
Emergent Capabilities of LLMs
ChatGPT ha detto: ChatGPT The article explores how LLMs develop emergent abilities like few-shot prompting and chain-of-thought reasoning as they scale, highlighting key research findings and debates on predictability, potential misuse, and understanding their limitations.

Emergence, a concept well-studied in fields like physics, biology, and mathematics, describes how complex systems can exhibit new, unforeseen properties as their complexity increases. Inspired by P.W. Anderson's influential idea that "More is Different," suggesting that complexity can lead to unexpected behaviors not evident from a system's individual components. A recent study by Google AI has extended this notion to machine learning, particularly in the area of natural language generation. This blog post will explore the phenomenon of emergent abilities within this context and address the debates it has sparked.
✨ Emergence
As per the recent study by Google AI mentioned above, an emergent ability is defined as an ability that is not present in small models but emerges in large models.
Throughout this blog post and the research referenced, emergence is studied by analyzing the performance of language models as a function of language model scale, as measured by total floating point operations (FLOPs), or how much compute was used to train the language model.
Emergent Few-Shot Prompted Tasks
In a fascinating exploration of the capabilities of pre-trained language models, recent research has unveiled the phenomenon known as emergent abilities, particularly within the context of prompted tasks. These findings show that these models are highly adaptable and can learn to perform tasks beyond their initial training without additional adjustments. Their ability to tackle new challenges highlights their natural ability to learn from limited data.
