
The Synthetic Data Revolution
Generating Synthetic data is a problem that has existed since the early days of deep learning [1]. Good data has always been a bottleneck for good quality machine learning models that can work well in unseen real-world data. However, since the generative AI revolution boom, after the incoming ChatGPT and DALL-E, researchers have gained more confidence in generating "faithful" and privacy-preserved synthetic data for different modalities. In this blog, we will discuss and understand what synthetic data is, its importance in the real world, and its privacy implications. We will also touch upon some latest research on the same topic.
🚀 Synthetic Data, An Introduction
To put this simply, synthetic data are a kind of data that does not exist in the real world, however, it approximates very similar behavior and statistical significance with the real-world data. The practice of generating this kind of data known as synthetic data through statistical ways like Gaussian Copula or using deep generative models like Variational Auto Encoders (VAE), Generative Adversarial Networks (GANs), LLMs, Diffusion models, etc, is known as synthetic data generation.
Different types of synthetic data
Synthetic data can be found in different modalities and forms. Here is a list with some examples:
- Tabular Data: Tabular data is one of the most important because of their abundance and usage in building ML models. Examples include Financial time-series data, customer data, medical data, sensor data, inventory data, etc.
- Text Data: Realistic natural languages like emulating customer behavior or conversations or tweets etc.
- Image and video data: High-quality synthetic data is used for carrying out large-scale simulations. Example: Simulations for self-driving cars.
Not only that, we have sound, graph/network data also that can be generated synthetically with use cases like simulations and synthetic drug analysis etc.
The Need
In most real-world scenarios high-quality structured data with supervised signals are very rare. At a high level, current real-world business-specific ML modeling scenarios face a major problem of data availability vs data quality. Most of the time, high-quality data are not available, and even if available, are not easily sharable, due to their privacy constraints and legal implications. While in the cases they are available, they might not be abundant enough or not annotated enough to build a good supervised ML model. There are countless needs for synthetic data. Here are some examples:
- Tabular synthetic data includes synthesizing bank/financial fraudulent data. The need for synthetic data is because fraud data are a kind of anomaly so are less available and we can not often share real accounts with third parties or contractors due to legal liability, so sharing a statistically significant synthetic version of that data can bring huge benefits.
- Text-based medical records are very useful to analyze and carry out research on different medical domains. However patient information is very sensitive. So the synthetic counterpart can be very beneficial when it comes to sharing those data with researchers or any un-trusted third party.
- Take another example of training AI algorithms to analyze and recognize patterns in geospatial satellite data. These kind of data are either very little available in the public domain or takes a huge time to access, since obtaining data without any measure may breach national security. So generating similar synthetic data can at least help researchers to carry out their initial research and analysis without any legal bounds on data.
So when it comes to privacy and legal concerns:
Synthetic data offers a middle ground, sharing data that is like sensitive data, but isn't real data.[3]
Not only that, data annotation has always been a very expensive and time-consuming part of every modern data science life cycle. Incoming synthetic data can cut costs down to a huge rate.
The problem with synthetic data generation
However, generating synthetic data is not as easy as you think. There are several problems we have to face. Here are some problems with plausible reasons:
- Generating synthetic data is technically difficult: Before generating synthetic data, it is very important to understand the real data. Since these data are a mimic of the original data. So finding approaches to do so and making infrastructure to generate good quality synthetic data at scale is technically a challenging task.
- Inaccurate and Biased Behavior: A lot of times, generating synthetic data produces inaccurate or biased results when ML models are trained on them. The reason is, that biases are already introduced inside the datasets. These inaccuracies and biases come because, for the generative models, it becomes hard to capture the complex relationships, rare events, outliers and anomalies, dynamism, and underlined bias of the actual data.
- Preserving privacy vs Accuracy tradeoff: Making data PIIs or personally identifiable information free but not at the cost of data quality is a huge challenge. Sometimes some PII data like a person's income with its geo-spatial location have a huge co-relation. Mimicking that realistic correlation in synthetic data is hard.
Upcoming sections discuss the innovative and novel methods that try to mitigate those issues to a great extent.
