
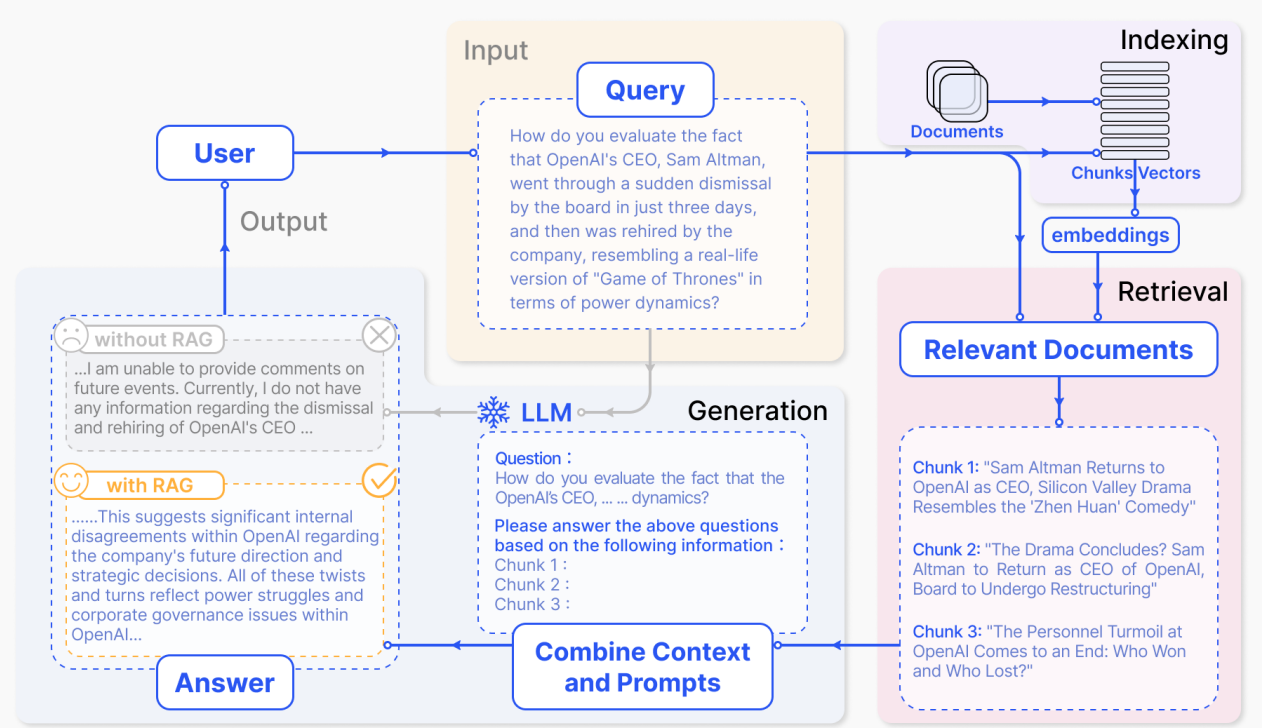
RAG Strategies


Imagine a student taking a closed-book exam, relying solely on what they've memorized. This is how traditional large language models (LLMs) operate, using only the data they were trained on. Retrieval-augmented generation (RAG) changes this by allowing the model, like a student now taking an open-book exam, to access external databases for additional, up-to-date information. This approach helps LLMs provide responses that are not only current but also more accurate, addressing problems with outdated or incorrect data. RAG effectively expands the model’s knowledge base on the fly, enhancing its ability to deliver relevant and factually correct answers, much like how a well-prepared student uses resources during an open-book test to give the best responses.

In this blog post, we explore three broad varieties of Retrieval-Augmented Generation (RAG) and introduce a new method for RAG-based fine-tuning called RAFT. We will also explore what it means to "RAG-optimize" a large language model (LLM), showcasing some new models claimed to be RAG-optimized, such as Cohere's Command R+ model.
👦 Naive RAG
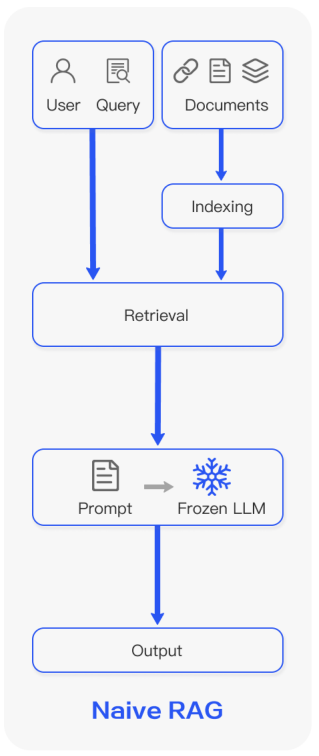
Overview: Naive RAG is the foundational form of retrieval-augmented generation. It involves a straightforward process where external documents are indexed, retrieved based on similarity with a user query, and then used to generate responses by an LLM.
Process:
- Indexing: Documents are pre-processed and converted into a uniform format, often broken down into manageable chunks.
- Retrieval: When a query is received, the system searches the indexed data for the most relevant chunks using vector similarity.
- Generation: The selected text chunks are fed into the LLM along with the query to generate a coherent answer.
Example: If a user asks about recent scientific advancements in AI, Naive RAG would fetch relevant document chunks from its database and use these texts to help the LLM produce an informed response.
Limitations:
- Precision and recall issues in the retrieval phase may lead to irrelevant information being fetched.
- The generation phase might suffer from hallucination, where the model generates incorrect or misleading information not supported by the data.
👨 Advanced RAG
Overview: Advanced RAG builds on the Naive RAG by introducing optimizations in the retrieval process and refining the indexing strategies. This type aims to enhance the quality of information retrieval before generation, thereby improving the overall output of the system.
Process:
- Pre-retrieval optimizations: These might include fine-grained segmentation of documents and using advanced techniques for more effective indexing.
- Retrieval enhancements: Incorporates advanced methods such as query rewriting and expansion to improve the relevance of retrieved documents.
- Post-retrieval processing: Focuses on refining the retrieved content through techniques like re-ranking and context compression, ensuring only the most pertinent information is used for generation.
Example: In an advanced RAG system, a query regarding climate change effects might lead to the system dynamically rewriting the query to cover specific aspects like "impact on polar ice caps" and retrieving highly relevant documents for generating a detailed response.
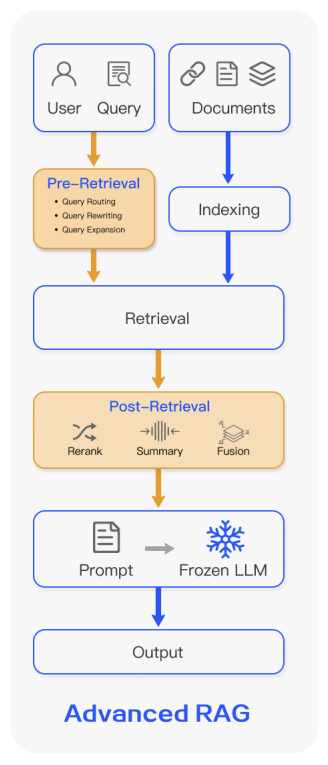
Benefits:
- Enhanced retrieval accuracy through refined queries and optimized indexing.
- Improved relevance and quality of generated content by focusing on the most pertinent information.
🎲 Query Transformation
Query transformation in an advanced Retrieval-Augmented Generation (RAG) system plays a crucial role in enhancing the system’s capability to provide detailed and relevant responses to complex queries, such as those regarding the effects of climate change. Here’s how the query transformation process would work in the given example:
Original Query: "What are the effects of climate change?"
Steps in Query Transformation:
1. Initial Query Analysis
- The system first analyzes the original query to understand its broad context and primary focus areas.
- It identifies key terms and concepts, such as "effects" and "climate change."
2. Query Rewriting
- Using predefined rules or machine learning models, the RAG system rewrites the original query into several more specific queries that can target different aspects of the broad topic.
- Rewritten Queries:
- "What is the impact of climate change on polar ice caps?"
- "How does climate change affect global temperatures?"
- "What are the consequences of climate change on sea levels?"
3. Routing to Specific Tools
- Each rewritten query is routed to the most appropriate tools or databases. For instance, queries about polar ice caps might be directed towards scientific research databases or specific environmental agencies’ resources.
- The system utilizes metadata about available tools to match queries with sources that are likely to contain precise and authoritative data.
