Fine-tuning Embeddings for Domain-Specific NLP
Fine-tuning embeddings are crucial for enhancing domain-specific NLP applications. General models may fall short in specialised fields like healthcare or law. By fine-tuning, models improve accuracy, relevance, and understanding of specific terminologies, ensuring better performance in niche tasks.


Why Fine-tuning Embeddings are Crucial for Domain-Specific NLP Applications
Fine-tuning embeddings plays a vital role in enhancing the performance of Natural Language Processing (NLP) systems. While general-purpose models can provide adequate results for broad tasks, they often fall short when dealing with specialized domains such as healthcare, legal fields, or finance. This is where fine-tuning comes into play, allowing the embedding models to better grasp the nuanced terminology and context-specific details of a domain.
For example, in the medical field, generic embedding models may struggle with highly specialized medical vocabulary, leading to subpar performance in information retrieval or question answering systems. By fine-tuning an embedding model on domain-specific datasets, it can be optimized to understand and retrieve more accurate results.
Fine-tuning is not only about improving accuracy; it also aligns the semantic understanding of the model with the specific requirements of a given use case, allowing for better document classification, semantic similarity detection, and retrieval-augmented generation (RAG). As the landscape of large language models (LLMs) evolves, there is increasing recognition that a one-size-fits-all approach does not suffice, especially in industries requiring precision.
Embeddings in NLP: A Foundation for Fine-tuning
Embeddings are at the core of many Natural Language Processing (NLP) tasks, providing dense numerical representations of text that capture semantic relationships. By mapping words, sentences, or documents into a multi-dimensional vector space, embeddings allow models to perform tasks like text classification, semantic similarity detection, and retrieval-augmented generation (RAG) with impressive accuracy.
At their foundation, embeddings work by placing semantically similar texts closer together in a vector space. This capability enables models to:
- Identify semantic similarity: Finding how closely related two pieces of text or images are.
- Classify text: Categorizing data into groups based on their meaning.
- Answer questions: Retrieving the most relevant document to answer a specific query.
- Enhance RAG: Combining embedding models with language models to improve the quality of generated responses.
While general-purpose embeddings can handle broad tasks, they often fail in domain-specific applications. For example, in specialized fields like medicine or law, embedding models must grasp the unique terminology and intricate relationships within the data. This is where fine-tuning becomes crucial—customizing the embeddings to fit the unique characteristics of the domain.
NLP Tasks that Rely on Embeddings:
- Text Classification: Grouping content into predefined categories.
- Semantic Search: Matching queries with the most relevant documents.
- Question Answering (QA): Identifying relevant answers based on a user's question.
- Entity Recognition: Identifying and classifying key entities in the text (e.g., names, places, dates).
As the LLM ecosystem evolves, developers now have access to a growing variety of open-source and proprietary models, such as LLaMA and Mistral, which offer the flexibility to fine-tune embeddings for specific industries. This shift from one-size-fits-all solutions allows for improved performance in niche applications, ensuring that models can deliver more accurate and relevant results.
Why Fine-tuning is Critical for Domain-Specific NLP Applications
While embeddings offer powerful tools for NLP tasks like semantic similarity, text classification, and retrieval-augmented generation (RAG), their performance diminishes when applied to highly specialized domains like medicine, law, or finance. This is where fine-tuning becomes crucial.
Why is Fine-tuning Necessary?
- Specialized Vocabulary: Domain-specific models, like those in the medical field, often contain terminology that general-purpose models don’t understand well. For example, terms like "myocardial infarction" in medicine would be missed or poorly understood by a generic embedding model.
- Contextual Nuances: Different industries have unique contexts and nuances. A legal term like "injunction" has a very specific meaning in law but might be interpreted differently by a general model. Fine-tuning helps align the semantic understanding with domain-specific contexts, leading to better performance in retrieval and generation tasks.
Key Benefits of Fine-tuning Embeddings:
- Improved Accuracy: Fine-tuned models can deliver more precise results when retrieving domain-specific documents or answering specialized questions.
- Enhanced Relevance: Embeddings that have been fine-tuned capture the context and meaning behind domain-specific vocabulary, improving the relevance of output across NLP tasks like classification and question answering.

Common Techniques for Fine-tuning Embeddings
There are several approaches to fine-tuning embeddings to make them more effective for specific domains:
- Triplet Loss:
- Encourages the model to place similar sentences closer together while pushing dissimilar sentences further apart. This is especially useful in information retrieval tasks where accuracy in ranking results is essential.
- Contrastive Loss:
- This technique uses positive and negative pairs to help the model distinguish between similar and dissimilar content. Fine-tuning with contrastive loss is often used in question-answering systems.
- Cosine Similarity Loss:
- Optimizes the embeddings based on the cosine similarity between sentence pairs, ensuring that sentences with similar meanings have embeddings that are close to each other in the vector space.
- Matryoshka Loss:
- A specialized loss function designed for truncatable embeddings, allowing for more efficient memory use and faster processing without compromising accuracy.
Techniques for Fine-tuning Embeddings: From LoRA to Loss Functions
Fine-tuning embeddings is crucial for adapting models to specific domains, especially in tasks where accuracy and relevance are critical. There are several advanced techniques available for fine-tuning embeddings, each offering unique advantages. This section explores key techniques, including LoRA and various loss functions, that help optimize the performance of embeddings in domain-specific tasks.
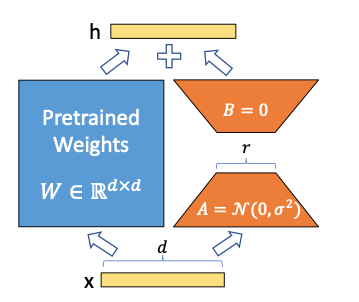
Low-Rank Adaptation (LoRA)
LoRA, or Low-Rank Adaptation, is a fine-tuning technique that introduces parameter-efficient learning by injecting low-rank updates into pre-trained models. This approach minimizes the number of trainable parameters, making it computationally efficient without sacrificing performance.
autotrain llm \
--train \
--model ${MODEL_NAME} \
--project-name ${PROJECT_NAME} \
--data-path data/ \
--text-column text \
--lr ${LEARNING_RATE} \
--batch-size ${BATCH_SIZE} \
--epochs ${NUM_EPOCHS} \
--block-size ${BLOCK_SIZE} \
--warmup-ratio ${WARMUP_RATIO} \
--lora-r ${LORA_R} \
--lora-alpha ${LORA_ALPHA} \
--lora-dropout ${LORA_DROPOUT} \
--weight-decay ${WEIGHT_DECAY} \
--gradient-accumulation ${GRADIENT_ACCUMULATION} \
--quantization ${QUANTIZATION} \
--mixed-precision ${MIXED_PRECISION} \
$( [[ "$PEFT" == "True" ]] && echo "--peft" ) \
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token )The snippet demonstrates the command for training a model using LoRA, along with key parameters like learning rate, batch size, and LoRA-specific parameters such as lora_r and lora_alpha.
Key benefits of using LoRA:
- Efficiency: LoRA reduces the number of trainable parameters while maintaining performance, allowing for more scalable training on larger models.
- Flexibility: This method can be applied across different layers of a neural network, enabling fine-tuning at different depths depending on the task.
A common implementation of LoRA involves updating only specific parts of the model, such as the query and value projection matrices in attention layers. This selective update reduces computation while allowing the model to adapt effectively to new data.
Loss Functions for Embedding Optimization
Loss functions guide the training process by measuring the discrepancy between the predicted embeddings and the actual labels. Choosing the right loss function is essential for ensuring the model learns the correct relationships between data points in the domain.
- Triplet Loss: Used to ensure that the embedding of a specific anchor point is closer to a positive sample (similar text) than to a negative sample (dissimilar text). This is effective for tasks like retrieval and ranking, where precision matters.
import torch
import torch.nn as nn
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative):
positive_dist = torch.norm(anchor - positive, p=2)
negative_dist = torch.norm(anchor - negative, p=2)
loss = torch.clamp(positive_dist - negative_dist + self.margin, min=0.0)
return lossThis snippet demonstrates how to implement Triplet Loss in PyTorch.
- Contrastive Loss: Focuses on maximizing the distance between dissimilar pairs and minimizing the distance between similar pairs. This method is commonly used in semantic similarity tasks, where the model must distinguish between related and unrelated inputs.
- Cosine Similarity Loss: Measures the cosine similarity between pairs of sentences and ensures that similar sentences have embeddings that are close in the vector space. This is widely used in document retrieval and question-answering tasks.
import torch.nn.functional as F
def cosine_similarity_loss(x1, x2):
return 1 - F.cosine_similarity(x1, x2).mean()This code snippet calculates Cosine Similarity Loss and can be easily adapted for NLP tasks.