📊 Synthetic Data in Tabular Data

Tabular data is one of the most common forms of data in machine learning (ML) – over 65% of data sets in the Google Dataset Search platform contain tabular files in either CSV or XLS formats [2]
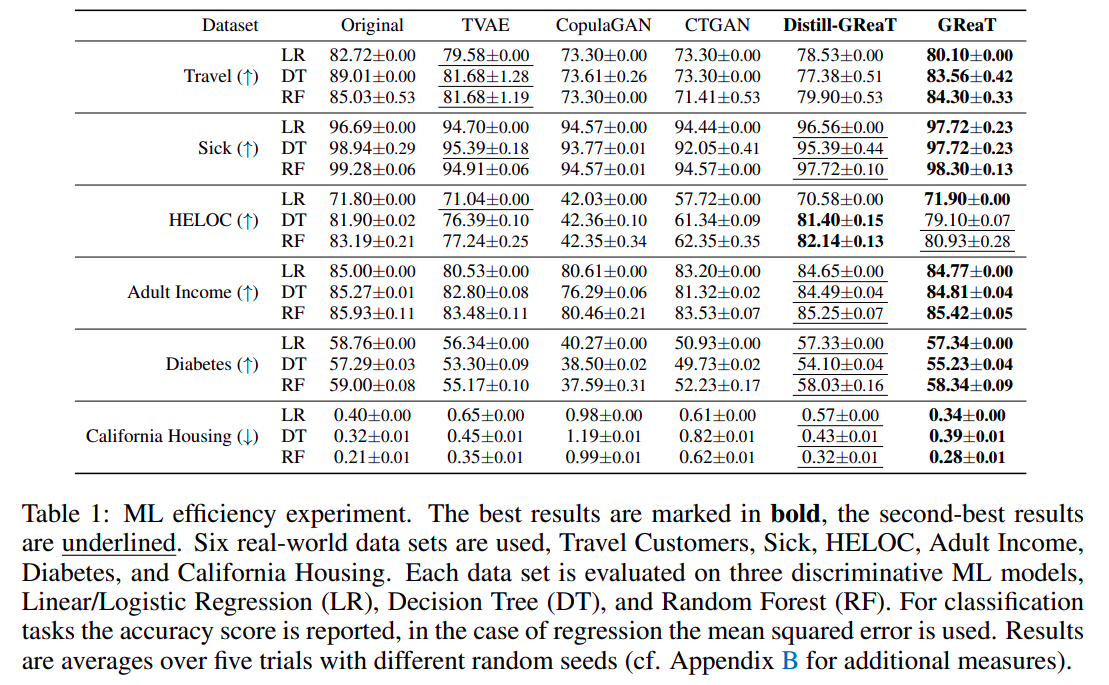
So, a lot of frontier research nowadays is done on generating good-quality tabular datasets. The metric to evaluate how good quality the synthetic dataset is lies in how much an ML model scores in standard metrics (like accuracy, F1 score, etc) when trained on synthetic data compared to when trained on real-world data.
An example scenario
Suppose we want to make a regression model on predicting taxi fair. We use a very common dataset like the NYC Taxi Yellow dataset. The dataset consists of billions of rows. Also, there are a lot of PIIs (like latitude and longitude of pick and drop of a person, etc), which brings a lot of legal hoops. So sharing of data can be painful until we share a synthetic version of it.
Statistical method of generating synthetic data
There is an awesome library called Synthetic Data Vault (SDV), that helps in generating synthetic data with ease. It can mimic data in a table across multiple relational tables or time series. Not only that, it can also enforce data constraints like redact PII or more. One popular algorithm that it uses to generate pure tabular synthetic datasets is Gaussian Copula. This algorithm is fast and effective and it can easily generate synthetic data points with good statistical significance, i.e. distribution of both the data (real and synthetic) are almost identical. Here are some results.

In the above figure, you can see that the co-relation heat map between features is very similar in synthetic data compared to real data. Although the underlined distribution of both the data can be very similar, there can be some factual inconsistency in this data and also brings some challenges like:
- Values can be negative values (for example: monetary amounts in negative) or unreasonably large amounts (for example: the distance covered)
- Inaccurate location coordinates. Giving some latitude-longitude coordinates that do not make sense within the context, or are sometimes invalid, i.e. >90 degrees latitude
- The distance covered is very short given the start and endpoints.
One of the core reasons for this kind of problem is that sometimes the real data might contain the above inconsistencies or faults. So some good practices are to preprocess the real data and finalize the synthetic data after post-processing it so that it is not just distributionally identical but preserves its factual correctness.
Using Large Language Models for Synthetic Data Generation
One of the core problems that is faced during synthetic dataset generation is preserving complex relationships in the underlined data. For our above scenario, a taxi fair highly depends on the location and some other parameters like the historical fair, etc. So this problem is related to contexts. Since LLMs are very good at understanding contexts, they can be used for generating context-aware synthetic datasets.
Be GReaT with generating data
GReaT or Generation of Realistic Tabular Data from this paper, proposes an innovative two-step approach to tackling the problem of generating context-aware synthetic datasets with LLMs. GReaT also comes up with a Python package named be-great, which you can check out if you want to do some hands-on.
Data Pipeline: The data pipeline does the following:
- It first converts the tabular data to a meaningful series of text data.
- Subsequently, a feature order permutation step is applied, where columns in a row are positionally shuffled. This is very important since they need to be positionally invariant.
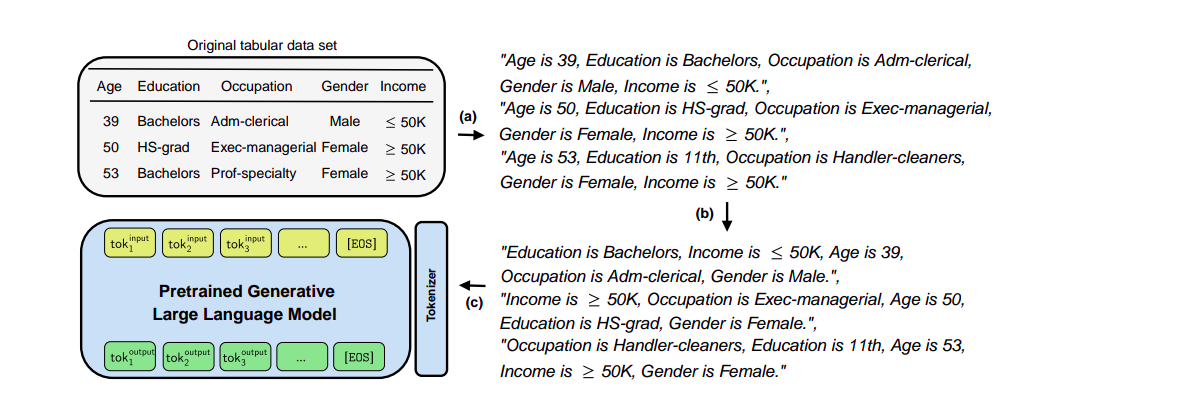
Once the data is been processed, it uses LLMs to do the following:
- Fine-tuning of a pre-trained LLM on textually encoded tabular data, for adapting the LLM to generate a dataset conditioned on prompts and identical to the original dataset.
- Sampling from the fine-tuned LLM to generate synthetic tabular data. More on Figure 3 below.
