
Evaluating LLMs for text to SQL with Prem text2sql
Explore the latest Text-to-SQL advancements in our new blog. We evaluate top models like GPT-4o and Llama using the newly released text2sql package on BIRDBench. Learn about Execution Accuracy, Valid Efficiency Score, and how open-source models are challenging closed-source alternatives.


Lastest update: 10th Sep 2024
Welcome to the second blog of our Text to SQL series. In our previous blog, we explored the Text-to-Sql problem and the different approaches, datasets, models, and evaluation methodologies currently available. We also delved into agentic methods employed to solve the problem.
 Anindyadeep Sannigrahi
Anindyadeep Sannigrahi
In this blog, we will evaluate state-of-the-art models like GPT-4o / 40-mini by Open AI, Claude by Anthropic, and Llama models by Meta AI. If you haven't checked our previous blog, you can read it here. We are also releasing our very first version of text2sql Python package. We will use this package to evaluate the latest models using the BirdBench dataset. The very first release of our package aims to provide easier ways to evaluate models for text-to-SQL tasks on different datasets. We also made it modular enough to use with other LLM orchestration libraries like langchain, llama-index, DSPy, etc. Finally, we also aim to extend this library so that you can evaluate it with your data. Check out here to learn more about text2sql.
 premAI-io
premAI-io🔄 A recap of text to SQL task and evaluation
Before starting with the main content, let's briefly understand what we are dealing with. Text to SQL is a task that aims to convert natural language questions into corresponding SQL queries that can be executed in relational databases. Interestingly, this problem statement was developed through research before the rise of large language models. After the boom of ChatGPT in general and Large Language Models in particular, these problems seem to steadily meet convergence.
The prompt for this task is simple: We dump all the table schema from the database we want to query and use these models to get the SQL output, parse it, and run it inside our database. To evaluate how good a model is, we see how many of the queries ran successfully (i.e., the output from the generated query matches the output of the ground-truth SQL query). There are two different ways to evaluate it.
- Execution Accuracy (EX): From the name, it is clear that the correctness of the LLM is measured by comparing the executed results from the LLM with the ground truth.
- Valid Efficiency Score (VES): The primary objective of LLM-generated SQL queries is to be accurate. However, it also needs to be performance-optimized when dealing with big data. This metric asses both of the objectives. It quantifies how efficient the query is and whether the query is accurate or not. The figure below shows how it is been computed.

Now that we have a quick recap of the general process, let's look at our process of how we evaluate different closed and open-source models with text2sql library.
📦 Evaluation using PremSQL
We start by introducing our new library, text2sql, which aims to facilitate the process of creating better text-to-SQL models and pipelines. Install PremSQL using PyPI.
pip install -U premsqlLearn more about PremSQL in our documentation:

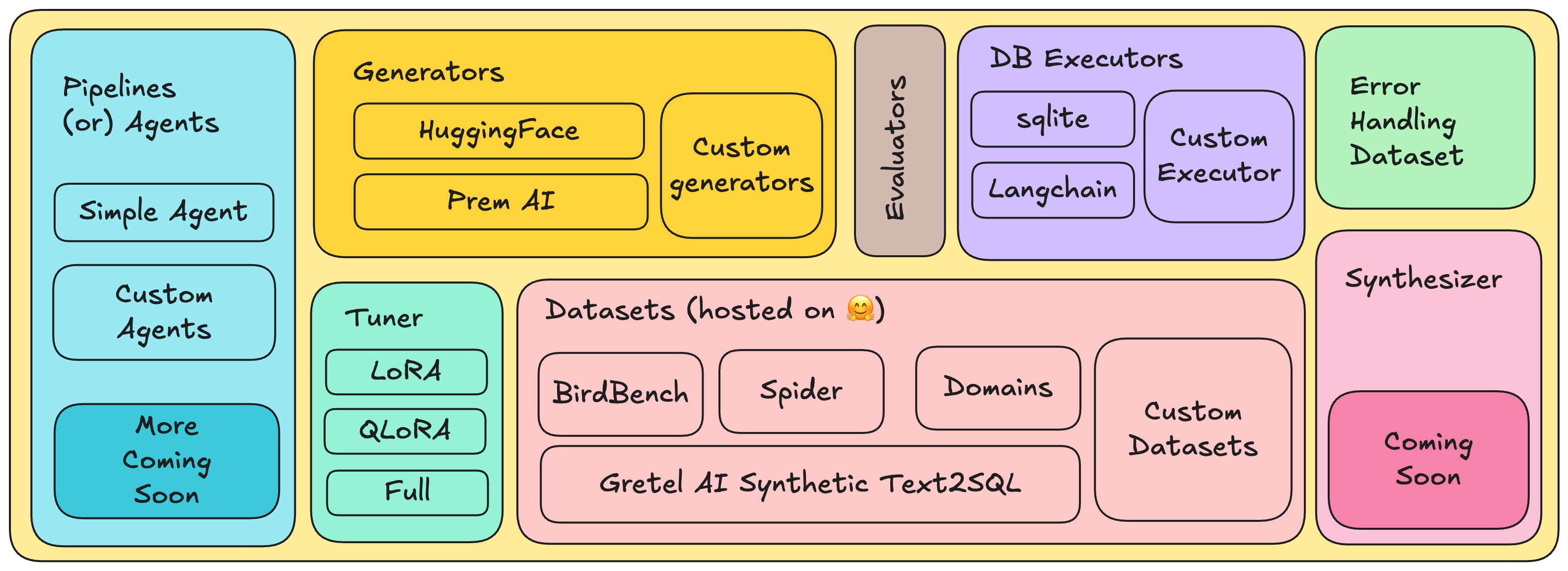
For our experiments, we will be using the dataset from BIRDBench. According to the paper:
"BIRD (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation) represents a pioneering, cross-domain dataset that examines the impact of extensive database contents on text-to-SQL parsing. BIRD contains over 12,751 unique question-SQL pairs, 95 big databases with a total size of 33.4 GB. It also covers more than 37 professional domains, such as blockchain, hockey, healthcare and education, etc."
Our text2sql library automatically downloads the dataset for evaluation and is compatible with HuggingFace models. You can extend the evaluation for your API or any other model implementation (running on a different engine like vLLM). All those detailed tutorials are available in our documentation and examples section. Here is the code on how to get started with evaluation using the Prem text2sql package.
from premsql.evaluator import Text2SQLEvaluator
from premsql.executors import SQLiteExecutor
from premsql.generators import Text2SQLGeneratorPremAI
from premsql.datasets import Text2SQLDataset
# Initialize the generator
generator = Text2SQLGeneratorPremAI(
project_id=1234,
model_name="gpt-4o",
experiment_name="testing_gpt4o",
type="test",
premai_api_key="xxx-xxx-xxx-xxx" # Get your API key at https://app.premai.io
)
# Initialize the dataset
dataset = Text2SQLDataset(
dataset_name='bird', split="validation", force_download=False,
dataset_folder="./dataset"
).setup_dataset()
# Generate the responses
response = generator.generate_and_save(
dataset=dataset
temperature=0.1,
max_new_tokens=256,
force=True
)
# Initialize the evaluator
executor = SQLiteExecutor()
evaluator = Text2SQLEvaluator(
executor=executor, experiment_path=generator.experiment_path
)
ex = evaluator.execute(
metric_name="accuracy",
model_responses=responses,
filter_by="difficulty"
)
ves = evaluator.execute(
metric_name="ves",
model_responses=responses,
filter_by="difficulty"
)Here is the summary of what is happening in the above code:
- First, we are loading the BIRDBench validation dataset, which is being processed internally.
- After this, we apply our prompt. The prompt contains the table schema and instructions for each database. You can also add your custom instruction (e.g., few-shot examples) to the prompt. The prompt has two modes: with and without knowledge. Knowledge here means it will provide some domain knowledge inside the prompt, which will help the LLM give better results. By default, we keep it true.
- We instantiate our clients, which generates results. We save the results and evaluate them to get the accuracy and Valid Efficiency Score metrics.
Using our evaluation library, you can not only evaluate but also properly debug and visualize the inputs and the outputs. For example, if some LLM is not working as expected, you can visualize the outputs generated by the LLM, the prompt given, etc.
We have also created a detailed tutorial explaining each of the components and their functions. You can check that out here.

📊 Results
The dev set of BIRDBench contains 1534 samples. We initially started with 20+ models (Open AI models, Gemma variants, Anthropic Models, Llama variants, Cohere models, etc.). However, a lot of them showed below-average results. We also saw a trend that adding domain knowledge gives more edge than not adding it. So we pruned down to take only 6 models, and those are as follows:
- Open AI GPT 4o
- Open AI GPT 4o mini
- Claude 3.5 Sonnet
- Claude 3 opus
- Code Llama 70B instruct
- Llama 3.1 405B instruct
Further, we have taken a small subset of the validation set, taking 100 simple, 100 moderate and 100 challenging questions.
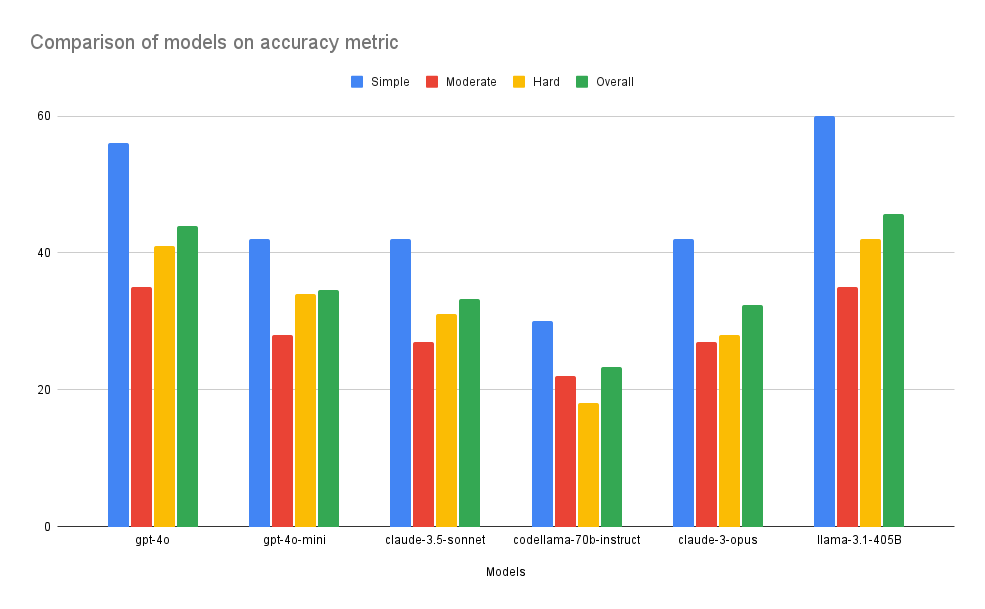
Comparison based on Accuracy
Here is the table that compares the above models on accuracy across 3 difficulty levels, 100 examples each.
| Models | Simple | Moderate | Hard | Overall |
|---|---|---|---|---|
| llama-3.1-405B | 60 | 35 | 42 | 45.66 |
| gpt-4o | 56 | 35 | 41 | 44 |
| gpt-4o-mini | 42 | 28 | 34 | 34.63 |
| claude-3.5-sonnet | 42 | 27 | 31 | 33.33 |
| claude-3-opus | 42 | 27 | 28 | 32.33 |
| codellama-70b-instruct | 30 | 22 | 18 | 23.33 |
Comparison based on Valid Efficiency Score (VES)
Here is the table that compares the above models on VES across 3 difficulty levels, 100 examples each.
| Models | Simple | Moderate | Hard | Overall |
|---|---|---|---|---|
| llama-3.1-405B | 95.3519 | 38.899 | 41.733 | 58.66 |
| gpt-4o | 54.9621 | 37.9472 | 41.9917 | 44.96 |
| gpt-4o-mini | 47.6245 | 26.3869 | 35.9608 | 36.65 |
| claude-3.5-sonnet | 44.4475 | 24.9191 | 31.3255 | 33.56 |
| claude-3-opus | 43.5037 | 25.8315 | 28.2806 | 32.53 |
| codellama-70b-instruct | 28.1269 | 26.1479 | 18.237 | 24.17 |
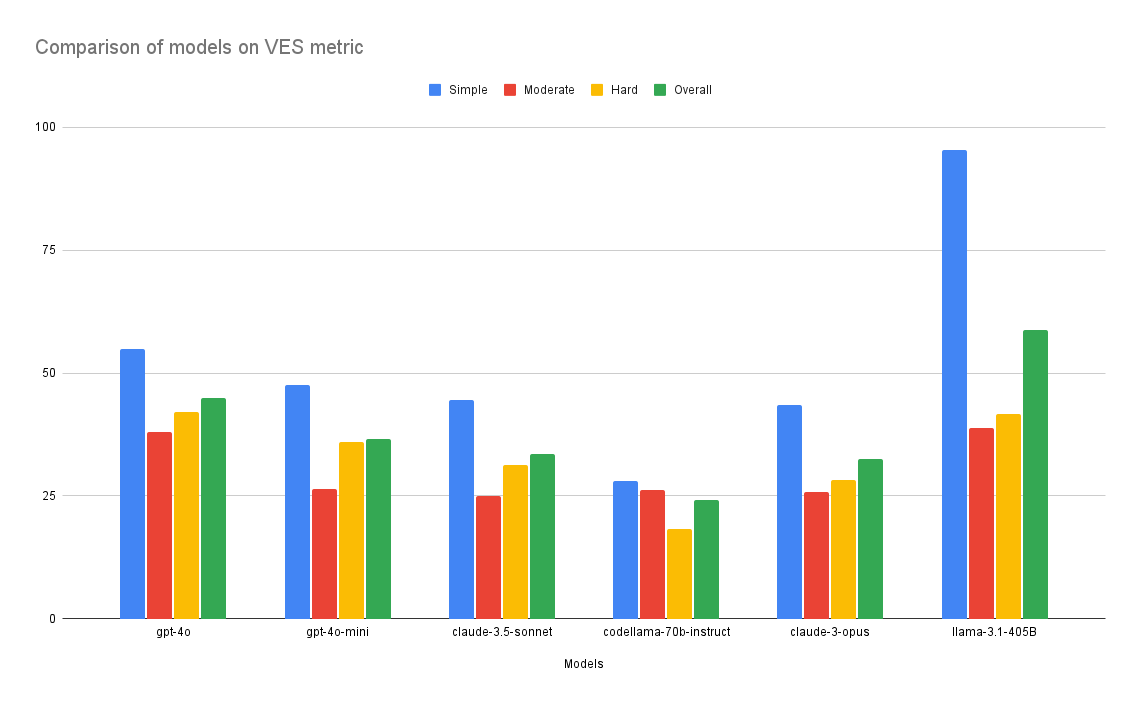
From the figures above, we can see that LLama 3.1 405B and GPT-4o are the winners here. The best part is that open-source models have started to outperform closed-source models without any external fine-tuning. You might question how VES for llama 3.1 reaches more than 95%. If you see the formula of VES, then it is defined like this (showing a part of the VES formula):
predicted_time = self.execute_sql(predicted_sql, db_path)
ground_truth_time = self.execute_sql(ground_truth, db_path)
