Fine-Tuning & Small Language Models

The Shift from GPT and the Rise of Diverse LLMs
The era where large language models (LLMs) dominated the landscape of is coming to an end. Today, the AI ecosystem is marked by a growing diversity of models, both open-source and proprietary, offering a range of functionalities that are tailored to specific use cases. This evolution has been driven by the increasing need for specialized solutions across industries.
As companies integrate AI into their operations, the limitations of using a single, monolithic model like GPT-4 become evident. The rapid advancements in machine learning research have spurred the creation of models that cater to niche applications, thereby moving away from the one-size-fits-all approach. Open-source models like LLaMA and Mistral provide developers with the flexibility to fine-tune them according to their specific needs, while proprietary models continue to push the boundaries of general AI performance.
Furthermore, the growing adoption of LLMs across industries highlights the importance of customizing models to meet domain-specific requirements. This customization often involves fine-tuning existing models or adopting smaller, more efficient architectures like Small Language Models (SLMs) that can perform specialized tasks with minimal computational overhead. The rise of these tailored models has created a dynamic AI landscape, where model selection and performance optimization are key to achieving business goals.
The Evolution of Language Models: LLMs and the Rise of SLMs
LLMs, with models like GPT-4, Claude, and Jurassic-2, are trained on vast amounts of data and consist of billions or even hundreds of billions of parameters. These models possess broad, generalisable language understanding and can tackle a wide range of tasks. However, their sheer size and scope make them resource-heavy and, at times, inefficient for specific, narrow tasks.
On the other hand, Small Language Models (SLMs) are built with task specialization in mind. While LLMs are general-purpose tools, SLMs focus on particular domains or applications, making them more computationally efficient, faster in inference, and often more precise in their specific tasks. The rise of models like Prem 1B and Prem-1B SQL exemplifies this shift toward smaller, more focused models that can deliver better performance for domain-specific problems without the massive overhead of an LLM.
Fine-Tuning in Large Language Models (LLMs)
Fine-tuning is an essential process that adapts pre-trained large language models (LLMs) to perform specific tasks. It modifies a base model’s parameters through additional training on task-specific data, enhancing the model's performance on that particular task while retaining its general capabilities. Fine-tuning is particularly valuable in settings where the model needs to excel in niche areas or complex environments, such as domain-specific tasks (e.g., legal or medical applications).
1. Parameter-Efficient Fine-Tuning Methods
Fine-tuning full model parameters can be computationally expensive, especially for large models like GPT-3, LLaMA, or BLOOM, with billions of parameters. To address this challenge, parameter-efficient fine-tuning techniques, such as Adapter Tuning, Prefix Tuning, and Low-Rank Adaptation (LoRA), have been developed.
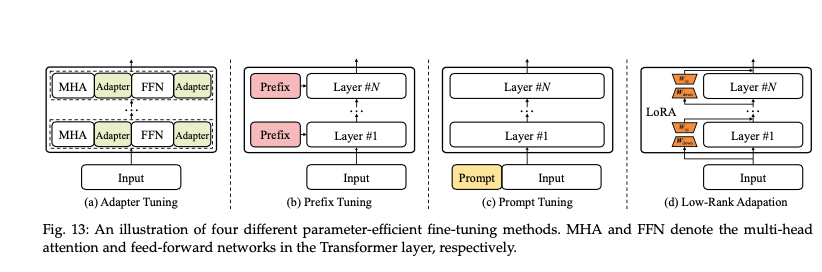
Adapter Tuning introduces small neural network modules into each Transformer layer without updating the base model's parameters. The adapters compress the input, apply a non-linear transformation, and then expand the output, effectively learning task-specific behaviour without overwhelming computational resources.
Prefix Tuning and Prompt Tuning are two other methods designed to adjust model behavior without changing all the parameters. In Prefix Tuning, task-specific prefix vectors are prepended to the input, which modifies the model's output in task-specific ways. Prompt Tuning (like P-tuning v2) is particularly effective for natural language understanding tasks, achieving performance comparable to full fine-tuning while significantly reducing the number of trainable parameters.