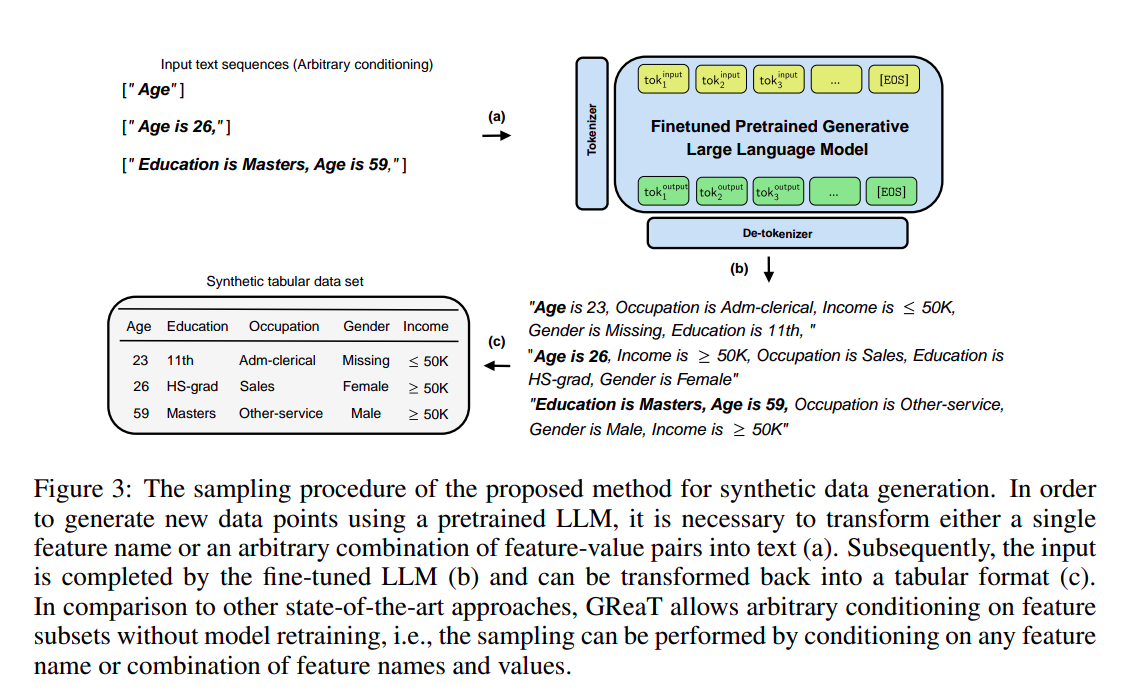
If you are more interested you can dig deeper into their paper. This paper shows us some awesome results when ML models were trained on their generated synthetic dataset. Here are the results from GReaT.
📜 Synthetic Data in Text

Prompting techniques for generation
Synthetic text generation in the era of LLMs seems to be very easy. The importance of using LLMs for synthetic data generation is because the LLM-generated synthetic dataset acts as a proxy for Humans. But, the truth is it is not when it comes to mimicking real-world scenarios. Let's take the simple task of generating tweets since most popular LLMs are trained to provide ethically bounded good quality generations, so most likely, with naive approaches we might not get tweets that mirror the real world. Thus, we are likely to introduce a systematic bias in the system. So, in this section, we will discuss some prompting techniques that help us generate better and more reliable and faithful synthetic texts for curating better synthetic text data. The paper Generating Faithful Synthetic Data with Language Models, introduces us to three methods of generating texts.

- Grounding: Perform in-context learning by putting training examples inside the prompt.
- Filtering: It consist of training a discriminator model (like GANs) to cull unfaithful synthetic datasets. Here it fine-tunes a model to discriminate between real and synthetic data and run on the full batch of grounded synethic datasets.
- Taxonomy: It consists of including a taxonomy in the prompt to encourage diversity. Here it breaks up the LLM generation into two steps. Asking the LLM first to:
- Theorize k-ways a text can possess a specific construct and sample across these k-approaches.
- Re-write the text according to the specific variant of the construct.
These three methods were evaluated on the Sarcasm Detection Dataset (from SemEval-2022). Detecting subtle sarcasm in texts is an inherently difficult task to annotate. These kinds of texts are highly context-specific and ambiguous. Here are the results for all the three methods:
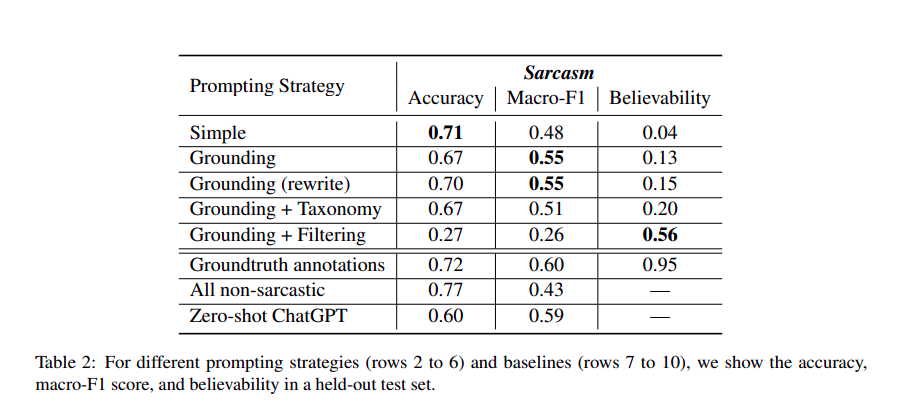
Where Believability estimates on how effective the LLMs are in fooling a synthetic vs real classifier. The dataset with the highest “believability” is the one created using the grounding + filtering strategies. Here is the summary of the key takeaways which we got from the above methods.
- Grounding works the best and is the key aspect of generating synthetic data. Without grounding the model tends to generate texts that are specialized in terms, and does not make it sound much real.
- Taxonomy and Realism: Creating a taxonomy can aid in making synthetic data appear more realistic, but it might not accurately represent the underlying construct.
- Filtering: Works very poorly overall. However, when paired with grounding, it appears to provide the best believability.
Differential Private (DP) Fine-Tuning LLMs to generate privacy-preserved synthetic datasets.
In the previous section, we discussed one key aspect of synthetic data generation is preserving quality and privacy at the same time. It becomes very hard to do both when some private information is correlated with other features. Also, LLMs or in general neural network models tend to memorize their training data [6]. It is very much possible to extract training data from a model. [7]
Researchers from Google, in their paper, Harnessing LLMs to Generate Private Synthetic Text introduce us to methods to generate synthetic datasets from a sensitive dataset. The method uses Differential Private to fine-tune (or DP Fine-tune) methods to tune fewer parameters of LLMs to generate excellent Differential Private synthetic data. Before moving forward, this term might be a bit new for some readers. So let's understand what the Differential Private (DP) training method is.
In the context of Machine Learning Differential Privacy is a concept that focuses on minimizing the chances of identifying individuals or PIIs within a dataset, while still extracting useful information from that data. DP can be of three types as follows:
- Introducing DP in the input level (will discuss in the upcoming sections)
- During the time of model training (DP-Training). This ensures that a particular ML model is DP (or Differentially Private). An example of this method is DP-SGD (Differentially Private Stochastic Gradient Descent), which tries to clip gradients for a batch of examples and injects Gaussian noise to make them private.
- DP during inference. Here during the time of inference, it tries to perturb the output of the prediction or the inference process. Here also we try to add some noise such that it obscures the influence of any single data point on final prediction. However, this method seems to be inferior to DP-Training (the previous method) during large-scale synthetic data.
This paper focuses on the first approach, which seems to be the hardest among the three. The reason it is hard is that DP at the input level ensures that any model trained on DP-SDG should be DP (Differentially Private) w.r.t original data. Whereas approach 2 of DP-Training ensures that a particular ML model is DP. So, the way it achieves this is through a four-step approach.
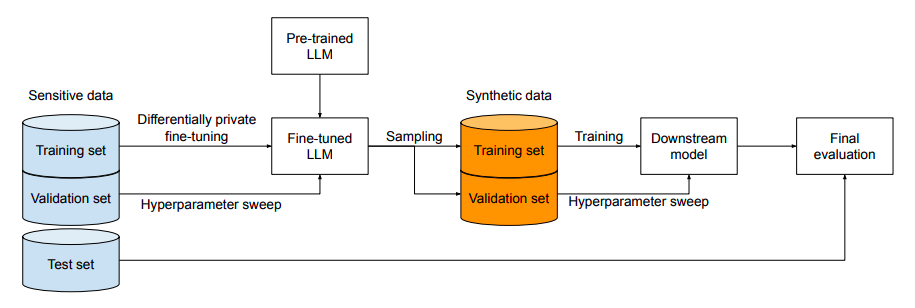
- Start with a sensitive private dataset, where each record of that dataset is protected.
- Privately fine-tune (i.e. using DP-Training) a publicly pre-trained LLM on that dataset.
- Now independently sample from the fine-tuned LLM to generate new synthetic datasets which will serve as synthetic training and validation sets.
- Evaluate a downstream ML model (like a text classifier trained on this synthetic dataset) and compare it with the same models trained on real private data.
For the fine-tuning step, the LLMs were fully fine-tuned and prompt-tuned. Here are some results of downstream ML models when trained on data synthesized from the approach.
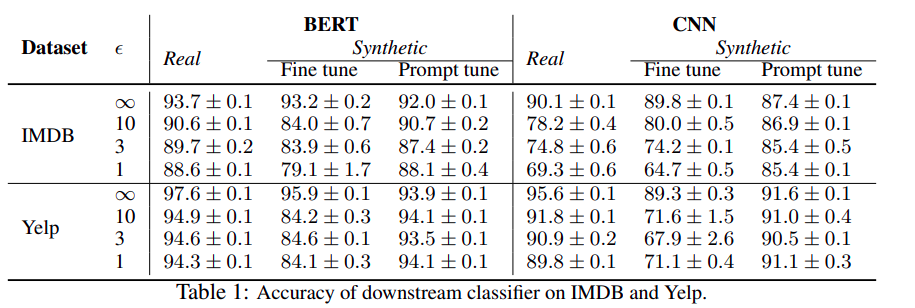
One very interesting thing to note here is, that LLMs when DP-Fine-Tuned using Prompt Tuning with Adam optimizer (In this method we prepend a small learnable prompt tensor in front of the model's input in the embedding space and freeze the rest of the model and only tune that tensor weight. Learn more on Prompt Tuning here.) works better compared to full-finetuning the LLM. One plausible reason for this could be, that in prompt tuning very small number of parameters (20480 compared to 8B) are trained which introduces less overall noise during training leading to more controlled task-specific generation.
🤔 Where to go from here?
Although there are lot to discuss on synthetic data. This article only gives an introduction and some methods to generate synthetic data for various domains. However, industries are right now seeing a huge value in generating synthetic data. Not only that latest LLMs are trained on synthetic data too. Where the synthetic part is the high-quality polished version of normal raw data. Here is some more on the latest industry trends and benefits of training LLMs on synthetic data.
Industry Perspectives on Synthetic Data
AI industry leaders believe synthetic data is key to AGI. Dr. Jim Fan, a senior AI scientist at Nvidia, predicts synthetic data will provide trillions of high-quality training tokens. Elon Musk also supports this view, stating that synthetic data, especially from embodied agents like Tesla's Optimus, will be crucial for AGI. The "bitter lesson" in AI suggests that methods relying more on computation than on human knowledge are more effective, further underscoring the importance of synthetic data.
The Future of Synthetic Data for LLMs
The future of AI heavily relies on synthetic data. Microsoft's phi-2 project showed how synthetic data could enhance AI capabilities. The project's use of synthetic textbooks to train AI models resulted in less toxic content generation and improved coding proficiency. Orca 2 model's success in reasoning tasks also further emphasizes the potential of synthetic data in specialized AI applications.
Conclusion
Synthetic data generation is still a new paradigm of generative AI and still a lot more to go. Overall, there are still a lot of concerns about accuracy, variability, and privacy concerns of the synthetic data when generated at scale. In this article, we understood what synthetic data are and what is synthetic data generation method. We explored different synthetic data generation methods on two important modalities tabular data and text data. Synthetic data for images and video are also very important, however, to keep this blog less overwhelming, we are keeping that for our next release.
📙 References
- A Synthetic Fraud Data Generation Methodology
- Large Language Models are Realistic Tabular data Generators.
- Synthetic Data for Better Machine Learning.
- Harnessing Large Language Models to generate private synthetic text.
- Unlocking the potential of Generative AI for Synthetic Data generation.
- The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks.
- Extracting Training data from Large Language Models.
- Generating Faithful Synthetic Data with Language Models.
- Gemini Technical Report.
- Microsoft Phi2 release.
- Microsoft Orca 2 Paper.