- Matryoshka Loss: A more specialized loss function that enables the creation of truncatable embeddings. By allowing embeddings to be truncated for memory efficiency without losing semantic meaning, Matryoshka loss offers significant advantages in resource-constrained environments.
Efficient Fine-tuning with LoRA Variants
Variants of LoRA, such as LoRA+, further enhance the process by adding adaptive learning rates and dropout techniques that increase training stability. These improvements make the fine-tuning process even more efficient, especially for larger models such as LLaMA.
Combining LoRA and Loss Functions for Optimal Results
By combining techniques like LoRA with specific loss functions, developers can fine-tune embeddings to meet the requirements of their specific domain. For example, using Triplet Loss with LoRA can optimize the model for high-precision retrieval tasks, while Contrastive Loss combined with LoRA is ideal for semantic similarity tasks.
Real-World Applications of Fine-tuning Embeddings
Fine-tuning embeddings is not just a theoretical approach; it has real-world applications across industries such as healthcare, finance, and legal domains. These sectors often deal with specialized and complex data that require customized embedding models to handle unique terminologies and tasks efficiently.
Domain-Specific Applications of Fine-tuning
- Healthcare:
- In the healthcare sector, fine-tuned embedding models are used to understand medical terminologies and retrieve relevant medical literature. For instance, in tasks like medical question-answering or document retrieval, general-purpose models may struggle with understanding specific terms like "myocardial infarction." Fine-tuning ensures that these models can retrieve more accurate and contextually relevant results.
- Finance:
- In finance, fine-tuning embeddings helps models comprehend complex financial jargon and regulations. Fine-tuned models are applied to analyze financial reports, detect fraud, and generate more accurate predictions based on historical market data.
- Legal:
- The legal field involves dense and complex language, making it necessary to fine-tune models to recognize legal jargon and handle tasks like contract analysis and legal document retrieval. Fine-tuned embeddings significantly improve the relevance of information retrieved for specific legal queries.
Leveraging Transfer Learning Techniques for Fine-tuning
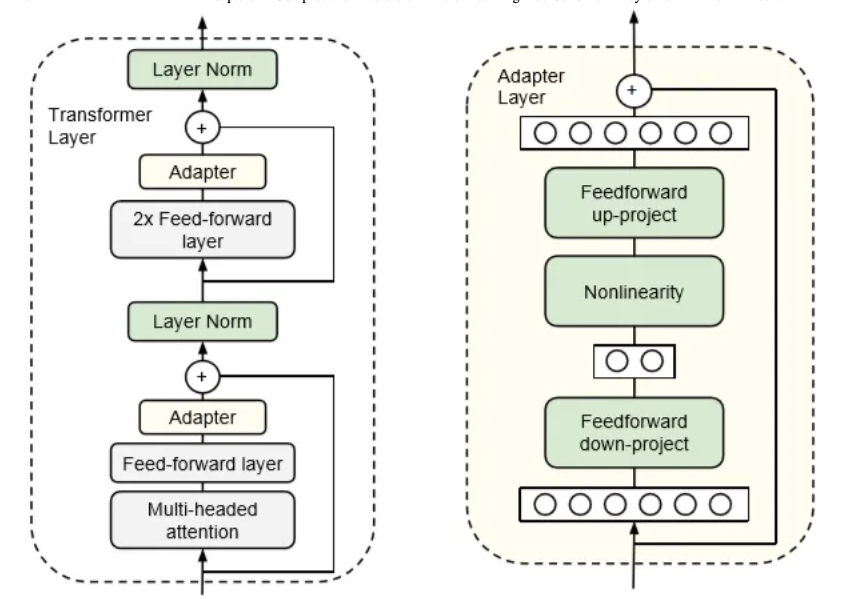
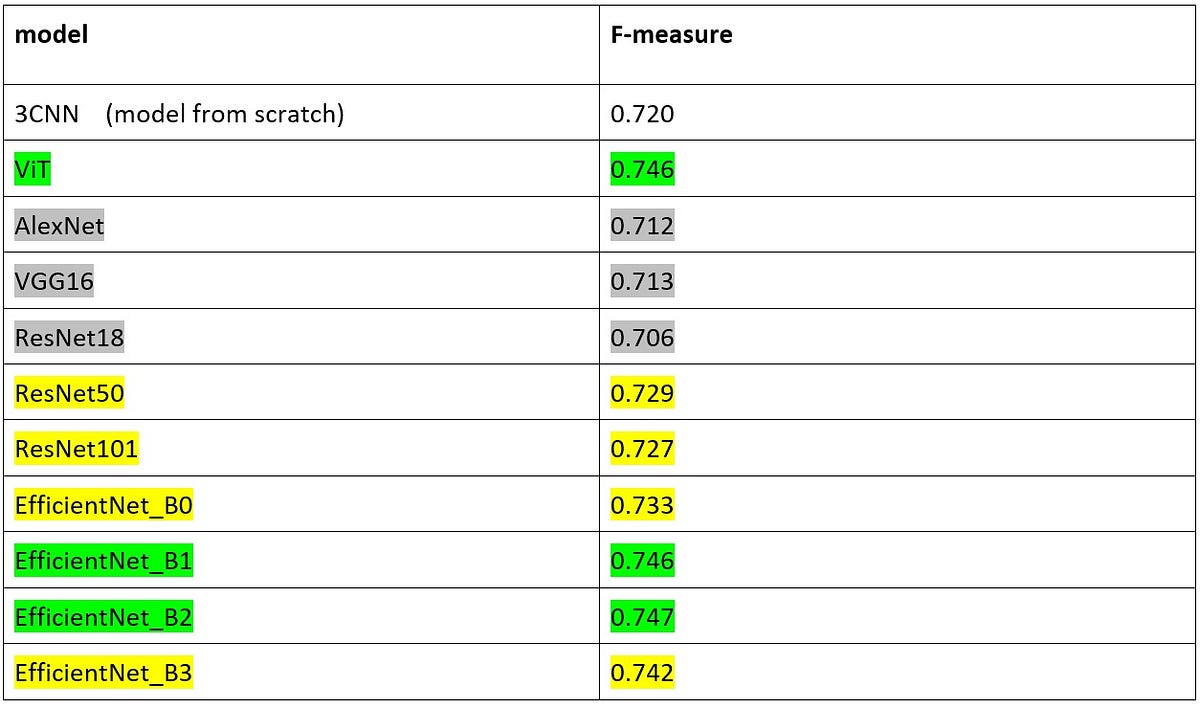
In addition to fine-tuning techniques like LoRA, Adapters are becoming increasingly popular for parameter-efficient transfer learning. This method involves injecting small adapter layers between pre-trained model layers, allowing for task-specific tuning without altering the core model parameters. This is especially useful for large-scale applications where training a new model from scratch for each task is inefficient.
from transformers import BertModel, AdapterConfig
# Load pre-trained BERT model
model = BertModel.from_pretrained("bert-base-uncased")
# Add a new adapter
adapter_config = AdapterConfig.load("pfeiffer")
model.add_adapter("domain_adapter", config=adapter_config)
# Activate the adapter for fine-tuning
model.train_adapter("domain_adapter")This code snippet demonstrates how to use adapter layers for fine-tuning with pre-trained models.
- Adapters for Efficient Transfer Learning:
- Adapters have proven to achieve results comparable to BERT on several NLP tasks while using significantly fewer parameters. The key advantage of adapters is that they enable the model to maintain high performance across multiple tasks without retraining the entire model.
Use Cases of Fine-tuned Embeddings
- Medical Question Answering Systems: Fine-tuned embeddings allow medical question-answering systems to retrieve precise documents based on specialized queries. For example, a fine-tuned model can differentiate between closely related medical terms, improving retrieval accuracy and assisting healthcare professionals in decision-making.
- Contract Analysis in Law: Fine-tuning embeddings for legal applications allows models to better understand complex legal texts, making them ideal for tasks like contract analysis, where specific legal terms carry significant weight.
- Fraud Detection in Finance: Fine-tuned models in finance help detect fraudulent activities by understanding the intricacies of financial transactions and identifying unusual patterns that might go unnoticed with general-purpose models.
The Future of Fine-tuning Embeddings: From Specialized Models to Scalable Solutions
As we look toward the future of fine-tuning embeddings, the landscape is evolving with the emergence of specialized models and more efficient transfer learning methods. The days of relying solely on massive, monolithic models are giving way to an era where smaller, task-specific models are becoming the norm. Here’s how the future is shaping up.
The Shift Toward Specialized Models
Large models like GPT-4 have been dominant, but they are increasingly being supplemented by more specialized models tailored to industry-specific tasks. These models, such as LLaMA and Mistral, offer developers flexibility to fine-tune embeddings without dealing with the overwhelming complexity of larger models. The need for niche applications in fields like healthcare and finance has accelerated this shift.
Key Trends:
- Industry-Specific Models: Companies are moving away from one-size-fits-all solutions toward models optimized for their specific domains. This means future embedding models will be much more customized to unique business needs.
- Open-Source Collaboration: The rise of open-source models, like LLaMA, is giving developers access to a broad range of customizable tools, allowing for more efficient fine-tuning.
Scalability and Efficiency in Fine-tuning
As models evolve, efficiency is becoming a key focus. Fine-tuning large language models for every small task is resource-intensive, but new methods like LoRA (Low-Rank Adaptation) and Adapters offer more scalable solutions for handling task-specific fine-tuning.
- LoRA:
- Efficiency: LoRA reduces the computational load by introducing low-rank updates to a model, cutting down the number of parameters that need to be fine-tuned.
- Scalability: This method allows for greater scalability as it can be applied to smaller, task-specific models, which can then be fine-tuned more quickly and with fewer resources.
- Compact Fine-tuning: Adapters add small trainable parameters between the layers of a pre-trained model, enabling task-specific adjustments without retraining the entire model.
- Multi-task Learning: These are highly efficient for multi-task learning, where models need to handle several tasks simultaneously, as the adapters can be adjusted for each task without disrupting the core model.
Future Applications: Transfer Learning and Data Efficiency
Transfer learning is becoming more important for reducing the data and computational requirements of fine-tuning. Instead of training models from scratch, developers can leverage pre-trained models for related tasks, which reduces the amount of data needed for fine-tuning.
- Data Efficiency: Many organizations don’t have vast datasets. However, techniques like transfer learning allow them to leverage models trained on large datasets, such as ImageNet, and fine-tune them for more specific tasks like medical image classification.
- Speed and Cost: Transfer learning also speeds up the training process and lowers costs, which is particularly beneficial in industries where data acquisition is expensive.
Looking Ahead
As the use of fine-tuning becomes more prevalent, models will continue to become more specialized and efficient. The introduction of more adaptable fine-tuning techniques like LoRA and Adapters means that companies can expect to handle task-specific requirements with less computational overhead. The future of embeddings is one of scalability, specialization, and efficiency—paving the way for a more accessible and adaptable AI landscape.
The End of Monolithic Models: Embracing the Diversity of Fine-tuned Embeddings
The dominance of large, monolithic models like GPT-4 is steadily giving way to a more diverse AI ecosystem where specialized models take center stage. As AI continues to integrate into industries like healthcare, finance, and law, the limitations of using a single model for all tasks have become more apparent. The era of one-size-fits-all models is being replaced by a tailored approach, where fine-tuned embeddings are customized for specific applications.
The Shift from Monolithic to Specialized Models
The growing demand for domain-specific solutions has prompted a shift away from large language models (LLMs) designed for general tasks. Models such as LLaMA and Mistral have been developed to cater to the specific needs of industries, providing developers with the flexibility to fine-tune embeddings according to their requirements. These models are more efficient for niche applications, as they allow for more granular control over performance.
Key factors driving this shift include:
- Efficiency: Specialized models are often more resource-efficient because they can be fine-tuned to perform a limited set of tasks exceptionally well, as opposed to general-purpose models which require extensive computational resources to cover a broad range of tasks.
- Flexibility: Open-source models like LLaMA give developers the freedom to customize embeddings to fit specific domains, such as medical image analysis or legal document retrieval.
The Role of Open-Source and Proprietary Models
Open-source models like LLaMA offer a flexible framework for developers to adapt models to industry-specific needs. On the other hand, proprietary models continue to push the boundaries of general AI performance, ensuring that organizations have access to state-of-the-art technologies.
The flexibility provided by open-source frameworks allows organizations to leverage powerful, fine-tuned embeddings without the constraints of using closed, monolithic systems. This evolution in model diversity is allowing businesses to optimize for specific use cases, whether they need retrieval-augmented generation (RAG) in legal settings or enhanced semantic similarity in customer service chatbots.
References:
 Filippo Pedrazzini
Filippo Pedrazzini Sayantan Das
Sayantan Das