
State of Text2SQL 2024

Text to SQL is a task that aims to convert natural language questions into corresponding SQL queries that can be executed in relational databases. Interestingly, this problem statement has been through research before the rise of Large Language Models.
Text to SQL creates a natural language interface between complex database schemas and queries. According to the Stackoverflow 2023 survey, around 51.52% of professional developers use SQL in their work, and 35.29% need to be trained to handle very complex queries efficiently. This kind of natural language query interface helps non database engineers to carry out their roles without spending much time honing this skill to an advanced level. In this blog, we will discuss the current research on the Text to SQL task. The blog will primarily focus on the current state-of-the-art models, datasets, evaluation, etc. We will also touch upon some agentic approaches in the end.
🔭 A Bird's eye view on the history
Text to SQL is a problem that has been actively researched since 2015. It all started with simple Parsing Trees and Rule-based approaches. Fast forward to 2019, after LSTMs, Transformers gained immense popularity. Encoder-decoder-based approaches like SQL sketch got immense traction. Fine-tuning off-the-shelf pre-trained language models like BERT and RoBERTa on Text to SQL corpus became popular in 2021. After the boom of Large Language Models like OpenAI-ChatGPT (closed source) and Llama 2/3 (Open Source), fine-tuning them on Text to SQL corpus has almost become the de facto standard to approach this problem. Here is a nice diagram that shows the evolution.
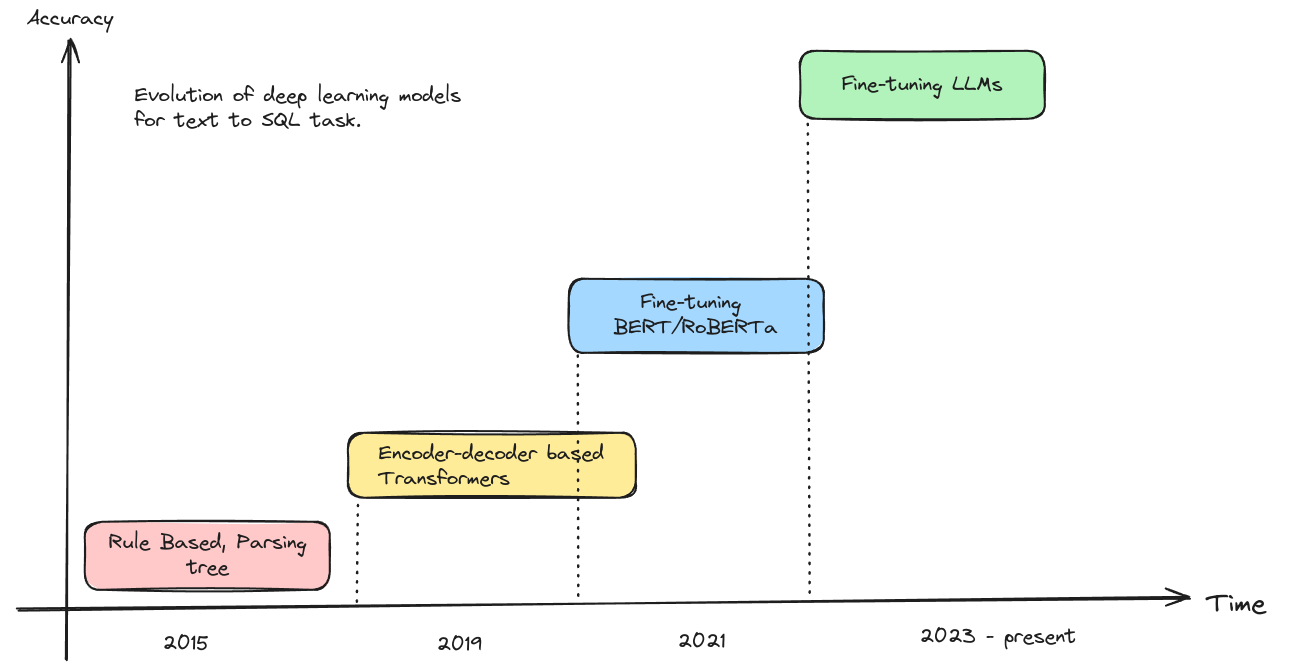
In this blog, we will mainly discuss on the LLM-based implementations and approaches since they have become the de-facto standard now. Although we are moving towards convergence to this problem, there are a lot of issues these models face. Some of them are as follows:
- Models get hallucinated when they are introduced to different unseen databases with complex schemas.