4. Sub-Question Generation
- For more granularity, the system may further break down rewritten queries into sub-questions.
- Sub-Questions for "Impact on polar ice caps":
- "What are the latest measurements of ice thickness in the Arctic?"
- "How have polar ice cap sizes changed in the last decade?"
5. Parallel Processing and Information Retrieval
- The system concurrently processes multiple rewritten queries and sub-questions, retrieving information from a variety of sources.
- This step ensures comprehensive coverage of the topic by gathering diverse perspectives and data points.
6. Synthesis and Response Generation
- The retrieved information from various queries and sub-questions is synthesized to construct a well-rounded response.
- The RAG model integrates the data, ensuring that the final response addresses the original query comprehensively, supported by the most relevant and up-to-date information.
7. Enhanced Answer Presentation
- The final response is presented in a structured format, often segmented by the aspects covered (e.g., ice caps, global temperatures, sea levels).
- This not only provides clarity and depth but also aids in user comprehension by systematically addressing different facets of the broad query.
For more details on this, refer to the Query Transform Cookbook by LlamaIndex.
🎰 Modular RAG
Overview: Modular RAG represents the most sophisticated type of RAG, featuring a flexible and extensible architecture that can incorporate various modules for different functionalities. This type supports complex interactions and integrates seamlessly with other AI components.
Process:
- Module integration: Different modules for tasks like search, retrieval, and generation can be swapped or reconfigured based on specific needs.
- Iterative and adaptive retrieval: Allows for more dynamic interactions where the system can iteratively refine the information it retrieves based on ongoing interactions.
- Customizable workflows: Enables the design of task-specific workflows, where retrieval and generation modules can be finely tuned or completely redesigned.
Example: A Modular RAG system could be used in a customer support chatbot where different modules are activated depending on the query's complexity or subject. For technical support, a specific module might fetch technical documents, whereas a billing query might access transactional databases.
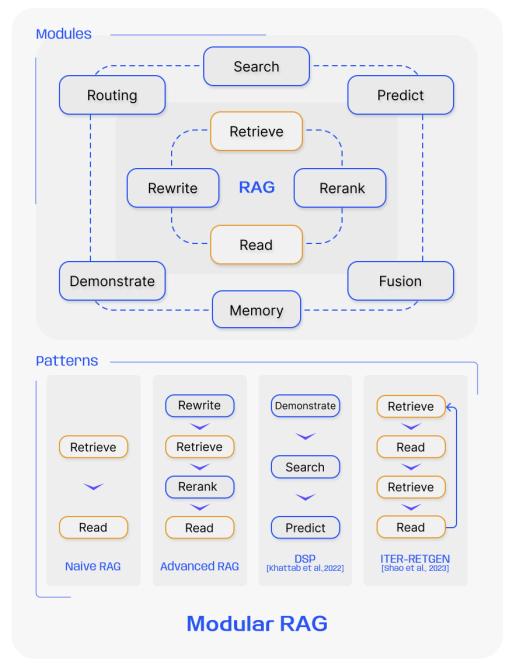
Advantages:
- High flexibility and customization options allow it to serve diverse applications.
- Supports more complex, iterative interactions that refine the user experience and response accuracy.