One of the most compelling illustrations of this phenomenon is the application of few-shot prompting for movie review sentiment analysis. In these instances, a model is presented with just a single example to classify a review as positive or negative.
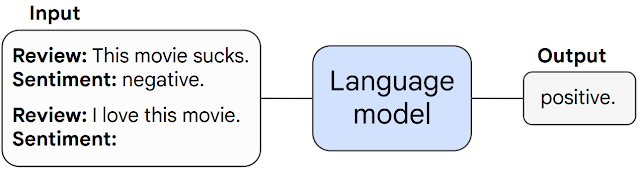
As you can see from the above figure, the model armed with this minimal instruction proceeds to accurately categorize an unseen review. This exceptional demonstration of learning and application from limited examples highlights the model's ability to extrapolate and apply learned knowledge in novel situations.
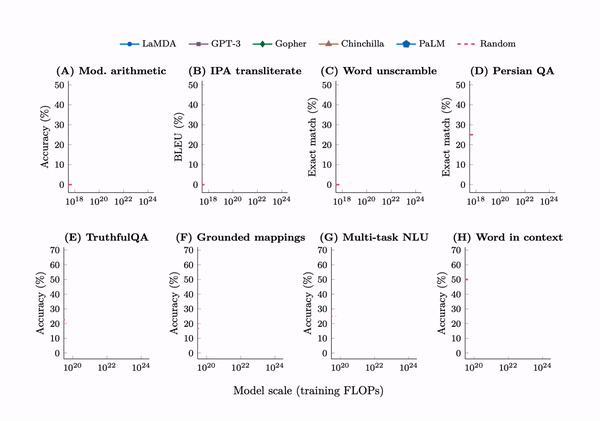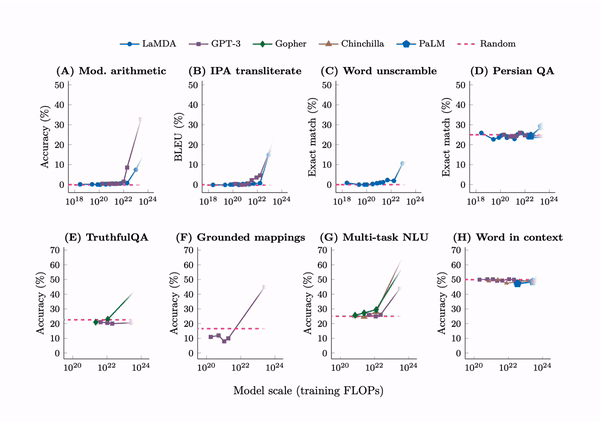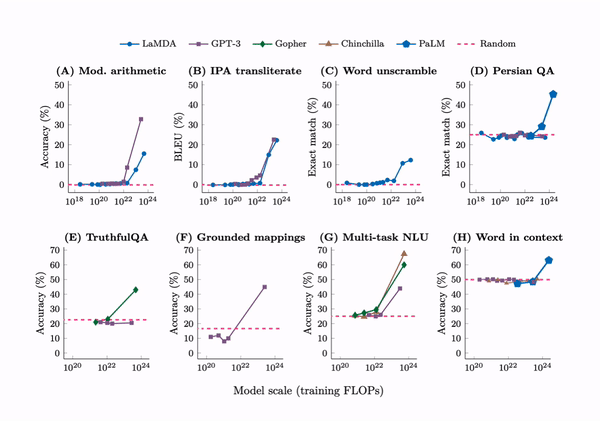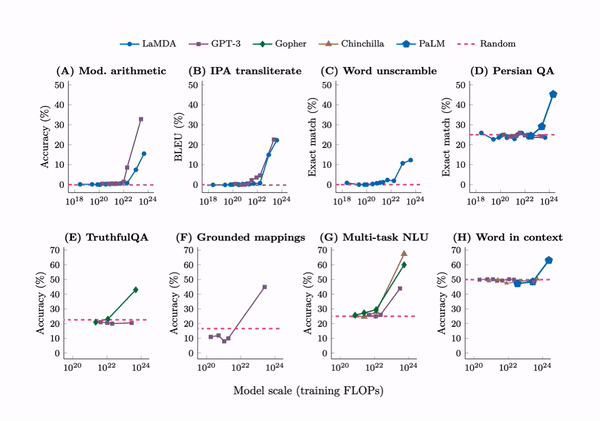
The research delineates a prompted task as emergent when a model's performance unpredictably leaps from random to significantly above random, crossing a particular scale threshold. This is particularly evident in tasks that demand multi-step arithmetic solutions, success in college-level exams, and the discernment of context-specific word meanings. Initially, language models exhibit only minimal performance gains as model size increases. However, a critical juncture is reached—a threshold at which performance is dramatically enhanced. This is evident from the figure above.
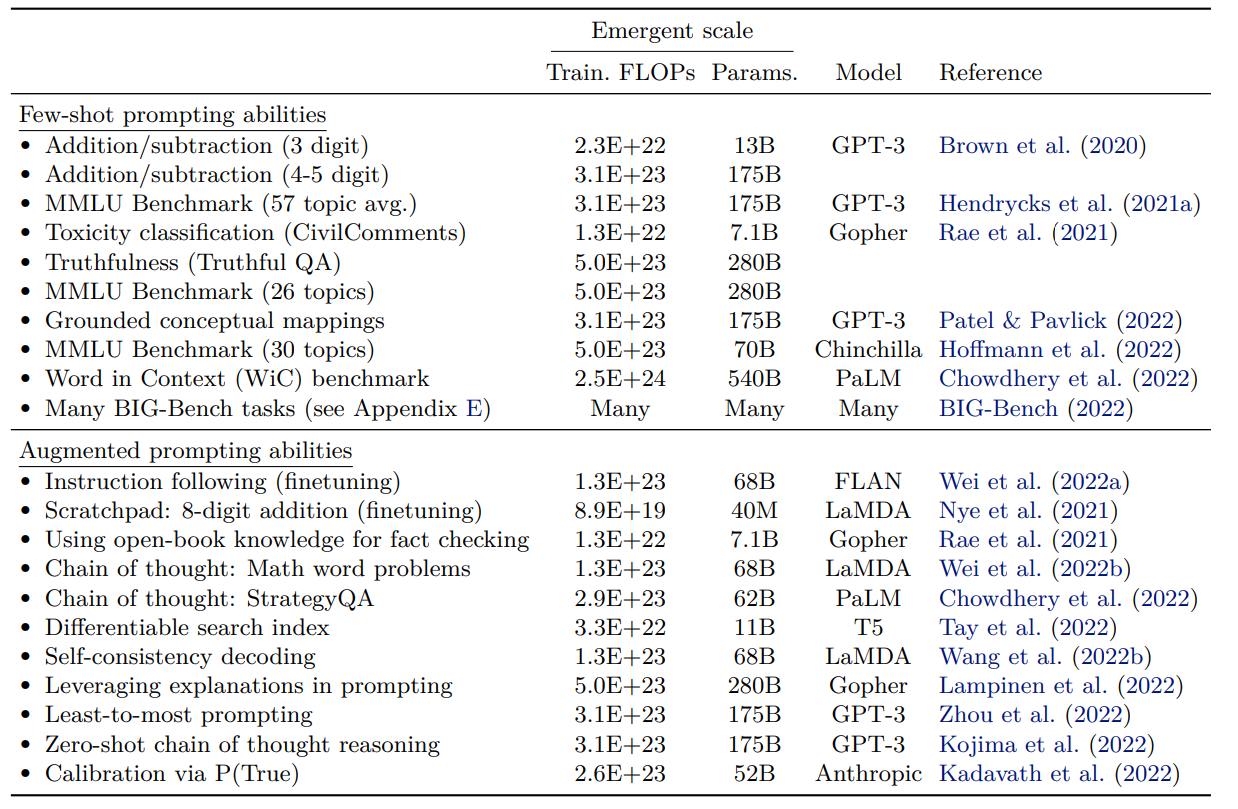
The tasks described are only possible for models with high computing power, needing over 1022 FLOPs for math and language understanding and more than 1024 FLOPs for understanding words in context. Despite testing many advanced models like LaMDA, GPT-3, Gopher, Chinchilla, and PaLM, none consistently improved these tasks, showing that these abilities suddenly appear at high computing levels.
Moreover, the study catalogs an array of additional tasks where emergent abilities have been documented, illustrating the vast potential of large-scale models to unveil novel capabilities and insights far beyond their initial programming and training parameters. Jason Wei, one of the authors of this research paper, highlights 137 such tasks on his blog.
Emergent Few-Shot Prompting Techniques
The exploration of language models has unveiled an exciting breakthrough in emergent abilities, especially in creating prompting strategies that greatly improve these models' capabilities. These strategies, acting as general approaches for various tasks, truly shine when used on large-scale models, showing that smaller models can't leverage them as effectively.
Among the most notable strategies surfacing is the chain-of-thought(CoT) prompting. This new method helps a model break down a problem into steps to find the final answer, making it easier to solve complex problems like multi-step math word problems. Surprisingly, models learn to think through problems step by step on their own, without being specifically trained for it, showing a natural ability to process information gradually.
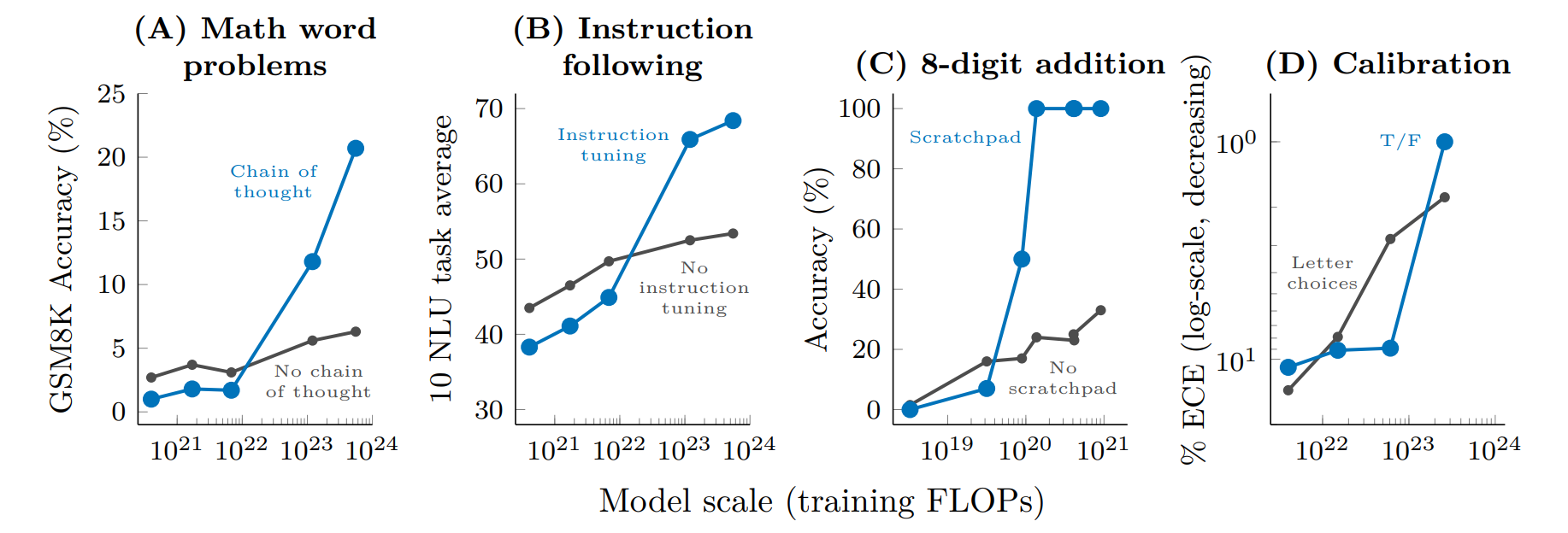
The introduction of chain-of-thought prompting marks a significant leap forward in the problem-solving prowess of large-scale models, empowering them to navigate the intricacies of reasoning tasks with unprecedented effectiveness. The empirical success of this strategy is particularly noteworthy; where smaller models falter in the face of standard prompting techniques, their larger counterparts thrive, demonstrating remarkable improvements. The application of chain-of-thought prompting to models boasting over 1024 FLOPs has been met with a remarkable 57% solve rate on the GSM8K benchmark—a suite of demanding mathematical word problems—thereby highlighting a substantial enhancement in performance.
Instruction following
Other than chain-of-thought (CoT) prompting, a notable line of research has explored how language models can learn to perform new tasks by following written instructions, eliminating the need for few-shot exemplars. This approach involves fine-tuning language models on various tasks described directly through instructions, enabling them to appropriately respond to instructions for tasks they haven't encountered before. However, it's been observed that this instruction-finetuning technique initially reduces performance in smaller models, particularly those up to 7 x 1021 training FLOPs (see Figure 3B). Only in significantly larger models, around 1023 training FLOPs (roughly 100B parameters), does that performance begin to improve. Nevertheless, subsequent studies have shown that smaller models, such as encoder-decoder T5, can adopt this instruction-following behavior with the right fine-tuning approach.
8-digit addition
In the realm of program execution, tasks that require a series of steps, like performing 8-digit addition or running computer programs, present a unique challenge. Fine-tuning language models to forecast intermediate steps, or using a "scratchpad," has enabled these models to carry out multi-step computations effectively. For tasks as complex as 8-digit addition, the advantage of employing a scratchpad becomes apparent only in models with around 9 x 1019 training FLOPs (or 40 M parameters) or more.
🤔 Criticism
A. Emergence is just in-context learning
The recent scholarly discourse around LLMs has introduced a compelling argument that emergent abilities often attributed to these models might actually be an extension of in-context learning enhanced through instruction tuning. This perspective challenges the idea that instruction tuning unveils new reasoning abilities within LLMs.
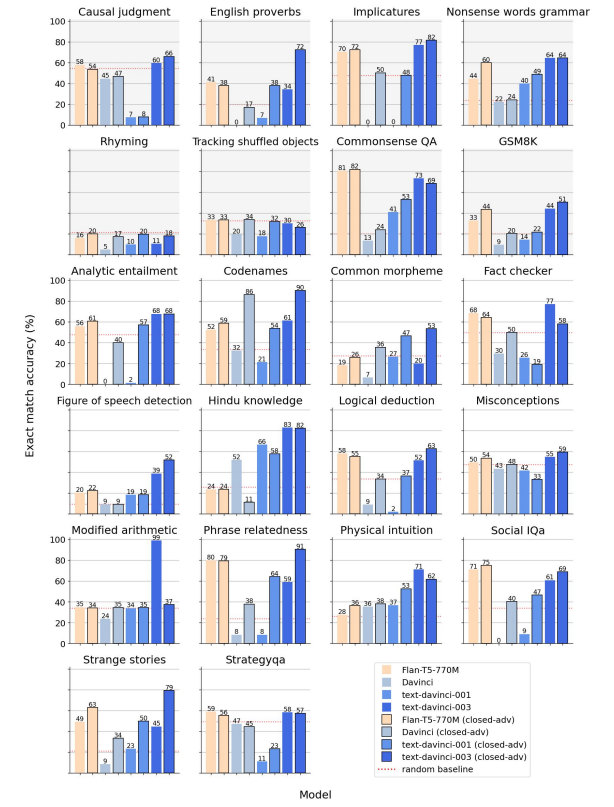
Instead, it suggests that observed improvements result from models better applying in-context learning, a phenomenon termed "implicit" in-context learning (ICL). Implicit ICL theory posits that models, through instruction tuning, become proficient at linking instructions with relevant examples from their training, enhancing their ability to tackle new tasks. This notion implies that emergent reasoning observed in LLMs is more about their skill in applying learned patterns to novel situations rather than the emergence of new cognitive skills.
For example, a comparative analysis between Flan-T5 and various versions of GPT-3 models—despite GPT-3 having over 200 times more parameters than T5—reveals no significant emergent abilities in either model when examined in a zero-shot setting. This setting allows for comparing their instruction-following capabilities without relying on direct in-context learning. The analysis shows a significant overlap in the tasks both models can perform well on, indicating that the boost from instruction tuning is consistent regardless of the model's scale or the complexity of the tasks. However, in tasks requiring recall, such as "Hindu knowledge," the larger GPT-3 model outperforms the smaller T5, underscoring the advantage of larger models in tasks dependent on recall capabilities.
This example highlights that the perceived superiority of instruction-tuned models in certain tasks could be more accurately attributed to refined in-context learning mechanisms rather than the emergence of new reasoning faculties. This re-evaluation of LLMs and their emergent abilities within the context of in-context learning not only clarifies their operational dynamics but also addresses concerns about their predictability and misuse, advocating for a deeper understanding of their capabilities and limitations.
B. Emergence is just a result of using non-linear y-axis metrics
A recent study suggests that the special skills we see in LLMs might not just come from the models themselves but also from how we measure their performance. It argues that using complex or inconsistent ways to evaluate them could mistakenly make it seem like these models have developed emergent abilities. This illusion arises as these metrics reshape model outputs, leading to sharp and unpredictable surges in performance that are often mistaken for emergent capabilities rather than indicating actual evolution in model behavior with increased scale.
The study presents this alternative explanation through a straightforward mathematical model and substantiates it through a tripartite examination:
- An analysis of the InstructGPT/GPT-3 model family across tasks traditionally associated with emergent abilities reveals how the choice of metric substantially influences the perceived manifestation of these abilities.
- A meta-analysis conducted on the BIG-Bench benchmark underscores that emergent abilities are predominantly reported under specific metrics, often characterized by their nonlinearity or discontinuity.
- Demonstrations that a change in evaluation metrics can either bring forth or entirely negate the appearance of emergent abilities across multiple vision tasks and diverse deep network architectures.
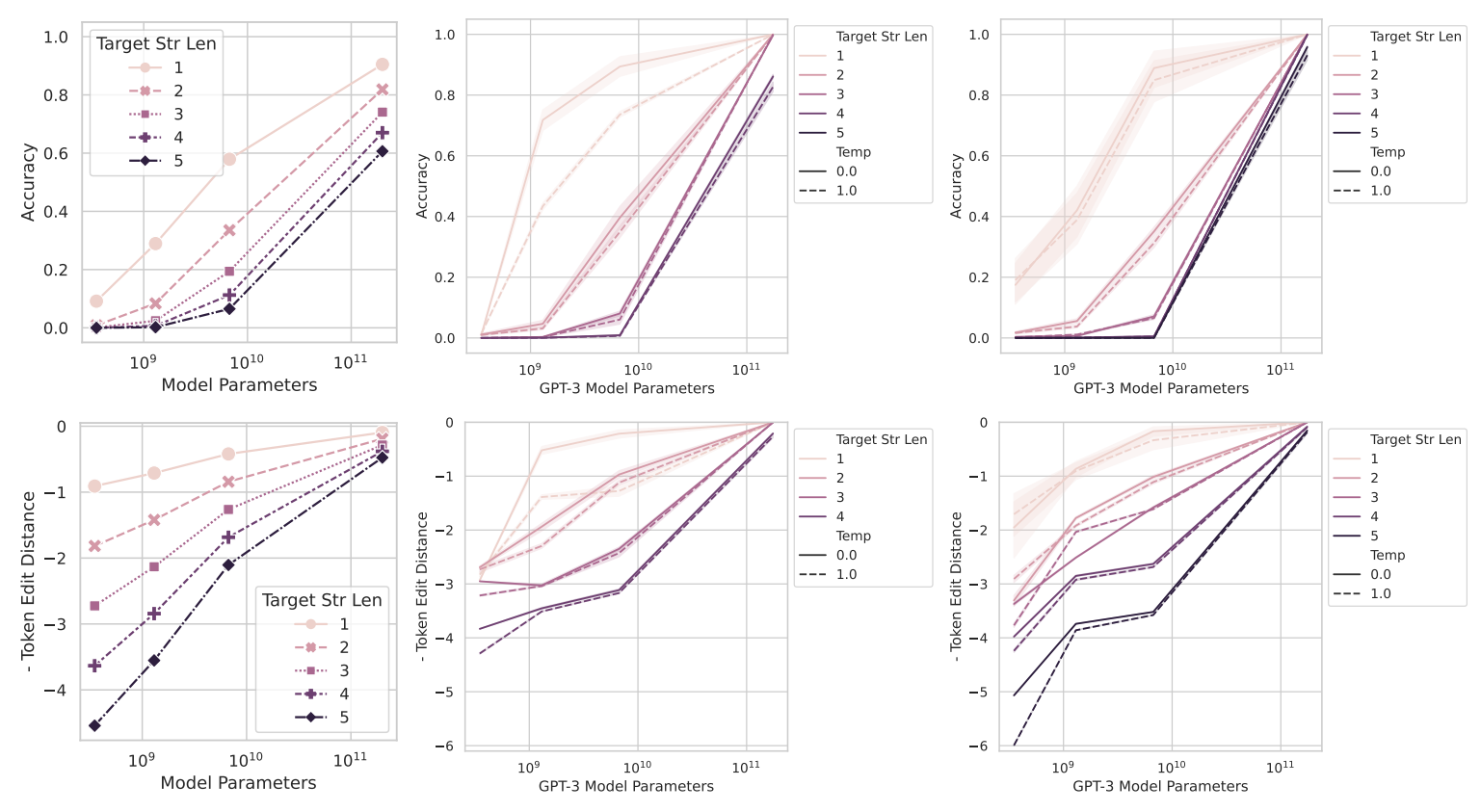
This nuanced approach calls into question the prevailing belief that emergent abilities are an inherent aspect of scaling AI models. Instead, it proposes that such abilities may emerge as a byproduct of the selected evaluative metrics. For instance, metrics demanding absolute correctness in a sequence of tokens (e.g., Accuracy) can cause a model's performance to appear volatile and unpredictable. Conversely, transitioning to metrics that allow for gradual improvement (e.g., Token Edit Distance or Brier Score) unveils a more consistent and predictable enhancement in model performance.
