
Open Source Reasoning Models: Welcome Qwen QwQ and QvQ
Open-source reasoning models Qwen QwQ and QvQ represent a shift in AI from generation to structured reasoning. With transparency, multimodal capabilities, and fine-tuned performance, they set benchmarks in logical problem-solving, advancing industries like finance, healthcare, and education.


Open-source reasoning models like Qwen QwQ and QvQ are redefining the landscape of large reasoning models (LRMs). These models excel in transparency, logical consistency, and domain-specific fine-tuning, setting new benchmarks for AI reasoning. This article explores their technological advancements, their impact on reasoning AI, and the implications for developers and organizations embracing this next-generation AI paradigm.
From Generation to Reasoning—The Shift in AI Paradigms
The evolution from generative capabilities to reasoning-first approaches marks a transformative shift in AI. While traditional LLMs have excelled at generating fluent text, reasoning models now focus on step-by-step transparency and logic, enabling more accurate and interpretable outputs.
The Limitations of Traditional LLMs
Large Language Models (LLMs) such as GPT-4 and Claude have dominated AI innovation, excelling at generating fluent and contextually relevant text. However, their reliance on pattern recognition and autoregressive token prediction often leaves them struggling with tasks requiring structured reasoning or transparency in their thought processes.
In contrast, the emergence of Large Reasoning Models (LRMs) represents a paradigm shift. LRMs prioritize structured reasoning, breaking down problems into manageable steps through methods like Chain-of-Thought (CoT) reasoning. This focus on logical progression and interpretability allows these models to excel in areas where precision and clarity are critical, such as mathematics, coding, and scientific problem-solving.
Why Open Source Matters in Reasoning
Open-source projects like OpenR and OpenRFT have played a pivotal role in advancing reasoning capabilities. These frameworks provide tools for integrating reinforcement learning techniques and process reward models, enabling developers to fine-tune models for domain-specific tasks while ensuring transparency.
Open-source reasoning models democratize access to state-of-the-art AI, empowering smaller organizations and independent developers to innovate without the cost barriers of proprietary systems. By fostering collaboration and community-driven development, these initiatives accelerate advancements in reasoning AI while ensuring alignment with diverse user needs.
Qwen QwQ and QvQ—A New set of Frontier multimodal Open Reasoning Mode
Open-source reasoning models like Qwen QwQ and QvQ exemplify the forefront of AI advancements. These models combine transparency, fine-tuning, and multimodal capabilities to set new benchmarks in structured reasoning and problem-solving.
What Sets Qwen QwQ Apart
Qwen QwQ represents a significant leap forward in reasoning AI. Designed for iterative problem-solving, it excels in breaking down complex, multi-step tasks across domains such as financial analysis and logic puzzles. By employing advanced fine-tuning strategies, Qwen QwQ achieves high accuracy in numeric reasoning, as demonstrated by its 90.6% score on MATH-500.
A standout feature of Qwen QwQ is its ability to optimize memory retention during multi-turn conversations, reducing redundancy and increasing consistency. This is particularly evident in its capacity for nuanced contextual reasoning, enabling more accurate interpretations of ambiguous queries. Additionally, its integration of recursive reasoning allows the model to backtrack and refine solutions, addressing a critical limitation of earlier models like GPT-o1.
However, challenges remain. Open-source versions of Qwen QwQ face safety concerns and occasional struggles with language mixing during reasoning tasks, underscoring the need for robust evaluation in real-world applications.
QvQ’s Vision-Reasoning Fusion
QvQ is a cutting-edge multimodal reasoning model that combines visual and textual inputs to tackle complex tasks requiring a deep understanding of context across modalities. Built on the Qwen2 architecture, QvQ leverages advanced visual reasoning capabilities, enabling it to excel in tasks such as image-to-text reasoning and multimodal problem-solving.
Its achievements on benchmarks like the Multimodal Massive Multi-task Understanding (MMMU) test, where it scored 70.3%, highlight its multidisciplinary potential. This performance stems from innovative architectural improvements, such as the incorporation of grouped query attention and dual chunk attention, which enhance its ability to process long-context and multimodal data.