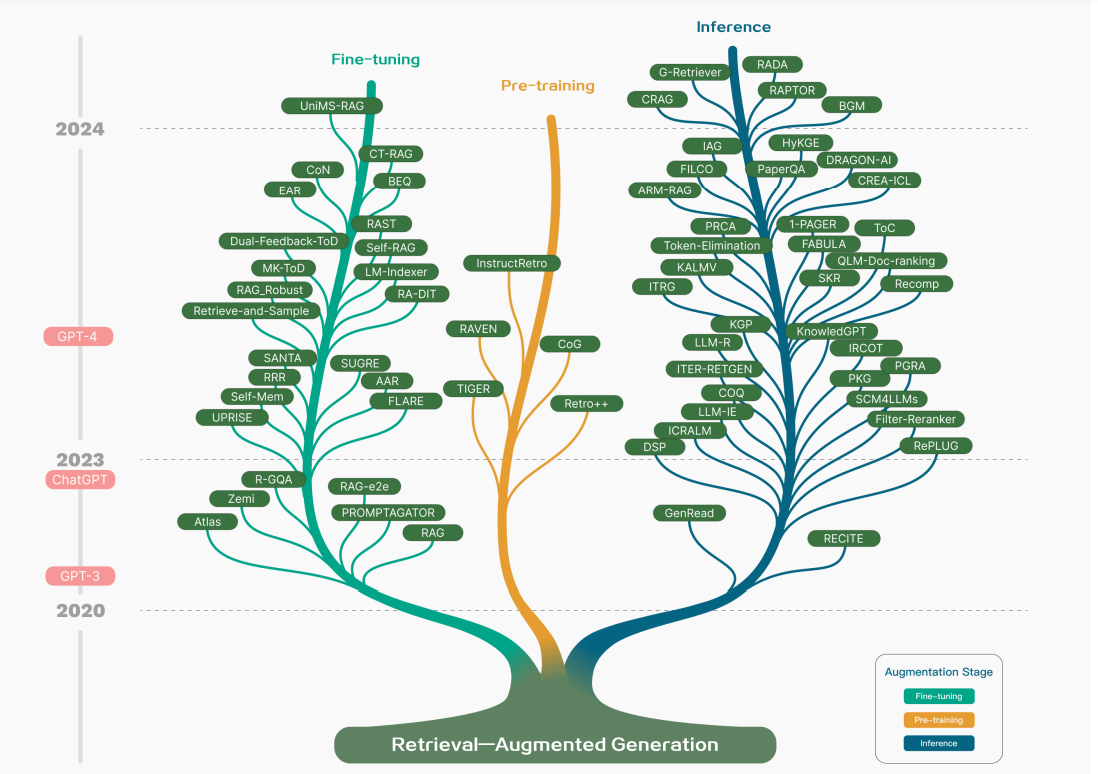
🔎 When to Fine-tune and When to RAG ?
When deciding between using Retrieval-Augmented Generation (RAG) and fine-tuning (FT) for optimizing large language models, the choice largely depends on the application's requirements for data dynamics and operational context. Primarily, RAG is applied in tasks such as question answering (both single-hop and multi-hop), information extraction, dialogue generation, and code search, with specific datasets tailored for each task. Evaluations focus on both retrieval and generation quality using metrics like EM, F1, Accuracy, BLEU, and ROUGE, adapted to assess different aspects of RAG performance.
To learn more about these evaluation metrics, head to our evaluation of LLMs part 1 blog linked below:
 Sayantan Das
Sayantan Das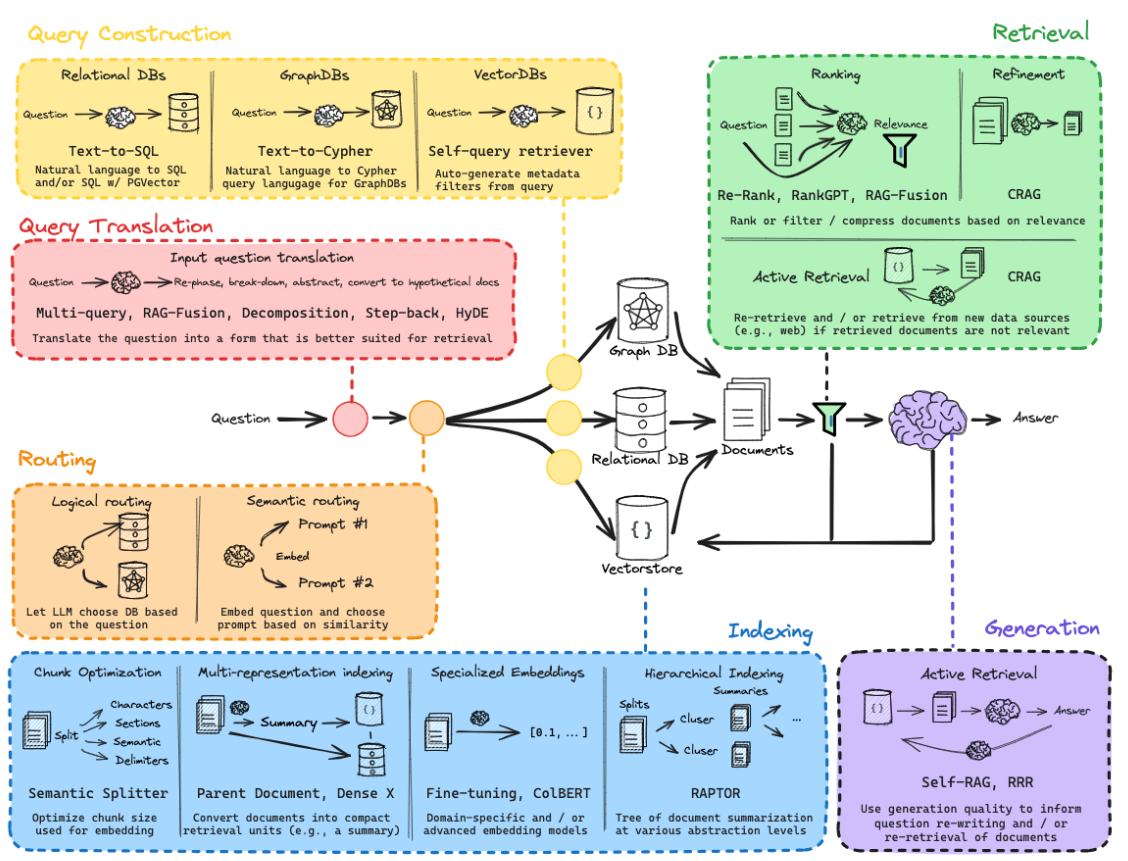
🔎 RAFT
RAFT (Retrieval-Augmented Fine Tuning) is a training methodology designed to adapt large language models (LLMs) for domain-specific tasks by utilizing a retrieval-augmented generation (RAG) mechanism. Here's a detailed explanation of RAFT using key components, structured as an overview, methodology, and its training protocol.
Overview