- Models fail to generate correct SQL statements, which include rare and complex operations and syntax (examples include sub-queries, outer joins, window functions, etc.).
- Sometimes, these models fail when introduced with a database that includes cross-domain knowledge (or domain knowledge that has been explored less).
Let's start with the currently available datasets for fine-tuning these models.

🛢️ Datasets
Data has always been very important when it comes to training models. Providing correct data which avoids human level errors or biases is very crucial. The overall Text to SQL task for LLMs can be divided into three sub-tasks or components:
- Domain context: This component contains all the domain-level context or knowledge that will help the LLM make decisions when a query requires some domain knowledge.
- Instruction: An instruction is also provided that tells the LLM what to do and what needs to be achieved. In our case, the instruction should tell the LLM to understand the context, and underlined DB schema to generate correct and performant SQL queries.
- Database Schema: This is very important. If the schema is not provided, the LLM will generate column names, table names or entities which is not present in the database and will cause an error.
So, most of the datasets used for fine-tuning these language models would roughly contain those three components in one way or another. Some datasets are extensively used for training/fine-tuning, and some are used for evaluation.
Common benchmarking text-to-sql evaluation datasets includes: Spider, BIRD, SParC, KaggleDBQA etc. Popular datasets which are used for fine-tuning are: WikiSQL, BIRD etc.
All of these datasets can also be categorized into three classes (based on this paper):
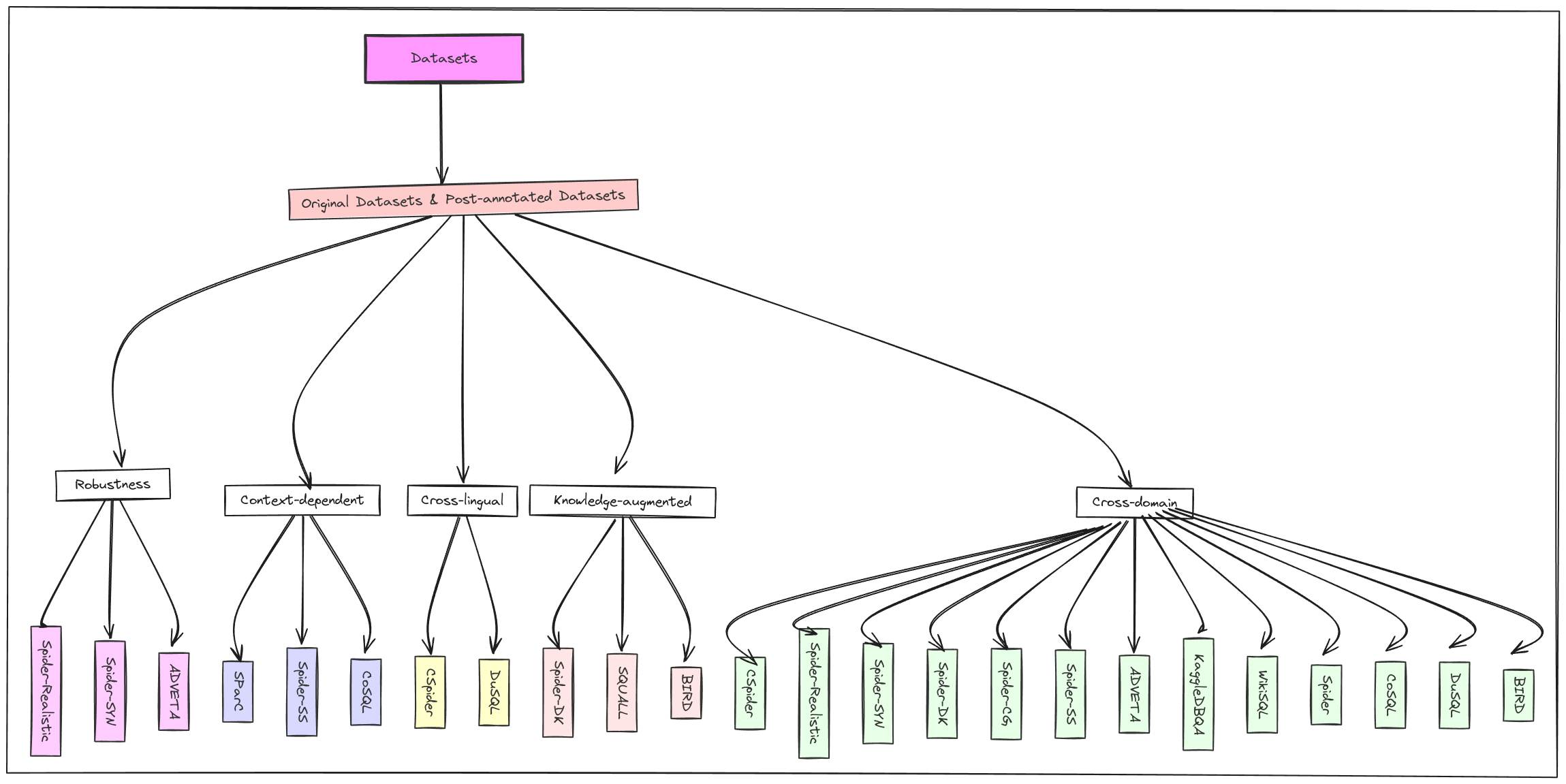
- Cross-domain dataset: These are the datasets where the background information of databases comes from different domains.
- Knowledge Augmented Datasets: Here, human annotators annotate each text-to-SQL sample with external knowledge (for example, numerical reasoning, domain knowledge, value illustration, etc)
- Context-dependent datasets: These datasets are more conversational in nature (single or multi-turn). The above two types are more traditional, consisting of a single user question and an SQL query.
Figure 2 above shows a nice taxonomy tree for the different types of datasets. The two tables below provide more information about the dataset's sources.
| Dataset | Release Time | #Examples | #DB | #Table/DB | #Row/DB | Characteristics |
|---|---|---|---|---|---|---|
| BIRD | May-2023 | 12,751 | 95 | 7.3 | 549K | Cross-domain, Knowledge-augmented |
| KaggleDBQA | Jun-2021 | 272 | 8 | 2.3 | 280K | Cross-domain |
| DuSQL | Nov-2020 | 23,797 | 200 | 4.1 | - | Cross-domain, Cross-lingual |
| SQUALL | Oct-2020 | 11,468 | 1,679 | 1 | - | Knowledge-augmented |
| CoSQL | Sep-2019 | 15,598 | 200 | - | - | Cross-domain, Context-dependent |
| Spider | Sep-2018 | 10,181 | 200 | 5.1 | 2K | Cross-domain |
| WikiSQL | Aug-2017 | 80,654 | 26,521 | 1 | 17 | Cross-domain |
Table 1: Original Text to SQL Datasets
| Dataset | Release Time | Source Dataset | Special Setting | Characteristics |
|---|---|---|---|---|
| ADVETA | Dec-2022 | Spider, etc. | Adversarial table perturbation | Robustness |
| Spider-SS&CG | May-2022 | Spider | Splitting example into sub-examples | Context-dependent |
| Spider-DK | Sep-2021 | Spider | Adding domain knowledge | Knowledge-augmented |
| Spider-SYN | Jun-2021 | Spider | Manual synonym replacement | Robustness |
| Spider-Realistic | Oct-2020 | Spider | Removing column names in question | Robustness |
| CSpider | Sep-2019 | Spider | Chinese version of Spider | Cross-lingual |
| SParC | Jun-2019 | Spider | Annotate conversational contents | Context-dependent |
Table 2: Post-annotated datasets, which are derived from the original datasets
Synthetic dataset for Text to SQL
Synthetic datasets are very new and have started to become very accessible after the rise of LLMs. In general synthetic datasets contains synethetic datapoints which are either used through statistical or generative means to train some model, when actual dataset has very less number of datapoints. For our text-to-SQL task, recently a dataset named: gretelai/synthetic_text_to_sql with more than 100K records have been synthesized by a company named gretel.ai. The dataset also follows the structure and has all the three components mentioned above. It contains queries with different levels of complexity. However, synthetic datasets sometimes act as a double-edged sword, where we have a good amount of volume of training data, but if those data are not scrutinized properly, it might introduce biases and errors when models are trained with that data. If you want to learn more about synthetic datasets, you can check out this blog.
 Filippo Pedrazzini
Filippo Pedrazzini📊 Evaluation and metrics
Evaluation of LLMs is a very wide spectrum topic. There have always been some generic methods of evaluation, like exact text-matching or embedding-based matches. However, text-to-sql is a very analytical problem. The task is simple, given some context, question, schema, we need to output the SQL string. Now, we can evaluate this with the ground truth in two different ways:
- Content Matching based evaluation.
- Execution based evaluation.
Content Matching based evaluation
By the name, we can understand that it uses some sort of string manipulation and matching technique to evaluate the LLMs. This type of evaluation can be done in two ways:
- Component Matching: It first extracts different components and sub-components of the two SQL statements (like:
SELECT,WHERE,GROUP BY,ORDER BYetc) and then do the exact match of the components of the generated and ground-truth SQL statement. It uses the F1-score as the metric to quantify the match. - Exact Matching: This can be considered a special case of Component Matching. Component Matching gives us a percentage of how much the generated components are identical to the ground truth. In Exact Matching, it will be correct if all the components match 100%; otherwise, it would be considered incorrect.
We have also made a detailed tutorial on how you can use PremAI's generative AI Platform with Stanford DSPy to carry out Text to SQL along with evaluation. Check it out here. Consider giving it a star, since we are adding more recipies in our cookbook.

Execution based evaluation
Execution-based metrics first parse the SQL string (remove anything other than the code), then execute the generated SQL in the target database and check with the ground-truth result. They return true only if the result matches. Otherwise, they are considered incorrect. This type of evaluation incorporates two different metrics to assess LLMs for this task.
- Execution Accuracy (EX): From the name, it is clear that it measures the correctness of the LLM by comparing the executed results from the LLM with the ground truth.
- Valid Efficiency Score (VES): The primary objective of LLM-generated SQL queries is to be accurate. However, it also needs to be performance-optimized when dealing with big data. This metric asses both of the objectives. It quantifies how efficient the query is and whether the query is accurate or not. The figure below shows how it is been computed,

Execution-based evaluation can be considered more reliable than content-based matching. However, execution-based matching can only be done when a database is available. The table below shows how current open-source datasets perform in some benchmark datasets.

🧮 Current Models and Techniques
In this section, we will explore different models and approaches that tackle the problem. Broadly, we can classify model approaches into two main categories:
- In-Context Learning
- Fine-tuning
In-Context Learning
There are different ways of practising in-context learning. However, in this blog, we are going to discuss four types of prompting as follows:
Trivial Prompting: Trivial prompts (baseline), including zero-shot and few-shot settings, utilize minimal input examples to guide large language models (LLMs) in generating SQL queries from natural language questions. These prompts rely on the inherent capabilities of LLMs to understand and respond accurately with limited contextual guidance. Let's coin this as C0.
Decomposition: The decomposition approach breaks down complex user questions into simpler sub-questions or tasks, making it easier for LLMs to generate accurate SQL queries. This method includes multi-step reasoning processes and the handling of intermediate steps, which improves the model's performance by simplifying the problem-solving process. Let's term it as C1.
Prompt Optimization: Prompt optimization focuses on improving the quality and structure of input prompts through techniques such as few-shot sampling strategies, schema augmentation, and external knowledge generation. This approach enhances the LLMs' SQL generation accuracy by providing more relevant and contextually rich prompts. Let's term it as C2.
Reasoning Enhancement: Reasoning enhancement involves incorporating advanced reasoning techniques, such as Chain-of-Thought (CoT) prompting or Program-of-Thought (PoT) prompting, to guide LLMs through complex logical and arithmetic reasoning steps. This method improves the LLMs' ability to handle complex queries by making the reasoning process explicit and structured. Let's term it as C3
Execution Refinement: Execution refinement incorporates feedback from executing the generated SQL queries to refine and improve the final output. This method involves sampling multiple SQL queries, executing them in the database, and using execution results to select or regenerate the most accurate SQL query, ensuring better alignment with the database environment. Let's term it as C4.
Here are some methods that incorporate either or a combination of these approaches. Since most of the benchmark is based on the Spider benchmark dataset, you can check out the current result and leaderboard here.
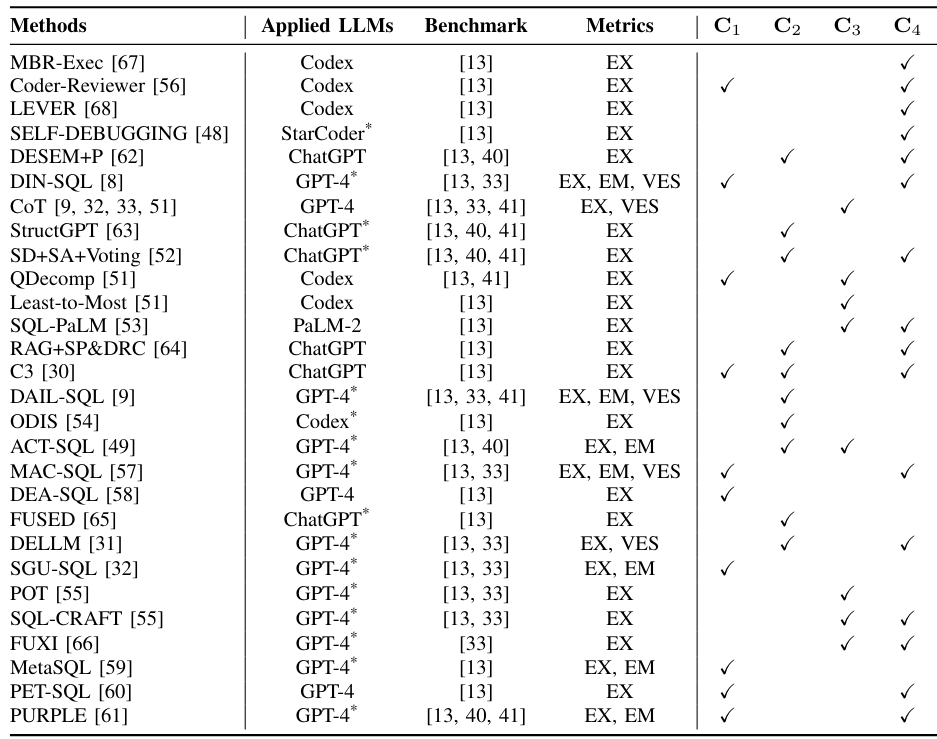
Fine-tuning
Fine-tuning is commonly practised on Large Language Models to align them for a domain-specific use case. Common tasks include making the model aware of private data (for better question answering) or acting in some specific way (for example, generating good commit messages from code diff). So, fine-tuning a model to generate correct SQL from text with proper data format is almost a no-brainer now. The difference lies in what the community has used additional methods. We are specifically going to discuss about the methods here mostly. You can check out the model's benchmarks in this leaderboard (However, it combines fine-tuning and in-context learning methods with open and closed source models).
Data Augmentation: The quality of training data is paramount for effective fine-tuning. Data augmentation techniques become invaluable in scenarios where high-quality annotated data is scarce. These techniques involve generating additional training examples by transforming existing data, such as paraphrasing or adding synthetic data. Data-augmented fine-tuning helps models generalize better and improve their performance on diverse and complex queries. By expanding the training dataset, models are exposed to a wider variety of SQL queries, enhancing their ability to handle different database schemas and user questions. For instance in Text2SQL:
- DAIL-SQL samples a few-shot text and SQL instances and uses them in the prompt to fine-tune using supervised fine-tuning.
- SymbolLM utilizes a two-stage tuning framework for Text2SQL tasks. In the first stage, called the Injection stage, various symbolic knowledge is injected into the model by conducting supervised fine-tuning (SFT) on a collection of text-to-symbol datasets. In the second stage, the Infusion stage, the model is further fine-tuned on a mixture of symbolic and general instruction-tuning data to maintain proficiency in symbolic and natural language (NL) tasks. This approach helps the model generate symbolic representations of the input questions and rely on external solvers for execution, ensuring a balanced capability between symbol-centric and NL-centric tasks.
- CodeS: CodeS distinguishes itself in the Text-to-SQL task by fine-tuning open-source language models, specifically for SQL generation with parameter sizes ranging from 1B to 15B, significantly smaller than existing models like GPT-4. It employs an incremental pre-training approach using a curated SQL-centric corpus and addresses schema linking and domain adaptation challenges through strategic prompt construction and bi-directional data augmentation (which mainly includes data generation from ChatGPT or other SoTA closed source models, which points us to knowledge distillation-based learning). This leads to superior accuracy and robustness on challenging text-to-SQL benchmarks while maintaining smaller model sizes.
Decomposition Techniques: Decomposition techniques enhance fine-tuning by breaking complex tasks into manageable sub-tasks. For text-to-SQL, this involves splitting intricate natural language questions into simpler components that the model can handle more effectively. Decomposition improves the model’s accuracy by simplifying the SQL generation process, enabling it to tackle challenging queries that involve nested clauses or complex joins. This approach ensures that models can generate precise SQL queries even for convoluted user inputs.
Enhanced benchmarking approaches for Text to SQL
Recently, this paper constructed a newer benchmark dataset to address the overfitting of LLMs through five different SQL tasks: text-to-SQL, SQL Debugging, SQL Optimization, Schema Linking, and SQL-to-text. They conduct an end-to-end evaluation using optimal prompts for SQL. They also propose multi-round generations with self-debugging for error corrections and found that only 1-2 rounds are optimal.
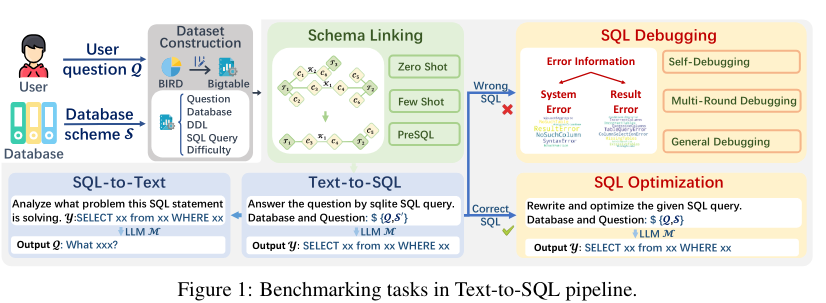
Using this benchmarking pipeline shown in Figure 5, here are some benchmark scores for different above-mentioned tasks.
From a quick glance, we can see that InternLM2-20B gives comparable results with its 70BB counterparts.
🤖 Agentic frameworks for Text to SQL
Building an agentic framework using LLMs has been the most tremendous success in the generative AI ecosystem. One of the problems that LLMs fail continuously is that they are very much prone to subtle hallucinations. Several reasons for hallucination include Knowledge cut-off, considerable context length, the inability of LLMs to reason properly, etc. However, suppose we provide LLMs with tools like a calculator for basic math, web search to fetch recent information (otherwise, it would fall under knowledge cutoff), and APIs call to fetch or stream domain-specific information to make the LLM more than just the next token predicting machines. Tool/Function calling is the basis of these agentic frameworks. If you want to learn more about tool calling in LLMs, check out our documentation, where we gave more details, and also learn how to access tool calling with Prem across the state-of-the-art models.

So far, we have seen that these models fail to generate correct and performant SQL queries after a certain threshold. So, to make this whole text-to-SQL task more productive and focused, we should use different tools and create these agents to make the overall workflow more robust in nature.