Despite its strengths, QvQ is not without limitations. The model occasionally exhibits issues with maintaining focus during multi-step visual reasoning, leading to hallucinations. Furthermore, its capabilities in basic recognition tasks, such as identifying objects or entities in images, do not surpass those of its predecessor, Qwen2-VL.
Core Technologies Behind Modern Reasoning Models
The success of modern reasoning models lies in their ability to emulate human-like thought processes through innovative techniques. Key advancements such as Chain-of-Thought (CoT) reasoning and Reinforcement Fine-Tuning (RFT) empower these models to tackle complex, multi-step tasks with remarkable accuracy and transparency.
Chain of Thought and Beyond
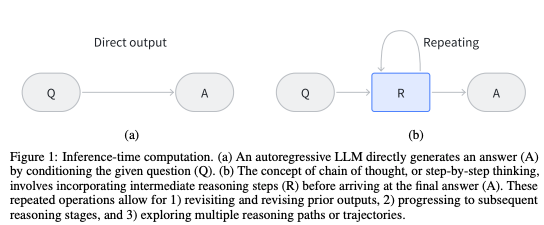
Chain-of-Thought (CoT) reasoning, a pivotal innovation, enables large reasoning models (LRMs) to solve problems step by step, mirroring human cognitive processes. This method improves not only reasoning accuracy but also interpretability by producing intermediate steps before arriving at the final answer. Techniques like Tree-of-Thought and Graph-of-Thought expand on CoT, allowing models to explore multiple pathways simultaneously for complex problem-solving.
For example, Tree-of-Thought organizes reasoning into a branching structure, systematically evaluating alternatives, while ReAct combines reasoning with real-world actions, creating a dynamic interplay between decision-making and execution. These advancements highlight the growing importance of structured reasoning in improving model reliability.
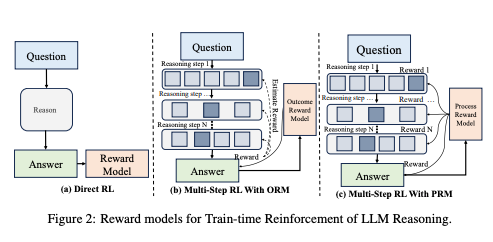
Reinforcement Fine-Tuning (RFT) and Process Reward Models (PRMs)
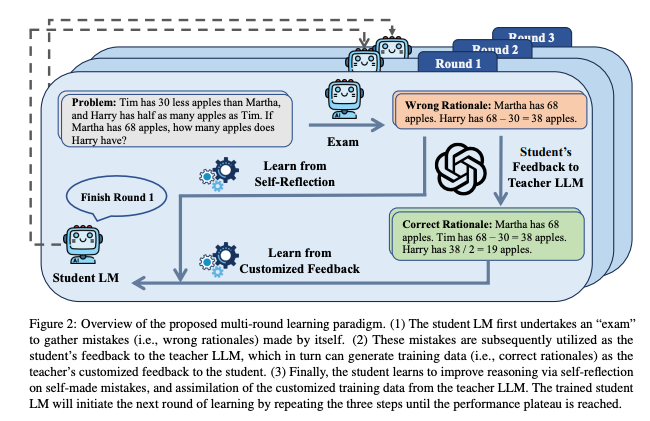
Reinforcement Fine-Tuning (RFT) marks a shift in training paradigms, moving beyond supervised learning to incorporate dynamic feedback loops. By integrating Process Reward Models (PRMs), RFT evaluates reasoning steps at a granular level, providing dense feedback rather than focusing solely on end outcomes. This ensures models not only generate accurate results but also align with human-like reasoning.
PRMs have been instrumental in elevating reasoning performance. They assign rewards to intermediate steps, encouraging models to refine their logic iteratively. This step-by-step feedback is particularly effective in tasks requiring complex decision-making, such as mathematical reasoning or multi-turn dialogues. By combining PRMs with techniques like Monte Carlo Tree Search (MCTS), reasoning models achieve higher accuracy and robustness in diverse domains.