RAFT aims to improve how LLMs utilize external documents during inference, specifically when answering questions within a specific domain (like medical, legal, or technical fields). This is analogous to studying for an "open-book" exam where the model learns to utilize and cite relevant documents to answer questions accurately.
Methodology
- Problem Definition: RAFT addresses the limitations of both standard supervised fine-tuning and pure in-context learning. In standard methods, models might not utilize external knowledge effectively at test time, while in-context methods might not train the model to ignore irrelevant information.
- Concept: RAFT combines the strengths of supervised learning with the dynamic nature of retrieval-augmented tasks. It trains models to discern between relevant (oracle) and irrelevant (distractor) documents, focusing on utilizing only the relevant information to answer questions.
Training Protocol
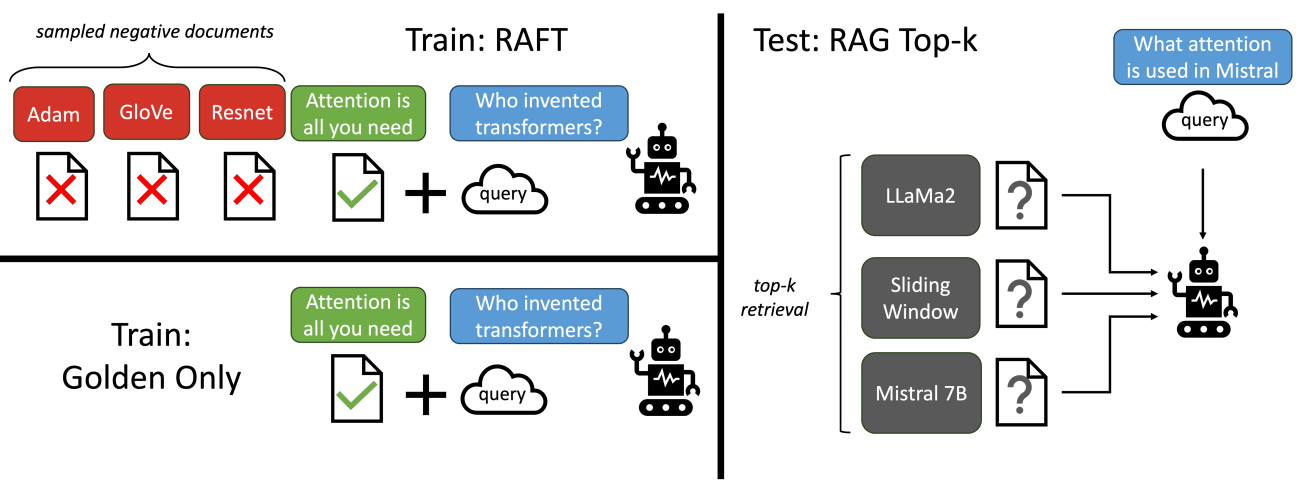
The training of RAFT involves several steps outlined as follows:
- Data Setup:
- Each training instance consists of:
- A question \( Q \)
- A set of retrieved documents \( D = \{D_1, D_2, \ldots, D_k\} \) including:
- Oracle documents \( D^* \): Contain the answer
- Distractor documents \( D_k \): Do not contain relevant information
- The answer \( A^* \) is constructed using a chain-of-thought approach, citing necessary information from the oracle documents.
- Each training instance consists of:
- Model Training:
- Input: Question \( Q \) and documents \( D \)
- Output: Answer \( A^* \) using reasoning from oracle documents
- The model is trained to generate an answer based on:
- The question \( Q \)
- A combination of oracle and distractor documents
- Periodically, training instances only include distractors to compel the model to rely on memorized knowledge or infer from limited information.
- Objective:
- RAFT's objective is to minimize the loss between the generated answer \( A^* \) and the ground truth answer, leveraging only relevant documents and ignoring distractors.
- Fine-Tuning Details:
- Retrieval-Aware: Unlike traditional methods, RAFT specifically trains the model to handle imperfect retrieval setups by learning to ignore distractors.
- Chain-of-Thought (CoT): Enhances the model's reasoning capabilities, guiding it to form answers based on a logical progression of thoughts and document references.
- Evaluation:
- The model is tested in a simulated RAG setup where a set of top-k retrieved documents are provided, mirroring the training conditions.
- The model's performance is evaluated based on its ability to extract and utilize the correct information from the mix of oracle and distractor documents.
Key Features
- Domain Adaptation: RAFT is particularly effective for domain-specific tasks where understanding and referencing domain-specific knowledge is crucial.
- Robustness to Distractors: By training with distractors, the model learns to focus on relevant information, improving its resilience against irrelevant or misleading data.
This method allows the adaptation of LLMs to specialized domains more effectively than traditional fine-tuning, by teaching models to actively utilize and cite relevant information from their training documents during inference. This ensures that the LLMs are not only retaining information but are also capable of applying it contextually, which is critical for performance in specialized domains.

➕ Command R + and its RAG optimized structure
The "RAG-optimized LLM" status of Command R+ is largely attributed to its sophisticated prompt template structure, which is specifically designed to facilitate the Retrieval Augmented Generation process. Here's how the template and other details contribute to its optimization for RAG tasks:
- Structured Prompt Template: The prompt template in Command R+ is divided into several key sections:
- Safety Preamble: Ensures the model does not generate harmful or immoral responses.
- System Preamble: Defines the basic rules and capabilities of the model as a conversational AI.
- User Preamble: Outlines the task, context, and the desired style of response, focusing on user needs.
- Tools Section: Specifies the tools available for the model to use, such as
internet_searchfor retrieving document snippets anddirectly_answerfor generating responses based on the model’s training.
- Retrieval and Augmented Generation Phases: The model operates in two main phases:
- Retrieval: Uses tools like
internet_searchto fetch relevant information based on the user’s query. - Augmented Generation: Utilizes the retrieved information to generate responses that are both informative and grounded in the retrieved data.
- Retrieval: Uses tools like
- Integration of Tool Outputs: In the augmented generation phase, the prompt template includes a place for inserting outputs from the retrieval tools right before the instructions for generating the response. This ensures that the generation phase is closely informed by the retrieved data, enhancing the accuracy and relevance of the response.
- Adaptability and Customization: The template allows for adjustments in the prompt structure, enabling users to tweak how the model handles different tasks. This can involve changing the number of times tools are used, the type of tools employed, or how the responses are structured and presented.
- Efficiency and Performance: The model supports a fast citation mode which directly integrates grounding spans into responses, allowing for quicker response generation albeit at some cost to grounding accuracy.
This structured approach not only ensures that the responses are well-informed by the latest and most relevant information but also allows for a high degree of customization to suit specific use cases, making Command R+ highly optimized for RAG tasks.
🔎 Evaluating RAG systems
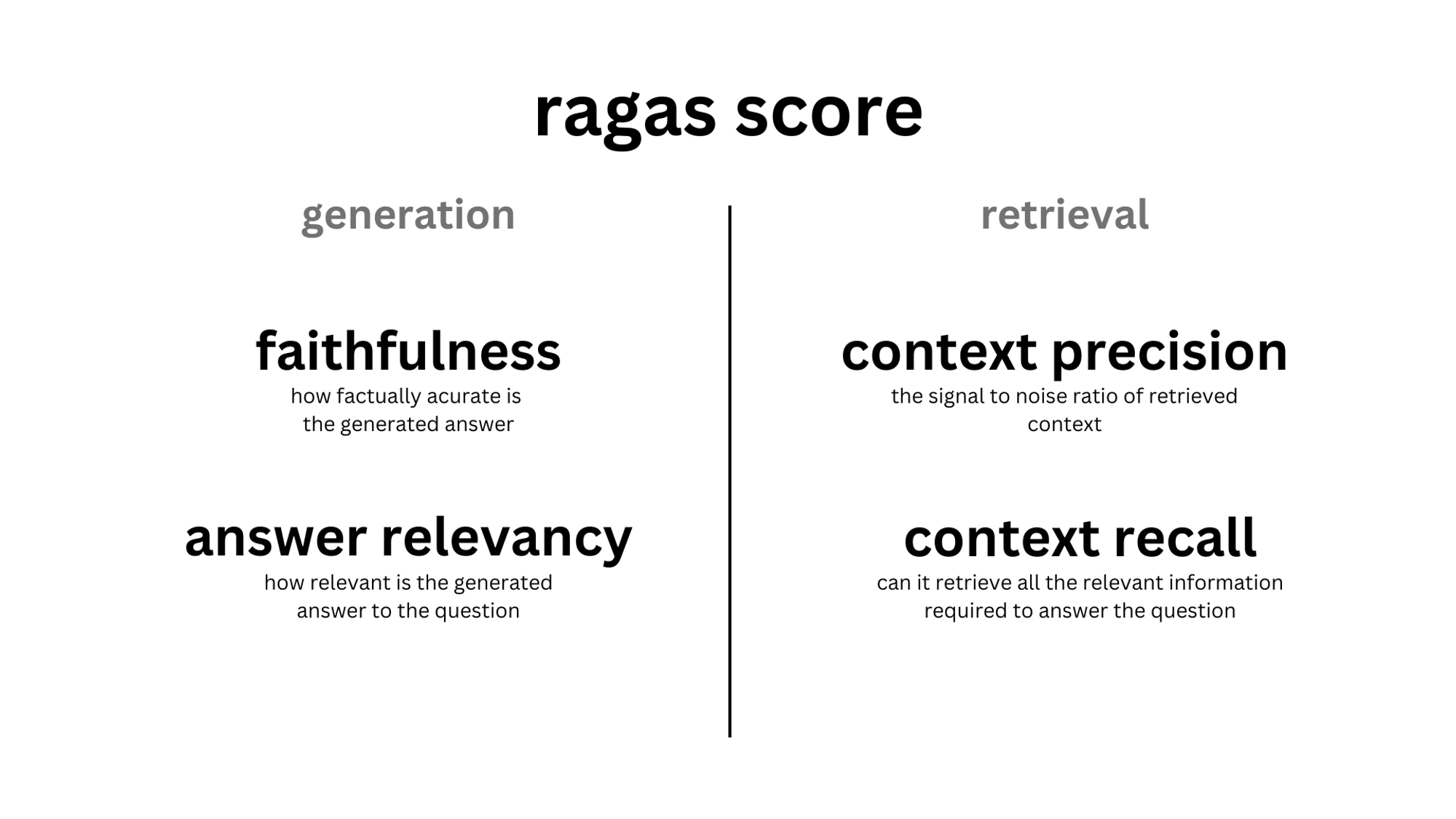
Evaluating Retrieval-Augmented Generation (RAG) systems involves assessing both the retrieval and generation components of the QA pipeline. The Ragas framework provides a structured approach to this evaluation, focusing on several key metrics that help in understanding the effectiveness of each component in the RAG system. Below, we'll delve into how to evaluate RAG systems using Ragas, providing both textual explanations and practical code examples.
