
Mixture of Experts - Part 2
The article "Mixture of Experts - Part 2" explores the resurgence of Mixture of Experts (MoE) architectures in NLP, highlighting models like Mixtral 8x7B and DeepMind's Mixture-of-Depths. It discusses MoE's evolution since 1991, focusing on scalability and efficiency in large language models.

The announcement of Mixtral 8x7B and DeepMind's Mixture-of-Depths, among others, has once again made the Mixture of Experts (MoE) architecture for transformers a popular choice in the NLP community. Continuing our previous blog on fine-tuning, we discuss the popular scaling of LLMs via sparse experts, referred to as Mixture of Experts, with their brief history and variants over the last few years.
Let's get started!

🛣️ Mixture of Experts (MoE): A Journey from 1991 to Today
MoE started as a concept in 1991, with a model comprising several experts, each specializing in different data aspects, and a gating mechanism to decide the input's most relevant expert. That paper was introduced as Adaptive Mixture of Local Experts. This concept was first implemented in modern deep learning (what we know as the current "ML revolution") by Shazeer et al. in 2017, integrating MoE into LSTMs, which were the recurrent architecture before the attention paper came in. This integration allowed for scalability and efficiency, replacing dense FFN layers with sparse MoE layers, where a gating network routes tokens to relevant experts.
If you want to understand more about MoEs, we have a dedicated blog post on that, which covers all the basic concepts as well as the evolutions of MoEs and usage in Large Language Models.
 Filippo Pedrazzini
Filippo Pedrazzini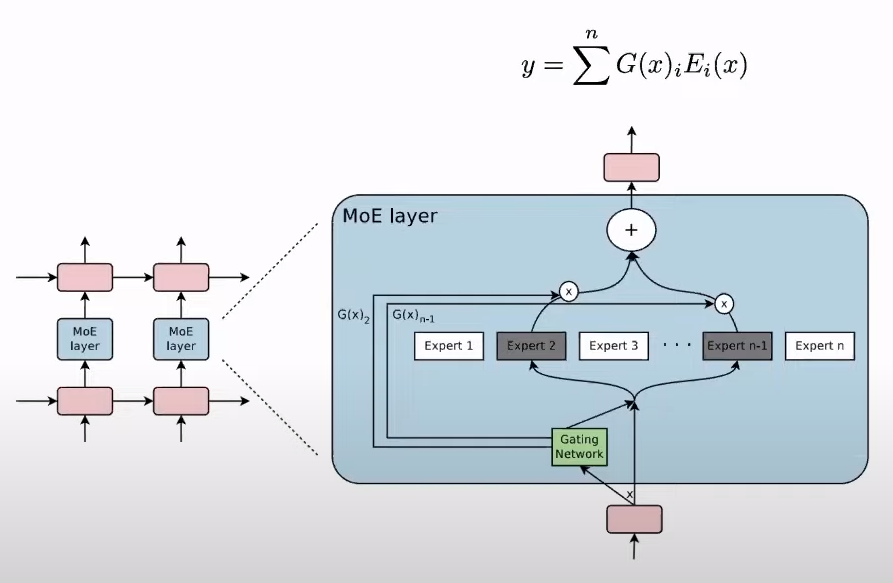
Shazeer et al. (2017) merged the MoE approach with an LSTM for machine translation, reviving MoE's 1991 introduction. This hybrid model processes input sequences via LSTM and employs a gating network \( G(h_t) = \text{Softmax}(W_g \cdot h_t + b_g) \) to dynamically allocate each input \( x_t \) to the most relevant experts \( E_i(h_t) \) for specialized processing. The final output is a weighted sum, \( \sum_{i=1}^{k} G(h_t)_i \cdot E_i(h_t) \), optimizing the model's focus and efficiency by leveraging expert diversity for varying translation aspects.
1. High communication costs due to the nature of expert selection
2. Model complexity
The Switch Transformer
Researchers at Google Brain proposed The Switch Transformer in 2021. This was the first time the idea of MoEs was tested at scale in the transformer paradigm.
