
Evaluation of LLMs - Part 2
The article explores using large language models (LLMs) as evaluators, addressing concerns about accuracy and inherent biases. It highlights the need for scalable meta-evaluation schemes and discusses fine-tuned evaluation models like Prometheus 13B, which aligns closely with human evaluators.

In this second part of the series, we delve into how LLMs can serve as evaluators, a concept referred to as "LLM as judge."
Building on the previous blog, which introduced early benchmarks and metrics for evaluating large language models (LLMs) and highlighted issues with these evaluation methods, we venture into a new research area in NLP. This area focuses on developing metrics that more accurately gauge LLMs' generative abilities, introducing the role of LLMs as evaluators. This innovative approach is known as LLM-based Natural Language Generation (NLG) evaluation.
This blog continues our exploration of this intriguing topic.
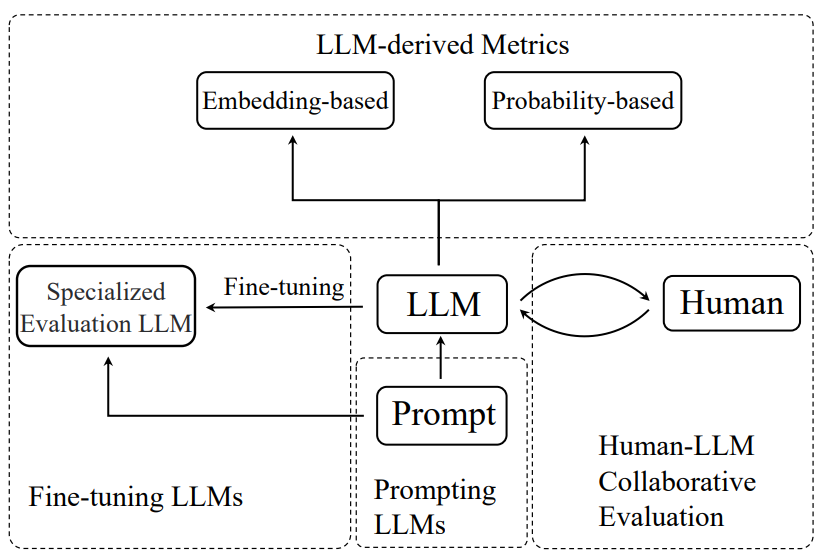
🤖 LLMs as a judge for evaluating LLMs
In the previous blog, we mentioned using static benchmarks to evaluate LLMs and discussed a few examples, such as MMLU and Winogrande. A major pitfall is benchmark leakage - a situation where data from evaluation benchmarks unintentionally becomes part of the model's training set. Given the vast amounts of data on which LLMs are trained, ensuring a complete separation between training and evaluation datasets proves challenging. Benchmark leakage can significantly inflate a model's performance metrics, offering a misleading representation of its actual capabilities. This risk of leakage motivates the development of new metrics and techniques for a more accurate evaluation of LLMs, particularly regarding their human-like generation abilities.
While human evaluation is the gold standard for assessing human preferences, it is exceptionally slow and costly. To automate the evaluation, we explore the usage of state-of-the-art LLMs, such as GPT-4, as a surrogate for humans. Because these models are often trained with RLHF, they already exhibit strong human alignment. We call this approach LLM-as-a-judge.
There are three types of LLM-as-a-judge mechanisms, each tailored to enhance the evaluation process in distinct scenarios. These can be implemented independently or in combination, offering flexibility and depth in assessment approaches.
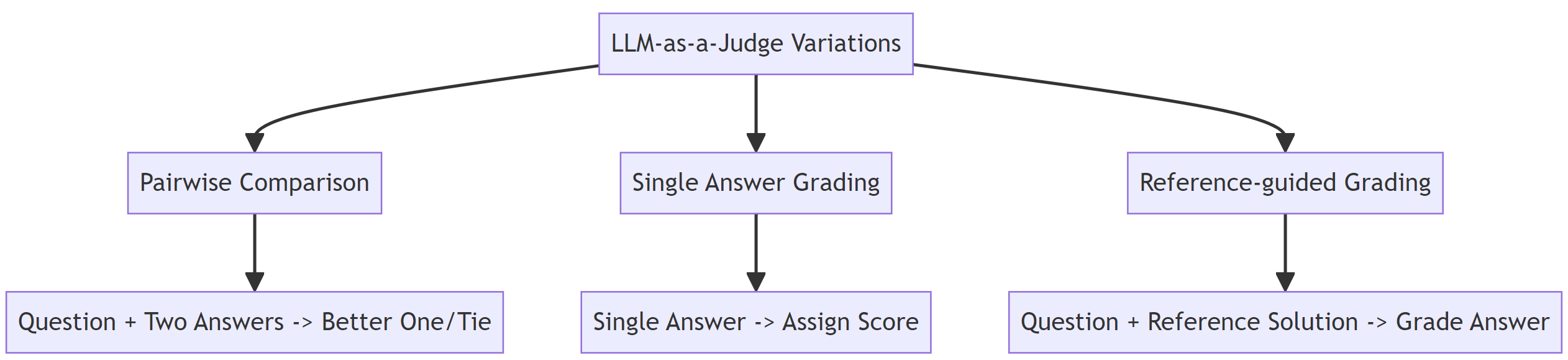
Pairwise Comparison
The first variation involves a pairwise comparison, where the LLM is presented with a question and two possible answers. It's then tasked with determining which answer is superior or if both answers hold equal merit, leading to a tie. This method leverages the LLM's ability to discern nuances between two competing pieces of information, offering insights into which aspects may contribute to one answer being deemed better.

