
Evaluation of LLMs - Part 1
The article "Evaluation of LLMs - Part 1" delves into the rapid development of Large Language Models (LLMs) and the necessity for robust evaluation strategies. It examines traditional n-gram-based metrics like BLEU and ROUGE, discussing their roles and limitations in assessing LLM performance.

The rapid development of Large Language Models (LLMs) also necessitates advancing robust evaluation strategies and systems. For a broader understanding of these technological advancements, look at our previous exploration in The Tiny LLM Revolution. In this blog post, we do a deep dive into existing evaluation benchmarks and discuss future directions to improve the relevancy of these systems.
In exploring the landscape of evaluation strategies for LLMs, it's imperative to delve into the specifics of how these models are assessed for effectiveness and accuracy. A pivotal aspect of this evaluation revolves around n-gram-based metrics, which are instrumental in quantifying the performance of language models across various applications. Let's examine these metrics more closely to understand their role in benchmarking the capabilities of LLMs.
👝 n-gram-based metrics
N-gram-based metrics are popular tools for evaluating Language Models (LMs), especially in areas like machine translation, summarizing text, and creating new text. Simply put, these metrics check how good the text produced by a model is by comparing groups of words (n-grams) from the model's text with those in a standard reference text.

Some important n-gram-based metrics are:
BLEU (Bilingual Evaluation Understudy):
The BLEU score measures the similarity of the machine-generated translation (the candidate) to one or more high-quality human translations (the references). The BLEU score is calculated as follows:
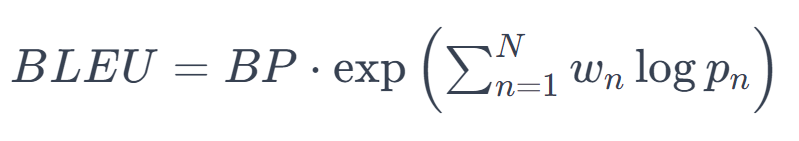
Where:
- \( BP \) is the brevity penalty, which penalizes short candidate translations.
- \( w_n \) are the weights for each n-gram size, typically equal for all n-grams.
- \( p_n \) is the modified n-gram precision for each n-gram size \( n\).
- \( N \) is the maximum size of n-grams considered, often 4.
The brevity penalty \(BP\) is defined as:
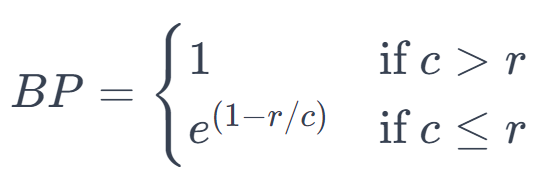
Here, \( c \) is the length of the candidate translation, and \( r \) is the effective reference length. This penalty ensures that too short translations are penalized, as they might otherwise artificially inflate the precision score.
The modified n-gram precision \( p_n\) is given by:
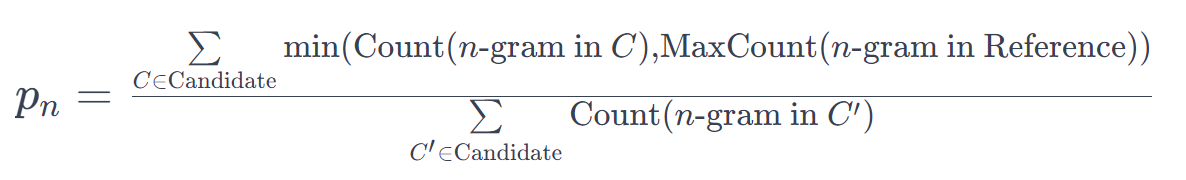
This precision measures how many n-grams in the candidate translation appear in the reference translations, adjusted to prevent the same n-gram in the candidate from being counted multiple times.
Overall, the BLEU score aims to capture the quality of a translation by considering both its precision and its appropriate length relative to the references.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
ROUGE is a metric primarily used in text summarization. Unlike BLEU, which focuses on precision, ROUGE emphasizes recall – the ability of the generated text to include content from the reference text. It calculates how many n-grams (sequences of 'n' words) or subsequences in the reference text are captured in the generated text. Common variants of ROUGE are ROUGE-N and ROUGE-L.
ROUGE-N: Measures the recall of n-grams.
Mathematically:

This formula calculates the ratio of the count of matching n-grams in the generated text to the count of n-grams in the reference text.
ROUGE-L: Focuses on the longest common subsequence (LCS), the longest sequence of words appearing in both the reference and generated texts in the same order.
Mathematically:

Where:
- LCS(Reference, Candidate) is the length of the longest common subsequence between the reference and candidate texts.
- Length(Reference) and Length(Candidate) are the lengths of the reference and candidate texts, respectively.
- \(\beta\) is a parameter to balance the importance of precision and recall (often set such that recall is weighted higher than precision).
Here, the formula calculates the ratio of the length of the LCS to the length of the reference text.
METEOR (Metric for Evaluation of Translation with Explicit Ordering):
Aligns the generated and reference texts to evaluate the quality of translation. It considers exact, stem, synonym, and paraphrase matches for unigrams and adjusts scores based on the quality of these alignments.
METEOR calculates its score using a combination of unigram precision (P), unigram recall (R), and a penalty for chunkiness. The formula to compute the METEOR score is as follows:
Unigram Precision (P): This is the ratio of the number of unigrams in the system translation that are mapped to unigrams in the reference translation to the total number of unigrams in the system translation. It can be expressed as:

Unigram Recall (R): This is the ratio of the number of unigrams in the system translation that are mapped to unigrams in the reference translation to the total number of unigrams in the reference translation. The formula is:

Harmonic Mean of Precision and Recall: METEOR uses a harmonic mean that places more weight on recall. This is important in translation because capturing the content of the reference translation is critical. The harmonic mean is given by:
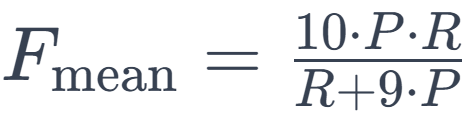
The factor of 9 in the denominator gives more weight to recall than precision.
Penalty for Chunkiness: This penalty is introduced to ensure the translation is not only accurate but also fluent and well-structured. It penalizes the score if the matched words are not in adjacent positions, leading to fragmented translations. The penalty is calculated as follows:
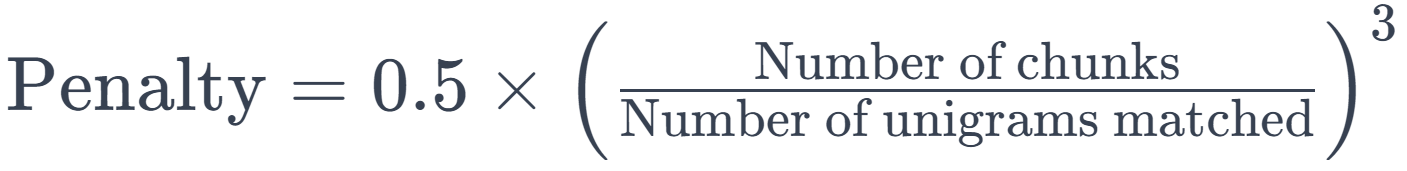
A 'chunk' is a set of adjacent words in the translation that are also adjacent in the reference.
Final METEOR Score: The final score is the harmonic mean reduced by the penalty factor. It is calculated as:

This reduction can be up to 50% in cases with no bigram or longer matches.
Example:
Let's consider an example to understand how METEOR calculates its score. Suppose we have the following:
- System Translation: "The president spoke to the audience"
- Reference Translation: "The president then spoke to the audience"
Here, we have a total of 6 unigrams in the system translation and 6 in the reference. All six unigrams are in the system translation map to the reference, so precision and recall are 1 (or 100%). However, there are two chunks: "the president" and "spoke to the audience."
Thus, the penalty would be \(( 0.5 \times \left( \frac{2}{6} \right)^3 \approx 0.028 )\).
The final METEOR score would be \(( 1 \times (1 - 0.028) = 0.972 )\).
This scoring system shows that METEOR considers the accuracy of translation and its structural and sequential coherence, making it a robust metric for evaluating machine translations.
📦 Embedding-based metrics
In the previous section, we discussed different classical/statistical metrics that help us evaluate the performance of language models. In this section, we will learn about metrics that require embeddings to evaluate the performance of language models.
BERTScore
BERTScore is an advanced metric for text generation evaluation, leveraging the deep contextual embeddings from BERT (Bidirectional Encoder Representations from Transformers). Unlike traditional metrics like BLEU, which rely on surface-level n-gram overlaps, BERTScore evaluates the semantic similarity between source and generated texts. This is achieved by computing the cosine similarity between the embeddings of each token in the candidate sentence and each token in the reference sentence, reflecting a deeper understanding of language context and meaning.
Mathematical Framework of BERTScore:
For each token \( i \) in the candidate sentence and each token \( j \) in the reference sentence, BERTScore computes the cosine similarity:
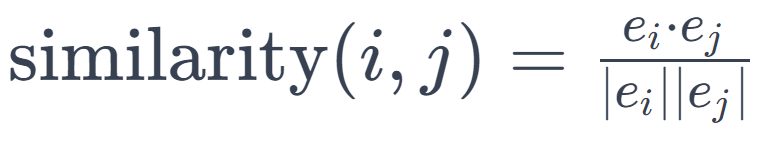
Here, \( \mathbf{e}_{i} \) and \( \mathbf{e}_{j} \) are the BERT embeddings of tokens \( i \) and \( j \), respectively. The final score is an aggregation of these individual similarities:
- Precision (P): The average of the highest cosine similarities for each token in the candidate sentence.
- Recall (R): The average of the highest cosine similarities for each token in the reference sentence.
- F1 Score: The harmonic mean of P and R, giving a balanced metric.

Example:
Consider the candidate sentence "I enjoyed the fast ride" and the reference sentence "The quick journey was enjoyable." The lack of exact word matches would result in a lower score in traditional metrics. However, BERTScore recognizes the semantic parallels between "fast" and "quick," "ride" and "journey," and "enjoyed" and "enjoyable," leading to a higher score due to its nuanced understanding of context and meaning.
This example highlights BERTScore's strength in capturing semantic similarities beyond mere word overlap, making it a more sophisticated tool for evaluating the quality of text generation tasks.
😥 Pitfalls
To quantify the effectiveness of these metrics for conversational systems such as LLMs, we examine their performance in the context of a topical chat benchmark, where each metric is evaluated based on its correlation with human judgments across four critical dimensions of dialogue quality: Naturalness, Coherence, Engagingness, and Groundedness. These dimensions reflect key aspects of conversational AI performance:
- Naturalness assesses how naturally the generated text flows. It measures linguistic quality and fluency, reflecting how similar the conversation is to what might be expected from a human in a similar context.
- Coherence evaluates how logically connected and consistent the responses are within the context of the conversation. It gauges the ability of the system to maintain topic and context throughout an interaction.
- Engagingness measures the ability of the system to produce responses that are interesting, stimulating, and likely to keep a human engaged in the conversation.
- Groundedness refers to the degree to which the responses are factually and contextually grounded in reality, providing accurate and relevant information when needed.

The table in discussion presents the correlation of each metric with human judgment using two statistical measures: Spearman's rho (ρ) and Kendall's tau (τ). Spearman's rho measures rank correlation, indicating how well the relationship between two rankings can be described using a monotonic function. Kendall's tau is another rank correlation coefficient that measures the ordinal association between two measured quantities.
A closer look at the table reveals the performance of each metric across these aspects:
- ROUGE-L, which focuses on the longest common subsequence, exhibits low correlations, suggesting that this measure of textual overlap is insufficient for capturing the qualitative aspects of human-like conversation.
- BLEU-4, which counts matching 4-grams between candidate and reference responses, shows marginal improvements over ROUGE-L in coherence but remains limited, underlining its inadequacy in capturing the conversational dynamics and nuances.
- BERTScore, leveraging contextual embeddings, performs better, particularly in engagingness and groundedness, indicating a higher semantic understanding. However, even BERTScore does not achieve high correlation scores, hinting at the complexity of modeling human conversational judgments.
These metrics reflect varying degrees of alignment with human preferences, with n-gram-based metrics like ROUGE-L and BLEU-4 falling short in all aspects and embedding-based metrics like BERTScore showing relatively better but still incomplete alignment. This underlines the challenge of developing evaluation metrics that can fully capture the subtleties of human conversational judgment and the multi-faceted nature of dialogue.
🧐 Popular static benchmarks
Static benchmarks are crucial in natural language processing (NLP) as they provide consistent and standardized ways to evaluate the performance of language models. Massive Multitask Language Understanding (MMLU) and Winogrande are particularly noteworthy among these.
MMLU (Massive Multitask Language Understanding):
- Overview: MMLU is a large-scale benchmark designed to evaluate models' general language understanding abilities across various tasks. It encompasses diverse subjects, ranging from humanities and social sciences to STEM.
- Structure: MMLU consists of tasks that are framed as multiple-choice questions. These tasks are sourced from various domains and require a model to possess a broad and deep understanding to perform well.
- Purpose: The primary goal of MMLU is to assess the generalization capabilities of language models beyond their training data. It tests whether a model can apply learned knowledge to new and diverse domains.
- Challenges: MMLU requires surface-level understanding and deep contextual comprehension across multiple disciplines, making it a rigorous test for language models.

A code snippet using lm-eval should look like:
lm_eval \
--model hf \
--model_args pretrained=EleutherAI/gpt-j-6B \
--tasks mmlu \
--device cuda:0 \
--batch_size 8 \
--log_samples \
--output_path output/gpt-j-6BWinogrande:
- Overview: Winogrande is a large-scale dataset that evaluates common sense reasoning in language models. It's an advanced version of the Winograd Schema Challenge, created to test AI's language understanding in a commonsense context.
- Structure: The challenge involves sentence completion tasks where a language model must choose the correct word to complete a sentence. These sentences are carefully crafted to require commonsense understanding.
- Purpose: Winogrande aims to evaluate a model's ability to perform commonsense reasoning, a crucial aspect of natural language understanding beyond mere pattern recognition.
- Difficulty Scaling: One unique aspect of Winogrande is that it offers a range of problems in its questions, making it a more dynamic tool for assessing language models at various levels of complexity.

lm_eval \
--model hf \
--model_args model=facebook/opt-125m \
--tasks winogrande \
--device cuda:0 \
--batch_size 8 \
--log_samples \
--output_path output/opt-125mMMLU and Winogrande are significant in AI and NLP because they push the boundaries of what language models are expected to understand and reason about. While MMLU focuses on broad domain knowledge and understanding, Winogrande zeroes in on the nuanced and often tricky realm of commonsense reasoning. Both benchmarks contribute to the ongoing efforts to create more intelligent, versatile, and context-aware AI systems.
🌀 Conclusion
The rapid advancement of Large Language Models (LLMs) necessitates robust and nuanced evaluation metrics that align with human judgment. While useful in their context, traditional n-gram-based metrics like ROUGE-L and BLEU-4 fail to capture the full spectrum of conversational nuances. Embedding-based metrics like BERTScore demonstrate better performance but do not completely resonate with human preferences. This indicates a pressing need for developing more sophisticated evaluation methods that capture the subtleties of naturalness, coherence, engagingness, and groundedness—key dimensions of human conversation. As we push the boundaries of what LLMs can achieve, our evaluation strategies must evolve in parallel to ensure they remain relevant and reliable.
In the next part of our exploration, we will explore the intriguing possibility of using LLMs themselves as judges to evaluate the performance of other LLMs, a self-referential approach that could revolutionize the assessment of conversational AI.
📜 References
- Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu, "BLEU: a Method for Automatic Evaluation of Machine Translation," Proceedings of the 40th Annual Meeting on Association for Computational Linguistics - ACL '02, 2002.
- Chin-Yew Lin, "ROUGE: A Package for Automatic Evaluation of Summaries," Text Summarization Branches Out: Proceedings of the ACL-04 Workshop, 2004.
- Satanjeev Banerjee and Alon Lavie, "METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments," Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, 2005.
- Yi Zhang, Jason Baldridge, and Luheng He, "BERTScore: Evaluating Text Generation with BERT," arXiv preprint arXiv:1904.09675, 2020.
- Hendrycks, D. et al., "Measuring Massive Multitask Language Understanding," arXiv preprint arXiv:2009.03300, 2020.
- Sakaguchi, K., Bras, R. L., Bhagavatula, C., & Choi, Y., "WinoGrande: An Adversarial Winograd Schema Challenge at Scale," arXiv preprint arXiv:1907.10641, 2019.
- Chi-Min Chan et al., "ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate," arXiv preprint arXiv:2308.07201, 2023.
📚 Resources
For those interested in exploring the topics covered in this blog post further, the following list of resources provides an opportunity for a more in-depth understanding:


 ehudreiter
ehudreiter