diff_list.append(ground_truth_time / predicted_time)For simple questions, llama 3.1 405 B has written queries much faster than the baseline execution SQL query. If you look closely, this strange phenomenon happened only for simple examples and not for the other two difficulty levels. We also moved forward to evaluate GPT-4o for the full dev set of 1534 examples and got these results:
Accuracy:
---------
+-------------+-------------------+-------------------+
| Category | num_correct (%) | total questions |
+=============+===================+===================+
| simple | 58.4865 | 925 |
+-------------+-------------------+-------------------+
| moderate | 43.75 | 464 |
+-------------+-------------------+-------------------+
| challenging | 42.7586 | 145 |
+-------------+-------------------+-------------------+
| overall | 52.5424 | 1534 |
+-------------+-------------------+-------------------+
Valid Efficiency Score (VES):
-----------------------------
+-------------+-----------+-------------------+
| Category | VES (%) | total questions |
+=============+===========+===================+
| simple | 60.1844 | 925 |
+-------------+-----------+-------------------+
| moderate | 46.4345 | 464 |
+-------------+-----------+-------------------+
| challenging | 43.9845 | 145 |
+-------------+-----------+-------------------+
| overall | 54.4941 | 1534 |
+-------------+-----------+-------------------+GPT-4o gives an overall accuracy of 52.54%. Given the nature of the problem, it is quite surprising that one of the best existing models gives ~ a 50 % chance of getting an SQL query correct every time a question is asked.
🧐 Analysis
Surprisingly, Text to SQL on a high level looks like a solvable problem natively by LLMs. However, the metrics say something else. We also cross-verified our results from the leaderboard from BIRDBench.
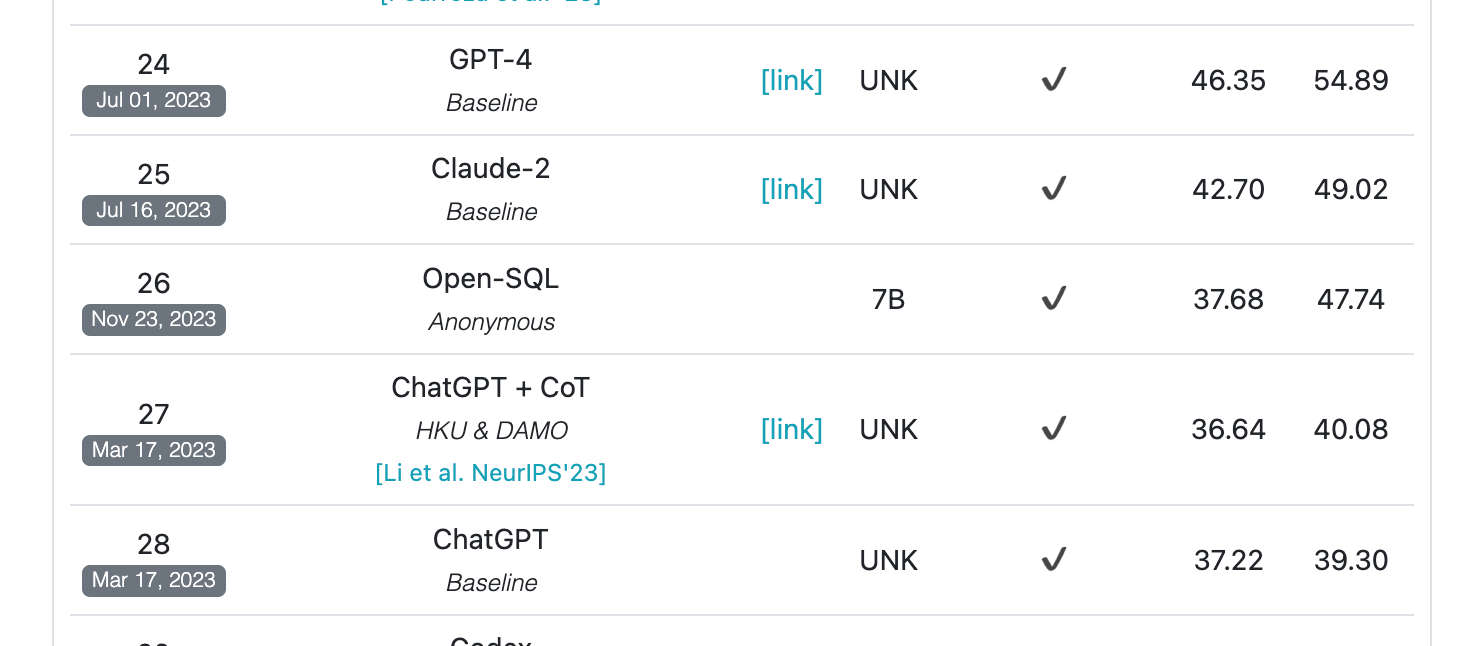
The above figure benchmarked these models one year ago. GPT-4o currently gives an accuracy of 52.54% and VES of 54.9%. According to BIRDBench's leaderboard, human performance is 92.96%. The current state of the art gives an accuracy of 67.21 %. This is from Distyl AI research, which uses Distillery + GPT-4o (paper/code unavailable).
Note: The current SoTA is not a single model; instead, their system is implemented end-to-end with agentic workflows. For now, we are more concerned about the native LLM performance. This sets the baseline threshold of 52% (GPT-4o) by a stand-alone LLM.
🚙 Aren't we there yet?
Great question. If we only consider native/stand-alone LLM performance, we still have many ways to go. But when we introduce several agentic workflows, like self-rectification (running the query more than once inside a sandbox, verifying it, repeating itself until it gets the right execution), using few-shot prompting, and fine-tuning on specific datasets, the performance dramatically increases.
Finally, these pipelines would be employed for users with databases that only concern their domain. These models can be further fine-tuned over that schema (if required) to give robust answers (which would apply to their databases only), enabling near-human-level performance in those cases.
🌀 Conclusion
In this blog, we have released our first version of the text2sql package. We have also evaluated current state-of-the-art models. You can now also use our package for your own evaluation purposes. There are several other benchmark datasets like Spider or WikiSQL. Our roadmap will try to include those in the future. In the next blog, we will open-source the fine-tuner module of the text2sql package. At Prem, we are very focused on the capabilities of small language models. We are also going to fine-tune some bunch of the small models and see how far they can reach or whether they can outperform the current baseline thresholds. Stay tuned for further updates and more releases.