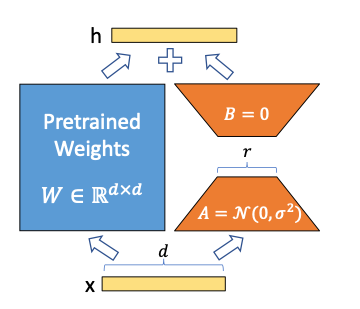
Low-Rank Adaptation (LoRA) modifies only a small number of parameters by introducing low-rank matrices within the Transformer architecture. LoRA has been particularly effective in models like LLaMA, where task-specific modules are injected into each layer to achieve state-of-the-art performance with fewer trainable parameters.
2.The Workflow of Fine-Tuning
There are different kinds of fine-tuning techniques for adapting language models, each serving a specific purpose:
- Supervised Fine-Tuning (SFT): In SFT, the model is exposed to a labeled dataset for a particular task. This phase aims to adjust the model's weights so it can generate desired outputs based on input data. For example, InstructGPT uses human-generated prompts and corresponding outputs for fine-tuning, enabling the model to learn task-specific behavior.
- Reinforcement Learning with Human Feedback (RLHF): RLHF combines both Reward Model Training and Reinforcement Learning:
- Reward Model Training: After SFT, the model produces outputs for a set of prompts. A reward model (either pre-trained or fine-tuned) ranks these outputs according to human preferences, ensuring alignment with human judgment.
- Reinforcement Learning: Leveraging the reward signals, reinforcement learning is then applied to optimize the model's behavior. This step further refines the model to be helpful and safe, enhancing alignment with human preferences.
- Combining Techniques: Often, fine-tuning may involve all three stages together: SFT + RLHF, which includes both training a reward model and applying reinforcement learning to optimize the model based on human feedback.
3. Fine-Tuning for Domain Specialisation
Fine-tuning allows LLMs to specialize in various domains. Models like Med-PaLM, derived from Flan-PaLM, are fine-tuned with medical datasets to develop domain expertise. Similarly, fine-tuning models like GPT-3 or BLOOM on domain-specific data enables them to perform exceptionally well in tasks that require specific knowledge.
By adapting the base model through task-specific fine-tuning, organizations can deploy models in specialized domains, optimizing them for tasks that go beyond general language understanding, such as legal document processing, medical diagnosis, or financial analysis.
4. Parameter-Scaling and Cost Implications
The computational cost of fine-tuning scales with the size of the model and the number of parameters involved. Full-model fine-tuning, such as in large models like LLaMA-65B, can be prohibitively expensive, both in terms of time and GPU resources. However, efficient tuning techniques like LoRA can significantly reduce this cost. For instance, while training LLaMA (13B) with full fine-tuning takes over five hours using eight GPUs, LoRA can reduce this to under half the time with just one GPU, offering similar performance.
5. Technical Considerations for Fine-Tuning
Data Efficiency: One of the key advantages of fine-tuning is its ability to leverage small datasets effectively. Since the base LLM has already been trained on large corpora, fine-tuning requires significantly less domain-specific data. Even a small, task-specific dataset can lead to notable improvements in performance for the target domain.
Computational Efficiency: While fine-tuning is generally less resource-intensive than training a model from scratch, the computational cost can still be substantial, particularly for models with hundreds of billions of parameters like GPT-3 or LLaMA. Fine-tuning smaller, efficient versions or using parameter-efficient tuning methods such as LoRA can help alleviate some of these demands.
Risk of Catastrophic Forgetting: One challenge during fine-tuning is the potential for catastrophic forgetting, where the model loses its general-purpose language understanding in favor of narrow domain expertise. To mitigate this, techniques like layer freezing (where certain model layers are kept unmodified during training) and low learning rates are employed to preserve the model’s broader knowledge while still adapting it to specific tasks.
