
The Tiny LLM Revolution - Part 1
This article examines the emergence of Small Language Models (SLMs), discussing the impact of high-quality data on their capabilities. It highlights studies like TinyStories and Microsoft's Phi-series, exploring how SLMs can achieve performance comparable to larger models.

Large Language Models (LLMs) became very famous because of the rise of their emergent capabilities and the concept of “one model does it all”, where a single model can do all sorts of tasks like generating emails, and poems, summarizing long papers, generating code, etc. However, LLMs are also infamous for their size and compute.
We cannot deny the fact that Language Models existed before the advent of ChatGPT, but the problem was, during that time, those models either needed to be heavily prompted or could not do all the NLP tasks flawlessly due to weak linguistic or instruction-following capabilities.
Researchers saw that there is a direct relationship between the model’s performance vs scaling the models in terms of the number of parameters, training time, and the amount of data used in training, and hence we got our famous scaling laws. However, there exists another school of thought that believes that Smaller Language Models (a.k.a SLMs) should exist and should be as performant as the existing 7B or 70B parameters LLMs. And the bottleneck that they hypothesize is the quality of data. LLMs are trained on a tremendous amount of data. This data is mainly coming from the web. Still after a lot of filtering and cleanup, we might end up with a huge number of impurities or with less structured or highly complex linguistic data.
What if we train a small language model (a.k.a SLM, with parameter size ≤ 1-3B) with extremely good quality data? Does it reach a similar performance? How does that help us? All of these questions will be answered in this blog post. This post will discuss the journey of the rise of Small Language Models (SLMs). Briefly, we will discuss the TinyStories paper, and the Phi-series models by Microsoft. We will also take a glance at other notable open-source SLM implementations and how they rank in the LLM Leaderboard. Finally, we will discuss the important takeaways from all the current research done on Small Language Models.
🤔 Why do we need smaller LLMs
Closed-source models like GPT-3.5/4 or open-source models like Llama 7/13/70B, and Mistral 7B are awesome for mostly doing any NLP tasks. They are super useful for providing a natural chat-like interface and interacting with systems or acting as an assistant. Since these models consist of a huge number of parameters, this increase in scale brings up a lot of added issues like huge amounts of costs (in millions) to train these models, and additional issues in serving, deploying, and maintaining the model quality in production. Hence the return on investment of integrating LLMs into real business use cases is not very fruitful.
Although LLMs blow up due to the chat-like capabilities (all thanks to ChatGPT), chat assistant or customer support is just one use case. Most of the business's use cases require capabilities that are very much domain-specific, and there we are very hopeful that a small language model (or SLM) can do that fine. This can be super useful for cutting out initial costs to build the model, easily maintaining it across the model lifecycle, and last but not least they are very much interpretable.
🧐 Coming back to first Principles
The question remains as, to why Language Models with a lesser number of parameters can not perform as well as their larger counterparts when both are trained on the same data volume. Smaller LLMs are not something new. We had numerous popular implementations where parameter size ranges between 100M - 1B. For example: GPT-Neo consists of 125M parameters, GPT-2 small consists of 124M parameters, whereas GPT-2 XL consists of 1.5B parameters. But as you have guessed right, besides training these models with huge amounts of data and computing, they were not as performant as they were expected to be.
So, what was the problem? Is the number of parameters really one of the deciding factors and holds a direct proportionality with performance? Well, as mentioned in the introduction, there is a third factor that needs to be considered and that is data quality and its underlined complexity.
The intuition behind creating TinyStories
A normal child (1-3 years of age) starts to learn their first language through simple story/picture books, toys, or cartoon videos. Now suppose, instead of simple picture books, give them high school math or a book on the theory of quantum mechanics or stories from Shakespeare. Even though all of those books were written in their preferred first languages, they are not likely to learn from those books at all. The reason is the semantics of those books were interleaved with very complex logical understandings and a child, who has just started to learn how to talk or write, cannot withstand that complex construct.