Moreover, the investigation highlights the critical role of metric selection in evaluating model performance, illustrating that emergent abilities could vanish under the scrutiny of better statistics or alternative metric choices. This finding emphasizes the need for meticulous consideration of how model outputs are quantified and interpreted.
By illuminating how the choice of evaluative measures might precipitate the sharp and unforeseeable shifts ascribed to emergent abilities, this study beckons a reassessment of our understanding of emergent abilities in LLMs. It not only illuminates the underlying mechanisms of these perceived abilities but also catalyzes a broader discourse on the methodologies and metrics applied in AI model assessment.
🚀 Conclusion & Future Directions
The exploration of emergent abilities in LLMs has unraveled the depth of these systems' ability to learn, adapt, and exceed their initial programming parameters.
- Benchmark Design and Metric Choice: The distinction between a task and its evaluation method is critical in benchmark construction. Choosing the right metrics is vital as it directly impacts our perception of LLMs' effectiveness, potentially masking their actual capabilities. It emphasizes the necessity for metrics that accurately reflect models' error rates and strengths, avoiding those that may misleadingly indicate emergent abilities.
- Ensuring Rigorous Controls: Highlighting emergent abilities within LLMs necessitates strict controls. The vast diversity of tasks, metrics, and model families demands comprehensive control measures to prevent abilities from being dismissed as statistical outliers.
- Promoting Model Openness: The path to collaborative and fruitful AI research is hampered by limited access to models and their outputs. Transparency in training processes and the sharing of outcomes is essential for the independent verification and replication of research findings.
- Rethinking Scaling: The observation that only a subset of tasks thought to exhibit emergent behaviors actually do challenges the practice of merely scaling models for enhanced AI functions.
Future Directions
- Venturing Beyond Scaling: Finding new ways to unleash LLMs' potential without exclusive reliance on scaling is crucial. Investigating innovative model architectures, training methodologies, and data formats may provide more efficient avenues to groundbreaking capabilities.
- Deep Dive into Task Analysis: Analyzing and categorizing tasks, focusing on memorability, data leakage, and the quality of test sets, is vital. This could offer deeper insights into LLMs' learning processes and their applicability across different contexts.
- Exploring Chain-of-Thought and In-Context Learning: Further research should examine the relationship between chain-of-thought prompting, in-context learning, and LLM reasoning. Understanding how models use context for complex reasoning could lead to new applications and enhanced interpretability.
- Mitigating Risks with Ethical Oversight: As LLM capabilities expand, so do the risks of unintended consequences. Creating tasks to assess and mitigate potentially harmful abilities is critical for identifying and addressing risks effectively.
- Enhancing Transparency and Addressing Data Leakage: Tackling data leakage challenges requires transparency from organizations developing LLMs. Researchers must remain cautious of potential biases, especially when evaluating models trained on proprietary datasets.
- Developing Comprehensive Evaluation Frameworks: Establishing frameworks for LLM evaluation that cover diverse metrics, task complexities, and model architectures is essential for a deeper understanding of these systems. Such frameworks should aim for inclusivity in terms of model sizes, architectures, and training data to capture the full range of capabilities and limitations.
To know more about LLM evaluations, make sure to check out our two-part series:
 Sayantan DasSayantan Das
Sayantan DasSayantan Das👓 Resources
- Characterizing Emergent Phenomena in Large Language Models
- Better Language Models Without Massive Compute
- Are Emergent Abilities of Large Language Models a Mirage?
- Are Emergent Abilities in Large Language Models just In-Context Learning?
- Scaling Laws for Downstream Task Performance of Large Language Models
- How predictable is language model benchmark performance?
- A Latent Space Theory for Emergent Abilities in Large Language Models
- 137 emergent abilities of large language models
- LessWrong discussion on emergent abilities in LLMs
- Scratchpad Technique
- Why can GPT learn in-context? Language Models implicitly perform gradient descent as meta-optimizers