MAC-SQL is a recent framework designed where only model-based Text-to-s SQL methods fail after a certain point. This framework is designed to tackle the challenges LLM-based Text-to-SQL methods face when dealing with large databases and complex multi-step reasoning questions. The framework comprises a core Decomposer agent that generates Text-to-SQL queries using few-shot chain-of-thought reasoning and is supported by two auxiliary agents:
- The Selector agent identifies relevant parts of the database schema to reduce irrelevant data interference.
- The Refiner agent employs external tools to refine erroneous SQL queries.
These agents collaborate dynamically and can be expanded to include new tools, enhancing the flexibility and effectiveness of the Text-to-SQL parsing. The framework leverages GPT-4 as the backbone of LLM. It fine-tunes an open-source model, SQL-Llama, to achieve near-comparable performance, demonstrating the robustness and adaptability of the multi-agent approach.
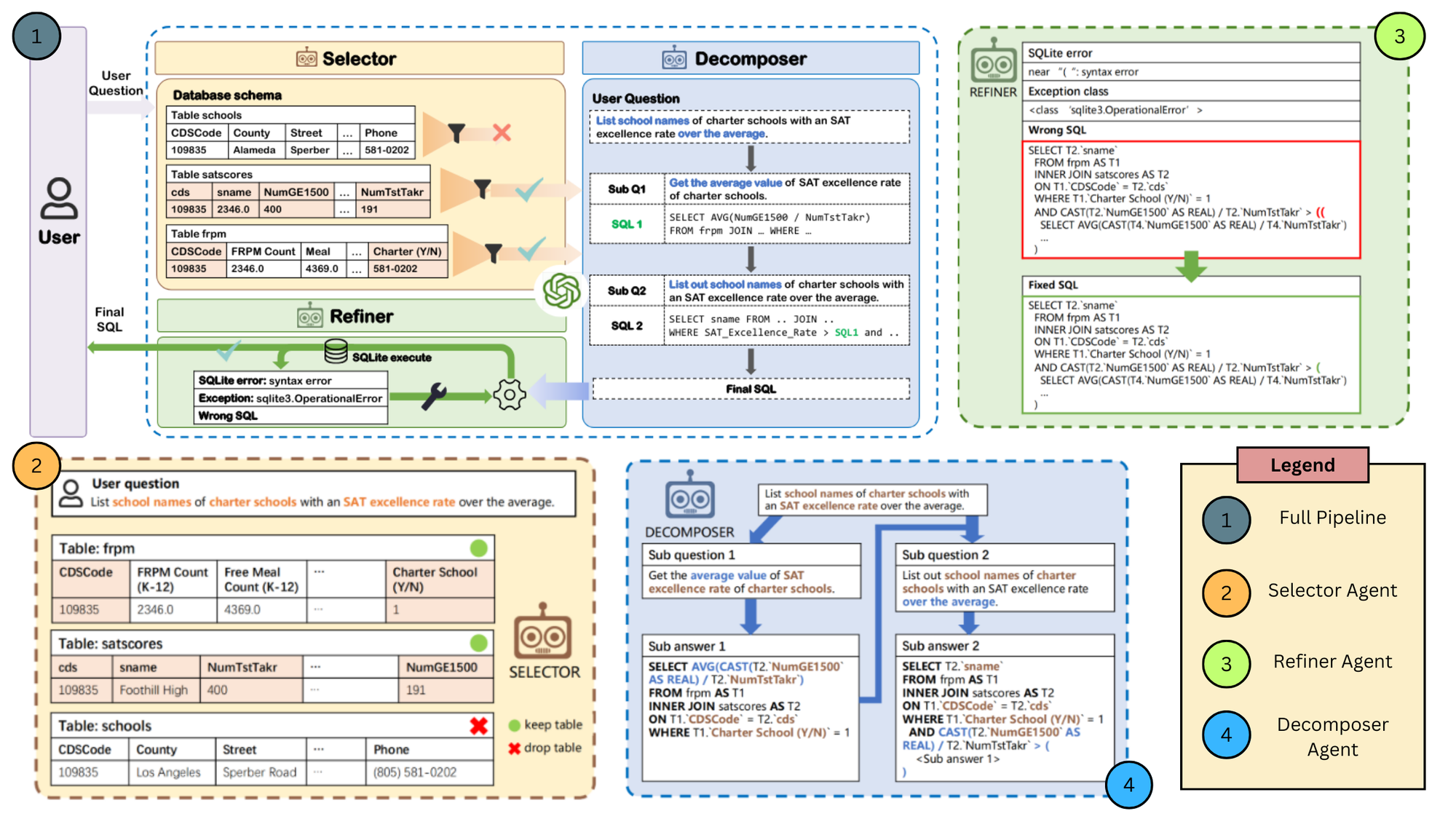
As shown in the above figure, each of the components is an independent agent that optimizes a part of the overall pipeline to generate more accurate and performant SQL statements. Here are the benchmark results from this pipeline.
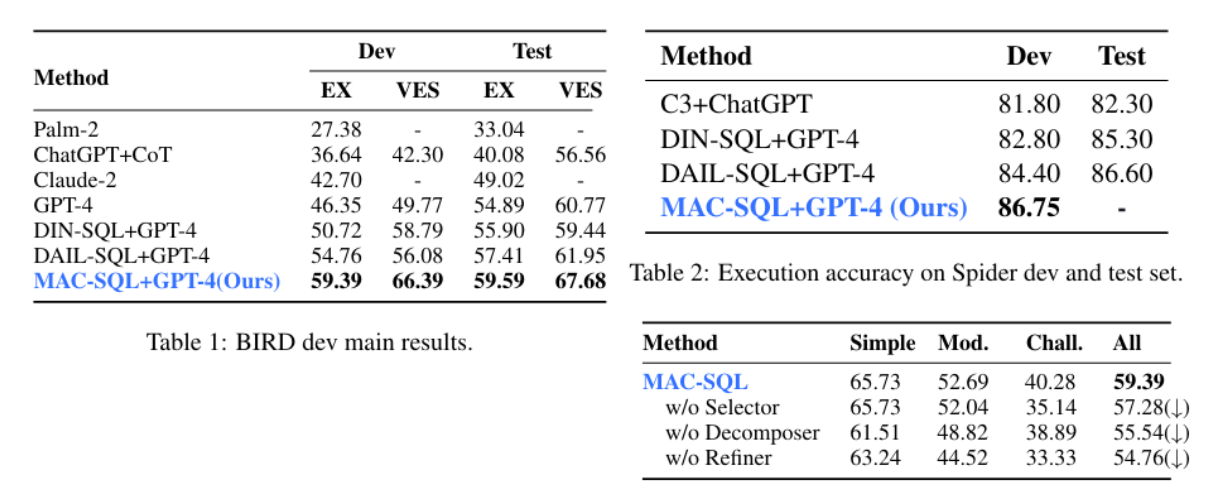
The leaps in the scores are significant. This concludes that agent based framework can help us to make more robust pipelines in general and make more performant Text to SQL pipelines in particular.
🌀 Conclusion
In this blog, we have reviewed recent work on Text-to-SQL tasks. We explored different datasets (training/fine-tuning and benchmarking dataset), saw how LLMs are evaluated for this task and uncovered different methods (in-context learning and fine-tuning based) for tuning and aligning the models. Last, we also discovered how an agentic framework can improve performance and make pipelines more robust. However, one clear indication is that a vast performance dependency comes from the data we are using to train these models, the way we represent the data, the models we are using and how we are fine-tuning them and using different prompting methods to get the most out of it. One thing that we saw while doing this research is that small language models (like Phi2 / Phi-3 mini, Gemma 2B, etc.) are used sparingly. So, in the next blog, we will evaluate, compare, and analyse how much the performance of SLMs differs from the existing SoTA LLMs, so stay tuned.
💡 References
- Stack Overflow 2023 Developers survey
- Next Generation Database Interfaces: A Survey of LLM based Text-to-SQL.
- MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
- Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation
- CodeS: Towards building Open Source Language Models for Text-to-SQL