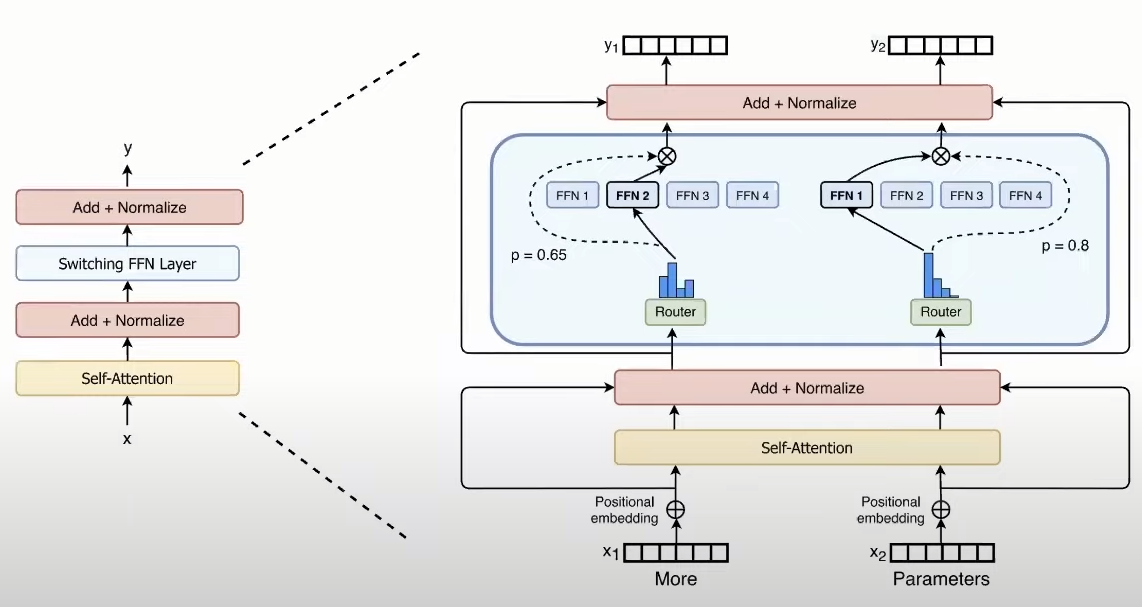
The goal was to replace the FFN layer with "multiple FFNs" and a router mechanism. Note that this is only applied in every layer of the transformer but for the FFN layer, not for the multi-head self-attention layer, unlike this new work by Deepmind called 'mixture-of-depths'.
In this research, the authors release the 1.57 trillion param model "Switch-C" in the suite of sparse layer transformers and compare it heavily with the T5 dense encoder-decoder model suite.

Key highlights from this research on Switch Transformer
- Selective Precision: While bfloat16 training saves compute costs, authors note the drop in negative log perplexity metric on the C4 dataset, compared to the float32 paradigm. They selectively apply float32 on the router computations to alleviate this while lowering compute usage.
- Top-1 Gating: While previous works discussed top-k gating, which allowed each token to be passed to k experts, researchers found that one expert per token worked well. This also enabled "expert parallelism," which allowed using experts in different GPUs, similar to a Single-Program-Multiple-Data scenario in computing.

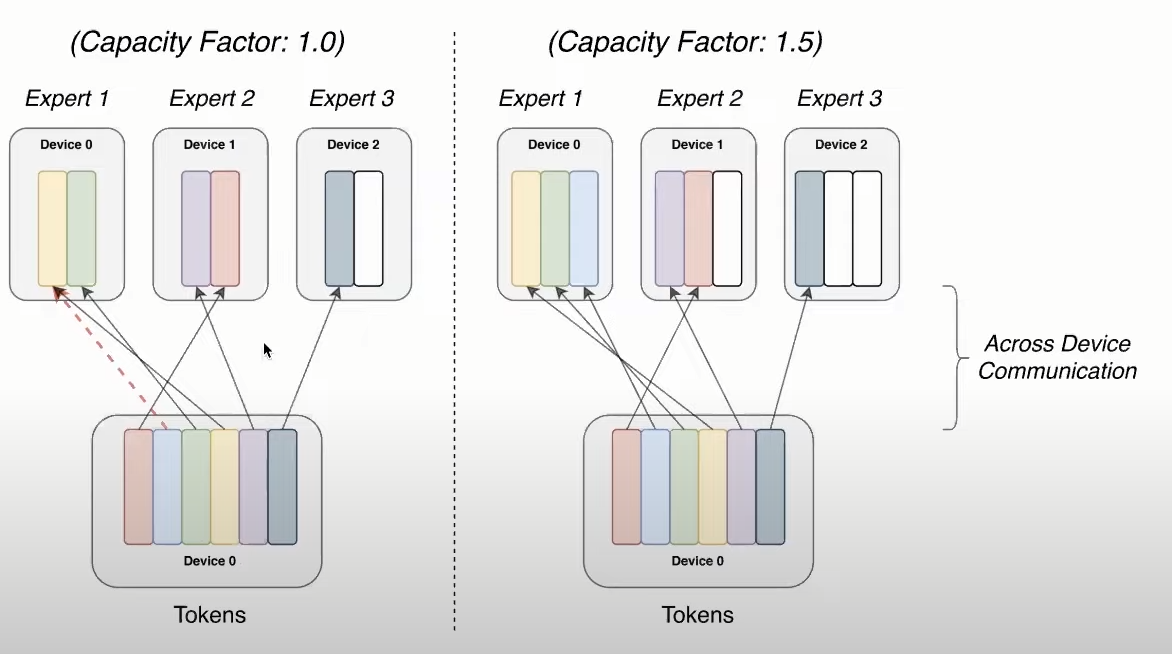
- Expert Capacity: Contrary to token capacity (or top-k gating), each expert is entitled to a fixed budget of tokens. This is a hyperparameter named "Expert Capacity". This ensures that no tokens are dropped.
Pretraining and Finetuning Performance Comparison (MoE, no MoE and Switch)
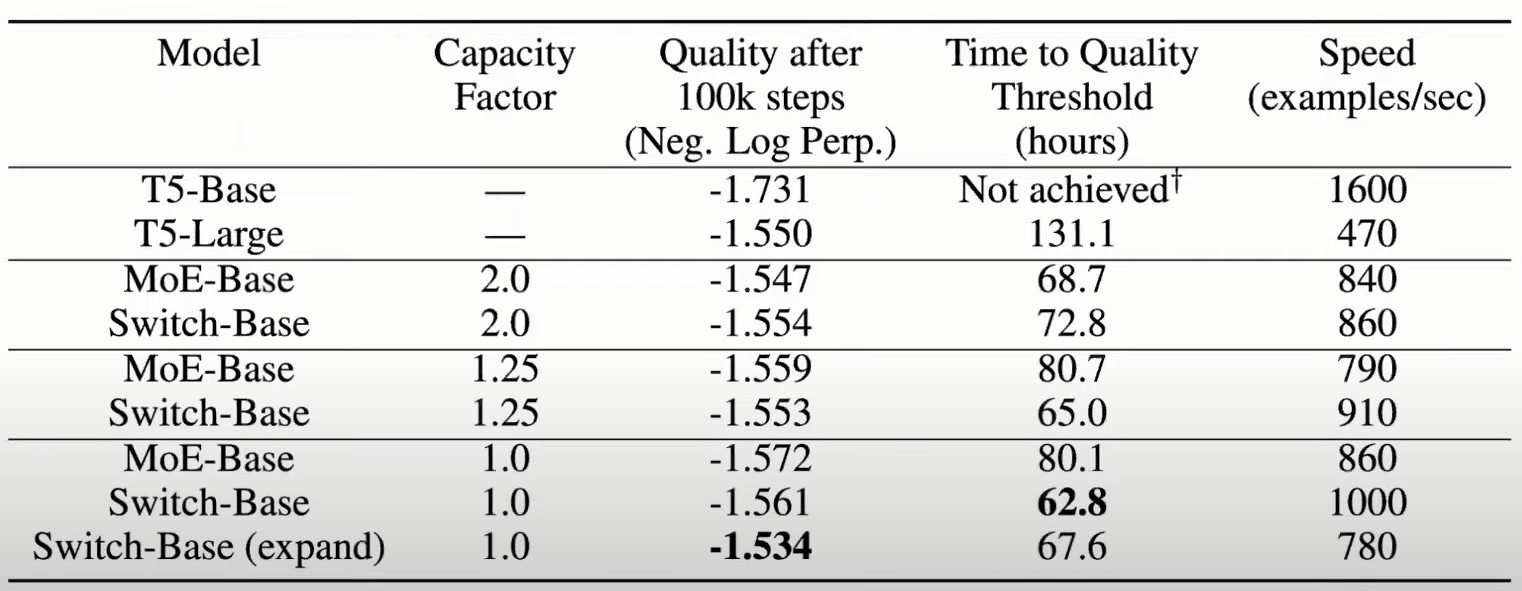
For varying capacity factors (sparse models only) and between dense (T5 family) and sparse (all else), we see the switch transformers improving in quality and time/speed.
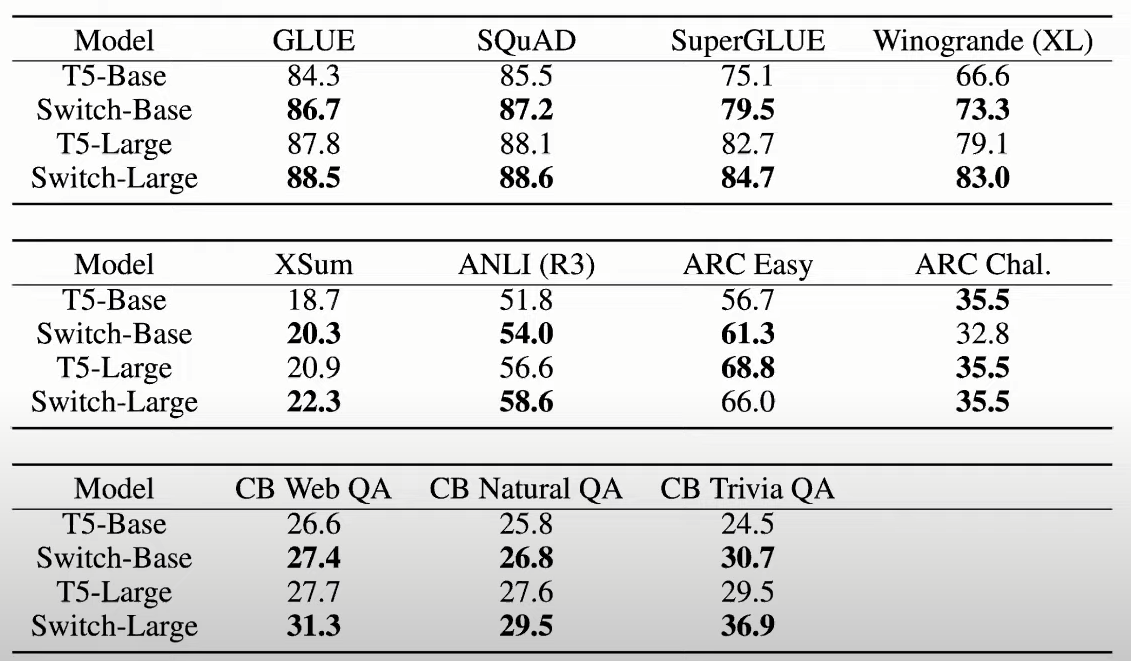
Note that Switch family models repetitively outperform their dense T5 family counterparts on respective downstream tasks. For in-depth info on static benchmarks, look at our blog post on LLM evaluations.
Sayantan DasThe MoE layer replaces every other Transformer feed-forward layer. Decoder modification is similar. (a) The encoder of a standard Transformer model is a stack of self-attention and feed forward layers interleaved with residual connections and layer normalization. (b) By replacing every other feed forward layer with a MoE layer, we get the model structure of the MoE Transformer Encoder. (c) When scaling to multiple devices, the MoE layer is sharded across devices, while all other layers are replicated.
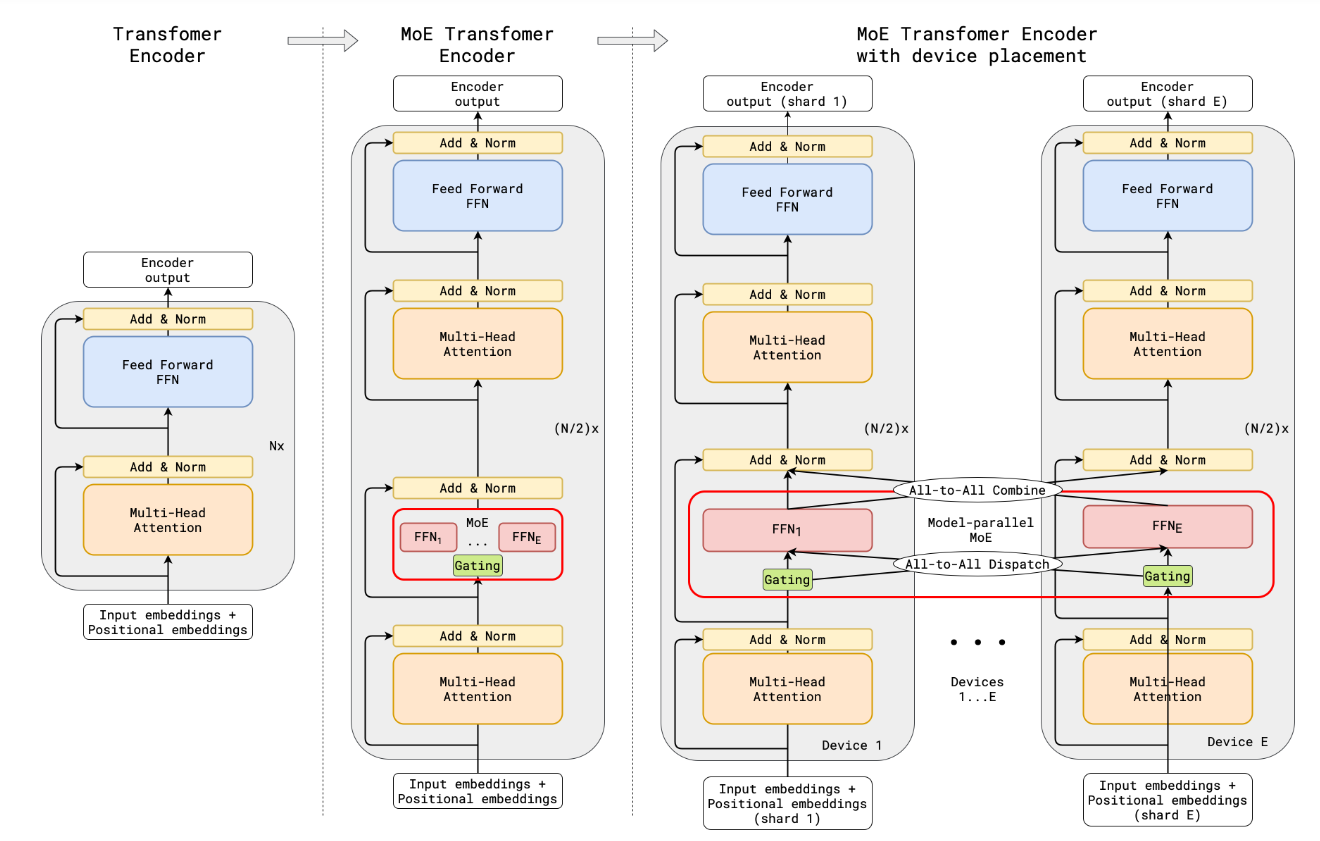
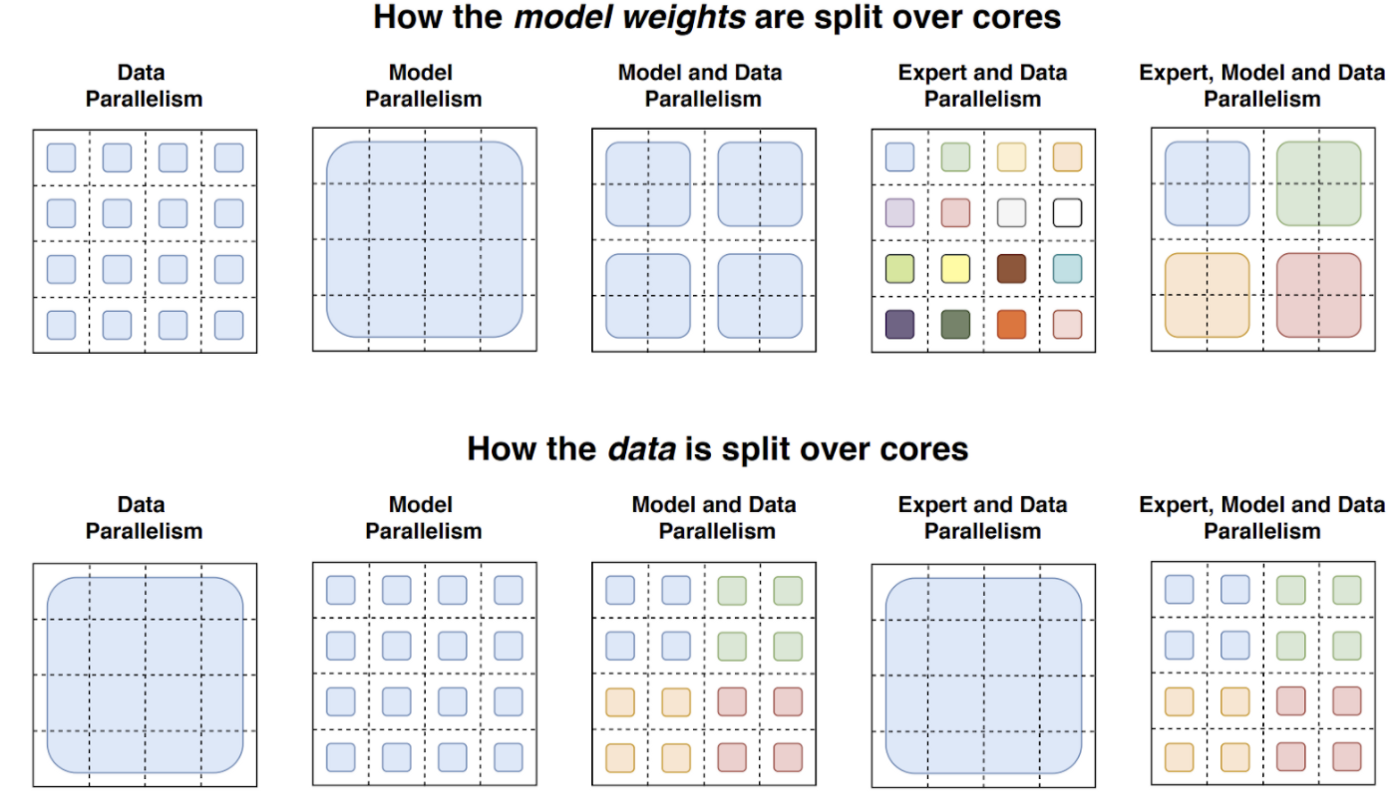
The switch transformer can scale up well because it can minimize communication requirements using model, data, and expert parallelism. Their Switch-C model (1.5T parameters), uses data and expert parallelism, whereas the Switch-XXL (397B parameters), uses data, model, and expert parallelism.
🧙 The Mixtral 8x7B
Mixtral by MistralAI is the first decoder-only model to apply MoE over 8 experts. For Mixtral, they use the same SwiGLU architecture as the expert function \( E_i(x) \) and set \( K = 2 \). This means each token is routed to two SwiGLU sub-blocks with different weights. Taking this all together, the output \( y \) for an input token \( x \) is computed as
\(y = \sum_{i=0}^{n-1} \text{Softmax}(\text{Top2}(x \cdot W_g))_i \cdot \text{SwiGLU}_i(x) \)
Qwen-MoE and DeepSeek-MoE: Fine-grained experts?
In contrast to the Mixtral paper, which proposes Top-2 routing, Qwen and DeepSeek propose some improvements:
- Fine-grained expert segmentation: Qwen and DeepSeek introduce a method where experts within a MoE model are segmented into more precise, smaller units. This segmentation allows for a more detailed and specific allocation of tasks or tokens to experts, significantly improving the model's ability to handle diverse and complex datasets. By dividing the experts into finer grains, these models facilitate a more nuanced approach to knowledge processing, allowing each segmented expert to specialize in a narrower field. This also brings learning efficiency, as each fine-grained expert can focus on learning specific aspects of the data more deeply. The segmentation also increases the flexibility and adaptability of the model, enabling a more dynamic response to varying data types and learning tasks.
- Shared expert isolation: The architecture isolates 𝐾number of experts as shared ones, which are always activated. These shared experts aim to capture common knowledge across different contexts, reducing redundancy among other routed experts. By consolidating common knowledge into these shared experts, DeepSeekMoE enhances parameter efficiency and ensures that each routed expert focuses on distinct, specialized knowledge.
Similar thoughts were reflected in the Qwen's blog.
In the case of Qwen1.5-MoE-A2.7B model, we have incorporated 4 shared experts to be always activated alongside 60 routing experts with 4 to be activated.
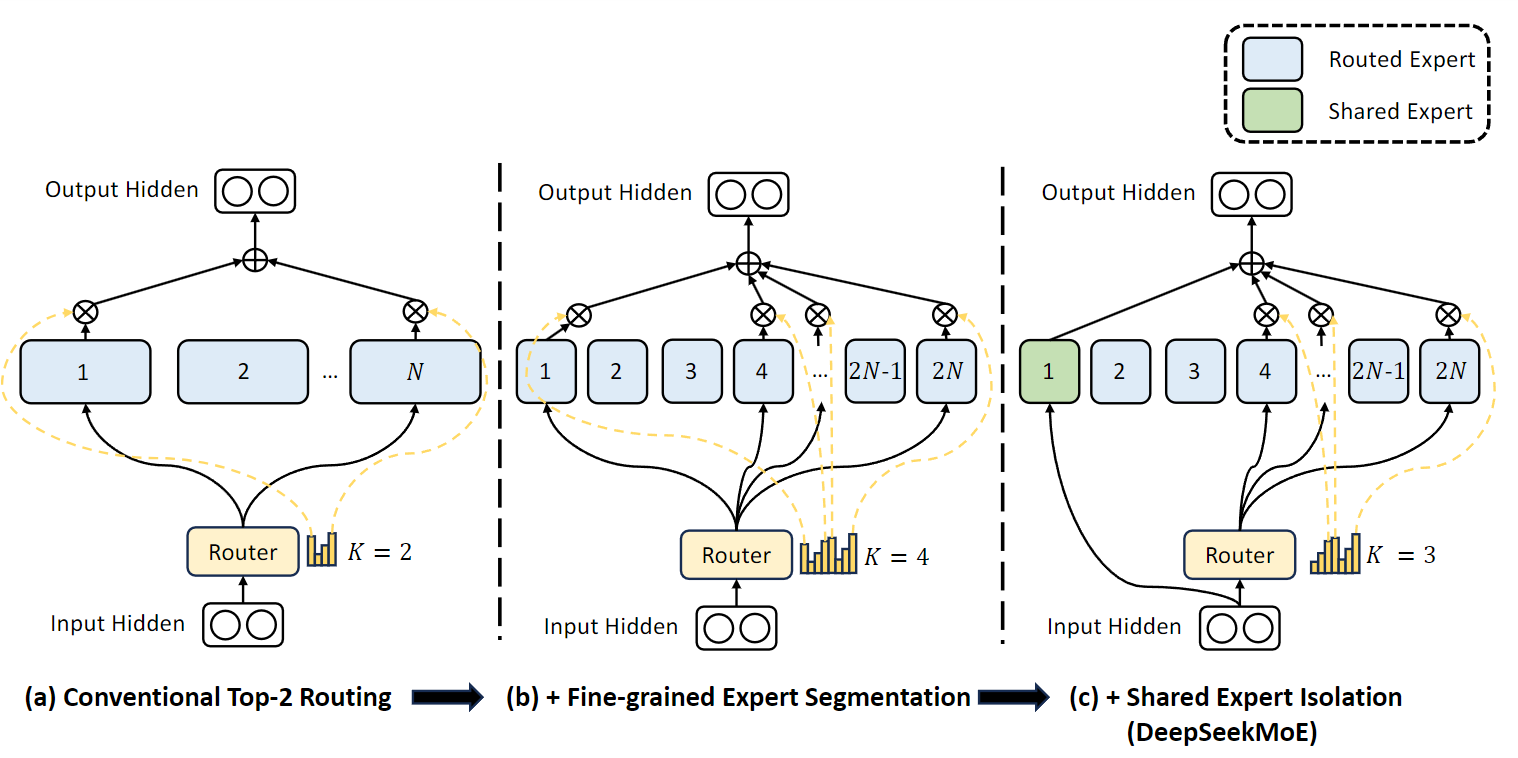
Refer to Figure 9 above for an illustration of DeepSeek-MoE. Subfigure (a) showcases an MoE layer with the conventional top-2 routing strategy. Subfigure (b) illustrates the fine-grained expert segmentation strategy. Subsequently, subfigure (c) demonstrates the integration of the shared expert isolation strategy, constituting the complete DeepSeekMoE architecture. Notably, the number of expert parameters and computational costs remain constant across these three architectures.
🤿 Mixture-of-Depths (Deepmind, 2024)
Another conditional computation technique similar to MoE is this newly released paper by Deepmind called “Mixture of Depths”.
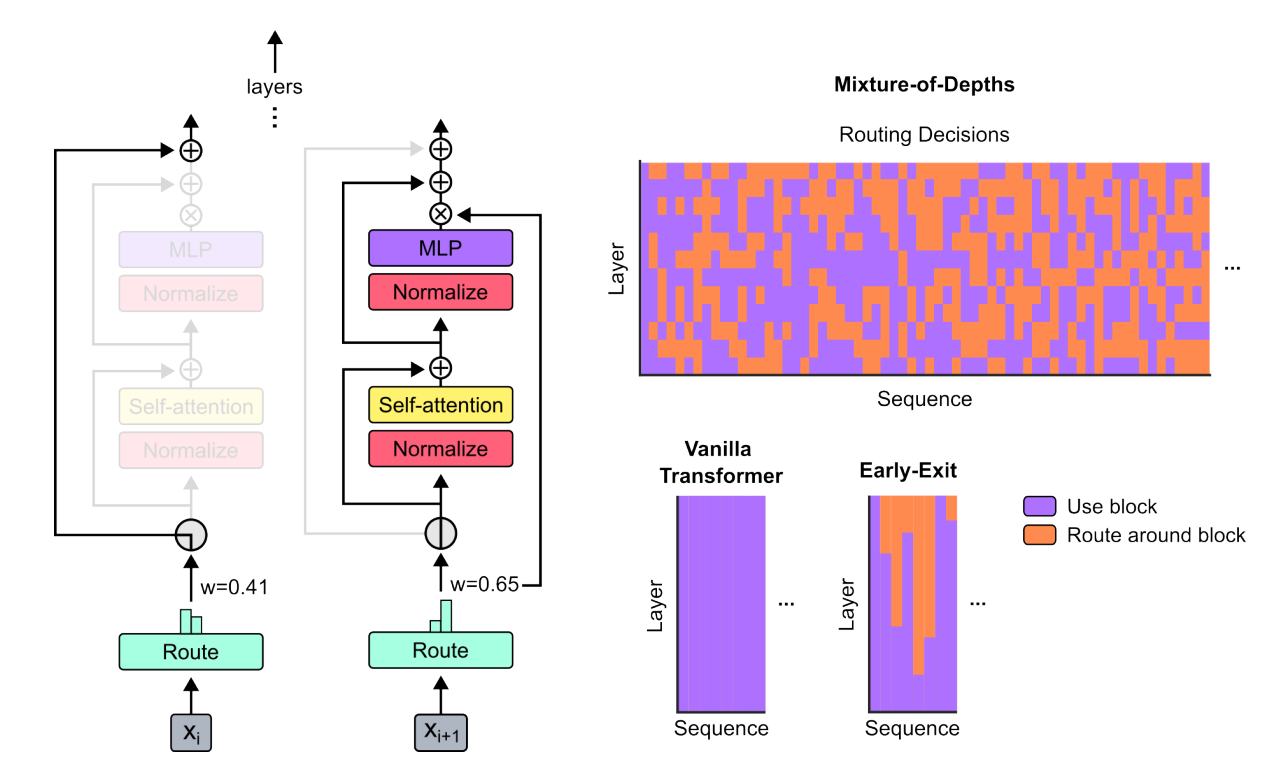
The paper's authors describe a Mixture-of-Depths (MoD) transformer that uses a router to choose among potential computational paths, similar to mixture-of-experts (MoE) transformers. However, unlike MoE transformers, the possible choices in MoD transformers are a standard block's computation (i.e., self-attention and MLP) or a residual connection. Since some tokens take the residual connection route, MoD transformers have a smaller total FLOP footprint than vanilla or MoE transformers.
The authors illustrate (see Figure 11) a trained model's routing decisions for a short sequence truncated to 64 tokens on the top right of the figure. Upon examining the choices, one can find tokens processed by later blocks' layers despite passing through relatively few total blocks throughout the model's depth. The authors point out that this is a unique feature of MoD compared to conventional halting-based or early-exit conditional computation, which instead engages blocks serially, or vanilla transformers, which engage every block.
The Mixture-of-Depths (MoD) technique differs from the Mixture-of-Experts (MoE) approach in several key aspects:
- Routing Logic:
- MoE: In MoE models, tokens are routed to different expert modules for processing based on learned routing decisions. Each expert specializes in a particular aspect of the input data.
- MoD: In MoD models, tokens are routed through different computational paths within the transformer architecture. This routing can involve standard transformer blocks, null computations (equivalent to multiplying by zero), or residual connections. The focus is on dynamically adjusting the depth of processing for individual tokens.
- Compute Allocation:
- MoE: MoE models use conditional logic to route tokens to different expert modules while maintaining a constant total compute expenditure.
- MoD: MoD models dynamically allocate compute resources by varying the depth of processing for tokens. This enables more efficient use of compute resources based on the complexity of the prediction task.
- Number of Experts:
- MoE: MoE models typically involve routing tokens to multiple expert modules, each specializing in a different aspect of the input data.
- MoD: MoD models deploy a single expert that can be dynamically skipped. They focus on adjusting the depth of processing for individual tokens rather than routing to multiple experts.
- Impact on Keys and Queries:
- MoE: Routing in MoE models primarily affects which expert module processes a token, influencing the final output.
- MoD: Routing in MoD models not only determines the computational path for tokens but also impacts which tokens are available for attention mechanisms like self-attention. This can affect how tokens interact with each other during processing.
Overall, while both MoE and MoD involve token-level routing decisions, MoE focuses on routing to multiple expert modules with constant compute expenditure, while MoD emphasizes dynamically adjusting the depth of processing for tokens within the transformer architecture to optimize compute usage.
🌀 Conclusion
As we move on, here are a few key takeaways from our discussion on MoEs:
- Revitalized Interest in MoE: The renewed focus on Mixture of Experts (MoE) architectures, driven by innovations like Mixtral 8x7B and DeepMind's Mixture-of-Depths, underscores the NLP community's pursuit of more efficient and scalable transformer models.
- Evolution of MoE: From its inception in 1991 to its integration into state-of-the-art models, MoE has shown significant promise in enhancing computational efficiency and model scalability through the utilization of sparse networks of specialized experts.
- Advancements in MoE Applications: The Switch Transformer by Google and Mixtral by MistralAI highlight how MoE architectures can be applied at scale and adapted to different model formats, including decoder-only configurations.
- Innovative Approaches to Expert Utilization: Developments in fine-grained expert segmentation and shared expert isolation point to a trend toward more nuanced and effective use of experts, aiming to improve model performance on complex datasets.
- Alternative Techniques like Mixture-of-Depths: DeepMind's introduction of Mixture-of-Depths presents an alternative to traditional MoE models by varying the computational depth for different tokens, showcasing the field's continuous innovation.
The future looks promising for MoEs, or in general, models with a router. The community also refers to these models as dynamic compute methods.
These savings further compound when paired with Mixture of Experts. We are entering an era of scalable compute of LLMs. Tokens will not have fixed costs, the machine will take the time it needs to think. Massive improvements for both gpu rich and poor pic.twitter.com/ZAuwXFwFju
— Hassan Hayat 🔥 (@TheSeaMouse) April 4, 2024
dynamic computer networks
Quantization of MoEs is already a thing (QMoE, Oct 2023) and will be an emerging trend. This will make MoE deployments suitable for very specific use cases across many devices. We can't wait to see how production systems utilize MoEs.
📜 Resources
- T5 Model Family
- AutoTrain
- Mistral codebase
- Qwen blog
- HF blog on MoE
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Switch Transformers: Scaling to Trillion Parameter Models
with Simple and Efficient Sparsity - Stanford CS25 lecture on switch transformers
- Yannic Kilcher's video on sparse experts
- ST-MOE: DESIGNING STABLE AND TRANSFERABLE
SPARSE EXPERT MODELS - Routers in Vision
- Out of the box optimizations by Unsloth
- MEGABLOCKS: EFFICIENT SPARSE TRAINING WITH MIXTURE-OF-EXPERTS (Paper behind the "no-token-left-behind" strategy).
- Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
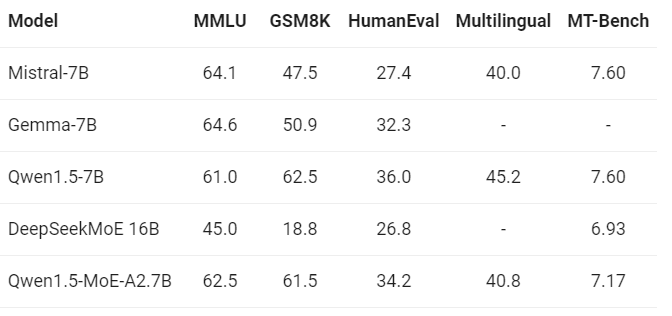
- Mistral Benchmark
- OpenLLM Leaderboard