Evaluation Metrics in Ragas
Ragas introduces specific metrics aimed at addressing different aspects of a QA system's performance:
- Context Relevancy: Measures how relevant the retrieved information is to the given query.
- Context Recall: Assesses whether the retriever captures all necessary information relevant to the query.
- Faithfulness: Evaluates the accuracy of the generated response in staying true to the retrieved information.
- Answer Relevancy: Determines how well the generated answer addresses the query.
These metrics together give a holistic view of both retrieval and generation performance, addressing both precision and recall, as well as the quality of the generated output.
Setting Up Ragas Evaluation
To evaluate a RAG system using Ragas, you first need to set up the necessary components and configure the evaluation chains for each metric. The following code demonstrates how to implement this with LangChain and Ragas:
from langchain.chains import RetrievalQA
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.chat_models import ChatOpenAI
from ragas.metrics import faithfulness, answer_relevancy, context_relevancy, context_recall
from ragas.langchain import RagasEvaluatorChain
# Load the document and create an index
loader = WebBaseLoader("https://en.wikipedia.org/wiki/New_York_City")
index = VectorstoreIndexCreator().from_loaders([loader])
# Create the QA chain
llm = ChatOpenAI()
qa_chain = RetrievalQA.from_chain_type(
llm, retriever=index.vectorstore.as_retriever(), return_source_documents=True
)
# Prepare evaluator chains for each metric
eval_chains = {
m.name: RagasEvaluatorChain(metric=m)
for m in [faithfulness, answer_relevancy, context_relevancy, context_recall]
}
# Function to evaluate each metric
def evaluate_ragas_metrics(qa_result):
for name, eval_chain in eval_chains.items():
score_name = f"{name}_score"
print(f"{score_name}: {eval_chain(qa_result)[score_name]}")
Running the Evaluation
Once you have set up the evaluation framework, you can run the evaluation by querying the QA chain and passing the results through the Ragas evaluator chains:
# Test the QA system
question = "How did New York City get its name?"
result = qa_chain({"query": question})
# Evaluate using Ragas
evaluate_ragas_metrics(result)
# Expected output includes scores for faithfulness, answer relevancy, context relevancy, and context recall
Understanding and Visualizing Results
The scores obtained from Ragas provide actionable insights. For instance, if the context relevancy score is low, it suggests the retriever component may be improved by optimizing the indexing strategy or by fine-tuning the retrieval model. Low faithfulness scores might indicate a need to refine the generation model to better utilize the retrieved context.
Further, integrating these evaluations with LangSmith allows for continuous monitoring and improvement:
from langsmith.smith import RunEvalConfig, run_on_dataset
# Assuming configuration and setup are done, run evaluation on a dataset
result = run_on_dataset(
client,
"NYC test dataset",
create_qa_chain,
evaluation=RunEvalConfig(custom_evaluators=list(eval_chains.values()))
)
# Now, visualize and analyze the results in LangSmith’s dashboard to understand and improve the QA system continuously.
🔢 Conclusion
RAG represents a significant evolution in the capabilities of large language models, akin to the transition from closed-book to open-book exams in academic settings. By leveraging external, up-to-date data, RAG systems not only enhance the accuracy and relevance of responses but also address issues associated with outdated or incorrect data inherent in traditional models. The development and refinement of RAG strategies, from Naive RAG to more sophisticated Modular and RAFT-enhanced systems, illustrate a clear trajectory towards increasingly dynamic and contextually aware AI systems.
Looking ahead, there is a growing interest in expanding RAG capabilities into multimodal and Knowledge Graph-based applications (KG-RAG). Multimodal RAG involves integrating text with other data forms like images, video, and audio, promising to revolutionize tasks requiring complex sensory data interpretation. On the other hand, Knowledge Graph RAG aims to enrich response accuracy and contextuality by embedding structured world knowledge into the retrieval process. These advancements are expected to not only enhance the depth of understanding and interaction possible with AI systems but also broaden their applicability across various domains, from automated educational assistants to sophisticated interactive agents in customer service and beyond.
As RAG technology continues to evolve, it remains a vital area of research and application, pushing the boundaries of what artificial intelligence can achieve in understanding and interacting with the complex world around us.