Small Language Models (SLMs)
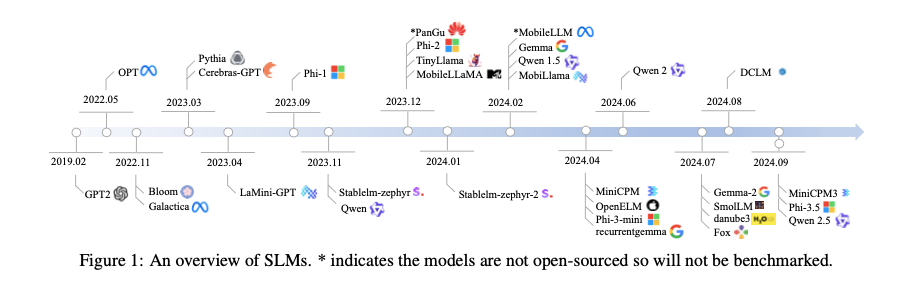
Small Language Models (SLMs) are a growing area of focus in natural language processing, particularly for their role in on-device deployments where computational resources are constrained. SLMs range in size from 100 million to 5 billion parameters and are typically designed for tasks that do not require the extensive computational power of large language models (LLMs) like GPT-4. Despite their smaller scale, SLMs can achieve impressive performance on specific tasks through specialised architectures and training methods.
1. Key Characteristics of SLM Architectures
The architecture of SLMs is derived from transformer models, typically with decoder-only architectures. While LLMs focus on maximizing model accuracy across a broad range of tasks, SLMs are more focused on efficiency, both in terms of memory and processing time. This design trade-off allows SLMs to be deployed on edge devices such as smartphones, tablets, and even wearable gadgets like smartwatches .
Key aspects of SLM architectures include:
- Attention Mechanism: SLMs often utilize group-query attention (GQA) as opposed to the more conventional multi-head attention (MHA) used in LLMs. GQA is less computationally expensive, allowing for faster inference times on resource-constrained devices .
- Feed-Forward Networks (FFNs): SLMs tend to use gated feed-forward networks (FFNs) with non-linear activation functions like SiLU, which help balance computational complexity and performance .
- Parameter Scaling: SLMs often employ parameter scaling techniques to optimise memory usage and processing time. For example, models like OpenELM introduce layer-wise parameter scaling, where different transformer layers have variable parameter allocations based on the task's complexity .
- Vocabulary Size: SLMs typically operate with smaller vocabulary sizes than LLMs, which reduces the computational overhead during tokenization and decoding stages. However, some SLMs with larger vocabularies, such as Bloom-560M, demonstrate a trade-off where larger vocabularies improve model accuracy but increase memory requirements .
2. Training Datasets and Algorithms
SLMs, like their larger counterparts, require large amounts of data for pre-training. However, there is a significant emphasis on the quality of the training data rather than its quantity, given the resource limitations for training SLMs. Recent advances have focused on model-based data filtering techniques, such as those used in the FineWeb-Edu and DCLM datasets, which select high-quality training data through model-based filtering .
SLMs often benefit from knowledge distillation, where a smaller student model learns to replicate the outputs of a larger, more complex teacher model. This allows SLMs to inherit the capabilities of larger models while maintaining a smaller parameter footprint . Additionally, two-stage pre-training strategies have been adopted, where a model is first trained on a large corpus of coarse data and then fine-tuned on more task-specific data .
3. Performance and Capabilities
While SLMs may not match LLMs in raw performance, they have made significant strides in closing the gap, particularly in common sense reasoning and domain-specific tasks. In benchmarks conducted across various tasks, including common sense reasoning, problem-solving, and mathematics, SLMs have demonstrated impressive performance gains between 2022 and 2024.
For instance, models like Phi-3-mini have achieved accuracy levels comparable to larger models like LLaMA-7B in commonsense reasoning and problem-solving tasks. This illustrates the potential of SLMs to perform on par with LLMs in specific domains, particularly when trained on high-quality data .
SLMs are also proficient in in-context learning, where they improve performance on specific tasks based on additional context provided during inference. Although in-context learning is typically associated with larger models, SLMs have demonstrated their ability to leverage this technique effectively across a range of tasks .

4. Runtime and Computational Efficiency
SLMs are designed with a focus on computational efficiency, particularly in terms of memory usage and inference latency. Key components that influence runtime performance include the KV cache, which stores key-value pairs during attention calculations, and the compute buffer, which handles matrix operations during inference .
The primary reason SLMs are more efficient is their smaller parameter size. For instance, a 1B parameter model requires significantly less memory and computational resources compared to larger models, such as 7B or 50B parameters. This makes SLMs more suitable for resource-constrained environments. Additionally, the runtime performance of SLMs is sensitive to the length of the input context; however, due to their reduced parameter size and more efficient architectures (e.g., GQA over multi-head attention), they often achieve better memory efficiency and speed.
5. Deployment Considerations
SLMs are increasingly being deployed in edge environments, such as mobile devices and Internet of Things (IoT) devices. One of the critical challenges for on-device deployment is managing the trade-off between model accuracy and resource consumption. To address this, techniques such as quantization (reducing model precision from floating point to integer values) are used to optimize the model for specific hardware, such as mobile NPUs .
Moreover, SLMs are often trained to be over-optimized on large datasets beyond the recommended ratio of parameters to training tokens. This "over-training" is aimed at maximizing performance on devices with constrained computational power by allowing the model to leverage more training-time compute .
6. Future Directions and Challenges
The future of SLM research lies in co-designing models with device hardware to optimize both accuracy and speed. As more powerful edge devices emerge, SLMs will likely increase in size and complexity, blurring the lines between small and large models. Moreover, the development of synthetic datasets for training SLMs is expected to grow, with innovations focused on filtering high-quality data to improve model performance .
The Future of AI Model Development
1. Multimodal Capabilities
The future of AI lies in the expansion of multimodal AI systems that can process multiple forms of input—text, images, videos, and more—simultaneously. Major players such as Google and OpenAI have already begun integrating multimodal models like Gemini, which is capable of understanding and generating complex outputs across a variety of formats. These systems are not only more powerful but also more versatile, allowing them to be used in diverse industries such as medical imaging, content creation, and autonomous systems.
2. Open Source vs. Proprietary AI Models
As the AI ecosystem evolves, a clear dichotomy is emerging between open-source and proprietary models. Open-source models like LLaMA have gained traction for their accessibility and innovation potential, allowing developers to experiment, modify, and build applications more easily. Meanwhile, proprietary models, such as GPT-4 with vision, continue to dominate commercial applications due to their unmatched scale and performance. This balance between open-source accessibility and the power of proprietary models is expected to drive the next wave of AI innovation.
3. Ethical and Regulatory Challenges in AI
As AI systems grow in influence, concerns around data privacy, bias, and ethical governance become increasingly critical. AI regulatory frameworks are being developed, such as the EU's Artificial Intelligence Act, which aims to provide comprehensive guidelines for AI deployment. As AI models like gen AI grow in capability, companies will need to invest in robust governance structures to mitigate risks associated with bias, misinformation, and data privacy.
4. The Growing Importance of AI in Industry
AI is becoming indispensable across industries. In fields like healthcare, AI-driven drug discovery is accelerating the development of new treatments, while in manufacturing, AI systems optimize supply chains and reduce operational costs. The adoption of generative AI in marketing, finance, and customer service is also expected to increase as organizations deploy AI-powered systems to generate personalized content, streamline workflows, and enhance customer engagement.
5. The Environmental Impact of AI
One of the biggest challenges for the future of AI is managing its environmental footprint. Training large AI models like GPT-4 requires massive computational resources, contributing to growing concerns about energy consumption and sustainability. As AI systems become more widespread, organizations will need to focus on developing more energy-efficient models and adopting practices that reduce the carbon footprint of AI training.
Preparing for the Future
The future of AI is poised to bring unparalleled advances in technology, but it also requires navigating a complex landscape of regulatory, ethical, and environmental challenges. Companies that embrace AI not only as a tool for automation but as a driver of innovation and competitive advantage will be well-positioned for success. Staying ahead of the curve means embracing both the potential of open-source innovation and the robustness of proprietary systems, all while ensuring responsible, sustainable AI practices.
References:





