Transformer Inference: Techniques for Faster AI Models
Transformer inference powers tasks in NLP and vision, but is computationally intense, requiring optimizations. Large models like GPT-3 need extensive memory and FLOPs, with techniques like KV caching, quantization, and parallelism reducing costs.

What is Transformer Inference?
Transformer models, known for their self-attention mechanisms, are central to tasks like NLP and computer vision. Inference, the phase where these models generate predictions on unseen data, requires significant computational resources.
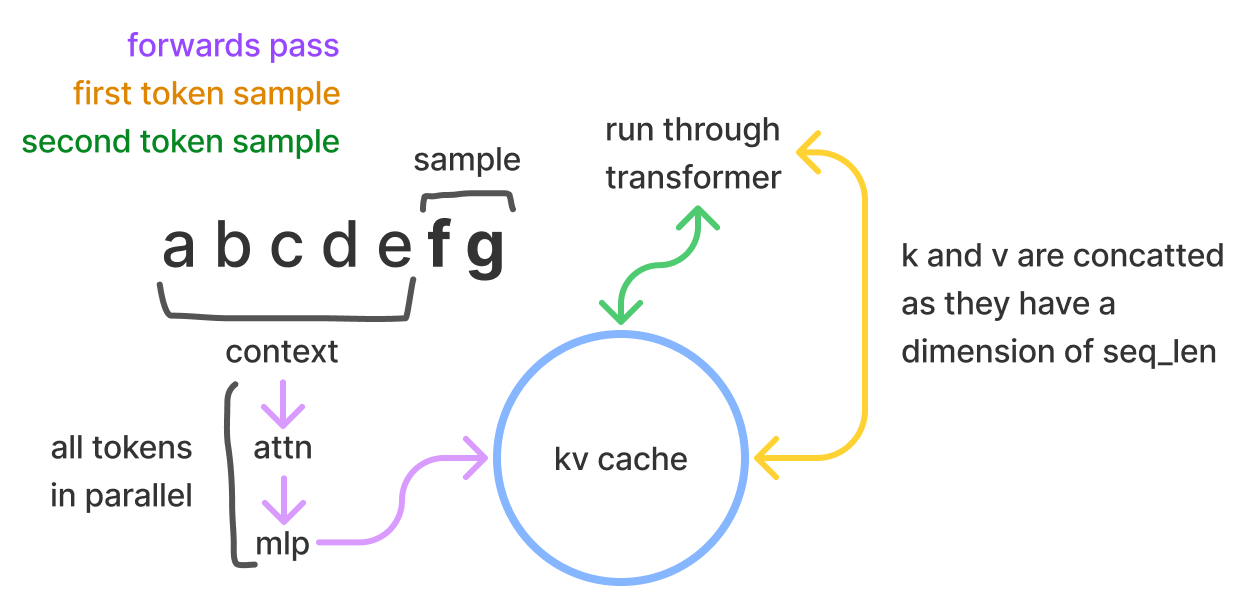
One key factor affecting transformer inference is the number of floating-point operations (FLOPs). Each layer involves matrix multiplications, and for large models like GPT-3, this can amount to trillions of FLOPs per token. To reduce computational overhead, Key-Value (KV) caching is used, allowing the model to reuse previously computed attention vectors, speeding up autoregressive decoding.
Memory usage is another constraint, with models like GPT-3 demanding over 200 GB of memory. Techniques like quantization and parallelism help manage these resources more efficiently, but transformer inference often remains memory-bound, where memory bandwidth limits the speed of computation.
Transformer Architecture and Inference Flow
The core architecture of transformers is based on the self-attention mechanism and a series of stacked layers, each comprising attention and feed-forward networks. During inference, transformers apply pre-trained parameters to make predictions, typically token by token in autoregressive models like GPT.
Inference involves several matrix operations, particularly matrix-vector multiplications in each attention layer. For each new token, the model computes query (Q), key (K), and value (V) vectors by multiplying input embeddings with learned weight matrices.
The attention mechanism calculates relevance scores by multiplying the query with the transposed key matrix, scaling the result by the square root of the dimension size, and applying a softmax function. This process allows the model to weigh the importance of each token in the sequence. While highly effective, these matrix multiplications are computationally expensive, particularly in large models like GPT-3 or LLaMA, where each attention head performs billions of FLOPs per token.
Phases of Transformer Inference: Prefill and Decode
Transformer inference operates in two key phases: prefill and decode. These phases dictate how the model processes input tokens and generates output tokens, with different performance implications for each.
1. Prefill Phase: In the prefill phase, the model processes the entire input sequence in parallel, transforming tokens into key-value pairs. This phase is computationally intensive but highly parallelizable, enabling efficient GPU utilization. Operations primarily involve matrix-matrix multiplications, allowing the GPU to handle multiple tokens simultaneously. Prefill excels in batch processing, where large amounts of data can be processed together, minimizing latency.
2. Decode Phase: The decode phase is more memory-bound and sequential, generating tokens one by one. Each new token depends on the previously generated tokens, requiring matrix-vector multiplications, which underutilizes the GPU compared to the parallel nature of the prefill phase. The sequential process introduces latency bottlenecks, making this phase significantly slower, especially in large models like GPT-3.
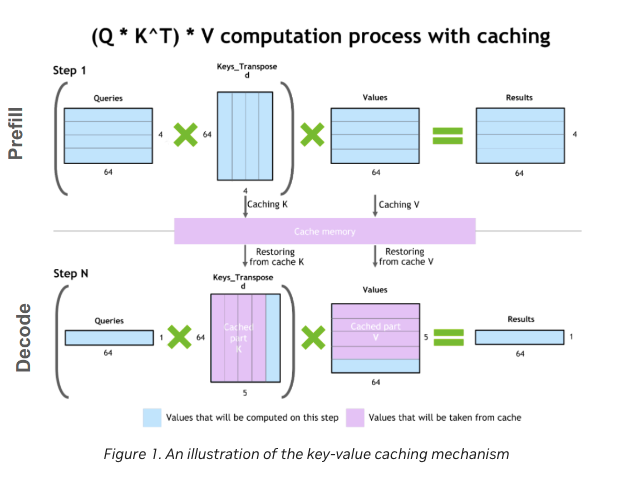
Key-Value (KV) Caching is a critical optimization in the decode phase. By storing previously computed key-value matrices, the model avoids recomputation, reducing complexity from quadratic to linear.
Challenges in Transformer Inference
Large transformer models, especially Large Language Models (LLMs) like GPT-3, introduce several challenges during inference due to their size and compute requirements. These challenges revolve around memory limitations, latency, and balancing between memory-bound and compute-bound operations.
1. Memory and Computational Demands:
Storing both model weights and the key-value (KV) cache during inference requires vast amounts of memory. Large models like GPT-3, with 175 billion parameters, often need over 200 GB of memory. Additionally, the KV cache size grows linearly with sequence length and batch size, further increasing the memory burden. For instance, a LLaMA model with 7 billion parameters and a sequence length of 4096 can consume around 2 GB of memory just for the KV cache.
2. Latency in Sequential Token Generation:
Latency is a critical issue, especially in the decode phase, where tokens are generated one at a time. Each new token depends on the previous one, which results in sequential operations that underutilize the GPU’s compute power. Even highly optimized models suffer from memory bandwidth bottlenecks, which become more pronounced as the sequence length increases.
3. Balancing Batch Size and Performance:
Larger batch sizes can improve GPU utilization, especially during the prefill phase, but they are limited by memory capacity. Increasing batch size helps maximize throughput, but only up to the point where the system becomes memory-bound. Beyond this, the system may encounter diminishing returns, as memory bandwidth starts to limit further performance gains.
4. Trade-offs in Memory-Bound vs. Compute-Bound Operations:
Transformer inference alternates between memory-bound and compute-bound operations. During the decode phase, matrix-vector multiplications are often memory-bound, while prefill matrix-matrix operations tend to be compute-bound. Effective optimization of batch size, KV cache management, and precision (e.g., FP16, INT8) is crucial for reducing latency and ensuring efficient GPU use.
Optimisation Techniques for Faster Inference
As transformer models like GPT-3, LLaMA, and other large language models (LLMs) continue to scale, optimisation techniques have become essential for managing the increased memory, computational load, and latency associated with inference. By applying techniques like quantization, key-value (KV) caching, speculative decoding, batching, and parallelism, developers can significantly improve inference performance.
1. Quantization
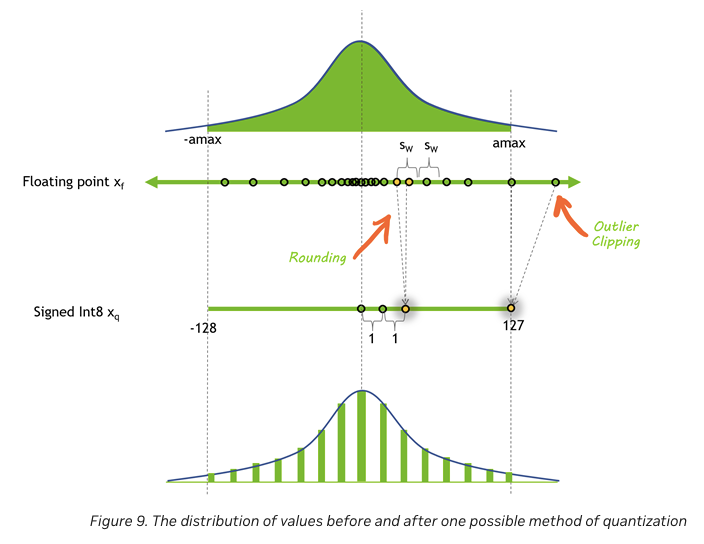
Quantization reduces the precision of model weights and activations, allowing for faster computation and lower memory usage. Instead of relying on 32-bit or 16-bit floating-point precision, models can use 8-bit (INT8) or even lower, which reduces memory bandwidth and allows the model to handle larger batch sizes or longer sequences more efficiently.

For example, applying INT8 quantization to GPT-3 can result in up to a 50% reduction in memory requirements, directly leading to lower latency and higher throughput during inference. Quantization is particularly useful for memory-bound models that face bandwidth limitations.
2. Key-Value (KV) Caching
In autoregressive models, each new token generation requires accessing all previous tokens. This leads to a quadratic increase in computations as the sequence length grows. KV caching mitigates this by storing key and value tensors from previous tokens, allowing the model to reuse them without recomputation.
The size of the KV cache grows linearly with the number of tokens, layers, and attention heads. For instance, in the LLaMA 7B model, a sequence length of 4096 tokens would require approximately 2 GB of memory for the KV cache.
This optimization significantly reduces the computational load in the decode phase, improving both speed and memory efficiency.
3. Speculative Decoding
Speculative decoding is an advanced optimization technique that reduces latency by parallelizing token generation. Instead of waiting for each token to be processed sequentially, speculative decoding uses a smaller draft model to predict several tokens ahead, verifying the predictions with the main model. If the predictions are accurate, they are accepted; if not, they are discarded.
This approach allows for parallel execution, reducing the overall time required for token generation while maintaining accuracy. It’s especially useful for real-time applications, such as chatbots, where fast response times are crucial.
4. Batching
Batching is a straightforward yet powerful technique for optimizing transformer inference. By processing multiple inputs simultaneously, batching improves GPU utilization, as the memory cost of the model’s weights is shared across multiple requests. However, batching is limited by available memory, particularly in models with long sequences.
A challenge with traditional batching is that different requests within a batch may generate varying numbers of output tokens. This can lead to inefficiencies, as all requests must wait for the longest-running one to complete. To address this, in-flight batching allows the system to evict completed requests from the batch immediately, freeing up resources for new requests.
5. Hardware Optimisation: Parallelism
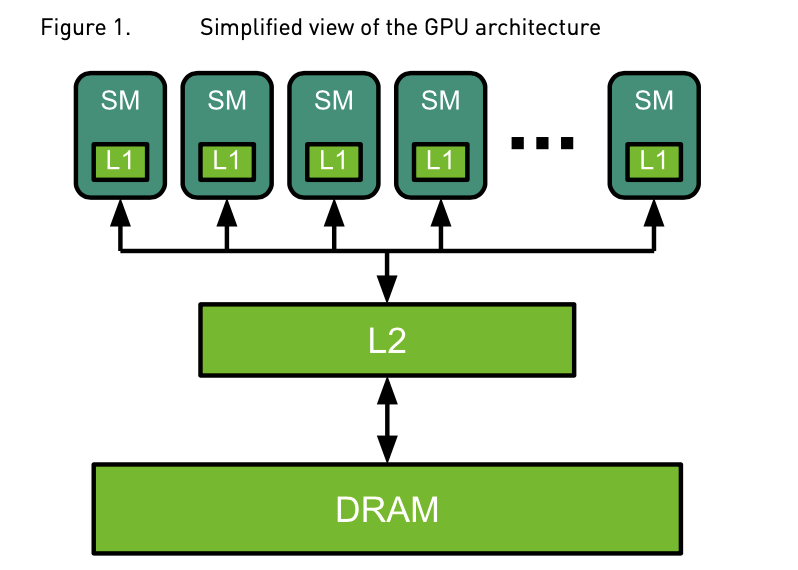
Hardware optimizations, particularly tensor parallelism and pipeline parallelism, are critical for scaling large models. These methods distribute the computational load across multiple GPUs, allowing systems to handle models that exceed the memory capacity of a single GPU.
· Tensor Parallelism: This technique splits a model’s parameters across multiple GPUs, enabling them to process different parts of the same input in parallel. Tensor parallelism is particularly effective for attention layers, where different attention heads can be computed independently.
· Pipeline Parallelism: This approach divides the model into sequential chunks, each processed by a different GPU. Pipeline parallelism reduces the memory footprint per GPU, allowing larger models to run efficiently. However, it introduces some idle time between GPUs while waiting for data from previous stages.
Both forms of parallelism are essential for managing large models like GPT-3 and LLaMA, where memory and computational demands often exceed the capabilities of a single GPU.
6. FlashAttention and Memory Efficiency
Another critical advancement is FlashAttention, which optimizes memory access patterns by reducing the number of times data is loaded and stored in memory. FlashAttention leverages GPU memory hierarchies to perform computations more efficiently, fusing operations and minimizing data movement. This technique can lead to significant speedups, especially in models with large sequence lengths, by reducing memory waste and enabling larger batch sizes.
Inference Optimization in Large Language Models (LLMs)
Optimizing inference for large language models (LLMs) like GPT-3 and LLaMA requires a combination of techniques to manage memory, reduce latency, and increase throughput. This case study demonstrates how key optimization techniques—KV caching, quantization, and parallelism—are applied in practice to improve inference performance for these models.
1. GPT-3: Efficient Inference with KV Caching and Quantization
GPT-3, with 175 billion parameters, poses significant challenges in terms of memory usage and computational load. Two major optimizations, KV caching and quantization, have proven essential for improving GPT-3’s inference efficiency.
· KV Caching: During inference, GPT-3 processes tokens autoregressively, where each token depends on all previously generated tokens. Without KV caching, this would result in a quadratic growth in computation. However, KV caching stores previously computed key-value pairs, which are reused for subsequent tokens, reducing computation time significantly. For long sequences (e.g., 4096 tokens), the KV cache can occupy several GBs of memory.
· Quantization: By reducing the precision of model weights from 32-bit or 16-bit to 8-bit (INT8), quantization helps lower memory bandwidth requirements, allowing for faster computation and larger batch sizes. In GPT-3, quantization can result in up to a 50% reduction in memory usage, directly enhancing throughput and reducing latency during inference.
2. LLaMA: Scaling with Model and Pipeline Parallelism
The LLaMA family of models (e.g., 7B, 13B, 65B) employs model parallelism to efficiently distribute its computational workload across multiple GPUs. For larger models like LLaMA 65B, where a single GPU cannot handle the entire model, tensor parallelism and pipeline parallelism are critical.
· Tensor Parallelism: By splitting attention heads and feed-forward layers across GPUs, tensor parallelism allows LLaMA to handle longer sequences without overwhelming a single GPU's memory. This technique ensures that the model can generate tokens efficiently across multiple GPUs without memory bottlenecks.
· Pipeline Parallelism: To further optimize memory usage, pipeline parallelism splits the model into sequential chunks, where each GPU processes a specific subset of layers. While this approach introduces some idle time between GPUs, it reduces the overall memory footprint per GPU and helps balance the load across devices, making it possible to scale LLaMA efficiently for inference.
3. Benchmarking Inference Performance
Benchmark tests for both GPT-3 and LLaMA illustrate the impact of these optimizations. For GPT-3, the combination of KV caching and quantization has been shown to reduce inference time by up to 60% compared to unoptimized models, with throughput reaching hundreds of tokens per second. In LLaMA, the use of parallelism techniques ensures that even the largest models, like LLaMA 65B, can maintain high throughput while keeping latency under control.
These optimizations allow both models to scale effectively, ensuring that they can handle real-world applications, from long-context generation to real-time responses, with significantly reduced computational and memory demands.
Trends in Transformer Inference
As transformer models continue to grow in size and complexity, optimizing inference is crucial for keeping up with the demands of real-world applications. The next wave of innovations focuses on scaling transformer models efficiently, improving memory management, and leveraging advanced hardware capabilities. Below are some of the most impactful trends shaping the future of transformer inference.
1. Memory Optimization with Paging and FlashAttention
A key trend is optimizing memory usage through techniques like PagedAttention and FlashAttention. In current inference processes, models often over-provision memory to handle the maximum possible sequence length, which leads to inefficiencies. PagedAttention addresses this by allocating memory only as needed, breaking the key-value (KV) cache into smaller blocks that are fetched on demand.
FlashAttention further enhances memory efficiency by optimizing the order of computations and reducing data movement between memory and compute units. By fusing operations and leveraging GPU memory hierarchies, FlashAttention can significantly reduce memory waste and enable larger batch sizes and faster processing. These advancements will be key to scaling large models while maintaining high performance.
2. Multi-Query and Grouped-Query Attention
Optimizing the attention mechanism itself is another important trend. Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) are two variations that reduce the memory footprint while maintaining model performance. In MQA, all heads share the same key-value pairs, which reduces the size of the KV cache while preserving accuracy.
Grouped-Query Attention (GQA), which strikes a balance between MQA and traditional multi-head attention, uses shared key-value pairs for grouped heads. This approach further reduces memory usage while maintaining high performance, making it particularly useful for long-context models like LLaMA 2 70B.
3. Parallelism: Tensor and Sequence
Parallelism remains a central strategy for scaling large models. Tensor parallelism divides model layers into independent blocks that can be processed across multiple GPUs, reducing the memory burden on individual devices. This method works well for attention heads and feed-forward layers, where parallel processing can significantly boost efficiency.
vSequence parallelism further improves memory efficiency by splitting operations like LayerNorm and Dropout across the sequence dimension. This reduces memory overhead, particularly for long-sequence tasks, and allows models to scale more effectively.
4. Speculative Inference for Real-Time Applications
For real-time applications, speculative inference offers an innovative approach to reduce latency. By using smaller draft models to predict multiple tokens ahead, speculative inference allows for parallel execution. The draft tokens are then verified by the main model, which either accepts or discards them.
This technique helps bypass the sequential nature of autoregressive models, making it especially useful in low-latency applications such as chatbots and real-time language models. By parallelizing token generation, speculative inference enables faster responses while maintaining accuracy.
References:


 Shashank Verma
Shashank Verma