Similarly, researchers took a hypothesis that Language Models might also struggle due to those complex language constructs and become more difficult to learn. It can be much easier for a model if they are trained using simple stories rather than Wikipedia articles. The sole purpose of this paper is to prove the above hypothesis, that a small language model can learn to generate coherent texts if trained with data with very little complexity and which is very highly structured.
🤏 TinyStories

You might have heard about Microsoft’s keynote announcement on the Phi-2 model recently, then you would also be surprised to know that the TinyStories paper was the precursor of the Phi model series. This paper does not intend to make another State-of-the-Art Language Model. Rather, the main purpose of this paper is to understand language models with first principles. Simply, understanding the model's correlation with its quality and underlined data complexity it is trained on. This paper also focuses on understanding, from what number of parameters, emergent-capabilities of the language models start to rise, and how textbook-like synthetic data can help in this process. The main contributions of these papers are:
- An open-source synthetic dataset named TinyStories, which consists of small text-book quality story-like paragraphs (with the vocabulary of a typical 3–4-year-old child), generated by GPT-3.5 and GPT-4.
- Small Language Models (SLMs) with several parameters ranging from 1-33M, and an embedding size of 256. A lot of architectural combinations (single transformer block, more than one block, etc) were analyzed to see whether reasoning capabilities emerge or not from out-of-distribution data or not.
- Experiment with the interpretability of these models, since these models are much smaller, and also analyze whether and how much the models are memorizing.
- Evaluation using GPT-4, where GPT-4 is prompted to evaluate the SLM’s generation on grammatical correctness, creativity punctuation, etc.
TinyStories and TinyStories Instruct Dataset
Two variants of the dataset were released in this paper. The TinyStories dataset is a synthetic dataset generated by GPT-3.5/4. Around 1500 basic words (which try to mimic the vocab of a typical 3–4-year-old child separated into nouns, verbs, etc.) are randomized in the prompt to introduce diversity in the dataset as much as possible. In each generation, 3 words are chosen randomly into the story.
TinyStories-instruct on the other hand, is the instruction-following synthetic dataset where the challenge is to produce coherent texts which are relevant and consistent with given instruction or constraint. Example instruction like a list of some words that should be included in a story, or a sentence (like a proverb) that needs to be somewhere in the story, etc. The below figure shows an instance of TinyStories and the instruct dataset.

📊 Evaluation and insights from the TinyStories models
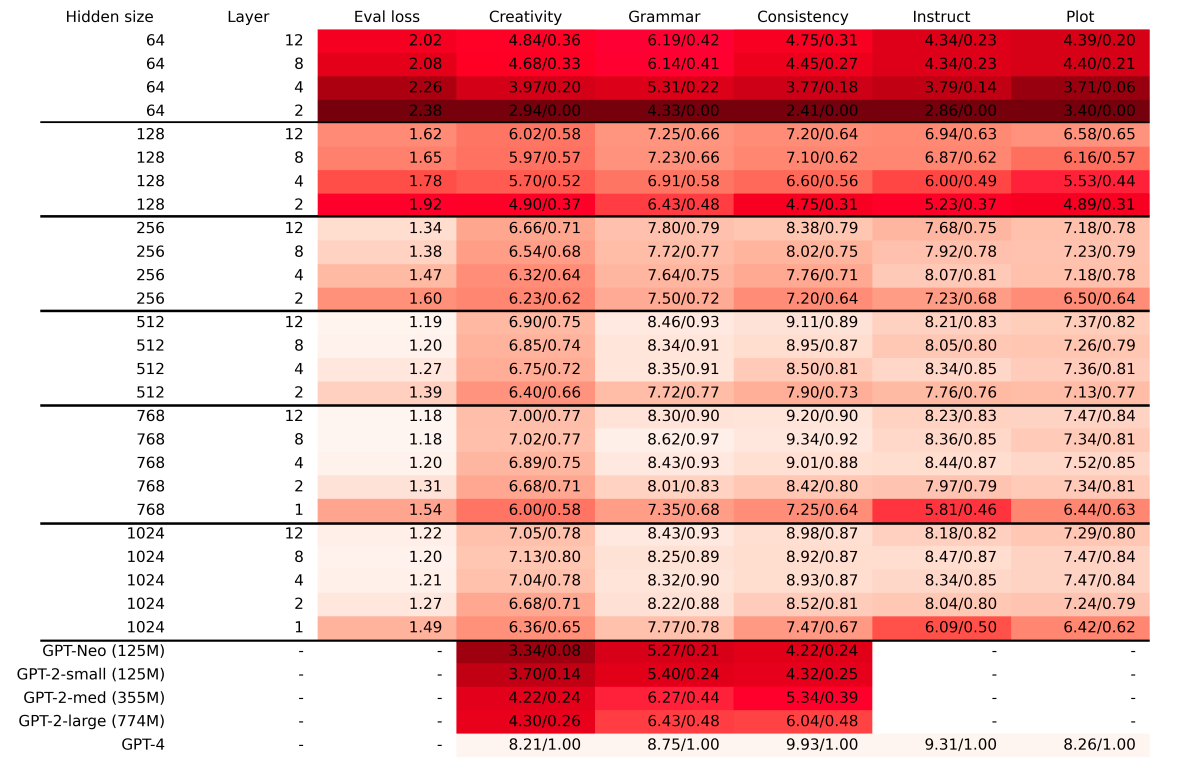
This paper brings some wonderful insights and ways to evaluate and understand the model's performance and its learnings. This section will discuss various methods and key insights analyzed during the evaluation of the model. Before moving forward, please note that this paper has trained several model variants. For example, some models have < 10M parameters with just 1 transformer block. Whereas they also trained the model to 35 M parameters. The evaluations are compared with models with similar sizes like GPT-2 XL etc. All the TinyStories models were trained on single V100 GPUs with a training time of almost 30 hours.
GPT-Eval
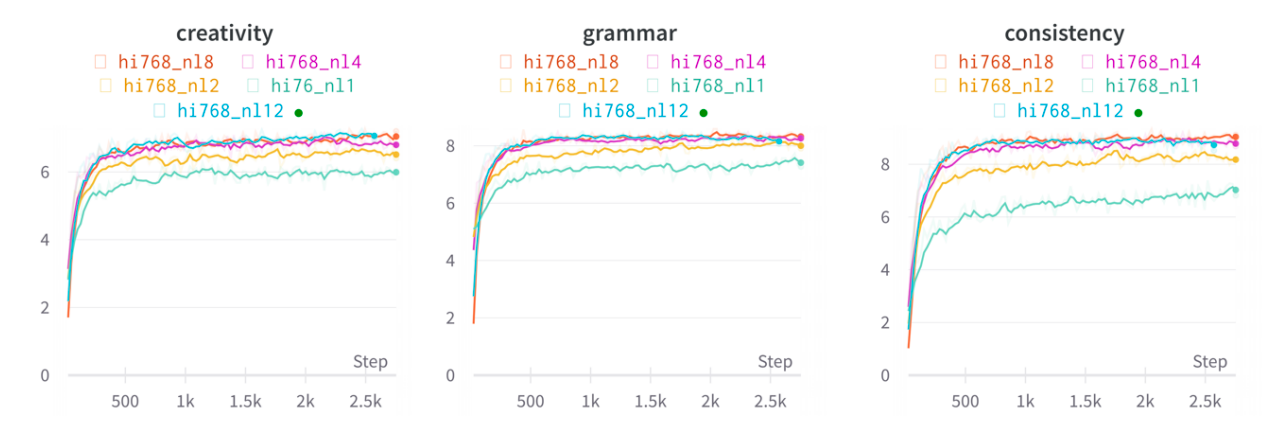
This paper comes up with an innovative way of evaluating using GPT-4. The team created 50 manual handcrafted prompts, where the prompt contained the start of an unfinished story. The task is to simply complete the given story. After this, GPT-4 is carefully prompted to comment on the candidate's response (the response from the TinyStories model) and grade it on grammar, creativity, consistency, and Age group. For each prompt, the candidate generated 10 completions (all with temperature set to 1) and the results were averaged and plotted. We can see in the figure below, that with an increase in a number of parameters and training time, those evaluation results also got better.
Here are some insights that were found in this evaluation.
- Shallow models (with fewer parameters and less number of transformer blocks) excel in grammar but struggle with content consistency, revealing that model depth influences content coherence more than syntactic correctness.
- Grammar proficiency peaks earlier in model training compared to consistency and creativity, with smaller models mastering grammar while larger ones excel in consistency and creativity.
- The transition from generating consistent story continuations occurs when the model's hidden size increases from 64 to 128.
- Creativity only emerges with a larger model size. Grammar (or we can syntax rules) plateaus at an earlier stage than other scores.
- Single-layer models face challenges in instruction-following due to limited global attention, while two layers suffice to some extent. Following instructions relies more on layers, whereas plot coherence is more dependent on hidden dimensions.
Figure 3, shows a detailed visual overview of the above insights.
This same insight was also seen when the models were further evaluated on different instruction-following prompts or out-of-distribution prompts (i.e. containing data whose distribution is not similar to training data).
Some more Insights
Here are some super important insights that were analyzed when the models were evaluated on additional three different types of prompts as follows:
- Factual prompts, which test the models’ knowledge of common-sense facts.
- Reasoning prompts, test basic reasoning abilities, such as cause and effect and elimination.
- Consistency (context-tracking) prompts test the models’ ability to maintain coherence and continuity with the given context, such as the names and actions of the characters, the setting, and the plot.
For each of the prompts, candidates (The TinyStories SLMs) with different configurations were given to generate and their performance was color-coded. Where red means “poor”, green means “right” and yellow means “almost there”. Here are the visualizations for each of them. Figure 4, shows a good visualization of the results of different types of prompts.
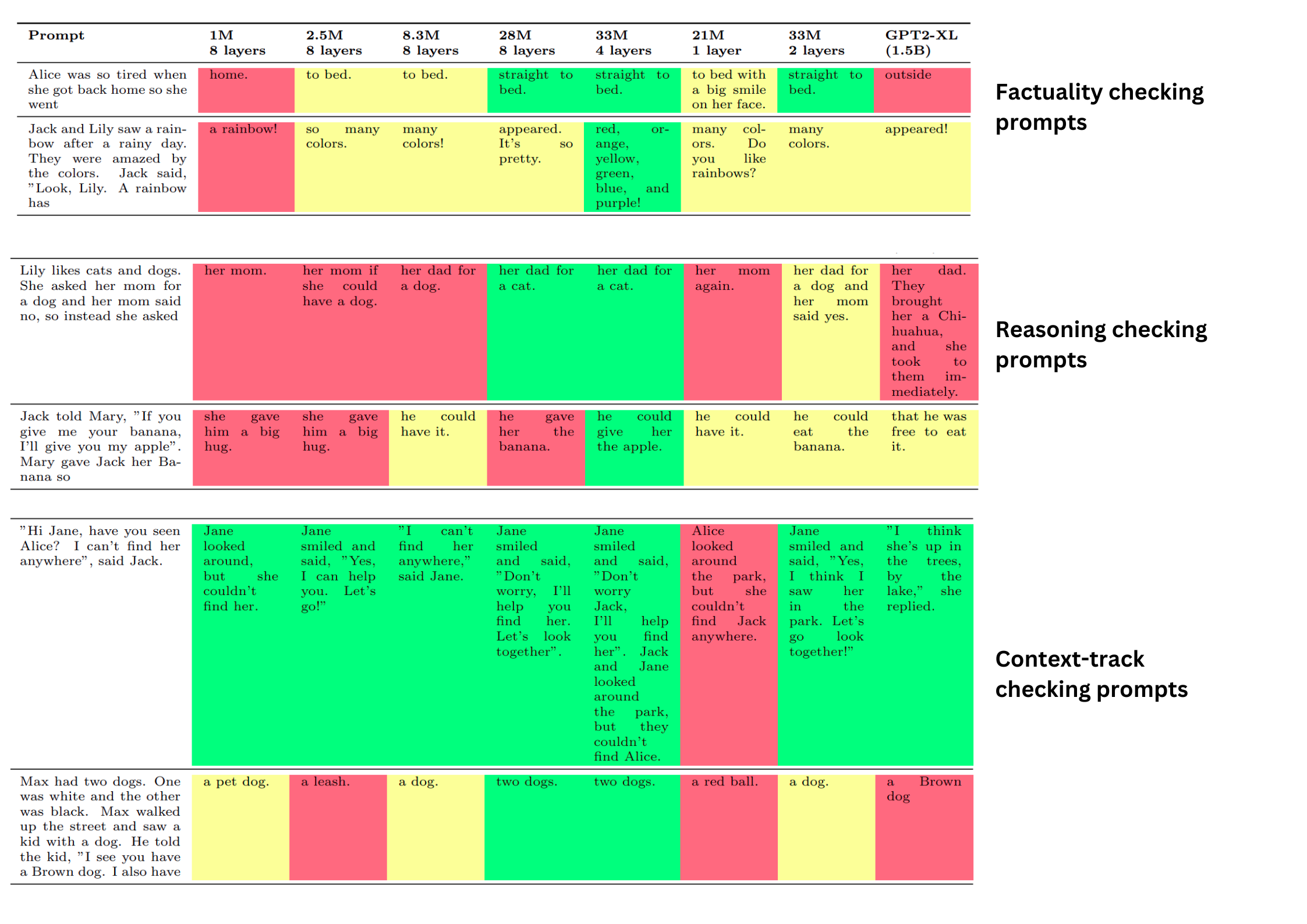
You can get more visualizations on the actual paper. Two very important insights were gathered during the above experimentations:
- The models with higher embedding dimensions and more layers tend to generate more accurate, relevant, and natural continuations, while the models with lower embedding dimensions and fewer layers tend to generate more nonsensical, contradictory, or irrelevant continuations.
- Compared to the completions given by GPT2-XL shows us that despite its much larger size, its performance in all three categories is worse than in some of our models.
💽 Are the models memorizing
Memorization is a very important aspect of a language model that needs strict checking. We need to check whether the model is actually generating text that is aligned with the context or just spitting out some form of content from the existing training dataset.
The paper first starts by comparing the generation of the TinyStories (2.5M parameter) model with GPT-2 XL (1.5B parameter). The prompt was taken from the training dataset. Here is the original training data point.
Sara and Ben are playing in the snow. They make a big snowman with a hat and a scarf. They are happy and laugh. But then a big dog comes. The dog is angry and barks. He runs to the snowman and bites his hat. Sara and Ben are scared and cry. ”Go away, dog! Leave our snowman alone!” Sara shouts. But the dog does not listen. He bites the scarf and the snowman’s nose. He shakes his head and makes the snowman fall. Sara and[Ben run to their house. They slam the door and lock it. They are safe and hug each other. ”Mom, mom, a big dog broke our snowman!” Ben says. Mom comes and hugs them. She is sorry and kisses them. ”Don’t worry, my loves. We can make another snowman tomorrow. But now you need to get warm and have some hot chocolate. You are cold and wet.” She takes them to the kitchen and makes them hot chocolate. She gives them cookies and marshmallows. She tells them to drink and eat in order. Sara drinks first, then Ben. Ben eats first, then Sara. They feel better and smile. They thank mom and tell her they love her. They escape from the big dog and the cold. They are happy and warm.]
The brackets [ ] denote the start of where the models are expected to generate. And here is what the two models generate. The below figure shows the generation from GPT-2XL and TinyStories 2.5M.

Both the generations when compared with the actual training samples tell us that the models do not tend to memorize. Also, if you look closely, TinyStories did a much better job in producing higher-quality text despite being 1000 times smaller. The paper also claims to conduct similar experiments, to see the overlap between generations from the training dataset with the actual data point. And also considering out-of-distribution datasets. And there it’s been seen that the model does not rely on memorization.