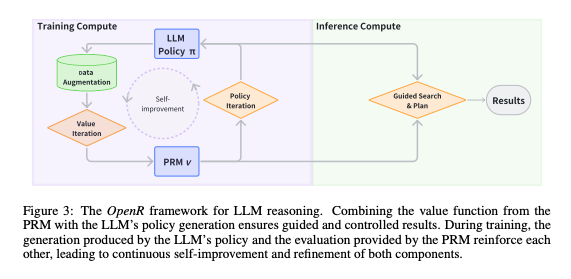
Comparative Benchmarks of Reasoning Models
The rapid evolution of reasoning models has led to significant advancements in performance across a variety of benchmarks. Models such as GPT-o1, Qwen QwQ, and QvQ have demonstrated exceptional capabilities in reasoning-intensive tasks, often outperforming traditional LLMs in domains requiring structured logic and transparency.
Quantitative Performance Across Benchmarks
Mathematical Reasoning
Qwen QwQ has achieved remarkable results on the MATH-500 benchmark, scoring 90.6%, which places it among the top-performing open-source reasoning models. This surpasses the performance of GPT-o1, which, while strong in structured reasoning, has not been as optimized for iterative problem-solving. Similarly, QvQ demonstrates strong numerical reasoning capabilities, with significant improvements in visual-mathematical tasks, leveraging its multimodal design.
| Model | Benchmark | Score (%) | Key Features |
|---|---|---|---|
| GPT-o1 | MATH-500 | 85.3 | Chain-of-Thought (CoT) reasoning |
| Qwen QwQ | MATH-500 | 90.6 | Fine-tuned for iterative problem-solving |
| QvQ | MMMU | 70.3 | Multimodal reasoning, combining vision and text |
Coding and Logical Reasoning
On coding benchmarks such as HumanEval and MBPP, reasoning models have shown their ability to break down complex problems into manageable sub-steps. Qwen QwQ, optimized for domain-specific fine-tuning, has consistently outperformed generalist models. Its recursive reasoning capabilities ensure improved memory retention and reduced errors in multi-turn tasks.
Comparing Strengths and Weaknesses
- Qwen QwQ: Strong in numeric and logical reasoning, excelling in tasks requiring multi-step iterations. However, it struggles with issues like language mixing and consistency in open-source environments.
- QvQ: Excels in multimodal reasoning tasks but has limitations in retaining focus during long visual reasoning sequences. Its hallucination risks also highlight areas needing improvement.
- GPT-o1: A generalist reasoning model that established the baseline for structured logic but lacks some of the advanced fine-tuning and iterative capabilities found in Qwen QwQ.
Implications of Benchmark Results
These benchmarks underscore the growing potential of reasoning models to tackle complex, high-stakes tasks. By leveraging reinforcement fine-tuning and multimodal integration, models like Qwen QwQ and QvQ pave the way for a new era of AI that blends transparency, accuracy, and adaptability across domains. However, challenges such as scalability, safety, and real-world validation remain pivotal to their success.
Industry Use Cases of Reasoning Models
Reasoning models like Qwen QwQ and QvQ are driving transformative applications across diverse industries. By combining advanced reasoning capabilities with multimodal inputs, these models address complex challenges that traditional LLMs struggle to solve. Below are key domains where reasoning models are creating significant impact.
1. Financial Analysis and Risk Assessment
Qwen QwQ’s ability to handle iterative problem-solving and logical reasoning makes it a powerful tool for financial analysis. Tasks such as fraud detection, credit risk assessment, and market trend forecasting benefit from its structured reasoning capabilities. For example:
- Fraud Detection: The model identifies anomalous patterns in transaction data, combining numeric and contextual reasoning to flag potential fraud.
- Portfolio Optimization: By analyzing market data and predicting trends, reasoning models help financial advisors make data-driven decisions.
2. Healthcare Diagnostics and Research
Multimodal reasoning models like QvQ are revolutionizing healthcare by integrating textual and visual data for diagnostics. Their ability to analyze patient records, combine them with medical imaging, and reason through potential outcomes is paving the way for:
- Medical Imaging Analysis: QvQ identifies abnormalities in X-rays or MRIs while cross-referencing patient histories to suggest diagnoses.
- Drug Discovery: By leveraging large datasets, reasoning models can propose hypotheses and analyze molecular interactions, accelerating drug development.
3. Education and Adaptive Learning
Reasoning models are enhancing personalized learning experiences by dynamically adapting to students’ needs. For instance:
- Math Problem Solving: Qwen QwQ excels in guiding students through step-by-step solutions, helping them grasp complex mathematical concepts.
- Language Learning: By generating nuanced responses and correcting errors, these models simulate natural conversations to improve language skills.
4. Legal Analysis and Contract Review
Legal professionals leverage reasoning models for tasks like contract analysis and case law research. With their structured logic and ability to process vast amounts of text, reasoning models:
- Review Contracts for Risks: Highlight potential ambiguities or risks in contract clauses.
- Summarize Case Law: Extract relevant information from lengthy legal documents, saving time for lawyers.
5. Scientific Research and Engineering
Reasoning models like Qwen QwQ are accelerating progress in scientific research and engineering design by solving complex equations and analyzing experimental data:
- Physics Simulations: Simulate multi-step calculations in thermodynamics or quantum mechanics.
- Engineering Designs: Optimize designs using iterative reasoning to meet safety and efficiency standards.
6. Retail and E-Commerce
Retailers are adopting reasoning models to enhance customer experiences and operational efficiency:
- Personalized Recommendations: By combining multimodal inputs such as product images and customer reviews, QvQ delivers tailored suggestions.
- Inventory Management: Predict demand fluctuations and optimize stock levels with advanced reasoning capabilities.
Open Challenges and the Future of Reasoning Models
The rise of reasoning models like Qwen QwQ and QvQ signals a new era for AI, where transparency, structured reasoning, and multimodal capabilities take center stage. However, realizing their full potential requires addressing key challenges that affect their scalability, safety, and accessibility.
Addressing Bias and Safety
Reasoning models face ongoing concerns around biases in training data and the ethical implications of their outputs. Issues such as hallucinations, recursive reasoning loops, and inconsistencies in open-source implementations highlight the need for rigorous evaluation and mitigation strategies. Enhancing transparency through methods like Chain-of-Thought reasoning and process-level supervision can help build user trust.
Developing robust safety protocols and integrating real-time feedback mechanisms are crucial for deploying these models in high-stakes environments such as healthcare, finance, and legal analysis. Without these safeguards, the potential misuse or unintended consequences of reasoning models could overshadow their benefits.
Overcoming Scalability Barriers
The computational demands of reasoning models present a significant barrier to entry, particularly for smaller organizations or developers with limited resources. Advanced techniques such as model quantization, parameter-efficient fine-tuning, and distributed inference are promising avenues for making these models more accessible without compromising performance.
Efforts to adapt reasoning models for edge devices and resource-constrained environments will democratize their use, enabling applications in underserved regions and industries. This scalability will also be vital for fostering innovation across a wider spectrum of developers and organizations.
Bridging the Gap Between Research and Real-World Applications
While reasoning models excel on benchmarks, their real-world deployment often reveals gaps in performance and practicality. Developing domain-specific fine-tuning methods and expanding multimodal capabilities will be critical for addressing these shortcomings. Additionally, fostering collaboration between academia, industry, and open-source communities can accelerate the adoption and refinement of these technologies.
Looking Ahead
The future of reasoning models lies in their ability to integrate seamlessly into complex workflows, empowering industries with tools that are not only accurate but also interpretable and adaptable. By addressing the challenges of bias, scalability, and application readiness, reasoning models have the potential to redefine the boundaries of what AI can achieve.
With continued innovation and a commitment to ethical practices, reasoning models like Qwen QwQ and QvQ will not only elevate the standards of AI but also pave the way for new possibilities across domains, transforming the way we approach problem-solving in the age of artificial intelligence.
References:
