What Is a Unified AI API? How to Access Multiple LLMs from One Endpoint
Learn what a unified AI API is, why enterprises use them, and how to evaluate LLM gateways. Compare PremAI, OpenRouter, LiteLLM, Portkey, and more.

Your engineering team uses GPT-4o for summarization, Claude for document analysis, Gemini for multimodal tasks. That's three SDKs. Three authentication flows. Three billing dashboards. Three sets of rate limits to monitor.
Now add a fourth model. And a fifth.
Enterprise LLM spending jumped from $3.5 billion to $8.4 billion in just two quarters of 2025. Teams are running more models in production than ever. 37% of enterprises now use five or more models. Managing each integration separately is a tax that compounds fast.
A unified AI API fixes this. One endpoint, one SDK, one bill. Your application talks to a single interface, and the API routes requests to whatever provider you need.
This guide covers what a unified AI API actually does, which platforms are worth evaluating, and how to pick one that fits your stack, especially if your needs go beyond basic routing.
What Is a Unified AI API?
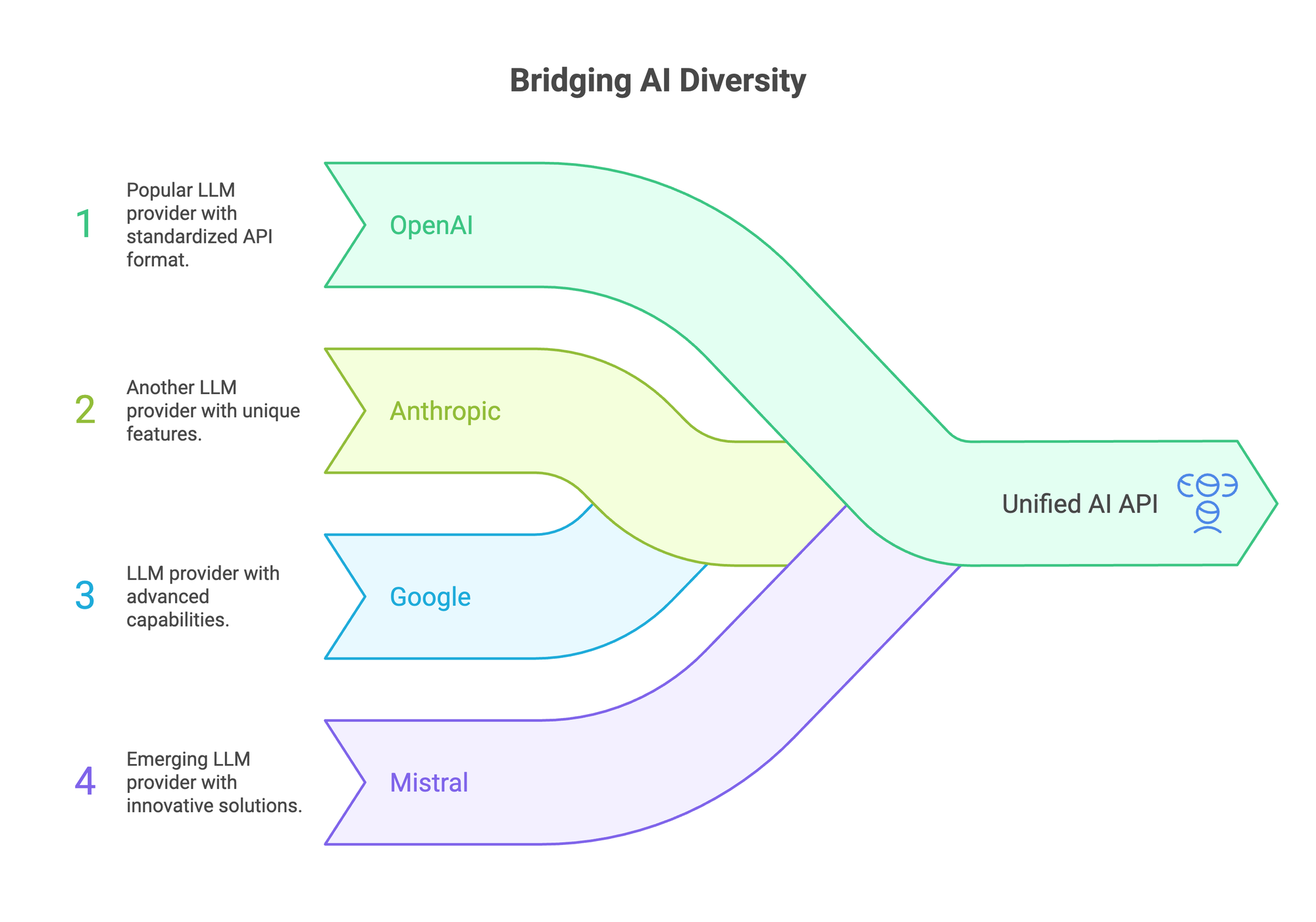
A unified AI API is a single interface that abstracts multiple LLM providers behind one endpoint. Your application code stays the same. Only the model name changes.
The architecture is straightforward:
- Your app sends a request to the unified endpoint
- The API layer routes it to the right provider (OpenAI, Anthropic, Google, Mistral, etc.)
- The response comes back in a standardized format
Most unified APIs follow the OpenAI chat/completions format as the standard. If your codebase already uses the OpenAI SDK, switching to a compatible gateway can take minutes. Change the base URL and API key, and everything else stays the same.
Two main flavors exist:
Managed gateways like OpenRouter or Eden AI run the infrastructure for you. Sign up, get an API key, start routing requests. Zero server management.
Self-hosted proxies like LiteLLM give you the same abstraction layer but you run it on your own infrastructure. More setup, more control, particularly over data flow.
Quick note on terminology: "AI gateway," "LLM proxy," "LLM router," and "unified LLM API" all describe the same concept. Different vendors, different labels, same core function.
Why Enterprise Teams Are Adopting Unified AI APIs
The shift toward unified AI APIs isn't a trend chasing exercise. It's a response to real operational problems that get worse as AI usage scales.
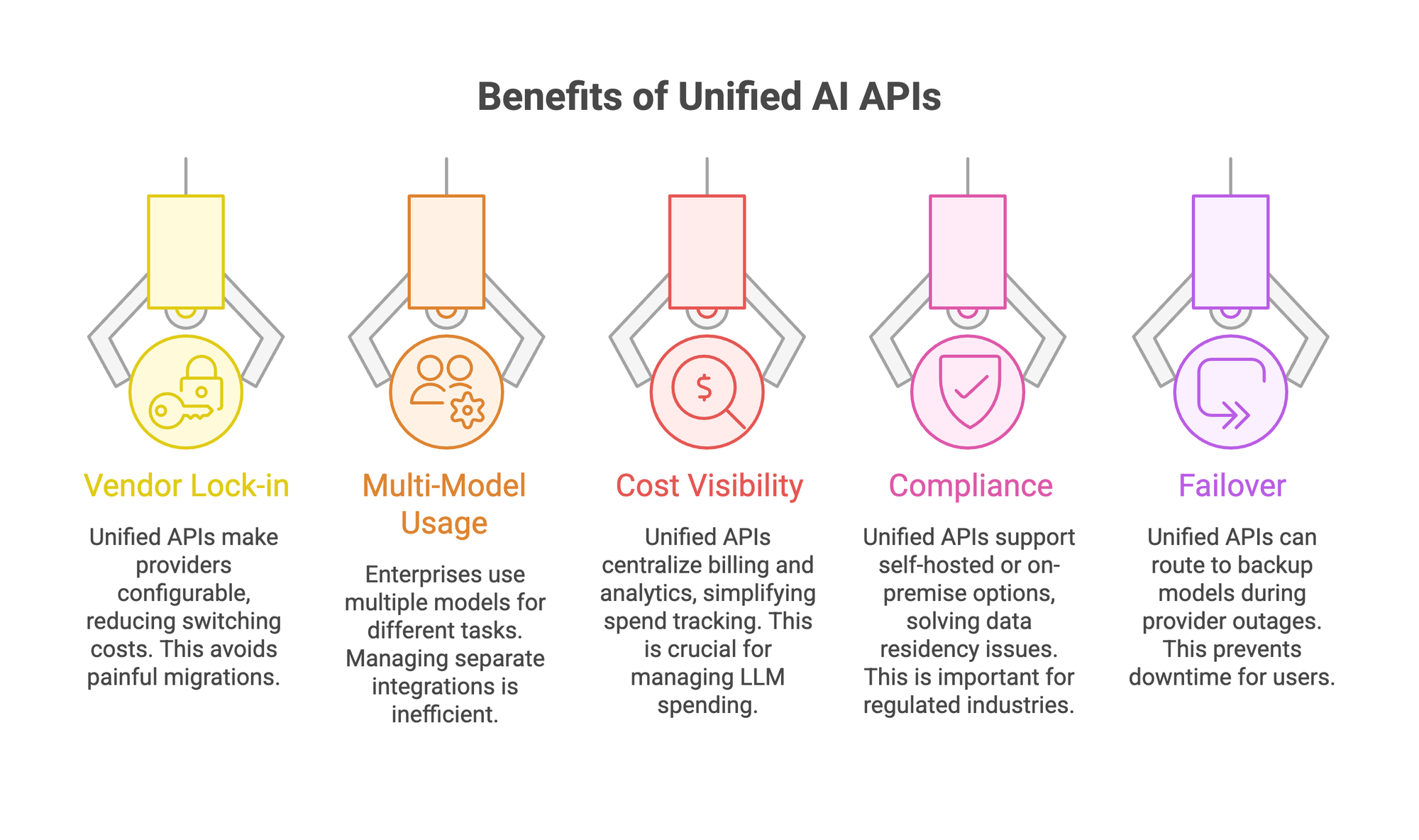
1. Vendor lock-in gets expensive.
When you hard-code to one provider's SDK, switching costs are real. A unified API makes the provider a config variable instead of an architecture decision. Only 11% of enterprise teams switched LLM vendors in the past year, not because they didn't want to, but because migration is painful. A unified API removes that friction.
2. Multi-model is the default now.
According to a Menlo Ventures survey, 69% of enterprises used Google models, 55% used OpenAI, and Anthropic's share hit 32-40% in 2025. Teams aren't picking one provider. They're mixing models based on task performance and cost. One model for code generation (Claude holds 42% market share there), another for classification, another for customer-facing chat. Managing each integration separately doesn't scale.
3. Cost visibility matters.
With separate providers, tracking spend across projects means reconciling multiple dashboards. A unified API centralizes billing and usage analytics in one place. When 72% of enterprises plan to increase LLM spending this year, knowing where that money goes is worth the investment alone.
4. Compliance creates hard constraints.
Regulated industries can't route customer data through arbitrary third-party infrastructure. A unified API that supports self-hosted deployment or on-premise options solves the data residency question at the infrastructure level.
5. Failover prevents outages.
Provider downtime happens. When your app is hard-wired to a single provider, an outage means downtime for your users. A unified API can route to backup models automatically.
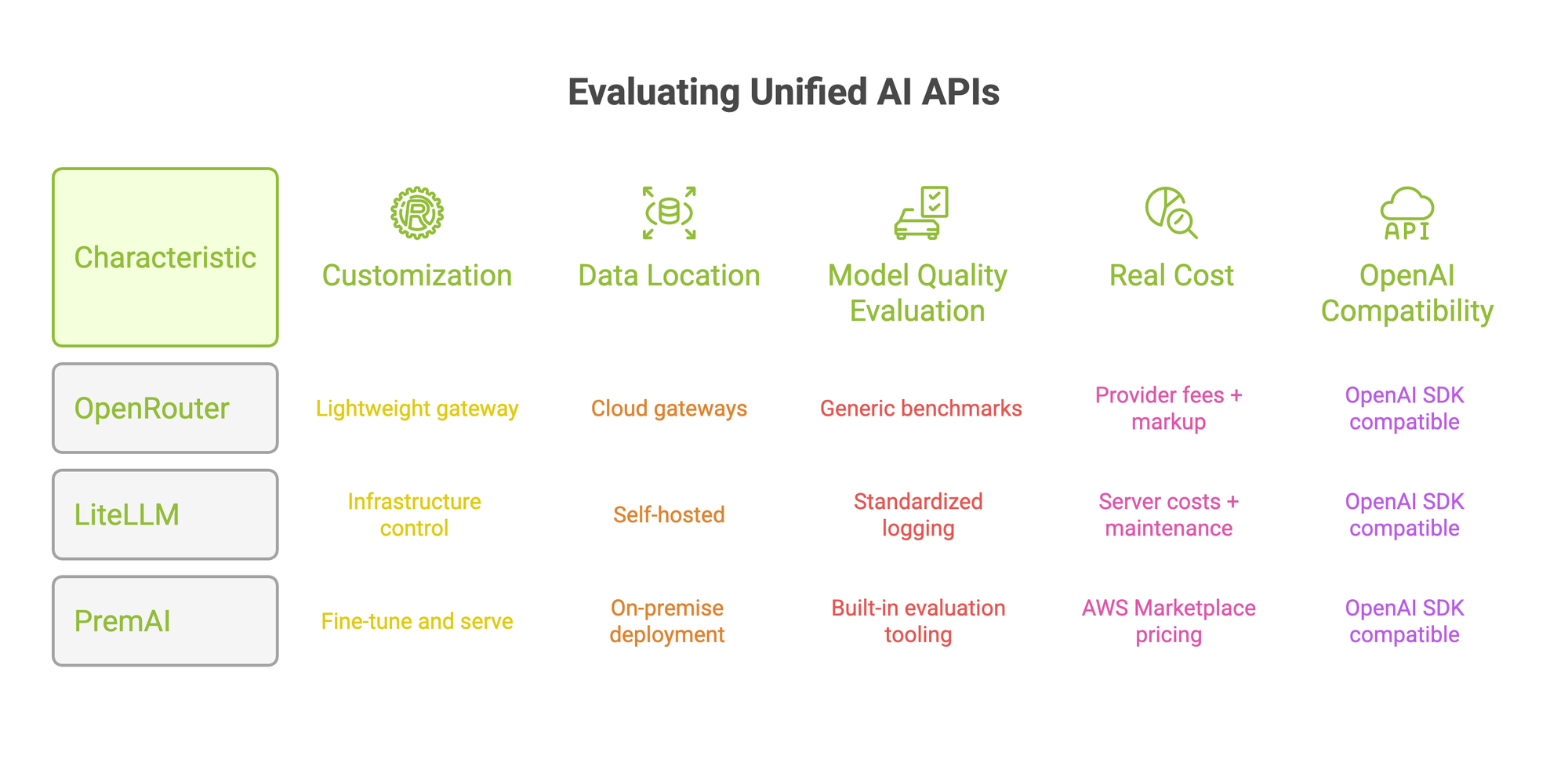
Top Unified AI API Platforms Compared
Here's where the market stands. Each platform approaches the "unified API" problem differently, and the right choice depends on what you need beyond basic routing.
1. PremAI
PremAI isn't a gateway in the traditional sense. It's a full enterprise AI stack built around an OpenAI-compatible API.
You get unified model access, yes, but also fine-tuning across 30+ base models (Mistral, LLaMA, Qwen, Gemma), built-in evaluation with LLM-as-a-judge scoring, and one-click deployment to AWS VPC or your own infrastructure.
The differentiator is data sovereignty. PremAI is Swiss-headquartered, SOC 2 compliant, and runs a zero data retention architecture with cryptographic verification. For teams in finance, healthcare, or any regulated industry where prompts contain sensitive data, this matters. Your data never leaves your control.
Pricing runs through AWS Marketplace on a usage-based model, with enterprise tiers available for reserved compute and volume discounts.
Best for: Enterprise teams that need model customization alongside unified access, particularly those with data residency requirements.
2. OpenRouter
OpenRouter is the largest model marketplace available through a unified API. Over 500 models from 50+ providers, accessible through an OpenAI-compatible endpoint. Sign up, get an API key, and start making requests.
Pricing follows a pass-through model: you pay the provider's rate plus roughly a 5.5% platform fee on credit purchases. Credits expire after one year. Latency overhead sits around 25-40ms in production, which is negligible for most use cases given that model inference itself takes hundreds of milliseconds.
OpenRouter added SOC 2 Type I certification in July 2025. It doesn't log prompts or completions by default (metadata only). A bring-your-own-key (BYOK) option lets you use your own provider credentials, with the first million requests per month free.
Free tier gives you 50 requests per day, or 1,000 daily if you've loaded $10+ in credits.
Best for: Teams that want the widest model selection with minimal setup. Particularly useful for experimentation and prototyping where you're still figuring out which models work best for each task.
3. LiteLLM
LiteLLM is an open-source proxy server and Python SDK. You host it yourself. Over 100 providers supported through an OpenAI-compatible interface.
The selling point is control. You define routing, fallbacks, and load balancing in YAML config files. Budget controls work per team, per project, or per API key. Virtual keys let you hand out access without exposing provider credentials. The admin dashboard shows token usage across every project.
Performance benchmarks show a P95 latency of 8ms at 1,000 requests per second. The overhead is minimal.
Recent releases (v1.80+) added Gemini 3 support, MCP Hub for Model Context Protocol, an Agent Hub, prompt versioning through the UI, and batch API routing. LiteLLM also supports all major OpenAI endpoints: /chat/completions, /responses, /embeddings, /images, /audio, and /batches.
Enterprise features include SSO, audit logs, and compliance controls through their hosted offering.
Best for: Platform engineering teams that want a self-hosted, vendor-free gateway with granular budget and access controls. The trade-off is infrastructure management: you're running and scaling the proxy yourself.
4. Portkey
Portkey positions itself as an AI gateway with observability at its core. It routes to over 1,600 LLMs, supports both the OpenAI and Anthropic Messages API formats, and adds a layer of production tooling on top.
The standout feature set includes guardrails (jailbreak detection, PII redaction, policy-as-code), prompt management with versioning, request caching, and detailed cost analytics by app, team, or model. The gateway itself is Rust-based, adding roughly 50ms of overhead.
Pricing starts with a free tier (10K requests/month). The Growth plan costs $49/month as a platform fee plus your provider costs. Enterprise plans add private cloud deployment, SOC 2 Type 2 compliance, GDPR/HIPAA, SSO, and audit trails.
Portkey holds a 4.8/5 rating on G2.
Best for: Teams already running LLMs in production that need better visibility into costs, latency, and model behavior. The observability features add value when you're past the prototyping stage.
5. Eden AI
Eden AI takes a slightly different approach. It's a managed API that spans beyond just LLMs, covering text, vision, speech, OCR, and translation across 100+ AI models.
The core value proposition is cross-provider benchmarking. You can compare outputs from different providers side-by-side to see which model performs best for your specific use case, then route production traffic based on those results.
Pricing is pay-per-use. Provider pricing applies plus a 5.5% Eden AI platform fee. Free tier starts with $10 in credit and 60 API calls per minute. Personal plans start at $29/month with 300 calls per minute.
Eden AI also offers no-code integrations through Zapier, Make, and Bubble, and supports BYOK for teams that want to use their own provider credentials.
Best for: Teams evaluating multiple AI providers across different modalities (not just text), or non-technical stakeholders who need to compare provider quality before committing.
6. Vercel AI SDK
The Vercel AI SDK is a TypeScript toolkit, not a hosted gateway. It abstracts provider differences at the code level, giving you a consistent interface across 15+ providers through React hooks like useChat and useCompletion.
It handles streaming, function calling, multimodal inputs, and generative UI components natively. With over 20 million monthly downloads, it's the most widely adopted frontend AI integration toolkit.
Thomson Reuters used the Vercel AI SDK to build CoCounsel, their AI assistant for legal professionals, with just 3 developers in 2 months. They're now migrating their full codebase to the SDK, deprecating thousands of lines across 10 providers.
The SDK is free. Costs come from whichever Vercel hosting plan you use and the underlying model provider fees.
Best for: Frontend-heavy teams building AI features into Next.js, React, Svelte, or Vue applications. Not a fit if you need server-side orchestration, fine-tuning, or infrastructure-level routing.
How to Evaluate a Unified AI API for Your Team
The comparison table helps narrow the field. But the right pick depends on your specific situation. Here's a framework for evaluating what actually matters.
Do you just need routing, or do you need customization?
If your team calls foundation models as-is and doesn't plan to fine-tune, a lightweight gateway works fine. OpenRouter gives you the most model options. LiteLLM gives you the most infrastructure control.
But if your roadmap includes fine-tuning models on proprietary data and serving them through the same API, the requirements change. Most gateways don't handle training at all. PremAI is one of the few platforms where you fine-tune and serve through the same interface.
Where does your data live?
Cloud gateways route your prompts and completions through third-party infrastructure. For teams in regulated industries (finance, healthcare, government), that creates compliance risk that's hard to mitigate.
Self-hosted options (LiteLLM) or platforms with on-premise deployment (PremAI) keep your data within your own perimeter. PremAI's Swiss jurisdiction and zero data retention architecture add another layer for teams with strict data security requirements. If privacy is your top concern, you may also want to explore private ChatGPT alternatives that prioritize data sovereignty from the ground up.
How do you evaluate model quality?
Switching models is the easy part. Knowing which model to switch to is harder. Generic benchmarks (MMLU, HumanEval) don't tell you how a model performs on your specific data.
Look for platforms with built-in evaluation tooling, or at minimum, standardized logging that lets you benchmark across providers on your own metrics. PremAI's team has published empirical testing results across providers that show how performance varies by task type.
What's the real cost?
Gateway pricing is straightforward to compare: provider fees plus any markup or platform fee. But total cost includes infrastructure time for self-hosted options, integration effort, and the operational overhead of managing the gateway itself.
OpenRouter adds ~5.5% on credit purchases. Portkey charges $49/month on the Growth plan. LiteLLM is free to self-host, but you're paying for servers and someone's time to maintain them. PremAI runs through AWS Marketplace, so pricing rolls into your existing AWS billing.
Does OpenAI compatibility matter?
If your codebase already uses the OpenAI SDK, migration to any OpenAI-compatible gateway takes minutes. Change the base URL, swap the API key, and your existing code works. Most platforms on this list support this format.
If you use Anthropic's Messages API natively, check that the gateway translates properly. Portkey explicitly supports both the OpenAI and Anthropic formats. PremAI offers OpenAI SDK compatibility through its Python and JavaScript SDKs.
Beyond Routing: What a Full Enterprise AI API Stack Looks Like
Most teams start with a gateway. Route requests, track costs, add failover. That handles month one.
By month three, the questions change.
"GPT-4o works, but it's too expensive to run on 10 million documents. Can we use a smaller, cheaper model fine-tuned on our data?"
"Legal says we can't send customer data through US-hosted APIs. Now what?"
"We're running Claude and our fine-tuned model side by side. How do we actually measure which one is better for our use case?"
A routing layer doesn't answer any of these.
A full enterprise AI API stack does.
Here's what that stack looks like:
- Access: Unified endpoint, OpenAI-compatible, multi-provider routing. The table stakes. Every platform listed above handles this.
- Customize: Fine-tune base models on proprietary datasets without managing GPU infrastructure. Upload your data, select a base model, run training. Knowledge distillation to create smaller, faster models that match the performance of larger ones on your specific domain.
- Evaluate: Compare models side-by-side using your own rubrics and data, not generic benchmarks. LLM-as-a-judge scoring, custom metrics, real-world test sets built from your actual use cases.
- Deploy: Serve fine-tuned models on your infrastructure or a sovereign cloud. One-click deployment to AWS VPC or on-premise. You own the model. You own the infrastructure. No enterprise hardware required.
PremAI wraps all four layers into a single platform through Prem Studio. You start by calling existing models through their API, fine-tune when ready, evaluate results with built-in evaluation tools, and deploy to your own infrastructure. Swiss jurisdiction, SOC 2 compliant, zero data retention by default.
The EU RegTech case study illustrates this in practice: an enterprise replaced manual compliance review with a sovereign fine-tuned model that processes massive datasets hourly with 100% data residency compliance.
Frequently Asked Questions
What is a unified AI API?
A single API endpoint that connects your application to multiple LLM providers (OpenAI, Anthropic, Google, Mistral, and others) without writing separate integrations for each. Your code talks to one endpoint, and the API handles routing, formatting, and authentication behind the scenes.
Is a unified AI API the same as an LLM gateway?
Functionally, yes. "LLM gateway," "AI API gateway," "LLM proxy," and "unified AI API" describe the same concept: an abstraction layer between your application and model providers. Some gateways add features like caching, guardrails, or observability on top of the basic routing.
Can I fine-tune models through a unified AI API?
Most gateways focus exclusively on routing and don't support training. PremAI is one of the few platforms that combines unified API access with fine-tuning, evaluation, and deployment in a single interface. LiteLLM offers some fine-tuning API support but routes to external providers for the actual training.
Do unified AI APIs add latency?
Typically 3-50ms of overhead depending on the gateway. Self-hosted proxies like LiteLLM report P95 latency around 8ms at 1,000 requests per second. Managed gateways like OpenRouter add 25-40ms. For most applications, this overhead is negligible compared to model inference time, which runs in the hundreds of milliseconds.
Which unified AI API is best for enterprise?
It depends on your priorities. OpenRouter for the widest model selection. LiteLLM for self-hosted control. Portkey for production observability. PremAI for the full lifecycle: unified access, fine-tuning, evaluation, and sovereign deployment in one platform. Start by defining whether you need just routing or the complete stack, and evaluate based on your compliance requirements and customization needs.
Choosing the Right Unified AI API
Unified AI APIs solve a real infrastructure problem. Managing multiple LLM providers through separate integrations is engineering overhead that compounds as your AI usage grows. And with enterprise LLM API spend projected to keep climbing, that overhead only gets more expensive.
For most teams, the decision comes down to what you need today and where you're headed. If it's pure routing with maximum model access, pick a lightweight gateway and move on. If your roadmap includes model customization, evaluation on proprietary data, and data sovereignty, invest in a platform that covers the full lifecycle.
PremAI offers a unified, OpenAI-compatible API with built-in fine-tuning, model evaluation, and Swiss data residency. Get started with the docs or book a demo.