architecture trained on 100,000 hours of public domain speech data to achieve unparalleled naturalness and expressiveness.
Additionally, Kokoro-82M has emerged as a revolutionary model, balancing efficiency and performance. With only 82 million parameters, it outperforms significantly larger models like XTTS v2 (467M) and MetaVoice (1.2B). Kokoro-82M utilizes the StyleTTS 2 architecture and ISTFTNet backend, achieving state-of-the-art results in benchmarks like the TTS Spaces Arena.
Other noteworthy frameworks include:
- OpenTTS: A modular and flexible framework supporting multilingual synthesis.
- VITS: A variational model excelling in prosody and naturalness.
- LTTS: Lightweight TTS models tailored for low-resource devices.
FunASR complements these frameworks with practical deployment tools, such as pre-trained Paraformer-based TTS models. It bridges the gap between academic research and industrial applications by offering plug-and-play modules for end-to-end synthesis.
Benchmarking TTS Models
Benchmarking has become an essential part of the TTS ecosystem, offering developers clarity on model performance. The TTS Arena, inspired by the Chatbot Arena, provides a platform to evaluate open-source and proprietary models side by side. Participants can compare models such as ElevenLabs, MetaVoice, Kokoro-82M, and open-source systems like WhisperSpeech by voting on the most natural-sounding outputs.
This transparent ranking system has democratized the evaluation process, encouraging innovation and improving the quality of TTS systems. By addressing gaps in traditional metrics like Mean Opinion Score (MOS), TTS Arena empowers the community to identify the most effective models. For example, Kokoro-82M consistently ranks as a leader, outperforming larger models with minimal computational resources.
The Role of Large-Scale Data in TTS
The development of Text-to-Speech (TTS) technology relies heavily on the availability and use of large-scale datasets. In 2025, leading TTS frameworks like MozillaTTS, ParlerTTS, and CoquiTTS demonstrate how leveraging diverse, expansive datasets can improve both naturalness and adaptability in speech synthesis. This subsection explores how these frameworks are transforming TTS through data-centric approaches.
Recent innovations by frameworks like CoquiTTS emphasize the importance of large-scale, multilingual datasets. CoquiTTS uses datasets curated for regional accents and dialects, enabling the generation of natural and localized speech. This aligns with broader trends in the industry, where training data diversity ensures inclusivity in speech synthesis.
ParlerTTS takes a unique approach by integrating speech synthesis with conversational models. By using datasets rich in conversational and emotional tones, ParlerTTS improves expressiveness, making it an ideal choice for interactive applications like virtual assistants.
MozillaTTS focuses on accessibility, offering tools to train models on publicly available datasets. By allowing developers to fine-tune models with minimal proprietary dependencies, MozillaTTS empowers the community to build applications tailored to specific use cases, such as screen readers or content narrators.
While large-scale data significantly boosts model performance, frameworks like CoquiTTS also highlight the growing trend toward data efficiency. Recent benchmarks show that data augmentation and synthetic data generation techniques can supplement traditional datasets, reducing the cost and time needed to achieve state-of-the-art results.
In this evolving landscape, the shift from purely massive datasets to optimized, curated data strategies marks a critical turning point for TTS frameworks. This trend not only enhances the scalability of models but also ensures ethical and inclusive practices in training.
Speech-to-Text (STT) Innovations
Speech-to-Text (STT) technology continues to evolve rapidly, with open-source models driving innovation in accuracy, scalability, and deployment. This section examines the leading frameworks, recent advancements in end-to-end systems, and performance benchmarks shaping the STT landscape in 2025.
Popular STT Frameworks
Open-source Speech-to-Text (STT) frameworks are rapidly advancing, offering developers innovative and scalable solutions for diverse applications. Recent developments have introduced more efficient and accessible frameworks to address evolving needs in accuracy, speed, and adaptability.
Mozilla’s DeepSpeech, a pioneering framework, remains a staple for lightweight and low-resource STT applications. Its ability to operate efficiently on edge devices like Raspberry Pi has made it a popular choice for real-time transcription in resource-constrained environments.
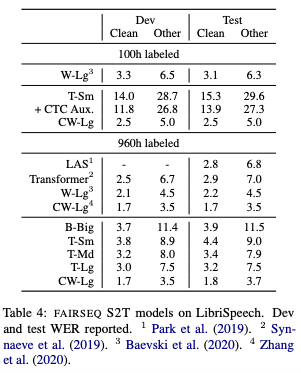
Fairseq S2T, developed by Meta, represents a cutting-edge solution for STT tasks with its transformer-based architecture. It supports multilingual speech recognition and translation, seamlessly integrating language models into workflows for complex applications.
More recently, frameworks like WhisperSTT and CoquiSTT have gained traction:
- WhisperSTT: Developed by OpenAI, this model leverages large-scale pretraining on multilingual datasets to deliver exceptional accuracy across various languages and dialects. Its robust performance in noisy environments makes it ideal for transcription services and accessibility tools.
- CoquiSTT: Built as a modular and extensible platform, CoquiSTT emphasizes community collaboration. It provides fine-tuning capabilities for domain-specific applications, such as transcription of legal and medical content.
FunASR complements these frameworks with its Paraformer model, a non-autoregressive approach that significantly improves inference speed without compromising accuracy. The toolkit also includes advanced voice activity detection (VAD) and text post-processing modules for industrial-grade deployments.
By incorporating these newer frameworks, developers now have access to tools that are more efficient, multilingual, and adaptable to specialized use cases, ensuring that STT technology remains relevant in an ever-expanding range of applications.
Advancements in End-to-End Models
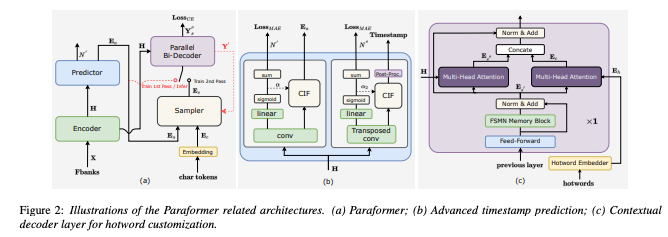
End-to-end STT models have made tremendous strides in both accuracy and efficiency. Paraformer, FunASR’s flagship model, uses a single-pass decoding mechanism to deliver fast and accurate speech recognition. Enhanced with timestamp prediction and hotword customization capabilities, Paraformer is ideal for real-world applications requiring precision and low latency.
Transformer-based architectures, such as those employed in Fairseq S2T and ESPnet, have also proven highly effective in handling complex language patterns and low-resource languages. By leveraging multi-task learning and pre-trained modules, these systems minimize data requirements while achieving competitive word error rates (WERs).
Performance Metrics
Measuring STT model performance has evolved beyond traditional metrics like WER. Benchmarks now emphasize practical considerations, including inference speed, resource utilization, and real-world accuracy. For example, Paraformer achieves industry-leading WERs while maintaining high efficiency through non-autoregressive decoding. Similarly, Fairseq S2T models excel in multilingual benchmarks, showcasing their adaptability across diverse languages and domains.
Community-driven platforms, such as TTS Arena’s counterpart for STT, are also emerging, enabling developers to compare models directly in real-world scenarios. This shift towards user-centric evaluation fosters transparency and drives continuous improvement in STT systems.
Integration and Deployment Challenges
As Text-to-Speech (TTS) and Speech-to-Text (STT) models mature, integrating them into production environments presents new challenges. This section explores scalability, customization for domain-specific use cases, and deployment on low-resource devices, highlighting how open-source frameworks address these hurdles.
Scalability and Customization
Scalability remains a critical challenge when deploying speech models in multilingual or domain-specific applications. FunASR tackles this issue by offering pre-trained models, such as Paraformer, that can be fine-tuned on small domain-specific datasets, enabling faster adaptation to new use cases. This flexibility makes it ideal for industries requiring highly specialized models, such as legal transcription or healthcare voice assistants.
ESPnet-TTS extends scalability by providing recipes for multi-speaker and multilingual training. These recipes allow developers to adapt TTS systems to a wide variety of languages and accents without requiring extensive language-specific expertise. Fairseq S2T further simplifies customization with transfer learning capabilities, leveraging pre-trained models for tasks like speech translation or low-resource language transcription.
Customizable voice activity detection (VAD) tools, such as those included in FunASR, help optimize deployments by accurately filtering speech from noise, ensuring robust performance in challenging environments like meetings or outdoor settings.