Other than this the paper also comes up with three different forms of memorization that they checked on the model. Those are as follows:
- Exact Memorization: An easily detectable, simplest, and most obvious form of memorization where the model copies and pastes the whole story from the training samples.
- Simple Template matching: A slightly more sophisticated form of memorization where the model changes the entities (like the name or place) but keeps the overall content memorized from some training instance.
- Complex Template matching: This is a more subtle form of memorization where the model follows a more abstract pattern or the structure of the dataset and is super hard to detect and quantify.
The paper uses several techniques to quantify or detect the model memorization patterns:
- Rigorous manual inspection: of model’s generation from human-constructed prompts. The models are closely inspected to check that the completions are not copies or close modifications of the stories in the dataset.
- Comparing completion of existing training stories: Here the stories from training samples are being truncated in the middle and the model is asked to generate a completion from there. Then it is checked how much the model copies from the original instance.
- Quantification of the overlap of the generation with the training samples using rouge-score over n-gram overlaps. This inspects the overlap of words and n-grams between different stories generated by the models and compares them with the overlap in the dataset. You can check the mathematical details on the paper. Findings from the paper show that there is a very low overlap with the dataset, indicating that they are not repeating the same words or phrases.
Using all the above tests, the paper claims that the model does not undergo either exact memorization or simple template matching.
🔍 Interpretability
Interpretability in Language Models (LLMs) pertains to the capacity to explain how and why these models generate specific predictions or outputs in human-comprehensible terms. It aims to make the model's decision-making process more transparent and understandable. t is a branch of Machine Learning, that provides statistically significant reasoning of some output from a Machine Learning model.
This section delves into comprehending the interpretability of the model by scrutinizing two primary components.
- Attention Heads: Exploring the functionality of the attention mechanism involves training a notably shallow model, comprising a single-block transformer, yet proficient in producing coherent texts. Within this framework, the attention heads directly oversee the generation of output tokens, affording them heightened interpretability.
- Neurons in MLP: The study discerns that certain neurons within the Multi-Layer Perceptron (MLP) exhibit activation patterns aligned with specific linguistic roles in English, such as identifying subjects or actions. For instance, within the narrative, these neurons respond distinctly to pivotal elements, such as the introduction of the protagonist, exemplifying their nuanced encoding of semantic and stylistic information.
For conducting both experiments (i.e. dependency of attention heads and MLPs), the following prompt was used to conduct all the visualization.

Visualizing Attention Heads
There are two types of attention which have been observed. Those are as follows:
- Distance-based attention: Out of the 16 attention heads, we observe multiple positional-based attention heads, such that each token attends to tokens with a prescribed relative distance. Different heads are associated with different distances.
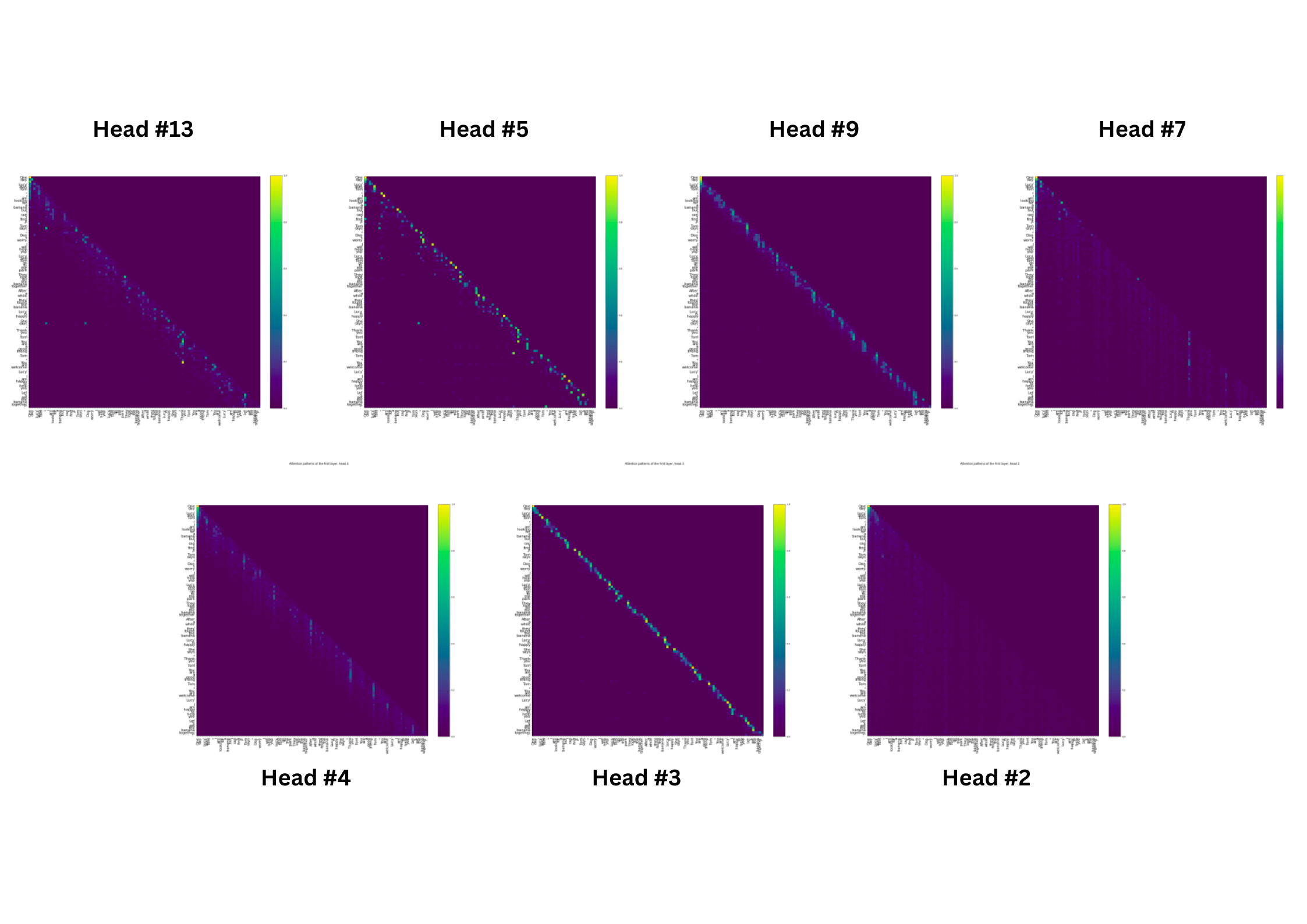
- Semantic-based attention: Some distinct attention heads exhibit intriguing behaviors: one head shows "the" and "a" directing attention to "banana," including a connection between "the" from "the park" to "banana," yet consistently generates "park" as the completion; another head displays both "the" and "a" attending to "park," while a third head predominantly focuses on words associated with "Tom" and "Lucy." This observation supports the premise that words like "the," "a," and punctuation rely on local attention heads due to their grammatical roles, while entities like "banana," "park," "Lucy," and "Tom" necessitate semantic attention heads due to their contextual complexity beyond immediate neighboring tokens.
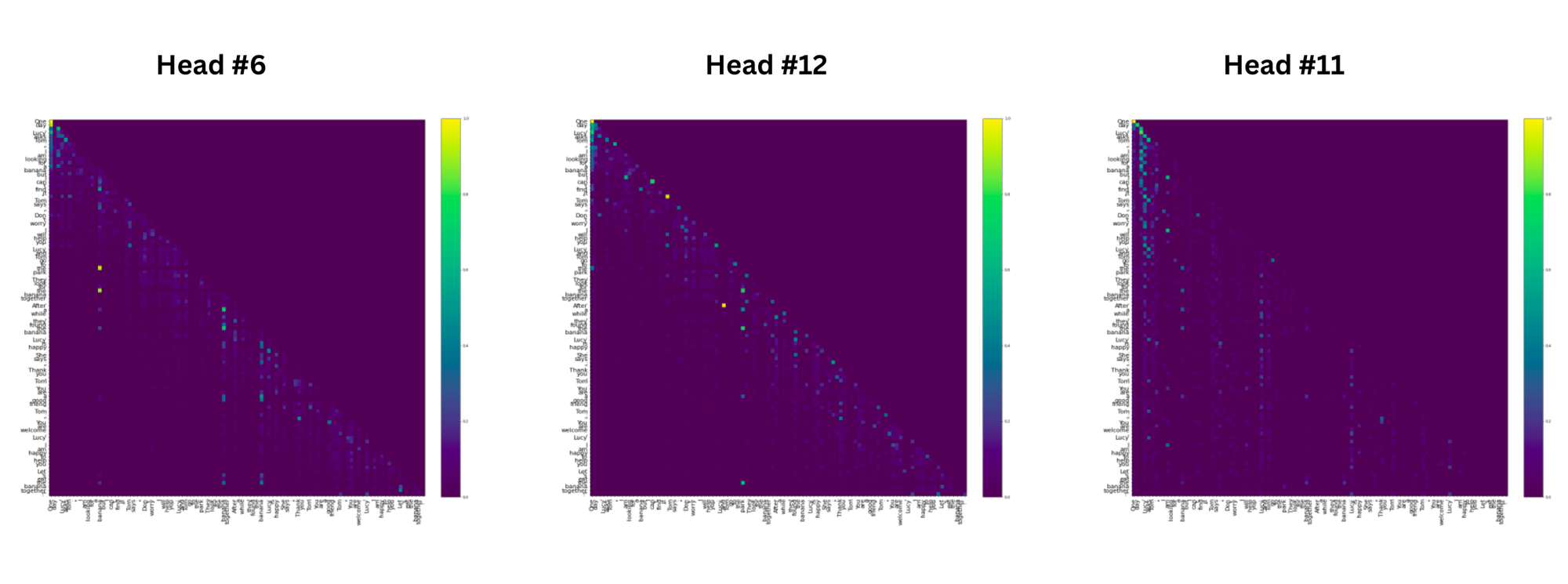
Visualizing MLP Layers
To investigate neuron roles, the study employs a method from previous work, visually presenting the most influential tokens for each neuron within specific layers of two models: a smaller one with 1M parameters trained on TinyStories and a larger GPT2-XL model. Using a collection of 20 stories, the researchers extract internal representations by activating neurons in the before-last and layer 6 of the small model. They identify distinct activations: one set reacts to pronouns or subjects, another to action words, and a third specializes in adjectives. Notably, a neuron in the small model appeared geared towards recognizing the initial mention of a story's protagonist. However, within GPT2-XL, the activated tokens for neurons in layer 12 exhibited no apparent discernible roles, indicating a difference in interpretability between smaller and larger models. The visualization below gives a clearer idea.

⭐ Conclusion
In this first part of our blog post, we learned with first principles and saw a step-by-step approach to understanding the generation quality of LLMs with the data it is trained on. The direction is clear: Smaller Language Models can achieve performance comparable to present 7B or 70B LLMs, if the data is properly structured and not very complex. In the next blog post, we will be discussing some recent popular Small Language Models like Phi-1/1.5 and 2, Falcon 1B, StableLM 3B, etc. We will also compare these small LMs with popular LLMs like Mistral 7B and LLama 2. So, stay tuned!
🌀 References
- Scaling Laws for Neural Language Models
- TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
- Number every LLM developer should know.
- Explainability of Large Language Models: A survey.
- The Illustrated Transformer
- Emergent Capabilities of Large Language Models.
- Interpretability Methods in Machine Learning: A Brief Survey
- Visualizing and Understanding Neural Models in NLP.
- Mistral 7B
- Llama 2: Open Foundation and Fine-Tuned Chat Models