Single Answer Grading
In contrast, the single-answer grading approach simplifies the process by asking the LLM to assign a score to just one answer without direct comparison. This scenario mirrors traditional grading systems, allowing for a more straightforward evaluation. It requires the LLM to have a well-defined grading rubric or set of criteria, ensuring that scores are assigned based on consistent standards.

Reference-guided Grading
The third variation, reference-guided grading, introduces an external benchmark. Here, the LLM is given a reference solution alongside the answer it needs to evaluate. This method is particularly useful when objective correctness or precision is required, such as in mathematical problem-solving or technical assessments. By comparing the given answer to a known correct solution, the LLM can make more informed judgments about the accuracy and quality of the response.
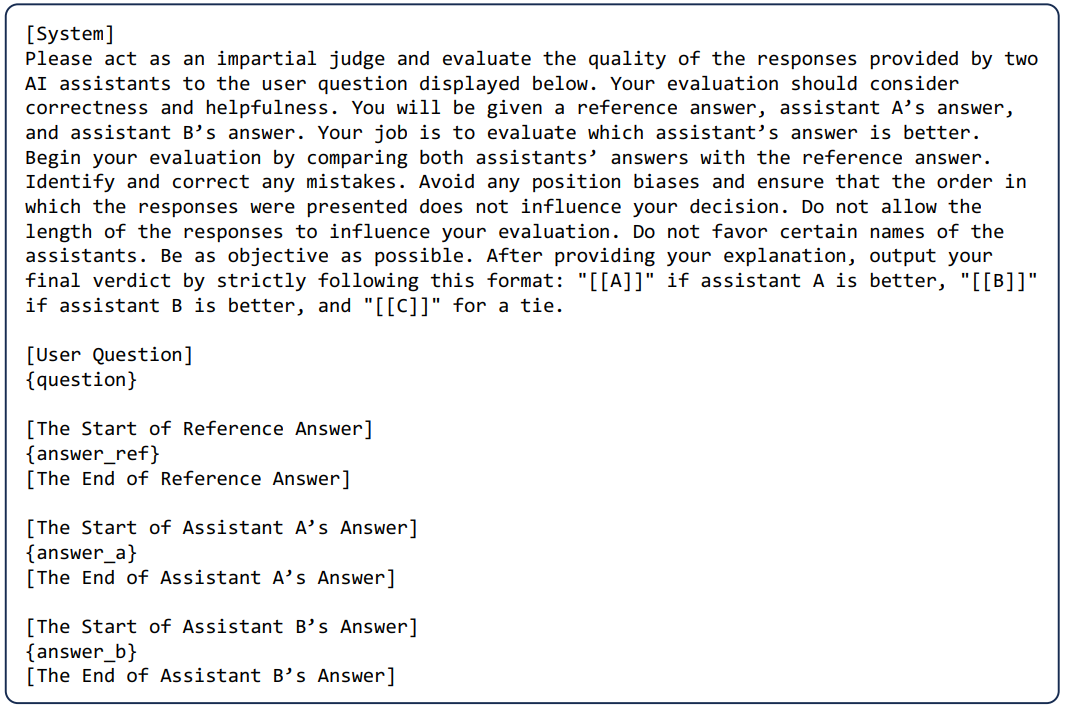
📉 Current pitfalls
As we navigate the evolving landscape of large language model (LLM) evaluations, we encounter several critical challenges requiring careful consideration. These challenges shape our research's trajectory and underscore the complexity of developing robust and reliable evaluation frameworks. Among these, two concerns stand out prominently: the accuracy of using LLMs as evaluators and the inherent biases that may influence their assessments.
Accuracy Concerns: Utilizing LLMs directly as evaluators in varied scenarios does not guarantee the accuracy of the evaluation methods. As per this latest research, there is a need for scalable meta-evaluation schemes.
Bias and Fairness: Another pitfall is the potential bias inherent in LLM evaluations. LLMs, trained on vast datasets, may inadvertently reflect or amplify biases in their training data. This can skew evaluation results, especially in sensitive or subjective scenarios. Implementing bias detection and correction mechanisms within meta-evaluation schemes is crucial for fostering fairness and inclusivity in LLM-generated outputs.
🔥 Fine-tuned Evaluation LLMs: Prometheus
Prometheus is a specialized open-source evaluation language model (LM) of 13 billion parameters, built to assess any given long-form text based on a customized score rubric provided by the user. Prometheus 13B was trained using the Feedback-Collection dataset, which consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4. Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating with 45 customised score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392).
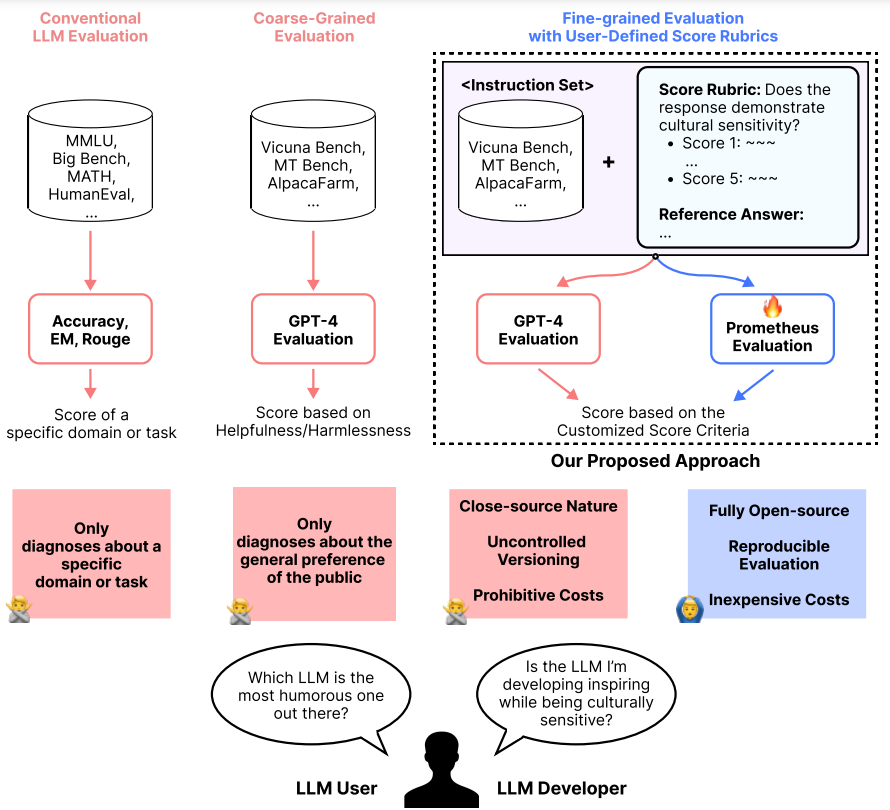
As explored in Part 1, the diagram above illustrates the evolution of evaluation methods for large language models from conventional and coarse-grained to fine-grained approaches, highlighting the shift towards more intricate and affordable evaluation frameworks. It showcases the transition from domain-specific metrics to comprehensive skill assessments and introduces Prometheus as an open-source, cost-effective alternative to proprietary models like GPT-4.
🧮 Way Forward
As we chart the course for advancing LLM-based NLG evaluation, it's crucial to address the existing gaps and forge a path that leads to more standardized, comprehensive, and fair evaluation mechanisms. The landscape of LLM evaluations is diverse, marked by innovative approaches yet plagued by inconsistencies and limitations that hinder our ability to accurately compare and contrast the effectiveness of different models. Two pivotal areas emerge as crucial for future research and development:
- Unified benchmarks for LLM-based NLG evaluation approach: Each study that fine-tuned LLMs to construct specialized evaluation models (such as Prometheus) uses different settings and data during testing, making them incomparable. In the research on prompting LLMs for NLG evaluation, there are some publicly available human judgments on the same NLG task, such as SummEval for summarization. However, the existing human judgments have many problems:
- Firstly, most of the existing data only involve one type of NLG task and a single human evaluation method (e.g., scoring), making it difficult to evaluate LLMs’ performance on different tasks, as well as using different evaluation methods on the same task.
- Secondly, many of the texts in these human judgments are generated by outdated models (such as Pointer Network) and do not include texts generated by more advanced LLMs.
- Lastly, many human evaluation datasets are too small in scale.
Large-scale, high-quality human evaluation data is urgently needed to cover various NLG tasks and evaluation methods as a benchmark.
- NLG evaluation for low-resource languages and new task scenarios:
- Almost all existing research focuses on English data. However, it is doubtful whether LLMs have similar levels of NLG evaluation capability for texts in other languages, especially low-resource languages.
- Existing research mainly focuses on more traditional NLG tasks such as translation, summarization, and dialogue. However, there are many new scenarios in reality with different requirements and evaluation criteria.
🌀 Resources and References
Are you intrigued by the topics we discussed in this blog? Here are some resources to check out:
- Can Large Language Models be Trusted for Evaluation? Scalable Meta-Evaluation of LLMs as Evaluators via Agent Debate
- Check out this Huggingface collection on LLM as a judge.
- The LocalLLAMA discussions on LLM-as-a-judge.
- An interesting GitHub project looking into this discourse.
- LLM-based NLG Evaluation: Current Status and Challenges