Deployment in Low-Resource Environments

Deploying high-performance speech models on devices with limited computational resources presents a significant challenge. However, recent advancements in lightweight frameworks and compact architectures have made it possible to achieve efficient deployment without compromising quality.
Mozilla’s DeepSpeech addresses this by offering lightweight models optimized for inference on devices such as Raspberry Pi. This enables STT capabilities for edge devices and IoT systems without requiring constant internet connectivity.
Frameworks like FunASR, and BASE TTS balance model complexity and efficiency, enabling fast inference even with limited hardware. BASE TTS, for instance, uses novel tokenization and decoding techniques to streamline computations while maintaining the quality of synthesized speech. This makes it a viable option for applications requiring real-time processing, such as automated customer support or in-car voice systems.
The emergence of WhisperModels (STT) and Kokoro models (TTS) further enhances low-resource deployment options:
- WhisperModels (STT): Developed with a focus on multilingual capabilities, WhisperModels excel in adapting to diverse languages and noisy environments while maintaining a small computational footprint. These models are ideal for mobile and embedded devices, providing high accuracy with minimal hardware requirements.
- Kokoro models (TTS): With only 82 million parameters, Kokoro models redefine efficiency in TTS. Their compact design enables deployment on devices with constrained memory and processing power while still achieving state-of-the-art performance. This makes Kokoro an excellent choice for applications requiring real-time, localized speech synthesis, such as smart assistants or navigation systems.
Additionally, the adoption of TensorRT and ONNX runtimes in frameworks like FunASR has made speech model deployment more accessible across platforms, from cloud-based systems to embedded devices. These tools ensure efficient use of hardware resources, reducing both cost and latency during real-time operations.
With these innovations, low-resource deployment is no longer a barrier to utilizing advanced STT and TTS technologies. Developers now have a wide range of lightweight frameworks to meet diverse application needs.
Future Prospects
The future of open-source Text-to-Speech (TTS) and Speech-to-Text (STT) technologies is brimming with possibilities. As these systems continue to evolve, ethical considerations and emerging trends will play a crucial role in shaping the next generation of audio models. This section explores the potential challenges and opportunities for the future.
Ethical Considerations
As open-source audio models gain traction, ethical concerns surrounding data privacy, accessibility, and bias come to the forefront. Ensuring that TTS and STT systems are trained on diverse and representative datasets is critical to avoiding bias in synthesized or transcribed speech. For instance, BASE TTS emphasizes multilingual training on extensive datasets to address variations in accents and languages.
Privacy is another pressing issue, particularly for STT models deployed in sensitive environments such as healthcare or legal services. By prioritizing on-device processing, frameworks like DeepSpeech and FunASR reduce reliance on cloud-based services, enhancing user privacy and data security.
Moreover, the growing accessibility of these tools raises concerns about misuse, such as deepfake audio generation. Establishing community-driven ethical guidelines and safeguards will be essential to mitigate such risks while maintaining the benefits of open innovation.
Roadmap for Open-Source Audio Models
The scalability and efficiency of audio models will likely continue to improve, driven by innovations in transformer architectures and non-autoregressive decoding. Frameworks like BASE TTS and FunASR have already demonstrated how scaling parameters and datasets can unlock emergent capabilities, such as natural prosody and emotional rendering. Future advancements may focus on further reducing computational requirements while enhancing model accuracy.
Recent models such as WhisperModels (STT) and Kokoro (TTS) are reshaping the roadmap with their compact yet highly effective designs:
- WhisperModels (STT): Known for their multilingual support and robust noise resilience, WhisperModels provide high accuracy across languages and environments, making them essential for global-scale transcription solutions.
- Kokoro (TTS): As a state-of-the-art model with only 82 million parameters, Kokoro combines efficiency with exceptional naturalness in synthesized speech. It represents the growing trend of compact models capable of competing with larger architectures.
Real-time processing and streaming capabilities will also become a primary focus, especially for interactive applications like virtual assistants and real-time transcription services. Innovations in model compression and inference optimization, as seen in FunASR, will enable seamless integration of audio technologies into low-latency environments.
Lastly, the community will play a pivotal role in shaping the future of TTS and STT technologies. Initiatives like TTS Arena provide transparent benchmarking and foster competition, ensuring continuous improvement in open-source models. This collective effort will likely drive advancements that make speech technologies even more accessible and impactful for a global audience.
References: